目录导读
- 限流在不同场景的最佳实践
- 1. 前言
- 2. 为什么要限流
- 3. 有哪些限流场景
- 3.1 限流场景分类
- 3.2 限流与熔断降级之间的关系
- 3.3 非业务限流
- 3.4 业务限流
- 4. 有哪些限流算法
- 4.1 计数器限流算法
- 4.2 漏桶限流算法
- 4.3 令牌桶限流算法
- 4.4 滑动时间窗限流算法
- 4.5 限流算法选型
- 5. 限流扩展实践
- 5.1 调用量限流扩展实践
- 5.2 QPS限流扩展实践
- 6. 参考资料
限流在不同场景的最佳实践
1. 前言
- 网上的很多资料,要么在介绍限流算法、要么就在讲限流实现;要么只关注开源的Sentinel是怎么做限流的,要么只关注业务逻辑中的限流是怎么做的……很少有人把各种限流的业务场景讲清楚。
- 前面介绍了熔断降级和限流的开源实践:熔断降级与限流在开源SpringBoot/SpringCloud微服务框架的最佳实践 ,里面加了太多开源代码的前置条件,阅读起来可能不那么顺畅,现在想抛开开源框架,单独讲讲限流在不同场景的最佳实践。
- 技术都是为了解决特定业务场景的问题而产生的,技术发展的初心就是简洁优雅地解决特定业务问题。
- 由于本人见识、经验有限,可能存在一些认知偏差,欢迎各位批评指正。
2. 为什么要限流
- 先给大家说明下我理解
限流的定义:为了避免在特定时间内给软件系统造成超出其承受能力的资源访问,而采取的一种防御技术手段。 - 在讲为什么需要限流时,先给大家讲讲没有限流行不行? 答案是:行!本人曾经在一家电信领域的巨无霸公司工作,在项目初期就会和客户确认业务并发量,然后基于这些指标设计方案、报价,得到客户的认可后,性能指标等都会写入交付合同,然后就启动开发、测试、性能评估,确保完全符合客户需求之后,才会正式交付给客户。当然实际交付时,性能指标通常会超出合同列举的性能指标,但是超出部分是不做商务承诺的,出了问题由客户自负;或者客户加钱,我们扩容或者设计更优的技术方案来满足更高的并发要求。不做限流是因为项目是私部署到客户机房的,很有可能只是客户业务场景中很小的一个环节,是不太好评估如何做限流,以及限制什么资源的访问流量;
- 那我们为什么要做限流呢? 还是先举个亲身案例来说明:本人还在一家金融保险领域的巨无霸公司工作过,主要是给客户提供SaaS服务。在正式提供服务前,我们会先和客户签订商务合同,同时约定并发量,超出时就我们就会无责限流。一旦客户有活动,需要提前几天和我们申请更高的并发(额外收费),我们收到申请后,就会评估并扩容,活动结束后,我们再移除扩容的资源。我们限流是因为服务依赖底层的GPU算力,而GPU又非常昂贵,基于成本考虑,我们没有做弹性扩缩容。因为我们必须保证其他客户的正常合理使用,所以需要按照合同约定对每个客户做精确的限流。
3. 有哪些限流场景
3.1 限流场景分类
- 我总结的限流分类如下图所示:

- 下面依次澄清下上图的限流场景概念:
-
从大的场景划分,
限流可分为非业务限流(又叫非功能限流,DFX特性 之可靠性设计)和业务限流(又叫功能限流,后面就不专门解释了,下同)。 -
非业务限流就是为了系统高可靠而存在,限制全部客户访问微服务的整体流量,与具体业务无关,与具体客户无关,因此非常适合做公共的限流模块,且只做QPS限流(更严格来说是并发限流,下同);由于与业务无关,也不适合做针对单个客户的调用量限流。 -
业务限流则是为了精细化业务场景的限流,保证在各种业务场景下都能正常运行,可分为单客户限流和单渠道限流(后面均简称客户限流和渠道限流)。客户限流是指限制客户端的访问,以保证服务的稳定;渠道限流是指限制服务对底层服务的访问,以保证本服务有足够的调配空间。客户限流就是为了避免客户的访问超过了系统的限制,从而让系统不稳定;渠道限流则是为了避免被渠道限制而主动采取的防御手段。如:本服务对接了多个渠道,而每个渠道都设置了每天的最大访问量,为了能够更好的使用而不超过渠道限制,那就需要对渠道调用量限流; -
客户限流和渠道限流均包含了QPS限流和调用量限流。QPS限流对应并发控制,调用量限流则是对应特定时间段的数量控制。二者的差异是:QPS限流时效极短,调用量限流时效较长;且二者实现的技术细节差别较大; -
从部署方式来看,限流可分为
单机限流、集群限流,对比分析如下:限流实现机制 特点 优势 不足 代表框架 单机限流 仅对实例本身做限流 1.可以不依赖外部组件存储限流数据,存取效率高;
