爬虫
- 前言
- 代码
- 效果
简单的爬取图片
前言
这几天打算整理与迁移一下博客。因为 CSDN 的 Markdown 编辑器很好用 ,所以全部文章与相关图片都保存在 CSDN。而且 CSDN 支持一键导出自己的文章为 markdown 文件。但导出的文件中图片的连接依旧是 url 连接。为了方便将图片保存到本地,在这里保存一下爬虫代码。
只要修改正则匹配代码,同样适用于博客园爬取。
代码
为了提高效率,该脚本将从保存的本地 markdown 文件读取图片链接。当然脚本中也保留了爬取某个页面所有图片的函数。
脚本名:spider.py
import urllib.request
import urllib.parse
import sys
import os
import re def open_url(url):'''用于网页爬取。这里不采用这个函数'''req = urllib.request.Request(url) req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0')# 访问url,并将页面的二进制数据赋值给 pagepage = urllib.request.urlopen(req)# 将page中的内容转换为utf-8编码html = page.read().decode('utf-8')return htmldef read_file(file):print('\n正在读取文件...')with open(file, 'rb') as my_file:content = my_file.read()content = content.decode('utf-8')print('已读取文件.')return contentdef get_img(content, file_path):# 正则匹配图片链接# p=r'<img src="([^"]+\.png)"' # 可用于网页爬取p=r'https://img-blog\.csdnimg\.cn/[\w\-/]+\.png'#返回正则表达式在字符串中所有匹配结果的列表print('\n正在读取图片链接...')img_list=re.findall(p, content)list_len = str(len(img_list))print('已读取图片链接.\n')for img_url in img_list:print(img_url)print('\n共 ' + list_len + ' 条数据')# 图片保存位置。如果文件夹不存在则创建save_path = file_path + '/assets/'if not os.path.exists(save_path):os.makedirs(save_path)print('\n正在保存图片...\n')num = 0 # 用于记录进度for each in img_list:#以 / 为分隔符,-1返回最后一个值photo_name=each.split("/")[-1]#访问 each,并将页面的二进制数据赋值给photophoto=urllib .request .urlopen(each)w=photo .read()f=open(save_path + photo_name + '.png', 'wb')f.write(w)f.close()# 展示进度print(num % 10, end="")if (num + 1) % 10 == 0 and num != 0:print(' 进度: ' + str(num + 1) + '/' + list_len)sys.stdout.flush() # 刷新输出缓冲num += 1print('\n\n完成!\n')if __name__=='__main__':if len(sys.argv) != 2:print("\nUsage: python spider.py <file>")print('example: python spider.py "F:\\T\\test.md"')sys.exit()file = str(sys.argv[1])file_name = os.path.basename(file)file_path = os.path.dirname(file)print('\nfile_name: ' + file_name)print('file_path: ' + file_path)# 读取文件内容content = read_file(file)# 爬取图片get_img(content, file_path)
效果
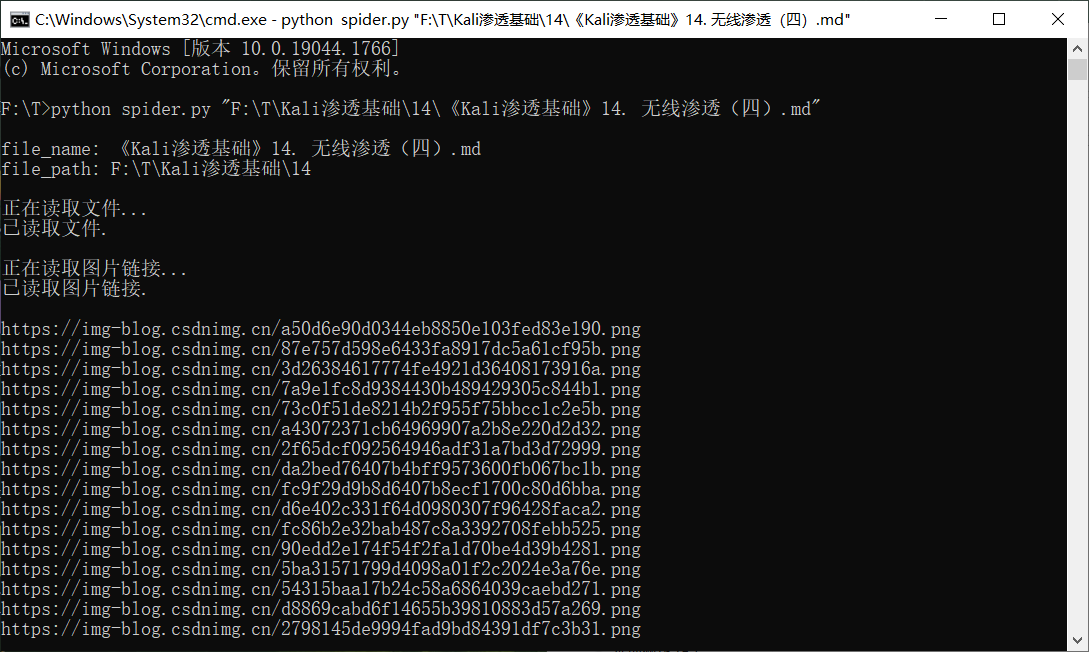
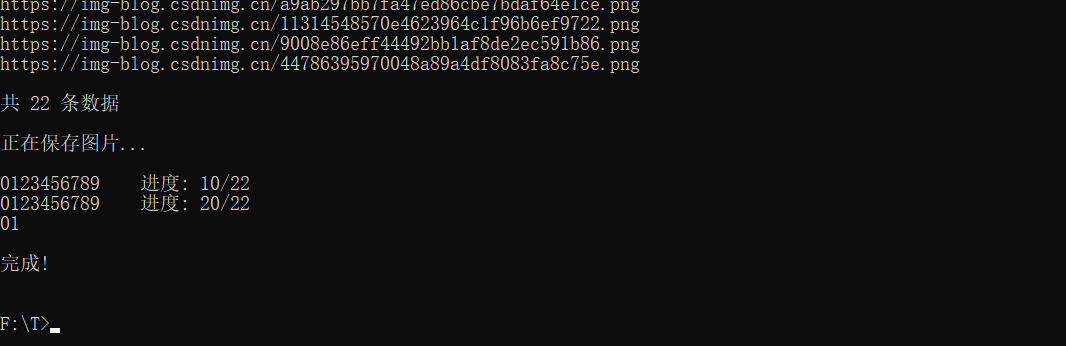
别后相思人似月,云间水上到层城。
——《明月夜留别》(唐)李冶