本文重点
前面已经学习了逻辑回归的假设函数,训练出模型的关键就是学习出参数w和b,要想学习出这两个参数,此时需要最小化逻辑回归的代价函数才可以训练出w和b。那么本节课我们将学习逻辑回归算法的代价函数是什么?
为什么不能平方差损失函数
线性回归的代价函数我们使用的是预测值和实际值的平方差或者平方差的一半,但是逻辑回归我们并不能使用这样的代价函数,因为当学习逻辑回归参数的时候,我们会发现我们的优化目标不是凸优化问题,会有多个局部最优值,梯度下降法很有可能找不到全局最优值,虽然平方差是一个不错的损失函数,但是在逻辑回归不行,所以我们要在逻辑回归中定义另外一个代价函数。
逻辑回归的单样本损失函数
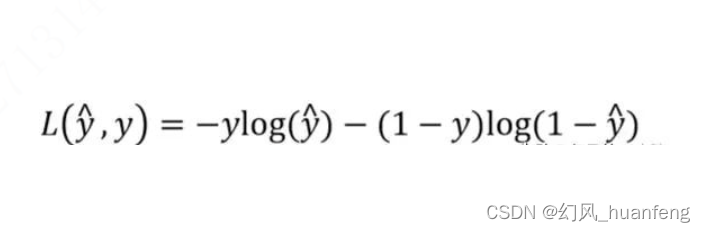
这个就是逻辑回归的损失函数(一个样本的损失),为什么逻辑回归使用这个损失函数呢?
当y=1时,损失函数为L=-log(y^),要想让L尽可能地小,那么y^就要尽可能地大,因为sigmoid函数取值为【0,1】,所以y^会无限接近1,这样y^≈1
当y=0时,损失函数L=-log(1-y^),如果想要让L尽可能地小,那么y^就要尽可能地小,为sigmoid函数取值为【0,1】,所以y^会无限接近0,这样y^≈=0
这个就是sigmoid地作用,其实在很多函数和sigmoid效果类似,就是y=1时,我们就尽可


![P1712 [NOI2016] 区间(线段树 + 贪心 + 双指针)](https://img-blog.csdnimg.cn/img_convert/4c30e02e3af7587428f7587fe6bc8127.png)