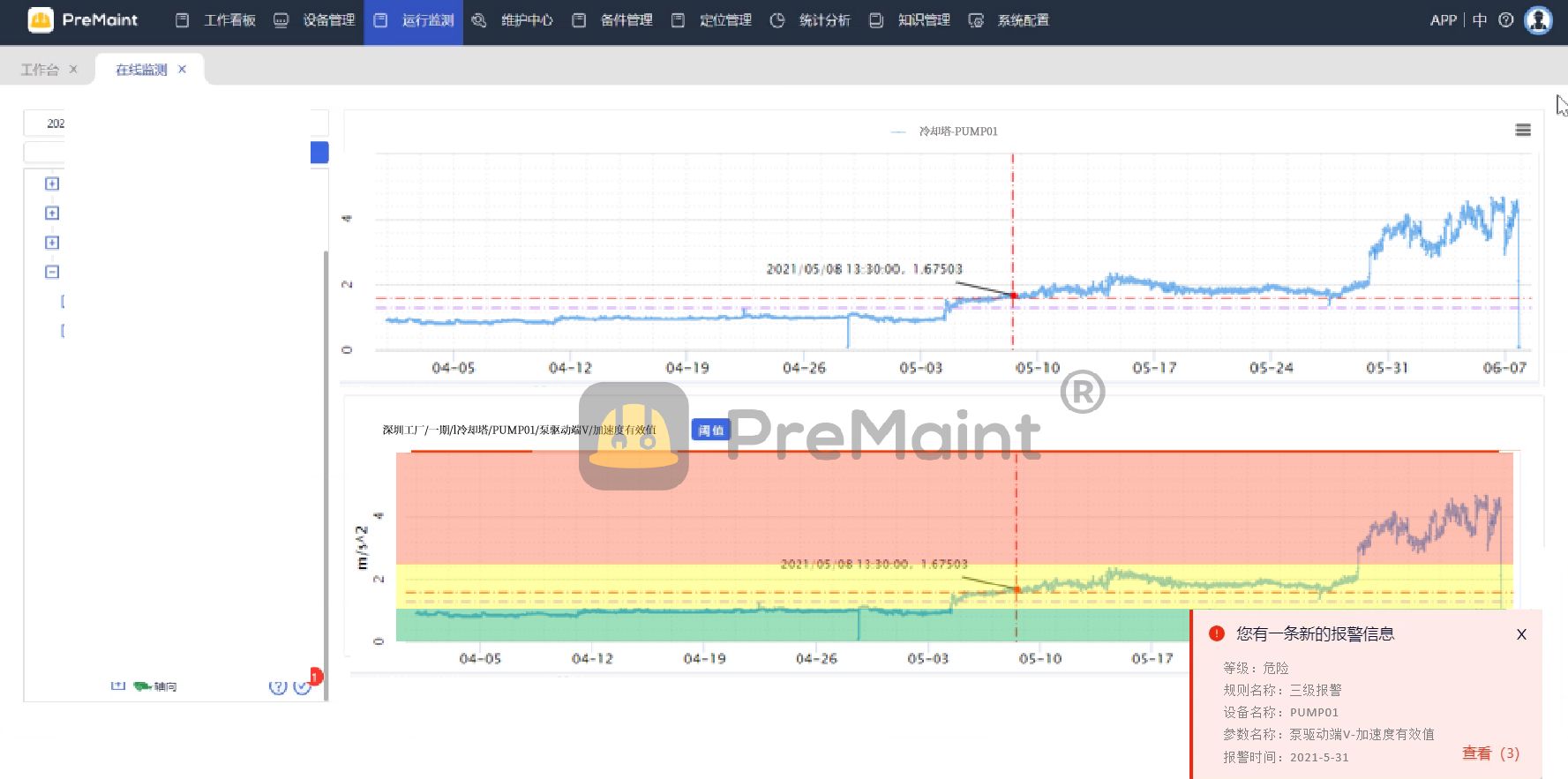
1. 准备工作
使用python语言可以快速实现,调用BeautifulSoup包里面的方法
安装BeautifulSoup
pip install BeautifulSoup
完成以后引入项目
2. 开发
定义url
url = 'https://s.微博.com/top/summary?cate=realtimehot'定义请求头,微博请求数据需要cookie,设置自己的cookie
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Mobile Safari/537.36','Host': 's.weibo.com','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'zh-CN,zh-Hans;q=0.9','Accept-Encoding': 'gzip, deflate, br',# 定期更换Cookie'Cookie': '你的cookie'
}cookie查看

分析数据结构,找到标签值
items = soup.find('section', {'class': 'list'})爬取的数据都是列表,定义好需要的列表list,循环标签值
href_list = []text_list = []order_list = []type_list = []view_count_list = []for li in items.find_all('li'):# 链接地址order = li.find('strong')if order == None:continuehref = li.find('a').get('href')href_list.append('https://s.weibo.com' + href)la = li.find('i')order_list.append(order.get_text())text = li.find('span').get_text()view_count = li.find('span').find('em').get_text()view_count_list.append(view_count)text1 = text.replace(view_count, '')text_list.append(text1)if la:type = trans_icon((la.get('class')[1]))else:type = trans_icon('')type_list.append(type)
中间有个热搜类别转换方法
def trans_icon(v_str):"""转换热搜类别"""if v_str == 'icon_new':return '新'elif v_str == 'icon_hot':return '热'elif v_str == 'icon_boil':return '沸'elif v_str == 'icon_recommend':return '商'else:return '未知'
最后把抓取的数据存到xlsx
df = pd.DataFrame(data)df.to_excel('C:\\Users\\Administrator\\Desktop\\微博热搜榜.xlsx', index=False) # 保存结果数据
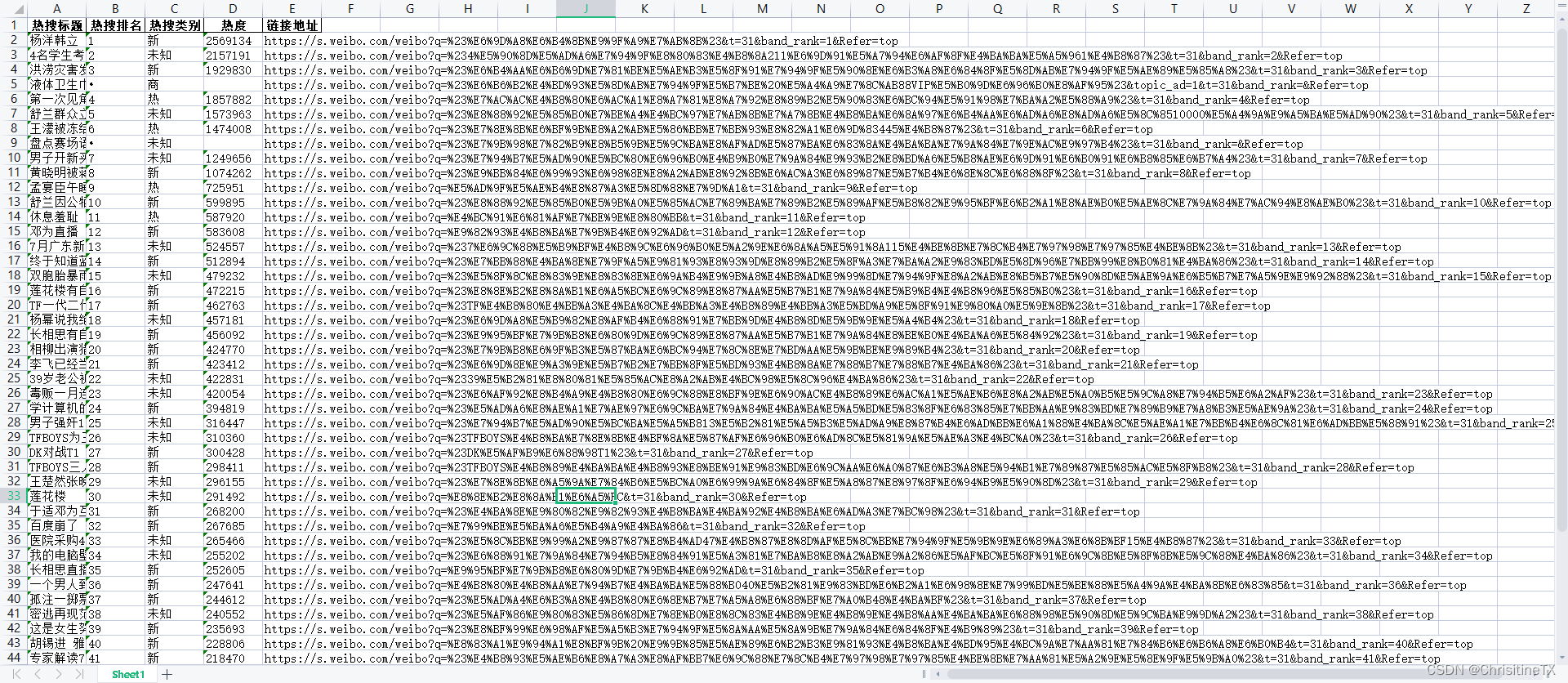
3. 效果