2.实例扩展非常便捷(如扩缩容);1.无法把控集群的限流。一旦实例流量不均衡,限流就是灾难;
2.实例数量会直接影响限流效果,不利于弹性扩缩容;Guava/Resilience4j 集群限流 对集群的多个实例做整体限流 1.集群限流理论上可以兼容支持单实例限流;
2.可以很好地支持实例的各种负载均衡模式;
3.通常会把限流的数据存储从实例中摘除,非常利于限流的弹性;1.存在外部存储依赖,执行的效率相对较低;
2.把分散的限流数据汇聚到了集中的存储组件中,数据量暴增N倍(N为实例数量),有时甚至需要更换存储方案;
3.限流的异常处理逻辑会因为实例、引入的组件而变得非常复杂;Sentinel/Redis
-
综上所述:
- 限流在大多场景下都是需要的,限流可以规避系统瓶颈问题,保护大部分客户的正常使用;
- 限流除了大家理解的常规的限制客户流量外,还可以变相地做内部的资源调配(如
渠道限流);- 虽然有
单机限流和集群限流,但是在实际微服务项目中,基本上都是基于集群限流,只有像独立的三方件(如:Nginx)才会使用单机限流;- 限流也并不是在所有场景下都是必须的,有些系统内的小业务模块,就没有必要单独做限流,因为外部的网关或者接入服务可能已经做了限流;
3.2 限流与熔断降级之间的关系
- 个人理解的限流、熔断和降级的概念 :
| 概念 | 处理终端 | 处理措施 | 具体指标 | 恢复措施 |
|---|---|---|---|---|
| 熔断 | 客户端 | 当客户端发起请求时,一旦服务方响应比较慢或者发生了异常,其数值超过了阈值, 则客户端在后续的请求中就直接跳过请求服务端,直接响应预设的失败结果 | 1.按照一定的响应时限熔断; 2.按照异常的比例或者类型熔断; | 一般支持半熔断状态,可自动恢复 |
| 降级 | 服务端/客户端 | 1.作为服务端,当资源紧张时,主动停掉部分不重要的服务,直接响应预设的异常数据给客户端; 2.作为客户端,作用类似于熔断,但是比熔断的作用范围要小。比如:熔断前会先变成半熔断状态,就可以认为是服务降级; | 1.按照业务重要程度来区分 | 自动或者手动恢复 |
| 限流 | 服务端/客户端 | 1.作为服务端,当客户在特定时间内的请求达到一定阈值时,直接响应超限的异常结果; 2.作为客户端,在特定时间内,达到服务端允许的调用阈值时,直接响应超限异常或者更换调用其他服务方; | 1.服务端约定时间内的最大调用量限流,如:允许客户A每天调用/xx接口100万次; 2.服务端约定QPS限流,如:允许客户A最大的QPS为100; 3.客户端被约定时间内的最大调用量限流,如:每天被允许调用/xx接口500万次; 4.客户端被约定QPS限流,如:被允许的最大QPS为200; | 自动恢复 |
- 限流、熔断降级框架比较 :
| 场景支持情况对比 | Hystrix | Resilience4j | Sentinel | Redis | Guava |
|---|---|---|---|---|---|
| 作为服务端,接口被调用的天调用量限流 | ✖ | ✖ | ✖ | ✔ | ✔ |
| 作为服务端,接口被调用的QPS限流 | ✔ | ✔ | ✔ | ✔ | ✔ |
| 作为服务端,接口被客户ID调用的天调用量限流 | ✖ | ✖ | ✖ | ✔ | ✖ |
| 作为服务端,接口被客户ID调用的QPS限流 | ✖ | ✖ | ✖ | ✔ | ✖ |
| 作为客户端,调用第三方接口的天调用量限流 | ✖ | ✖ | ✖ | ✔ | ✖ |
| 作为客户端,调用第三方接口的QPS限流 | ✖ | ✖ | ✖ | ✔ | ✖ |
| 集群限流 | ✖ | ✖ | ✔ | ✔ | ✖ |
总之,可以这样来理解限流与熔断、降级之间的关系:
- 限流主要是基于请求而言,阻断了超越系统承受能力的请求,属于被动防御;
- 熔断和降级则除了基于请求而言,还可以基于某个资源(如数据库资源、文件资源等)来做控制,除了可以被动防御外,还可以主动防御(如主动降级不重要的服务或者业务),从某种程度而言,熔断和降级是限流的外延(延伸和扩展);
- 一般把限流和熔断、降级放在一起比较,主要是基于
非业务限流,如上表的框架比较亦如此;- 基于业务的限流(如限制A客户最高并发是20,日最大调用量时10w,B客户最高并发是50,日调用量时30w)因为涉及到太多的业务规则和业务定制,不适合放在基础框架中去做,就适合做
