〇、背景:
项目需要,需要利用摄像头对人手进行实时监测,最先考虑到的就是简单易用且高效的YOLOv5,很快找到了公开数据集:Egohands
EgoHands: A Dataset for Hands in Complex Egocentric Interactions | IU Computer Vision Lab
一、Egohands介绍:
EgoHands 数据集包含 48 个 Google Glass 视频,内容涉及两个人之间复杂的第一人称交互。该数据集的主要目的是提供更好的数据驱动方法来理解第一人称计算机视觉中的手。
我下载使用的是[Labeled Data]这个数据集,该存档包含所有带标签的帧,格式为 JPEG 文件 (720x1280px)。 48 个视频中的每个视频都有 100 个标记帧,总共 4,800 个帧。真实标签由每种手型的像素级掩码组成,并以 Matlab 文件形式提供。
由于数据集是用于MATLAB的,所以需要将其转化为YOLOv5可用。
二、数据集转化:
下面的程序主要用于参考,具体使用时需要根据自己情况进行修改。
1,使用程序自动下载、解压并归档数据集
import scipy.io as sio
import numpy as np
import os
import gc
import six.moves.urllib as urllib
import cv2
import time
import xml.etree.cElementTree as ET
import random
import shutil as sh
from shutil import copyfile
import zipfileimport csvdef save_csv(csv_path, csv_content):with open(csv_path, 'w') as csvfile:wr = csv.writer(csvfile)for i in range(len(csv_content)):wr.writerow(csv_content[i])def get_bbox_visualize(base_path, dir):image_path_array = []for root, dirs, filenames in os.walk(base_path + dir):for f in filenames:if(f.split(".")[1] == "jpg"):img_path = base_path + dir + "/" + fimage_path_array.append(img_path)#sort image_path_array to ensure its in the low to high order expected in polygon.matimage_path_array.sort()boxes = sio.loadmat(base_path + dir + "/polygons.mat")# there are 100 of these per folder in the egohands datasetpolygons = boxes["polygons"][0]# first = polygons[0]# print(len(first))pointindex = 0for first in polygons:index = 0font = cv2.FONT_HERSHEY_SIMPLEXimg_id = image_path_array[pointindex]img = cv2.imread(img_id)img_params = {}img_params["width"] = np.size(img, 1)img_params["height"] = np.size(img, 0)head, tail = os.path.split(img_id)img_params["filename"] = tailimg_params["path"] = os.path.abspath(img_id)img_params["type"] = "train"pointindex += 1boxarray = []csvholder = []for pointlist in first:pst = np.empty((0, 2), int)max_x = max_y = min_x = min_y = height = width = 0findex = 0for point in pointlist:if(len(point) == 2):x = int(point[0])y = int(point[1])if(findex == 0):min_x = xmin_y = yfindex += 1max_x = x if (x > max_x) else max_xmin_x = x if (x < min_x) else min_xmax_y = y if (y > max_y) else max_ymin_y = y if (y < min_y) else min_y# print(index, "====", len(point))appeno = np.array([[x, y]])pst = np.append(pst, appeno, axis=0)cv2.putText(img, ".", (x, y), font, 0.7,(255, 255, 255), 2, cv2.LINE_AA)hold = {}hold['minx'] = min_xhold['miny'] = min_yhold['maxx'] = max_xhold['maxy'] = max_yif (min_x > 0 and min_y > 0 and max_x > 0 and max_y > 0):boxarray.append(hold)labelrow = [tail,np.size(img, 1), np.size(img, 0), "hand", min_x, min_y, max_x, max_y]csvholder.append(labelrow)cv2.polylines(img, [pst], True, (0, 255, 255), 1)cv2.rectangle(img, (min_x, max_y),(max_x, min_y), (0, 255, 0), 1)csv_path = img_id.split(".")[0]if not os.path.exists(csv_path + ".csv"):cv2.putText(img, "DIR : " + dir + " - " + tail, (20, 50),cv2.FONT_HERSHEY_SIMPLEX, 0.75, (77, 255, 9), 2)cv2.imshow('Verifying annotation ', img)save_csv(csv_path + ".csv", csvholder)print("===== saving csv file for ", tail)cv2.waitKey(2) # close window when a key press is detecteddef create_directory(dir_path):if not os.path.exists(dir_path):os.makedirs(dir_path)# combine all individual csv files for each image into a single csv file per folder.def generate_label_files(image_dir):header = ['filename', 'width', 'height','class', 'xmin', 'ymin', 'xmax', 'ymax']for root, dirs, filenames in os.walk(image_dir):for dir in dirs:csvholder = []csvholder.append(header)loop_index = 0for f in os.listdir(image_dir + dir):if(f.split(".")[1] == "csv"):loop_index += 1#print(loop_index, f)csv_file = open(image_dir + dir + "/" + f, 'r')reader = csv.reader(csv_file)for row in reader:csvholder.append(row)csv_file.close()os.remove(image_dir + dir + "/" + f)save_csv(image_dir + dir + "/" + dir + "_labels.csv", csvholder)print("Saved label csv for ", dir, image_dir +dir + "/" + dir + "_labels.csv")# Split data, copy to train/test folders
def split_data_test_eval_train(image_dir):create_directory("images")create_directory("images/train")create_directory("images/test")data_size = 4000loop_index = 0data_sampsize = int(0.1 * data_size)test_samp_array = random.sample(range(data_size), k=data_sampsize)for root, dirs, filenames in os.walk(image_dir):for dir in dirs:for f in os.listdir(image_dir + dir):if(f.split(".")[1] == "jpg"):loop_index += 1print(loop_index, f)if loop_index in test_samp_array:os.rename(image_dir + dir +"/" + f, "images/test/" + f)os.rename(image_dir + dir +"/" + f.split(".")