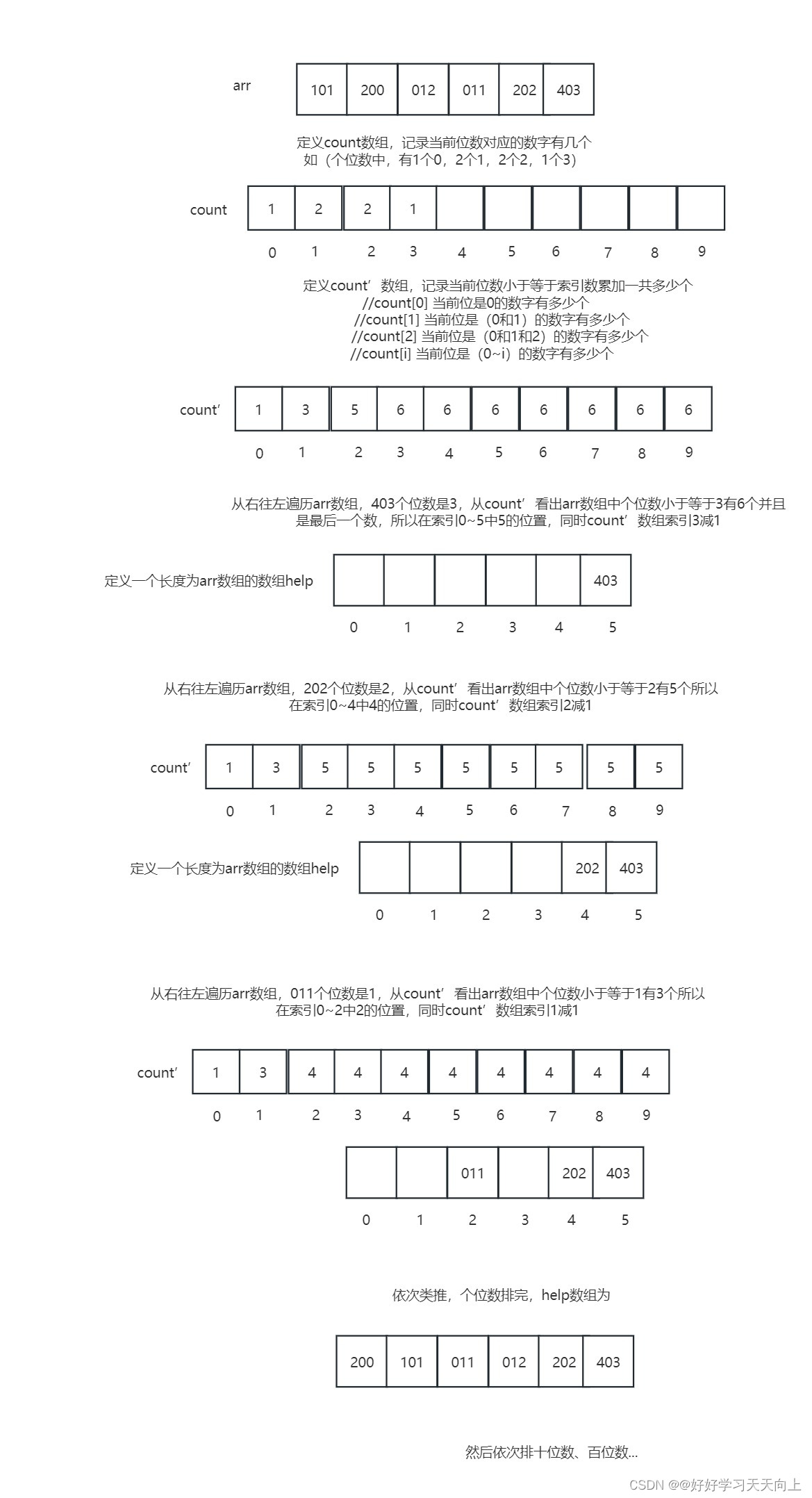
文章目录
- 前言
- 调整 Spark 默认配置
- 查看和设置 Spark 配置信息
- 动态扩展集群负载
- 数据的缓存和持久化
- DataFrame.cache()
- DataFrame.persist()
- 何时缓存和持久化
- 何时不缓存和持久化
- Spark 中的 JOINs
- 广播连接
- 排序合并连接
- 总结
前言
本文总结了 Spark 中比较重要和常用的调优手段,包括设置并优化 Spark 程序的默认配置,来改进大型任务的工作负载和并行度,从而减少 Spark executor 内存不足的问题。以及如何使用适当的缓存和持久化策略来增加对常用数据集的访问速度。还有说明了在操作复杂聚合时常用的两种连接方式,以及如何设置合理的排序键来进行分桶,尽量减少 shuffle 操作等优化手段。
调整 Spark 默认配置
Spark 的官方的配置官方的配置内容很多,以及对应的官方配置调优建议也很多,这里只说明部分常见和重要的调优配置策略。
查看和设置 Spark 配置信息
有三种获取当前 Spark 集群的配置信息,第一种方式是在$SPARK_HOME目录下查看对应配置文件:_conf/spark-defaults.conf.template_、_conf/log4j.properties.template_和_conf/spark-env.sh.template_
注意:这将修改整个集群的配置,需要小心
第二种方式是在通过 spark-submit 提交 Spark 应用程序本身时指定配置参数,该方法不会影响整个集群。
spark-submit --conf spark.sql.shuffle.partitions=5 --conf
"spark.executor.memory=2g" --class main.scala.chapter7.SparkConfig_7_1 jars/main-
scala-chapter7_2.12-1.0.jar
或者是在程序中指定配置:
// In Scala
import org.apache.spark.sql.SparkSessiondef printConfigs(session: SparkSession) = {// Get confval mconf = session.conf.getAll// Print themfor (k <- mconf.keySet) { println(s"${k} -> ${mconf(k)}\n") }
}def main(args: Array[String]) {// Create a sessionval spark = SparkSession.builder.config("spark.sql.shuffle.partitions", 5).config("spark.executor.memory", "2g").master("local[*]").appName("SparkConfig").getOrCreate()printConfigs(spark)spark.conf.set("spark.sql.shuffle.partitions",spark.sparkContext.defaultParallelism)println(" ****** Setting Shuffle Partitions to Default Parallelism")printConfigs(spark)
}spark.driver.host -> 10.8.154.34
spark.driver.port -> 55243
spark.app.name -> SparkConfig
spark.executor.id -> driver
spark.master -> local[*]
spark.executor.memory -> 2g
spark.app.id -> local-1580162894307
spark.sql.shuffle.partitions -> 5
第三种是在 shell 交互中查看并设置配置信息:
// In Scala
// mconf is a Map[String, String]
scala> val mconf = spark.conf.getAll
...
scala> for (k <- mconf.keySet) { println(s"${k} -> ${mconf(k)}\n") }spark.driver.host -> 10.13.200.101
spark.driver.port -> 65204
spark.repl.class.uri -> spark://10.13.200.101:65204/classes
spark.jars ->
spark.repl.class.outputDir -> /private/var/folders/jz/qg062ynx5v39wwmfxmph5nn...
spark.app.name -> Spark shell
spark.submit.pyFiles ->
spark.ui.showConsoleProgress -> true
spark.executor.id -> driver
spark.submit.deployMode -> client
spark.master -> local[*]
spark.home -> /Users/julesdamji/spark/spark-3.0.0-preview2-bin-hadoop2.7
spark.sql.catalogImplementation -> hive
spark.app.id -> local-1580144503745
还可以通过 Spark SQL 查询:
# In Python
spark.sql("SET -v").select("key", "value").show(n=5, truncate=False)+------------------------------------------------------------+-----------+
|key |value |
+------------------------------------------------------------+-----------+
|spark.sql.adaptive.enabled |false |
|spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin |0.2 |
|spark.sql.adaptive.shuffle.fetchShuffleBlocksInBatch.enabled|true |
|spark.sql.adaptive.shuffle.localShuffleReader.enabled |true |
|spark.sql.adaptive.shuffle.maxNumPostShufflePartitions |<undefined>|
+------------------------------------------------------------+-----------+
only showing top 5 rows
或者在 web 界面查看: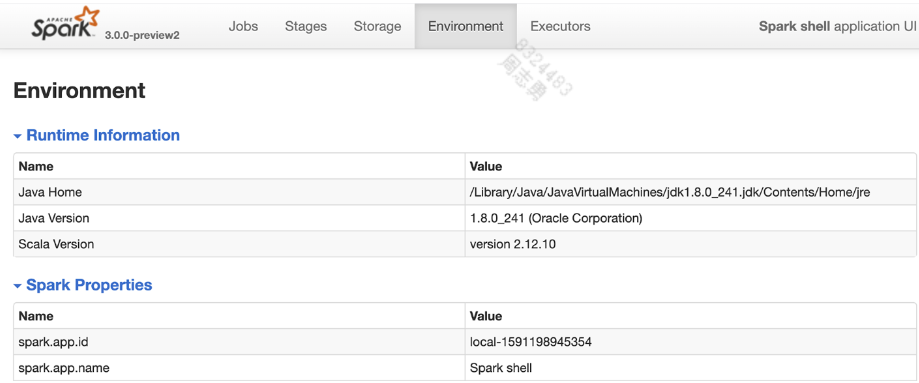
动态扩展集群负载
静态与动态资源分配
如果在提交任务的时候通过配置限定了使用的资源,集群有时候会因为任务所需资源大于预期限定,导致任务在队列中排队,会导致任务挤压,导致后续需要更多的资源运行任务。
如果说在配置中指定了动态资源分配配置,那么Spark 会根据任务来计算所需资源,动态分配,这有利于大量任务峰值的时候。
动态分配资源配置:
# 开启动态分配
spark.dynamicAllocation.enabled true
# driver 会请求集群最少创建两个 executor
spark.dynamicAllocation.minExecutors 2
# 任务队列中的任务积压超过 1m driver 就会请求 executor 执行该任务
spark.dynamicAllocation.schedulerBacklogTimeout 1m