业务限流。如上图而言,非业务限流最终采用了sentinel,而业务限流则采用了redis。
3.3 非业务限流
- 如上限流框架分析可知:
非业务限流使用支持集群限流的Sentinel更优。 非业务限流在SpringCloud框架下,主要分为SpringCloud-Gateway(WebFlux技术栈,底层是基于Netty的NIO)、SpringBoot-Web(Tomcat技术栈,底层是基于Servlet的BIO)两种技术栈。仅做限流实现时,只需要在Sentinel中配置资源URL限流参数即可。具体实现参见限流、熔断降级框架比较 。
注意:
非业务限流一般只做QPS限流。
3.4 业务限流
- 如上限流框架分析可知:
业务限流使用支持集群限流的Redis更优。 业务限流,可分为QPS限流和调用量限流,在SpringCloud框架下,主要是依赖所有微服务实例共享的Redis的高性能内存操作。具体实现参见限流、熔断降级框架比较 。
4. 有哪些限流算法
- 业务限流策略分为
QPS限流和调用量限流。QPS限流会涉及较为复杂的限流算法,调用量限流基本上只需要计数器限流算法即可。 - 通常所说的限流算法可分为
计数器限流算法、漏桶限流算法、令牌桶限流算法和滑动时间窗限流算法。 - 基于前面的业务场景分析,无论是
非业务限流还是业务限流,基本上都是使用分布式限流算法。下面就仅以支持分布式限流的redis来分析上述各种限流算法。
4.1 计数器限流算法
计数器限流算法是为了解决一定时间段内的总访问量问题。算法逻辑为:记录时间段的总调用量,一旦超过了阈值就限流。如:限制客户A每天的最大请求量为100笔。其redis的lua脚本代码如下:-- 获取限流key local limitKey = KEYS[1] --redis.log(redis.LOG_WARNING,'max limit key is:',limitKey)-- 调用脚本传入的限流大小 local limitNum = tonumber(ARGV[1])-- 传入过期时间(ms) local expireMills = tonumber(ARGV[2]) local count = redis.call('get',limitKey); if count then-- 获取当前流量大小local countNum = tonumber(count or "0")--是否超出限流值if countNum + 1 > limitNum then-- 拒绝访问return trueelse-- 没有超过阈值,设置当前访问数量+1redis.call('incrby',limitKey,1)-- 放行return falseend else-- 没有超过阈值,设置当前访问数量+1redis.call('set',limitKey,1)-- 设置过期时间(ms)redis.call('pexpire',limitKey,expireMills)-- 放行return false end
4.2 漏桶限流算法
漏桶限流算法是模拟漏斗同时进水和出水的场景来做限流的。算法逻辑:如果桶是空的,不用限流,如果桶满了,再来请求,则拒绝服务。它主要是保持恒定的流出速率,有流量整形的说法。但是桶的容量和流出速率设置是个比较麻烦的事情,而且它只保证了流出速率,无法100%保证QPS限流的效果。代码实现可参见计数器、滑动窗口、漏桶、令牌算法比较和伪代码实现 。
4.3 令牌桶限流算法
令牌桶限流算法则是模拟排队取号办业务场景来做限流的。它主要是保证了可控的流入速度,可避免突发高并发流量。与漏桶限流算法控制恰恰相反,令牌桶限流算法控制了请求的进入速度,漏桶限流算法控制了请求被处理的速度。代码实现可参见计数器、滑动窗口、漏桶、令牌算法比较和伪代码实现 。
4.4 滑动时间窗限流算法
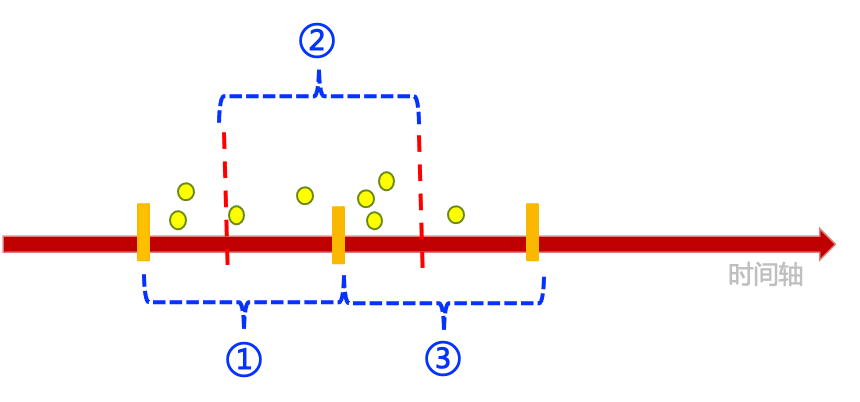
滑动时间窗限流算法是表示在特定的时间内,汇总之前记录的各个时间点的访问数量,大于限流阈值就限流,否则就不限流。这个无论是理解还是实现都是最直观的。- 下图展示了在时间滑动时,2个时间窗(如编号①和③所示,假如每个时间窗都是1秒)的调用情况,按照固定时间窗来看,2个时间窗的QPS都是4。这其实就是
固定时间窗限流算法,即:只关注整个单位时间内的调用数量。但是按照滑动时间窗来看,则还存在QPS为5的时间窗(如编号②所示)。理解滑动时间窗的核心是要理解:每个请求进入时,都需要往过去截取一个时间单位。
