最近一些前端面试问题整理
- 4月8号
- 1. TS 中的 类型别名 和接口的区别是什么?
- 2. 什么是深拷贝和浅拷贝?深浅拷贝的方法有哪些?
- 浅拷贝(Shallow Copy)
- 深拷贝(Deep Copy)
- 区别总结
- 3. 使用 JSON.stringify 和 JSON.parse 实现深拷贝存在一些局限性和缺点
- 4. React fiber 与生命周期有冲突吗?React 高版本为什么要废弃掉生命周期?
- React Fiber 与生命周期的冲突
- 废弃生命周期的原因
- 新增的生命周期函数
- 结论
- 5. React fiber 重写了 window.requestIdelCallbalk ,可以了解下为什么要重写,用什么写的(用调度器)
- 6. 斐波那契数列
- 递归方法
- 动态规划方法
- 矩阵快速幂方法
4月8号
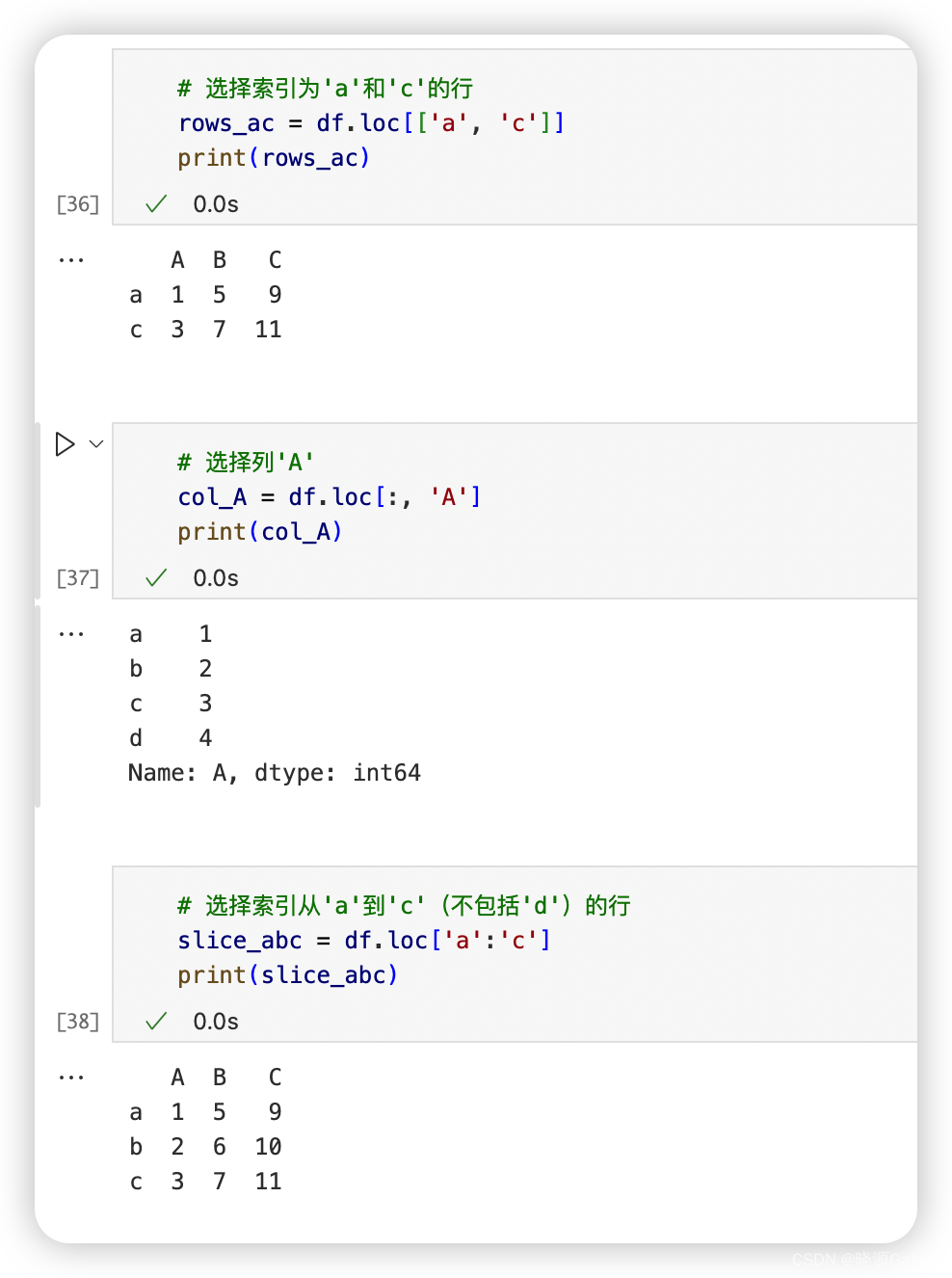
1. TS 中的 类型别名 和接口的区别是什么?
在以往的面向对象语言中,例如Java,接口是一个很重要的概念,它是对行为的抽象,而具体如何行动需要由类去实现。
在TypeScript中,接口(Interfaces)是一个非常灵活的概念,除了可用于对类的一部分行为进行抽象以外,也常用于对「对象的形状(Shape)」进行描述。而类型别名(Type Aliases)也可以用来描述对象的形状或者函数签名,但这二者在使用和特性上有一些区别:
类型别名(Type Aliases)
- 基本用途:类型别名可以用来描述基本类型、联合类型、元组,以及类、接口或任何其他类型的实例。
- 可扩展性:类型别名不支持声明合并,即不能有多个同名的类型别名声明。
- 使用场景:类型别名通常用于描述复杂的联合类型或交叉类型,或者当你需要使用 typeof 获取类型时。
- 灵活性:类型别名可以用于更广泛的类型描述,包括映射类型、条件类型等 高级类型 操作。
接口(Interfaces)
- 基本用途:接口主要用于描述对象的形状,规定了对象必须具备的属性和方法。
- 可扩展性:接口支持声明合并,即可以有多个同名的接口声明,它们会自动合并。
- 使用场景:接口非常适合用于定义对象、函数的参数和返回值的契约。
- 扩展性:接口可以通过继承其他接口来扩展,这有助于建立类型之间的层次结构。
区别总结
- 扩展性:都支持扩展,只不过写法不同。
- 合并:接口支持声明合并,而类型别名不支持。
- 用途:类型别名更加灵活,可以描述更广泛的类型结构,而接口更侧重于对象的形状和类型契约。
- 实现细节:类型别名可以使用 typeof 获取类型,这在某些高级用例中非常有用,如结合使用类和模块时。
在实际开发中,选择使用类型别名还是接口取决于具体的使用场景。有时,为了保持代码的清晰和一致性,开发者可能会选择其中一种方式作为主要的类型描述手段。然而,在许多情况下,类型别名和接口可以并行使用,以满足不同的需求和偏好。
https://blog.csdn.net/imagine_tion/article/details/118686460
2. 什么是深拷贝和浅拷贝?深浅拷贝的方法有哪些?
深拷贝和浅拷贝是编程中用来复制对象的两种不同方法,它们在处理对象及其属性时的行为和结果有所不同。
浅拷贝(Shallow Copy)
浅拷贝创建一个新对象,但是这个新对象的属性指向的是原始对象中属性的引用类型值的引用。换句话说,浅拷贝只是复制了对象的第一层属性,对于嵌套的对象或数组,它不会创建新的实例,而是复制引用。
浅拷贝的方法:
- 使用
Object.assign()方法,它可以将一个或多个源对象的所有可枚举属性复制到目标对象。 - 使用展开运算符
...,它可以在创建新对象或数组时“展开”现有对象或数组的属性。
深拷贝(Deep Copy)