[0] + ".csv", "images/test/" + f.split(".")[0] + ".csv")else:os.rename(image_dir + dir +"/" + f, "images/train/" + f)os.rename(image_dir + dir +"/" + f.split(".")[0] + ".csv", "images/train/" + f.split(".")[0] + ".csv")print(loop_index, image_dir + f)print("> done scanning director ", dir)os.remove(image_dir + dir + "/polygons.mat")os.rmdir(image_dir + dir)print("Train/test content generation complete!")generate_label_files("images/")def generate_csv_files(image_dir):for root, dirs, filenames in os.walk(image_dir):for dir in dirs:get_bbox_visualize(image_dir, dir)print("CSV generation complete!\nGenerating train/test/eval folders")split_data_test_eval_train("egohands/_LABELLED_SAMPLES/")# rename image files so we can have them all in a train/test/eval folder.
def rename_files(image_dir):print("Renaming files")loop_index = 0for root, dirs, filenames in os.walk(image_dir):for dir in dirs:for f in os.listdir(image_dir + dir):if (dir not in f):if(f.split(".")[1] == "jpg"):loop_index += 1os.rename(image_dir + dir +"/" + f, image_dir + dir +"/" + dir + "_" + f)else:breakgenerate_csv_files("egohands/_LABELLED_SAMPLES/")def extract_folder(dataset_path):print("Egohands dataset already downloaded.\nGenerating CSV files")if not os.path.exists("egohands"):zip_ref = zipfile.ZipFile(dataset_path, 'r')print("> Extracting Dataset files")zip_ref.extractall("egohands")print("> Extraction complete")zip_ref.close()rename_files("egohands/_LABELLED_SAMPLES/")def download_egohands_dataset(dataset_url, dataset_path):is_downloaded = os.path.exists(dataset_path)if not is_downloaded:print("> downloading egohands dataset. This may take a while (1.3GB, say 3-5mins). Coffee break?")opener = urllib.request.URLopener()opener.retrieve(dataset_url, dataset_path)print("> download complete")extract_folder(dataset_path);else:extract_folder(dataset_path)EGOHANDS_DATASET_URL = "http://vision.soic.indiana.edu/egohands_files/egohands_data.zip"
EGO_HANDS_FILE = "egohands_data.zip"download_egohands_dataset(EGOHANDS_DATASET_URL, EGO_HANDS_FILE)
在data_deal文件夹中,train_labels.csv与test_labels.csv是解压后的标注文件,下面需要针对csv文件进行转化
2,csv文件转为txt文件
#-*- coding:utf-8
import pandas as pd
import ospath_dir = './'