# driver 最多请求 20 个 executor 来执行积压的任务
spark.dynamicAllocation.maxExecutors 20
# 如果 executor 执行完积压任务并且 2m 内没有新的积压任务就终止该 executor
spark.dynamicAllocation.executorIdleTimeout 2min
配置 Spark executor 的内存和 shuffle 服务
仅仅动态分配资源是不够的,我们还需要知道 Spark 是如何分配和使用内存的,以便程序不收 JVM 垃圾回收的影响。
每个 executor 的内存分为三部分:
- 执行内存:去除保留内存后,默认分配剩下的60%,执行内存用于 shuffles, joins, sorts, 和 aggregations 操作。
- 存储内存:去除保留内存后,默认分配剩下的40%,存储内存主要保存 DataFrame 生成的数据结构和 partitions。
- 预留内存:默认保留 300M,防止 OOM
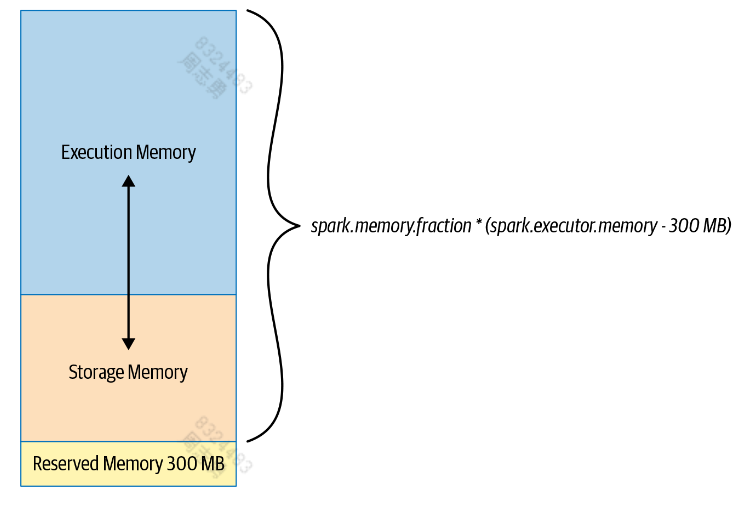
Spark 的默认内存分配适用于大部分情况,一般无需修改,但是如果作业存在大量 map 和 shuffle,Spark 会读取本地磁盘的 shuffle 文件 ,如果内存不足,会存在大量的 I/O 操作,造成瓶颈。这个时候默认配置就不再是最佳的配置了,需要根据具体的情况调整。
下边是建议调整的一些配置参数,但是要根据实际环境不断调整至最佳:
| 配置 | 默认值、建议和说明 | |
|---|---|---|
| spark.driver.memory | 默认值为1g(1 GB)。这是分配给 Spark driver 用于从executor 接收数据的内存量。可以在提交任务时通过–driver-memory 指定。 仅当希望executor 从该操作接收大量数据collect(),或者内executor 内存不足时,才更改此设置。 | |
| spark.shuffle.file.buffer | 默认值为 32 KB。建议为 1 MB。这允许 Spark 在将最终映射结果写入磁盘之前进行更多缓冲。 | |
| spark.file.transferTo | 默认为true.设置为false将强制 Spark 在最终写入磁盘之前使用文件缓冲区来传输文件;这将减少 I/O 活动。 | |
| spark.shuffle.unsafe.file.output.buffer | 默认值为 32 KB。指定shuffle 期间合并文件用到的内存大小。一般来说,较大的值(例如 1 MB)更适合较大的工作负载,而默认值则适用于较小的工作负载。 | |
| spark.io.compression.lz4.blockSize | 默认值为 32 KB。增加到 512 KB。可以通过增加块的压缩大小来减小shuffle 文件的大小。 | |
| spark.shuffle.service.index.cache.size | 默认值为 100m。指定shuffle 的最大内存。 | |
| spark.shuffle.registration.timeout | 默认值为 5000 毫秒。增加到 120000 毫秒。 | |
| spark.shuffle.registration.maxAttempts | 默认值为 3。如果需要,可增加到 5。 |
最大化 Spark 并行度
对于大的任务,Spark 会将任务拆分为多个 stage,每个 stage 内都会有多个任务。Spark 最多会为每个任务分配一个线程,去处理不同分区的数据。
为了充分利用资源,就最好保证分区数量最少和 executor 上的 core 数量一致,理想情况是一样多,这样既不会保证资源浪费,有保证每个任务都会执行。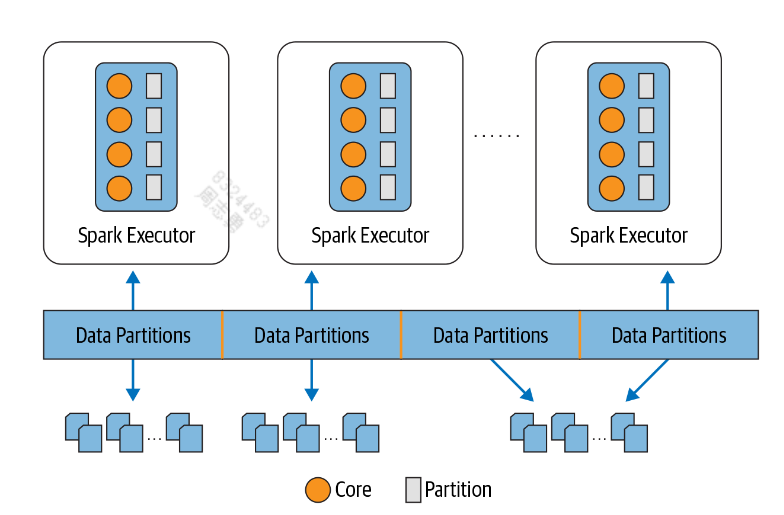
分区是如何创建的
