- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
参考论文:《Semi-Supervised Learning with Generative Adversarial Networks》
一、理论知识
1.1 SGAN提出用于解决哪些问题
SGAN被提出用于解决半监督学习问题。什么是半监督学习?举个例子,半监督学习就像是在学习时,有一部分作业是老师给了标准答案,但还有一大部分作业是没有答案的。你要尽力根据已知的答案来学习,然后猜测其他作业的答案。这就是半监督学习。
SGAN利用生成对抗网络(GAN)的框架,结合生成器和判别器的协同训练,通过生成器生成样本来扩充训练数据,从而提高模型在半监督学习任务上的性能。
1.2 SGAN模型
在标准的生成对抗网络(GAN)中,鉴别器网络 D D D 负责输出关于输入图像来自数据生成分布中的概率。传统方法中,这由一个单个 sigmoid 单元结束的前馈式网络实现,表示输入图像是真实数据的概率。然而,也可以通过使用一个 softmax 输出层来实现,每个类对应一个单元,包括真实数据和生成数据两类,即 [real, fake]。这种修改后的结构使得鉴别器 D D D 具有 N + 1 N+1 N+1 个输出单元,分别对应于 N N N 个真实数据类别和生成数据类别。在这种情况下, D D D 也可以被视为一个分类器,我们将这种网络称为 D / C D/C D/C。
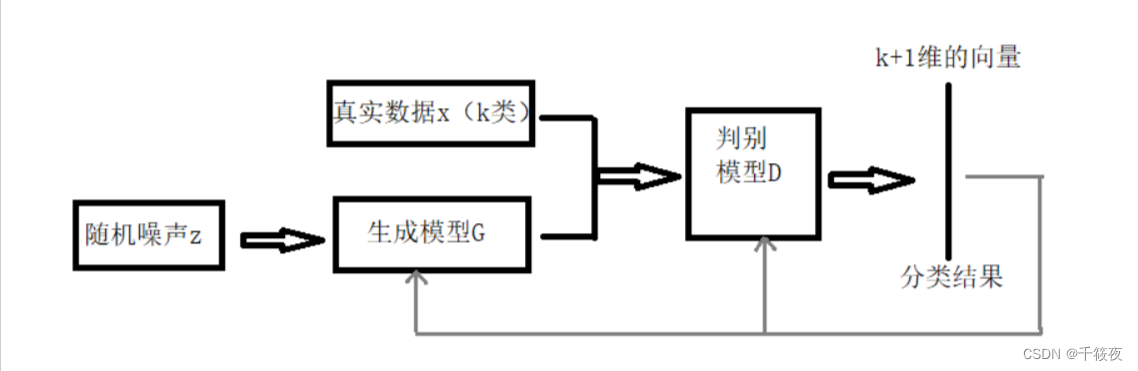
二、实战
2.1 前期准备
先导入所需库和模块,然后创建一个名为"images"的文件夹,用于保存训练过程中生成的图像,之后定义参数,包括训练的轮数(n_epochs)、批次大小(batch_size)、学习率(lr)等,最后使用torch.cuda.is_available()函数检查CUDA是否可用。
import argparse
import os
import numpy as np
import mathimport torchvision.transforms as transforms
from torchvision.utils import save_imagefrom torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variableimport torch.nn as nn
import torch.nn.functional as F
import torchos.makedirs("images", exist_ok=True)parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=50, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=4, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--num_classes", type=int, default=10, help="number of classes for dataset")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
opt = parser.parse_args()
print(opt)cuda = True if torch.cuda.is_available() else False
Namespace(n_epochs=50, batch_size=64, lr=0.0002, b1=0.5, b2=0.999, n_cpu=4, latent_dim=100, num_classes=10, img_size=32, channels=1, sample_interval=400)
2.2 权重初始化与模型定义
def weights_init_normal(m):classname = m.__class__.__name__if classname.find("Conv") != -1:torch.nn.init.normal_(m.weight.data, 0.0, 0.02)elif classname.find("BatchNorm") != -1:torch.nn.init.normal_(m.weight.data, 1.0, 0.02)torch.nn.init.constant_(m.bias.data, 0.0)class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()self.label_emb = nn.Embedding(opt.num_classes, opt.latent_dim)self.init_size = opt.img_size // 4 # Initial size before upsamplingself.l1 = nn.Sequential(nn.Linear(opt.latent_dim, 128 * self.init_size ** 2))self.conv_blocks = nn.Sequential(nn.BatchNorm2d(128),nn.Upsample(scale_factor=2),nn.Conv2d(128, 128, 3, stride=1, padding=1),nn.BatchNorm2d(128, 0.8),nn.LeakyReLU(0.2, inplace=True),nn.Upsample(scale_factor=2),nn.Conv2d(128, 64, 3, stride=1, padding=1),nn.BatchNorm2d(64, 0.8),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),nn.Tanh(),)def forward(self, noise):out = self.l1(noise)out = out.view(out.shape[0], 128, self.init_size, self.init_size)img = self.conv_blocks(out)return imgclass Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()def discriminator_block(in_filters, out_filters, bn=True):"""Returns layers of each discriminator block"""block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]if bn:block.append(nn.BatchNorm2d(out_filters, 0.8))return blockself.conv_blocks = nn.Sequential(*discriminator_block(opt.channels, 16, bn=False),*discriminator_block(16, 32),*discriminator_block(32, 64),*discriminator_block(64, 128),)# The height and width of downsampled imageds_size = opt.img_size // 2 ** 4# Output layersself.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1), nn.Sigmoid())self.aux_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, opt.num_classes + 1), nn.Softmax())def forward(self, img):out = self.conv_blocks(img)out = out.view(out.shape[0], -1)validity = self.adv_layer(out)label = self.aux_layer(out)return validity, label