# csvPath = path_dir + 'train_labels.csv'
csvPath = path_dir + 'test_labels.csv'
if not os.path.exists(csvPath):print('Not that files:%s'%csvPath)# txtPath = path_dir+'train_labels.txt'
txtPath = path_dir+'test_labels.txt'
data = pd.read_csv(csvPath, encoding='utf-8')with open(txtPath,'a+', encoding='utf-8') as f:for line in data.values:f.write((str(line[0])+'\t'+str(line[1])+','+str(line[2])+'\t'+str(line[4])+','+str(line[5])+','+str(line[6])+','+str(line[7])+'\t'+str(line[3])+'\n'))
转换完成后形成两个txt文件,下一步需要将txt文件进行拆分
3,拆分txt文件
import ostxt_path='./train_txt/'
with open('./train_labels.txt') as f:lines=f.readlines()for line in lines:line=line.strip()words=line.split('\t')file_name=words[0]img_size=words[1]coordinate=words[2]label=words[3]with open(txt_path+file_name[:-3]+'txt','a') as f1:f1.write(coordinate+','+label+'\n')
拆分完成后,在两个文件夹中会生成对应的txt标签文件,但目前的格式还不是YOLOv5需要的格式,还需要进行进一步转换
4,转换txt文件
import osinput_folder = "./labels/train/" # 替换为包含 txt 文件的文件夹路径
output_folder = "./labels_yolo/train/" # 替换为输出转换后标签的文件夹路径image_width = 1280
image_height = 720if not os.path.exists(output_folder):os.makedirs(output_folder)for filename in os.listdir(input_folder):if filename.endswith(".txt"):with open(os.path.join(input_folder, filename), "r") as input_file:lines = input_file.readlines()output_lines = []for line in lines:xmin, ymin, xmax, ymax, class_name = line.strip().split(",")center_x = (int(xmin) + int(xmax)) / (2.0 * image_width)center_y = (int(ymin) + int(ymax)) / (2.0 * image_height)width = (int(xmax) - int(xmin)) / image_widthheight = (int(ymax) - int(ymin)) / image_heightyolo_line = f"0 {center_x:.6f} {center_y:.6f} {width:.6f} {height:.6f}"output_lines.append(yolo_line)output_filename = os.path.join(output_folder, filename)with open(output_filename, "w") as output_file:output_file.write("\n".join(output_lines))
至此,转换步骤结束,我们已经得到了完整的4800个图像和对应的txt标签,然后用于训练即可
三、YOLOv5训练
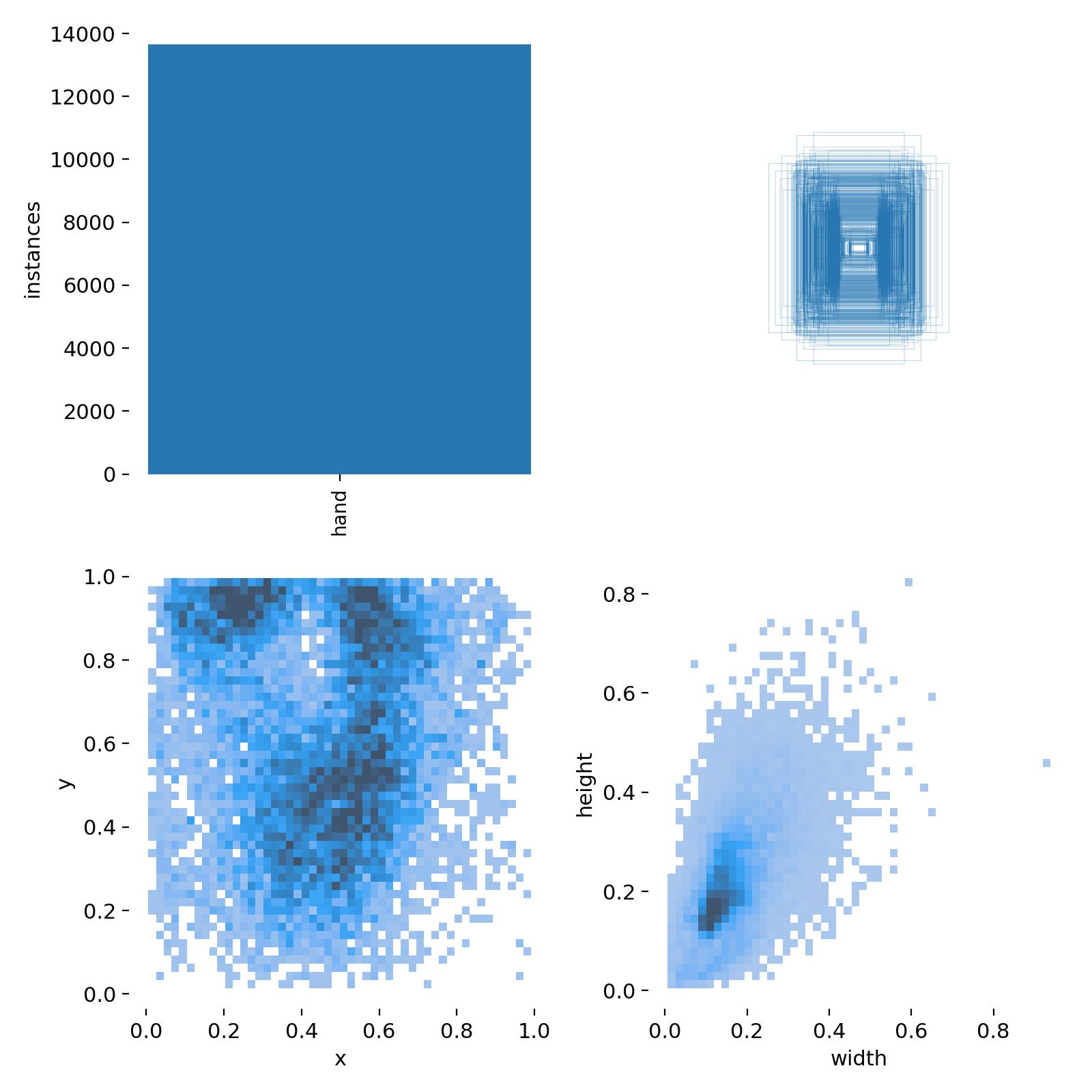
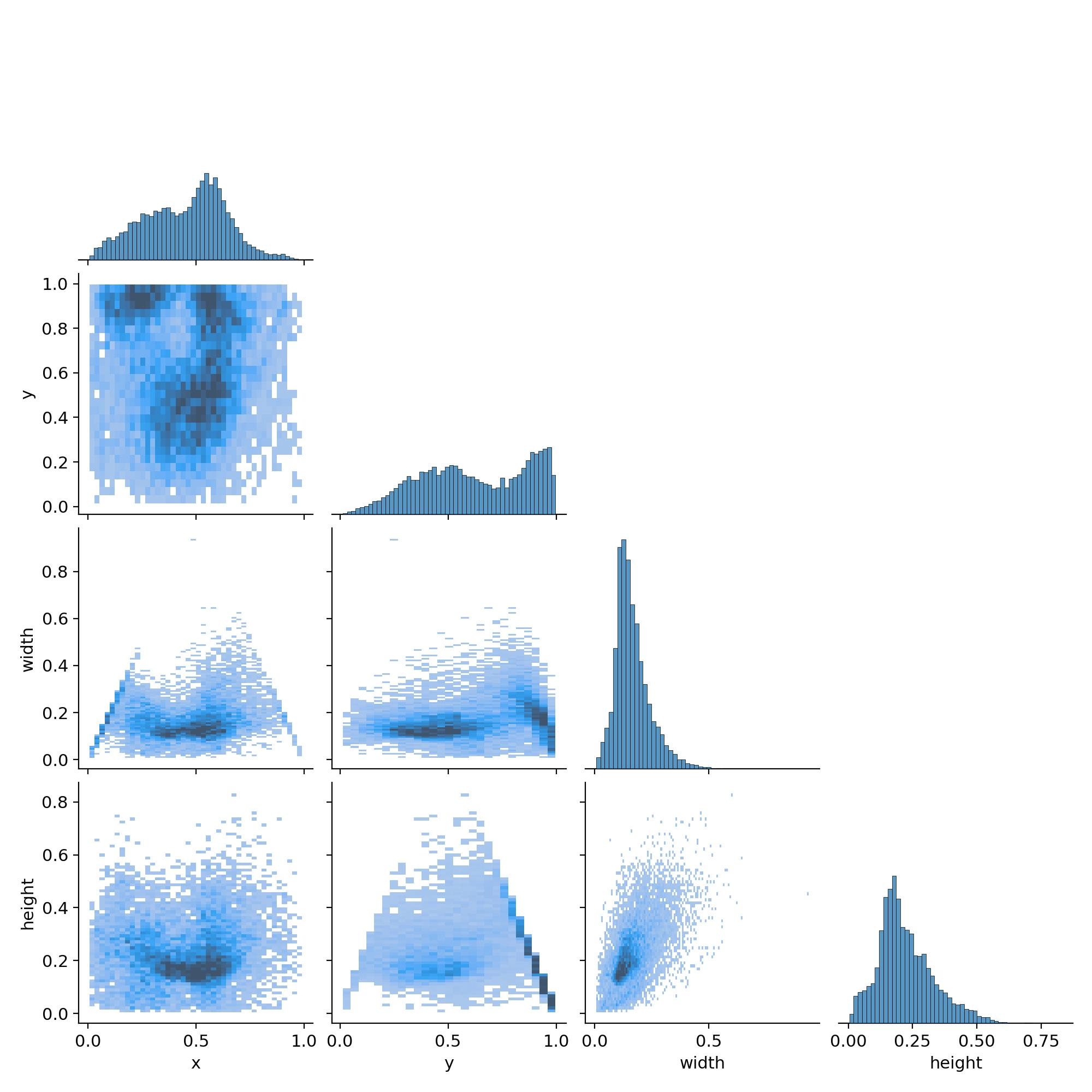
放着服务器不用,我拿闲置的2060跑了半宿,得到结果如下




四、直接下载修改好的数据集、标签和训练好的模型文件
我本来,想上传到CSDN资源里的,但我的压缩包1.3GB,CSDN最大只能上传1GB的文件,那这波积分是骗不到了,下面是123盘和百度网盘的链接,需要的朋友自取吧:
123云盘:https://www.123pan.com/s/wTqA-j00ph.html
提取码:oBH3百度网盘: https://pan.baidu.com/s/1wT8K4xTutfqE3WXLanAxiA?pwd=nmdj
提取码: nmdj