如前所述,Spark 的任务将数据处理为分区从磁盘读入内存。磁盘上的数据以块或连续文件块的形式排列,具体取决于存储。默认情况下,数据存储上的文件块的大小范围为 64 MB 到 128 MB。例如,在 HDFS 和 S3 上,默认大小为 128 MB(这是可配置的)。这些块的连续集合构成一个分区。
可以通过配置spark.sql.files.maxPartitionBytes来减小分区大小,但是可能会随着分区大小的减小,导致过多小文件生成的问题——许多小分区文件,由于打开、关闭和列出等文件系统操作而引入过多的磁盘 I/O 和性能下降目录,在分布式文件系统上可能会很慢。
程序中指定分区数量:
// In Scala
val ds = spark.read.textFile("../README.md").repartition(16)
ds: org.apache.spark.sql.Dataset[String] = [value: string]ds.rdd.getNumPartitions
res5: Int = 16val numDF = spark.range(1000L * 1000 * 1000).repartition(16)
numDF.rdd.getNumPartitionsnumDF: org.apache.spark.sql.Dataset[Long] = [id: bigint]
res12: Int = 16
最后通过配置spark.sql.shuffle.partitions指定 shuffle 分区的数量,默认情况下是200。
说明:当任务数据量下,或者 executor 上的 core 数量少,默认值可能太大,可以适当调小
shuffle 是在 groupBy()或者 join()等宽转换操时发生的,shuffle 会将内存中的数据持久化至本地磁盘,它会消耗网络和磁盘 I/O 资源。
数据的缓存和持久化
对于使用频率高的 DataFrame 和表,将其缓存,有利于提高任务运行效率。
DataFrame.cache()
// In Scala
// Create a DataFrame with 10M records
val df = spark.range(1 * 10000000).toDF("id").withColumn("square", $"id" * $"id")
df.cache() // Cache the data
df.count() // Materialize the cacheres3: Long = 10000000
Command took 5.11 secondsdf.count() // Now get it from the cache
res4: Long = 10000000
Command took 0.44 seconds
第一个count()实现缓存,而第二个访问缓存,导致该数据集的访问时间快了近 12 倍。
注意:
在使用cache() 或者 persist()时,不会完全缓存整个 DataFrame,只会缓存使用到的记录,比如 take(1), 则会缓存一个分区。
DataFrame.persist()
// In Scala
import org.apache.spark.storage.StorageLevel// Create a DataFrame with 10M records
val df = spark.range(1 * 10000000).toDF("id").withColumn("square", $"id" * $"id")
df.persist(StorageLevel.DISK_ONLY) // Serialize the data and cache it on disk
df.count() // Materialize the cacheres2: Long = 10000000
Command took 2.08 secondsdf.count() // Now get it from the cache
res3: Long = 10000000
Command took 0.38 seconds
取消持久化只需调用Dataframe.unpersist()即可。
我们可以从缓存的 Dataframe 创建缓存表:
// In Scala