2.3 模型配置
# Loss functions
adversarial_loss = torch.nn.BCELoss()
auxiliary_loss = torch.nn.CrossEntropyLoss()# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()if cuda:generator.cuda()discriminator.cuda()adversarial_loss.cuda()auxiliary_loss.cuda()# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(datasets.MNIST("../../data/mnist",train=True,download=True,transform=transforms.Compose([transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]),),batch_size=opt.batch_size,shuffle=True,
)# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if cuda else torch.LongTensor2.4 训练
for epoch in range(opt.n_epochs):for i, (imgs, labels) in enumerate(dataloader):batch_size = imgs.shape[0]# Adversarial ground truthsvalid = Variable(FloatTensor(batch_size, 1).fill_(1.0), requires_grad=False)fake = Variable(FloatTensor(batch_size, 1).fill_(0.0), requires_grad=False)fake_aux_gt = Variable(LongTensor(batch_size).fill_(opt.num_classes), requires_grad=False)# Configure inputreal_imgs = Variable(imgs.type(FloatTensor))labels = Variable(labels.type(LongTensor))# -----------------# Train Generator# -----------------optimizer_G.zero_grad()# Sample noise and labels as generator inputz = Variable(FloatTensor(np.random.normal(0, 1, (batch_size, opt.latent_dim))))# Generate a batch of imagesgen_imgs = generator(z)# Loss measures generator's ability to fool the discriminatorvalidity, _ = discriminator(gen_imgs)g_loss = adversarial_loss(validity, valid)g_loss.backward()optimizer_G.step()# ---------------------# Train Discriminator# ---------------------optimizer_D.zero_grad()# Loss for real imagesreal_pred, real_aux = discriminator(real_imgs)d_real_loss = (adversarial_loss(real_pred, valid) + auxiliary_loss(real_aux, labels)) / 2# Loss for fake imagesfake_pred, fake_aux = discriminator(gen_imgs.detach())d_fake_loss = (adversarial_loss(fake_pred, fake) + auxiliary_loss(fake_aux, fake_aux_gt)) / 2# Total discriminator lossd_loss = (d_real_loss + d_fake_loss) / 2# Calculate discriminator accuracypred = np.concatenate([real_aux.data.cpu().numpy(), fake_aux.data.cpu().numpy()], axis=0)gt = np.concatenate([labels.data.cpu().numpy(), fake_aux_gt.data.cpu().numpy()], axis=0)d_acc = np.mean(np.argmax(pred, axis=1) == gt)d_loss.backward()optimizer_D.step()batches_done = epoch * len(dataloader) + iif batches_done % opt.sample_interval == 0:save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)print("[Epoch %d/%d] [Batch %d/%d] [D loss: %f, acc: %d%%] [G loss: %f]"% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), 100 * d_acc, g_loss.item()))
[Epoch 0/50] [Batch 937/938] [D loss: 1.352186, acc: 50%] [G loss: 0.663589]
[Epoch 1/50] [Batch 937/938] [D loss: 1.235517, acc: 50%] [G loss: 1.671782]
[Epoch 2/50] [Batch 937/938] [D loss: 1.045947, acc: 65%] [G loss: 1.315296]
[Epoch 3/50] [Batch 937/938] [D loss: 1.039367, acc: 70%] [G loss: 2.646401]
[Epoch 4/50] [Batch 937/938] [D loss: 0.899272, acc: 85%] [G loss: 2.424302]
[Epoch 5/50] [Batch 937/938] [D loss: 1.031800, acc: 75%] [G loss: 1.979734]
[Epoch 6/50] [Batch 937/938] [D loss: 0.865867, acc: 87%] [G loss: 4.274090]
