说明
本文是北京邮电大学的硕士毕业论文,作者是郭梦婷。由于是艺术硕士,所以本文没有罗列很多公式,而是从动画创作的角度来写如何根据语音设计动画人物的嘴型及表情。本文作者行文缜密、轻松,举得例子都是一些热播的动画和电影,让我这个外行看着也很轻松。
视位设计
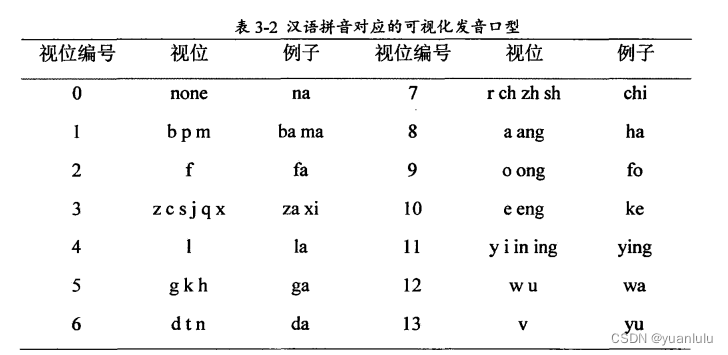
本文的衍生的成品不是一个软件,而是一段动画,而且是根据已有的语音来设计嘴型动画,作者根据汉语的发声特点设计了14种静态视位。这些视位对应的形状如下:

音素和视位的对应关系:
汉语的协同发音
语音具有多变性,不管是哪种语言在自然话语中都不是各个音素或者音节之间不是孤立的,也不是简单机械的排列,这些语音单元都是按照一定变化和组合构成的有机系统,这就是协同发音。
根据对汉语连续语音的发音特点的分析,音素与音素之间的过渡音段对其口型的影响在白然唇部动画合成中起重要作用。一般情况下,人讲话的语速为每分钟160到180个汉字左右,每个音节的发音大约在0.5秒,从音节的开始到结束基本用1-3个视位即可描述清晰,过多的口型反而使得唇形动画杂乱、着急,给观者带来糟糕的体验,根据汉语协同发音现象进行总结,连贯汉语语音流中一般呈现如下的规律:


根据音素之间互相影响的规律,按照容易被影响的程度将汉语声母、韵母进行等级的划分,越高级表示越不容易受到影响,如表3-3所示,表3-4所示。根据表格显示的等级,高等级的韵母更不容易受到低等级韵母的影响,高等级的韵母更容易对低等级的韵母、声母产生影响。

本文的其它亮点
本文有两处概述章节写的很不错,一处是“表情迁移技术”,一处是“MPEG4人脸参数”。读起来通俗易懂,又不失严谨。
可惜作者是艺术学院的,不是计算机相关专业,最终只是形成了一个给人看的做动画的技能指南,而不是一个自动化的软件工具。