深拷贝会创建一个新对象,并且递归地复制原始对象中所有的属性,包括嵌套的对象和数组。这意味着深拷贝会创建原始对象中所有对象的副本,新对象和原始对象之间不会共享任何引用。
深拷贝的方法:
- 使用
JSON.parse(JSON.stringify(object))方法,这种方法适用于简单的对象结构,不能复制函数、undefined、循环引用等,这个方法还有其他缺点,具体可看下面一个问题。 - 使用
Object.create(null)方法,通过手动复制每个属性来创建一个深拷贝。 - 使用第三方库,如
lodash的_.cloneDeep()方法,它提供了更全面和可靠的深拷贝功能。
区别总结
- 引用:浅拷贝只复制了对象的第一层属性,对于引用类型的属性,新对象和原始对象仍然指向同一个引用。深拷贝会递归地复制所有层级的属性,新对象和原始对象之间没有任何引用关系。
- 性能:浅拷贝通常比深拷贝更快,因为它不需要递归地处理每个属性。
- 适用场景:如果对象没有复杂的嵌套结构,或者你只需要复制对象的顶层结构,浅拷贝可能是一个合适的选择。如果你需要完整复制一个复杂的对象,包括它所有的嵌套对象和数组,那么你应该使用深拷贝。
在实际开发中,选择哪种拷贝方法取决于对象的复杂性和拷贝的需求。理解浅拷贝和深拷贝的区别对于编写可靠和高效的代码非常重要。
3. 使用 JSON.stringify 和 JSON.parse 实现深拷贝存在一些局限性和缺点
-
循环引用问题:如果原始对象中存在循环引用(即一个对象的属性指向自身或其子属性),
JSON.stringify会失败并抛出错误。

-
特殊类型丢失:
JSON.stringify无法序列化函数、undefined、Symbol类型以及循环引用。这些情况下,相应的属性在序列化结果中会被忽略或转换为null。 -
构造函数信息丢失:使用
JSON.parse(JSON.stringify(obj))进行深拷贝后,新对象会丢失原始对象的构造函数信息。这意味着即使你复制了一个由特定构造函数创建的对象,复制品也会被视为Object的实例。 -
日期和正则表达式问题:
Date对象在序列化后会变成它们的 ISO 字符串表示形式,而正则表达式会变成空对象{}。 -
NaN、Infinity 和 -Infinity 问题:这些特殊的数值在序列化时会变成
null。 -
枚举属性问题:
JSON.stringify默认只序列化对象的可枚举属性。如果对象中有非枚举属性,这些属性将不会被包含在序列化的结果中。 -
性能问题:对于大型或复杂的对象,
JSON.stringify和JSON.parse可能会导致性能问题,尤其是在频繁使用时。 -
兼容性问题:尽管
JSON是一个广泛支持的标准,但在某些旧环境或边缘情况下,可能需要额外的处理来确保兼容性。 -
安全问题:由于
JSON.stringify会将对象转换为字符串,如果对象中包含了敏感信息,那么在日志或调试输出中可能会有泄露风险。 -
不支持的结构:某些对象结构,如
Map、Set、WeakMap、WeakSet和DataView等,在序列化时不会被正确处理,通常会被转换为空对象或丢失。
在使用 JSON.stringify 和 JSON.parse 进行深拷贝时,需要考虑到上述缺点,并根据具体情况决定是否使用其他深拷贝方法,如递归复制、使用第三方库(如 Lodash 的 _.cloneDeep 方法)或浏览器提供的 structuredClone 方法(如果兼容)。
提到的
structuredClone方法可参考:https://juejin.cn/post/7193997944171790396
4. React fiber 与生命周期有冲突吗?React 高版本为什么要废弃掉生命周期?
