链接:https://pan.baidu.com/s/1hX4xpVPo70vwLIo0gdsM8A?pwd=q88b
提取码:q88b
一般认为数据质量决定了机器学习性能的上限,而机器学习模型和算法的优化最多 只能逼近这个上限。因此在数据采集阶段需要对采集任务进行规划。在数据采集之前, 主要是从数据可用性、采集成本、特征可计算性、存储成本的角度进行分析,以获得尽可能 多的样本特征为基本目标。
入侵检测的数据采集方法取决于入侵检测系统的类型,即网络入侵检测和主机入侵 检测系统。对于网络入侵检测,采用网络嗅探、网络数据包截获等方法获得流量数据。对 于主机入侵检测,采用的方法比较灵活,既可以是操作系统的各种日志,也可以是某些应 用系统的日志,还可以通过开发驻留于主机的应用软件等方法获得主机数据。因此,与网 络连接、网络请求有关的特征,以及各类日志中的特征都是入侵检测常用的数据源。
这里介绍入侵检测领域常用的数据集,包括 NSL-KDD等,这些公开的数据集为帮助 研究人员比较不同的入侵检测方法提供了基准。NSL-KDD 数据集是通过网络数据包提 取而成,由 M.Tavallaee等于2009年构建,它克服了更早之前 KDDCup99数据集中存 在的一些问题。
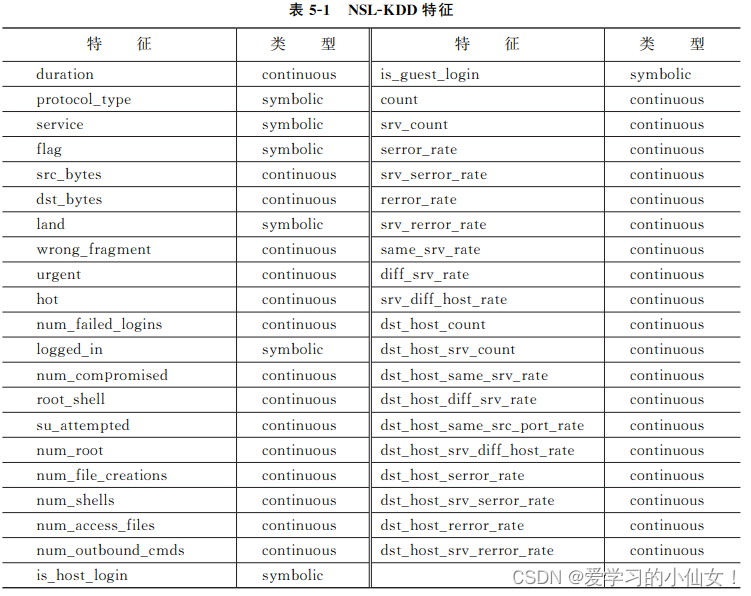
NSL-KDD共使用41个特征来描述每条流量,这些特征可以分为三组。
(1)基本特征(basic features),从 TCP/IP连接中提取。
(2)流量特征(traffic features),与同一主机或同一服务相关。
(3)内容特征(content features),反映了数据包中的内容。
除此之外,每条流量都带有一个标签,即normal和anomaly,表示相应的流量为正常 或异常。因此 NSL-KDD是一个二分类的异常检测数据集。
从特征工程的角度看,NSL-KDD实际上已经完成了特征工程中的特征可用性、特征 采集,以及衍生特征的定义和计算。使用该数据集进行检测实验,只要从特征清洗、特征 选择或特征提取开始就可以。
NSL-KDD每条流量的41个特征的含义如表5-1所示,表中列出了特征名称及其类 型,其中 continuous是 连 续 数 值 型,symbolic是 符 号 类 型。例 如,protocol_type属 于 symbolic类型,它的取值范围是 {t' cp','udp',i'cmp'},是一种枚举值。
从https://www.unb.ca/cic/datasets/nsl.html下载数据文件,该数据压缩文件中 包含的文件说明如下。
KDDTrain+ .TXT: 是完整的 NSL-KDD训练集,除了41个特征外,还包括数据包 类型的标签和难度等级。其中,数据包类型有 normal,以及 back、buffer_overflow、guess_ passwd、portsweep、rootkit、satan、smurf、teardrop、warezclient、warezmaster等 入 侵 类 型。难度等级表示每条记录分类时判断的难易程度,是一个[0,21]范围内的整数,数值越 大表示该记录越容易分类,0是最不容易分类的。整个数据集共125973条记录,难度等 级小于15的记录占2.94%,可以看出绝大部分记录的分类标签都是比较确切的。
KDDTrain + .ARFF:与 KDDTrain+ .TXT 大致相同,只是每条记录不包含难度 等级,同时数据包类型的标签被归类为normal和anomaly两种。该文件带有41个特征 的属性名和类型描述,可以直接在 Weka中使用。
KDDTrain+ _20Percent.TXT:是 KDDTrain + .txt文件的20%子集,实际上是 KDDTrain+ .txt前20%的记录。
KDDTrain+ _20Percent.ARFF:是 KDDTrain+ .arff文件的20%子集。
KDDTest+ .TXT:是完整的 NSL-KDD测试集,包括攻击类型的标签和CSV 格式 的难度等级。
KDDTest+ .ARFF:是完整的 NSL-KDD测试集,带有 ARFF格式的二进制标签。
KDDTest-21.TXT:是 KDDTest+ .txt文件的子集,其中不包括难度级别为21的 记录,即该数据集中共21个难度等级。
KDDTest-21.ARFF:是 KDDTest+ .arff文件的子集,其中不包括难度级别为21 的记录,该数据集共包含21个难度等级。
内容来自:标题 (tsinghua.edu.cn),可以再结合其他博客详细了解一下。