df.createOrReplaceTempView("dfTable")
spark.sql("CACHE TABLE dfTable")
spark.sql("SELECT count(*) FROM dfTable").show()+--------+
|count(1)|
+--------+
|10000000|
+--------+Command took 0.56 seconds
何时缓存和持久化
缓存的常见用例是需要重复访问大型数据集以进行查询或转换的场景,比如:
- 迭代机器学习训练期间常用的 DataFrame
- 在 ETL 或构建数据管道期间进行频繁转换时访问的 DataFrame
何时不缓存和持久化
并非所有用例都规定需要缓存:
- DataFrame 太大而无法放入内存
- 转换开销小,不关心大小,不会频繁使用的 DataFrame
Spark 中的 JOINs
与关系数据库类似,Spark DataFrame 和 Dataset API 以及 Spark SQL 提供了一系列连接转换:内连接、外连接、左连接、右连接等。所有这些操作都会触发 Spark executor 之间的大量数据移动。
这些转换(也叫 shuffle) 的核心是 Spark 需要根据 groupBy()、join()、agg()、sortBy() 和 reduceByKey() 等操作计算要生成哪些数据、要写入磁盘的键和关联的数据,以及如何将这些键和数据传输到对应的节点。
Spark 有五种不同的连接策略,通过它们在 executor 之间交换_、_移动、排序、分组和合并数据:广播哈希连接 (BHJ)、随机哈希连接 (SHJ)、随机排序合并连接 (SMJ)、广播嵌套循环连接(BNLJ),以及随机和复制嵌套循环连接(又名笛卡尔积连接)。我们在这里只关注其中的两个(BHJ 和 SMJ),因为它们是遇到的最常见的。
广播连接
当有两个数据集需要连接时,采用广播连接,会将较小的一个广播至所有 executor,然后与较大的数据集连接,这种策略避免了大规模的交换。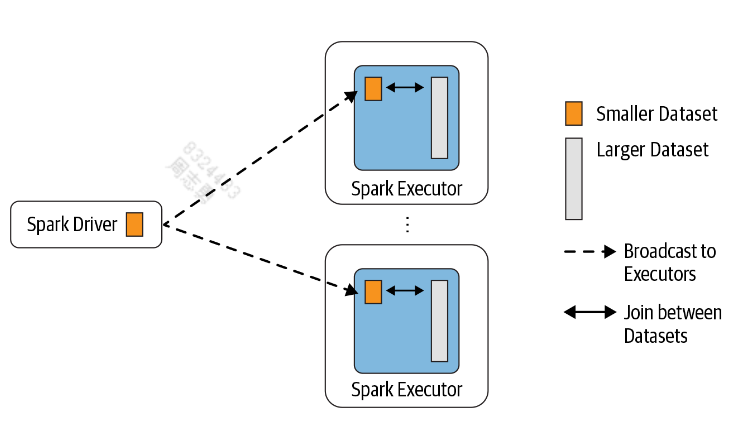
默认情况下,如果较小的数据集小于 10 MB,Spark 将使用广播连接。此配置可以在spark.sql.autoBroadcastJoinThreshold设置,可以根据每个executor 和 driver 中的内存量来减少或增加大小。如果确信有足够的内存,则可以对大于 10 MB(甚至高达 100 MB)的 DataFrame 使用广播连接。
BHJ 是 Spark 提供的最简单、最快的连接,因为它不涉及数据集的任何shuffle;广播后,executor 可以在本地获取所有数据。只需确保 Spark driver 和 executor 端都有足够的内存来在内存中保存较小的数据集。
何时使用广播连接
- 当较小和较大数据集中的每个键被 Spark 散列到同一分区时
- 当一个数据集比另一个数据集小得多时(并且在 10 MB 的默认配置内,如果您有足够的内存,则可以更大)
- 在执行 eq-join 时,根据匹配的未排序键组合两个数据集
- 不担心网络带宽使用过多或OOM错误时,因为较小的数据集将广播到所有executor
排序合并连接
此连接方案有两个阶段:排序阶段,然后是合并阶段。
排序阶段根据所需的连接键对每个数据集进行排序;合并阶段迭代每个数据集中行中的每个键,如果两个键匹配,则合并行。
下边是将两各大数据集通过公共键 uid == users_id合并的代码:
// In Scala
import scala.util.Random
// Show preference over other joins for large data sets
// Disable broadcast join
// Generate data
...
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "-1")// Generate some sample data for two data sets