React Fiber 与生命周期函数确实存在一些冲突,特别是在 React 16 及以后的版本中,Fiber 架构的引入导致了一些生命周期函数的废弃。以下是详细解释:
React Fiber 与生命周期的冲突
React Fiber 是一种新的协调算法,它允许 React 将渲染工作分割成多个阶段,从而提高应用的性能和响应性【1】【3】。Fiber 架构的目标是使得组件的渲染可以被中断和恢复,从而更好地处理大型应用和复杂的交互【1】【3】。
废弃生命周期的原因
在 React 16 中,Fiber 架构的引入导致了三个生命周期函数的废弃:componentWillMount、componentWillReceiveProps 和 componentWillUpdate【5】【4】【6】。这些函数在 Fiber 架构中可能会被多次执行,这与它们原有的设计目的相冲突,即它们应该只在组件生命周期的特定时刻执行一次【5】【4】【6】。
componentWillMount被废弃是因为在 Fiber 架构中,组件的挂载可能会被中断和延迟,这意味着componentWillMount可能会被多次调用,这与它的预期行为不符【5】【4】【6】。componentWillReceiveProps存在问题,因为它在处理 props 变化时可能会导致状态的不可预测更新,这与 React 希望的状态管理方式相冲突【5】【4】【6】。componentWillUpdate被废弃是因为在 Fiber 架构中,组件的更新可能会被中断,这使得componentWillUpdate无法保证只在每次更新前执行一次【5】【4】【6】。
新增的生命周期函数
为了解决这些问题,React 引入了两个新的生命周期函数:getDerivedStateFromProps 和 getSnapshotBeforeUpdate【5】【4】【6】。
getDerivedStateFromProps是一个静态方法,它允许开发者在渲染前根据新的 props 和现有的 state 计算出新的 state【5】【4】【6】。getSnapshotBeforeUpdate允许开发者在组件更新 DOM 之前获取最新的 DOM 信息,这可以用于处理像滚动位置这样的场景【5】【4】【6】。
结论
React Fiber 架构的引入是为了提高性能和响应性,但这导致了一些生命周期函数的行为与预期不符。因此,React 团队废弃了一些旧的生命周期函数,并引入了新的生命周期函数来提供更好的状态管理和性能优化【5】【4】【6】。开发者需要根据最新的生命周期函数来更新他们的组件代码,以确保与 React 的最新版本兼容。
https://zhuanlan.zhihu.com/p/424967867
https://juejin.cn/post/7006612306809323533
https://juejin.cn/post/7184747220036485177
https://developer.aliyun.com/article/1312153
https://segmentfault.com/a/1190000021272657
https://www.cnblogs.com/mengff/p/12894886.html
https://juejin.cn/post/6844903518357159949
5. React fiber 重写了 window.requestIdelCallbalk ,可以了解下为什么要重写,用什么写的(用调度器)
React Fiber 重写了 window.requestIdleCallback 的原因是为了更好地控制异步任务的调度,尤其是在浏览器的空闲时间。requestIdleCallback 是一个浏览器 API,允许开发者在浏览器空闲时执行低优先级的任务。然而,这个 API 在不同的浏览器和版本中可能存在兼容性问题,或者在实际使用中的表现可能与预期有所差异。