[Epoch 7/50] [Batch 937/938] [D loss: 0.862276, acc: 92%] [G loss: 3.419953]
[Epoch 8/50] [Batch 937/938] [D loss: 1.005301, acc: 82%] [G loss: 1.867689]
[Epoch 9/50] [Batch 937/938] [D loss: 0.919378, acc: 90%] [G loss: 4.254766]
[Epoch 10/50] [Batch 937/938] [D loss: 0.886876, acc: 90%] [G loss: 4.498873]
[Epoch 11/50] [Batch 937/938] [D loss: 0.969284, acc: 82%] [G loss: 3.070788]
[Epoch 12/50] [Batch 937/938] [D loss: 0.893068, acc: 85%] [G loss: 6.498258]
[Epoch 13/50] [Batch 937/938] [D loss: 0.840133, acc: 90%] [G loss: 8.441454]
[Epoch 14/50] [Batch 937/938] [D loss: 1.024140, acc: 84%] [G loss: 12.355464]
[Epoch 15/50] [Batch 937/938] [D loss: 0.821921, acc: 95%] [G loss: 6.133313]
[Epoch 16/50] [Batch 937/938] [D loss: 0.818303, acc: 95%] [G loss: 4.394979]
[Epoch 17/50] [Batch 937/938] [D loss: 0.806723, acc: 95%] [G loss: 6.602290]
[Epoch 18/50] [Batch 937/938] [D loss: 0.884590, acc: 92%] [G loss: 3.963483]
[Epoch 19/50] [Batch 937/938] [D loss: 1.092136, acc: 71%] [G loss: 8.668056]
[Epoch 20/50] [Batch 937/938] [D loss: 0.936026, acc: 89%] [G loss: 2.470026]
[Epoch 21/50] [Batch 937/938] [D loss: 0.875962, acc: 89%] [G loss: 5.632479]
[Epoch 22/50] [Batch 937/938] [D loss: 0.811583, acc: 95%] [G loss: 10.195074]
[Epoch 23/50] [Batch 937/938] [D loss: 0.789067, acc: 100%] [G loss: 11.308340]
[Epoch 24/50] [Batch 937/938] [D loss: 0.795523, acc: 96%] [G loss: 8.784575]
[Epoch 25/50] [Batch 937/938] [D loss: 0.865301, acc: 92%] [G loss: 10.207865]
[Epoch 26/50] [Batch 937/938] [D loss: 0.786401, acc: 100%] [G loss: 3.394327]
[Epoch 27/50] [Batch 937/938] [D loss: 0.796065, acc: 95%] [G loss: 7.474880]
[Epoch 28/50] [Batch 937/938] [D loss: 0.805746, acc: 96%] [G loss: 5.651248]
[Epoch 29/50] [Batch 937/938] [D loss: 0.773570, acc: 100%] [G loss: 7.849866]
[Epoch 30/50] [Batch 937/938] [D loss: 0.804366, acc: 96%] [G loss: 7.017126]
[Epoch 31/50] [Batch 937/938] [D loss: 0.898856, acc: 87%] [G loss: 11.380006]
[Epoch 32/50] [Batch 937/938] [D loss: 0.784667, acc: 98%] [G loss: 11.001215]
[Epoch 33/50] [Batch 937/938] [D loss: 0.781652, acc: 100%] [G loss: 8.813923]
[Epoch 34/50] [Batch 937/938] [D loss: 0.780957, acc: 98%] [G loss: 7.537516]
[Epoch 35/50] [Batch 937/938] [D loss: 0.784157, acc: 98%] [G loss: 9.816891]
[Epoch 36/50] [Batch 937/938] [D loss: 0.892552, acc: 92%] [G loss: 10.325437]
[Epoch 37/50] [Batch 937/938] [D loss: 0.788715, acc: 96%] [G loss: 12.527905]
[Epoch 38/50] [Batch 937/938] [D loss: 0.780603, acc: 98%] [G loss: 6.954862]
[Epoch 39/50] [Batch 937/938] [D loss: 0.853637, acc: 93%] [G loss: 11.160628]
[Epoch 40/50] [Batch 937/938] [D loss: 0.825676, acc: 95%] [G loss: 10.061171]
[Epoch 41/50] [Batch 937/938] [D loss: 0.782195, acc: 98%] [G loss: 7.089082]
[Epoch 42/50] [Batch 937/938] [D loss: 0.780453, acc: 98%] [G loss: 7.865266]
[Epoch 43/50] [Batch 937/938] [D loss: 0.785953, acc: 98%] [G loss: 7.176102]
[Epoch 44/50] [Batch 937/938] [D loss: 0.783754, acc: 98%] [G loss: 13.567838]
[Epoch 45/50] [Batch 937/938] [D loss: 0.798364, acc: 95%] [G loss: 15.339465]
[Epoch 46/50] [Batch 937/938] [D loss: 0.809889, acc: 92%] [G loss: 7.125263]
[Epoch 47/50] [Batch 937/938] [D loss: 0.807932, acc: 98%] [G loss: 7.732235]
[Epoch 48/50] [Batch 937/938] [D loss: 0.781007, acc: 98%] [G loss: 13.505493]
[Epoch 49/50] [Batch 937/938] [D loss: 0.780933, acc: 98%] [G loss: 10.880657]



最开始到三十多轮程序意外终止,尝试将n_cpu数下调至4,成功运行。