滑动时间窗限流算法的redis lua脚本实现如下:-- 获取限流key local limitKey = KEYS[1] --redis.log(redis.LOG_WARNING,'access limit key is:',limitKey)-- 调用脚本传入的限流大小 local limitNum = tonumber(ARGV[1]) -- 传入数据的有效期(ms,比如1秒) local expireMills = tonumber(ARGV[2]) -- 传入当前时间(ms) local nowMills = tonumber(ARGV[3])--清除过期数据 local expiredTimeMills = nowMills-expireMills; redis.call('zremrangebyscore',limitKey,0,expiredTimeMills);local count = redis.call('zcard',limitKey);-- 获取当前流量大小 local countNum = tonumber(count or "0")--是否超出限流值 if countNum + 1 > limitNum then-- 拒绝访问return true else-- 没有超过阈值,设置当前访问数量+1redis.call('zadd',limitKey,nowMills,nowMills)-- 设置过期时间(ms,相当于给这个zset key自动续期)redis.call('pexpire',limitKey,expireMills)-- 放行return false end前面之所以不介绍
固定时间窗限流算法,就是因为它是滑动时间窗限流算法中的一个特例,即传入限流参数时,把时间戳对应的秒后面的毫秒数全部抹掉,补0就是了。大家可以想想这是为什么。
4.5 限流算法选型
- 汇总下各限流算法的特点如下:
| 限流算法 | 算法概述 | 效率对比 | 适用场景 |
|---|---|---|---|
| 计数器限流算法 | 约定时间段内,基于计数限流 | 算法简单,占用存储空间小 | 适用于调用量限流,不能直接用于QPS限流 |
| 漏桶限流算法 | 约定单位时间内,基于漏桶大小和流出速率来限流 | 算法较简单,占用存储空间小 | 适用于不严格,但需要稳定的限流速率的QPS限流场景 |
| 令牌限流桶算法 | 约定单位时间内,基于令牌领取的排队机制来限流 | 算法较复杂,占用存储空间较大 | 适用于不严格,但是有突发高并发流量的QPS限流场景。如:抢购限流 |
| 滑动时间限流算法 | 约定滑动的单位时间内,基于计数限流 | 算法较复杂,占用存储空间大 | 适用于严格,且无需关注超出并发的QPS限流场景 |
总之,无论是非业务限流,还是业务限流,在当下的微服务场景下,一般都建议使用集群限流。非业务限流建议使用Sentinel;业务限流则建议使用redis做限流。常规情况下,建议使用redis做精确的滑动时间窗限流;最好的方式还是结合上面的表格,基于具体场景去分析。
5. 限流扩展实践
- 前面已经分析了限流的各个场景,以及各种限流算法实现。这里就重点讲讲怎么复用上面的限流实现去扩展支持各种不同的限流细化场景。
5.1 调用量限流扩展实践
- 前面介绍了基于调用量限流的redis lua实现。实际工作中,我还碰到过做客户
天调用量限流、月调用量限流的限流。仍基于上面调用量的lua脚本中,传入不同的limitKey和expireMills即可轻易做到。那是不是也很容易做到支持周、半个月、甚至是年的调用量限流?
5.2 QPS限流扩展实践
- 前面介绍了基于QPS限流的redis lua实现。实际工作中,上面的QPS限流脚本是可以直接支持客户QPS限流和渠道QPS限流的。除此之外,还可以一行代码不改,扩展支持特定时间内的并发限流,如
10秒内,并发不超过500个。也就是说QPS限流只是个人习惯的一个说法,其实用并发限流更准确,完全可以扩展到任意的时间单位来看并发。这也是上面的滑动时间窗图上没有标记时间单位的原因。
6. 参考资料
- [1]限流算法:时间窗口,令牌桶与漏桶算法对比
- [2]凤凰架构之流量控制
- [3]限流算法-令牌桶、漏桶算法之java实现
- [4]计数器、滑动窗口、漏桶、令牌算法比较和伪代码实现