var states = scala.collection.mutable.Map[Int, String]()
var items = scala.collection.mutable.Map[Int, String]()
val rnd = new scala.util.Random(42)// Initialize states and items purchased
states += (0 -> "AZ", 1 -> "CO", 2-> "CA", 3-> "TX", 4 -> "NY", 5-> "MI")
items += (0 -> "SKU-0", 1 -> "SKU-1", 2-> "SKU-2", 3-> "SKU-3", 4 -> "SKU-4", 5-> "SKU-5")// Create DataFrames
val usersDF = (0 to 1000000).map(id => (id, s"user_${id}",s"user_${id}@databricks.com", states(rnd.nextInt(5)))).toDF("uid", "login", "email", "user_state")
val ordersDF = (0 to 1000000).map(r => (r, r, rnd.nextInt(10000), 10 * r* 0.2d,states(rnd.nextInt(5)), items(rnd.nextInt(5)))).toDF("transaction_id", "quantity", "users_id", "amount", "state", "items")// Do the join
val usersOrdersDF = ordersDF.join(usersDF, $"users_id" === $"uid")// Show the joined results
usersOrdersDF.show(false)+--------------+--------+--------+--------+-----+-----+---+---+----------+
|transaction_id|quantity|users_id|amount |state|items|uid|...|user_state|
+--------------+--------+--------+--------+-----+-----+---+---+----------+
|3916 |3916 |148 |7832.0 |CA |SKU-1|148|...|CO |
|36384 |36384 |148 |72768.0 |NY |SKU-2|148|...|CO |
|41839 |41839 |148 |83678.0 |CA |SKU-3|148|...|CO |
|48212 |48212 |148 |96424.0 |CA |SKU-4|148|...|CO |
|48484 |48484 |148 |96968.0 |TX |SKU-3|148|...|CO |
|50514 |50514 |148 |101028.0|CO |SKU-0|148|...|CO |
|65694 |65694 |148 |131388.0|TX |SKU-4|148|...|CO |
|65723 |65723 |148 |131446.0|CA |SKU-1|148|...|CO |
|93125 |93125 |148 |186250.0|NY |SKU-3|148|...|CO |
|107097 |107097 |148 |214194.0|TX |SKU-2|148|...|CO |
|111297 |111297 |148 |222594.0|AZ |SKU-3|148|...|CO |
|117195 |117195 |148 |234390.0|TX |SKU-4|148|...|CO |
|253407 |253407 |148 |506814.0|NY |SKU-4|148|...|CO |
|267180 |267180 |148 |534360.0|AZ |SKU-0|148|...|CO |