为了确保 React 应用在各种环境下都能可靠地运行,React Fiber 采用了自定义的调度器来模拟 requestIdleCallback 的行为。React 团队通过创建一个基于 MessageChannel 和 requestAnimationFrame 的调度器来解决这些问题。这个调度器可以在浏览器的主线程上安排任务,同时考虑到浏览器的空闲时间和高优先级的任务。
通过这种方式,React Fiber 能够在保证应用性能的同时,避免依赖可能存在问题的浏览器 API。这种自定义的调度器提供了更一致的行为,使得 React 能够更有效地管理异步渲染任务,尤其是在处理大型或复杂的 UI 更新时。这也有助于提高应用的响应性和用户体验,因为它可以确保即使在资源紧张的情况下,用户交互仍然能够获得及时的响应。
6. 斐波那契数列
斐波那契数列(Fibonacci sequence)是一个非常著名的数列,它在数学、计算机科学以及自然界中都有广泛的应用。斐波那契数列的定义如下:
- 数列的前两个数字是 0 和 1。
- 从第三个数字开始,每个数字都是前两个数字的和。
用数学公式表示,斐波那契数列可以写成:
F(0) = 0, F(1) = 1, F(n) = F(n-1) + F(n-2) 对于 n > 1
斐波那契数列的前几个数字是:
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, …
在计算机科学中,斐波那契数列通常是算法和编程问题的一个经典例子。计算斐波那契数列的值可以通过递归、动态规划、矩阵快速幂等多种方法实现。
递归方法
递归方法是最直接的实现方式,但它的时间复杂度是指数级的,因为它重复计算了很多子问题。
function fibonacci(n) {if (n <= 0) return 0;if (n === 1) return 1;return fibonacci(n - 1) + fibonacci(n - 2);
}
动态规划方法
动态规划方法通过迭代计算斐波那契数列的值,并存储已计算的结果,避免了重复计算,时间复杂度为 O(n)。
function fibonacci(n) {let fib = [0, 1];for (let i = 2; i <= n; i++) {fib[i] = fib[i - 1] + fib[i - 2];}return fib[n];
}
矩阵快速幂方法
矩阵快速幂方法可以进一步优化斐波那契数列的计算,将时间复杂度降低到 O(log n)。
function matrixMultiply(a, b) {let c = [[0, 0], [0, 0]];for (let i = 0; i < 2; i++) {for (let j = 0; j < 2; j++) {for (let k = 0; k < 2; k++) {c[i][j] += a[i][k] * b[k][j];}}}return c;
}function fibonacci(n) {let result = [[1, 1], [1, 0]];let power = [[1, 0], [0, 1]];while (n > 0) {if (n % 2 === 1) {result = matrixMultiply(result, power);}power = matrixMultiply(power, power);n = Math.floor(n / 2);}return result[0][0];
}
斐波那契数列不仅在数学上有着丰富的性质,而且在计算机科学中也是算法设计和性能分析的重要工具。通过学习和实现斐波那契数列的不同计算方法,可以加深对算法复杂度和优化策略的理解。