|283187 |283187 |148 |566374.0|AZ |SKU-3|148|...|CO |
|289245 |289245 |148 |578490.0|AZ |SKU-0|148|...|CO |
|314077 |314077 |148 |628154.0|CO |SKU-3|148|...|CO |
|322170 |322170 |148 |644340.0|TX |SKU-3|148|...|CO |
|344627 |344627 |148 |689254.0|NY |SKU-3|148|...|CO |
|345611 |345611 |148 |691222.0|TX |SKU-3|148|...|CO |
+--------------+--------+--------+--------+-----+-----+---+---+----------+
only showing top 20 rows
查看执行计划:
usersOrdersDF.explain() == Physical Plan ==
InMemoryTableScan [transaction_id#40, quantity#41, users_id#42, amount#43,
state#44, items#45, uid#13, login#14, email#15, user_state#16]+- InMemoryRelation [transaction_id#40, quantity#41, users_id#42, amount#43,
state#44, items#45, uid#13, login#14, email#15, user_state#16],
StorageLevel(disk, memory, deserialized, 1 replicas)+- *(3) SortMergeJoin [users_id#42], [uid#13], Inner:- *(1) Sort [users_id#42 ASC NULLS FIRST], false, 0: +- Exchange hashpartitioning(users_id#42, 16), true, [id=#56]: +- LocalTableScan [transaction_id#40, quantity#41, users_id#42,
amount#43, state#44, items#45]+- *(2) Sort [uid#13 ASC NULLS FIRST], false, 0+- Exchange hashpartitioning(uid#13, 16), true, [id=#57]+- LocalTableScan [uid#13, login#14, email#15, user_state#16]
发现发生了 Exchange操作,也就是 shuffle。
通过 UI 也可以查看到: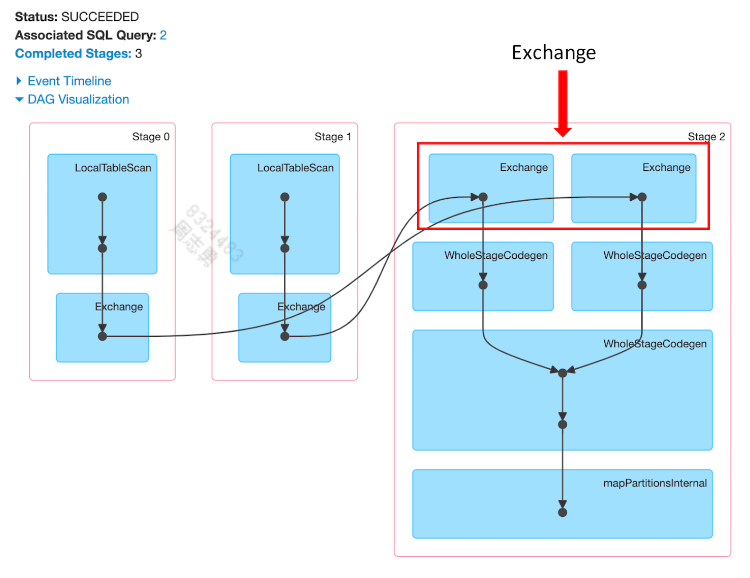
优化排序合并连接
如果我们为公共排序键或要执行频繁等连接的列创建分区存储桶则可以消除 Exchange.
可以创建明确数量的桶来存储特定的排序列(每个桶一个键)。以这种方式对数据进行预排序和重新组织可以提高性能,因为它允许我们跳过昂贵的Exchange操作并直接进入WholeStageCodegen。
何时使用排序合并连接
在以下条件下使用此类连接以获得最大收益:
- 当两个大数据集中的每个键都可以通过排序并哈希到同一分区时
- 当只想执行等连接以根据匹配的排序键组合两个数据集时
- 当能够预防Exchange和Sort导致大量 shuffle 操作时
总结
本文我们讨论了许多用于调整 Spark 应用程序的优化技术。通过调整一些默认的 Spark 配置,可以改进大型任务的扩展、增强并行度,并减少 executor 内存不足的问题。还了解了如何使用具有适当级别的缓存和持久化策略来加快对常用数据集的访问,并且我们研究了 Spark 在复杂聚合期间使用的两种常用联接,以及如何跳过 shuffle 等。