计算量估计
卷积神经网络复杂度分析
卷积神经网络CNN中的参数量(parameters)和计算量(FLOPs )
Roofline Model
Roofline Model与深度学习模型的性能分析
有了上面这些基础知识,再来往下分析会更有收获
发现问题 — 矩阵乘法
思路
根据 Roof-line-Model 理论,我们可以从两个角度入手计算该模型运算的时间
① Memory-bound
② Compute-bound
Memory-bound
RTX 4090 1.01 TB/s (理论)
实测本机带宽
cuda-samples/Samples/1_Utilities/bandwidthTest at master · NVIDIA/cuda-samples (实测)
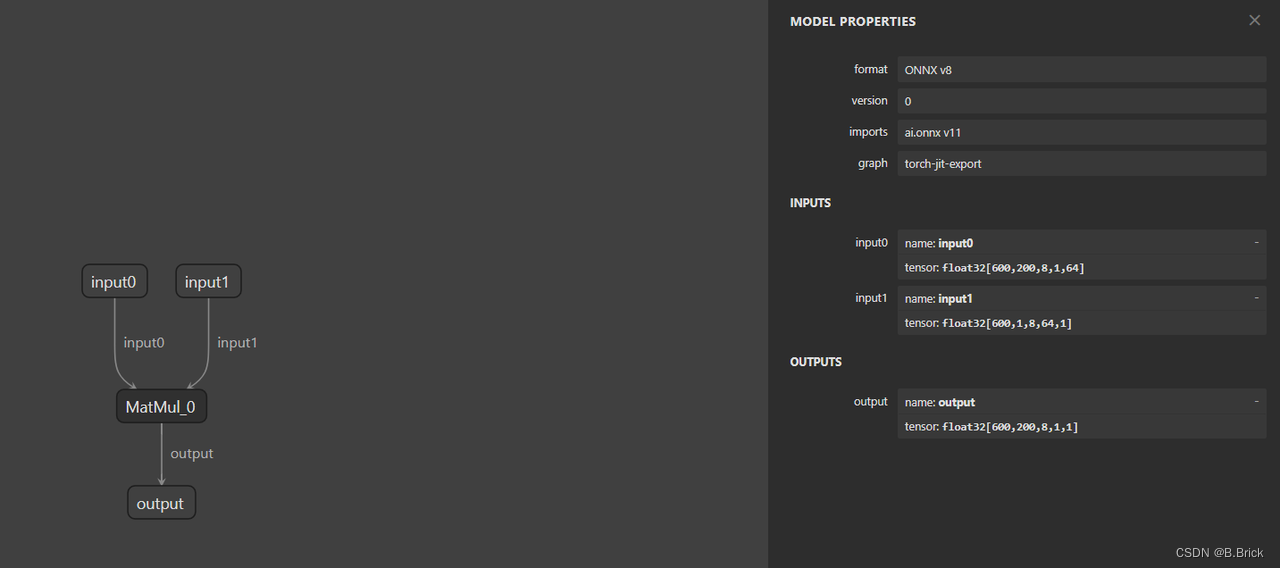
矩阵乘访存量
-
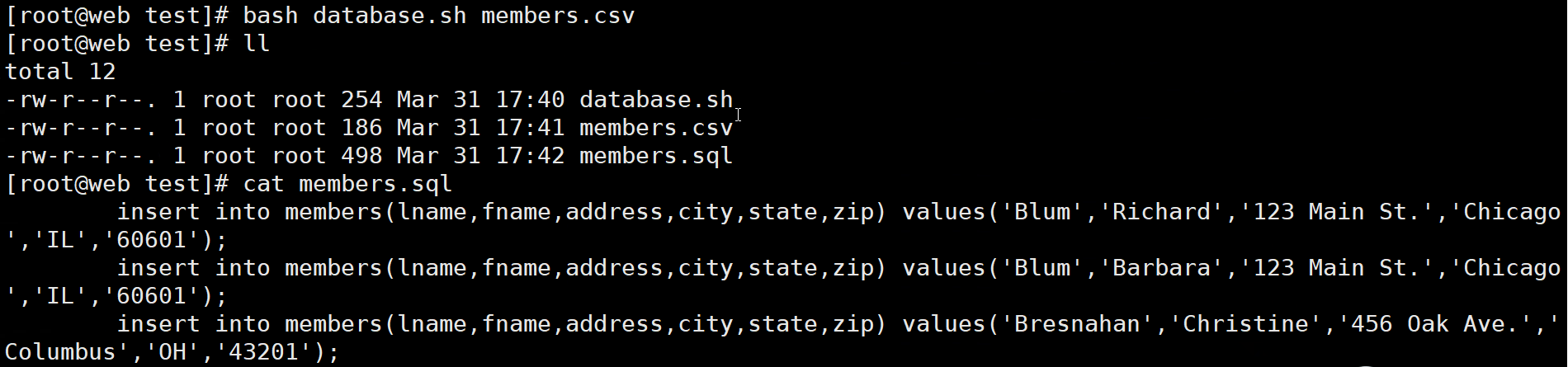
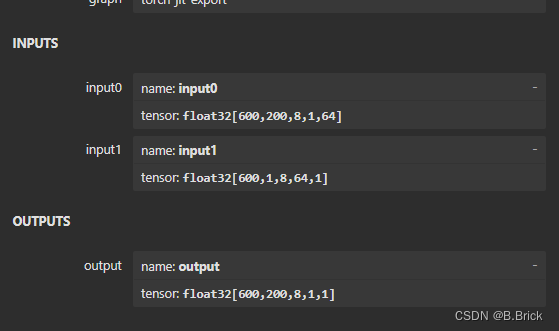
读取数据量(输入) input_0 = 600x200x8x1x64x sizeof(float32)
input_1 = 600x1x8x64x1x sizeof(float32)
-
写入数据量(输出) output = 600x200x8x1x1x sizeof(float32)
-
总访存量
Total = input_0 + input_1 + output = 250828800
Band_width_TBs(4090实际带宽) = 0.92 TB/s
Memory_time = Total / Band_width_TBs = 0.248 ms
Compute-bound
The NVIDIA GeForce RTX 4090 offers a peak single-precision (FP32) performance of 82.6 TFLOPS . (理论)
实测本机FLOPS
FLOPS = 78.65 TFLOPS (实测)
下面是计算过程
input_channel=512, output_channel=512, kenel_size=5, W=256, H=256
import torch
import torch.nn as nn
import onnxclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(512, 512, kernel_size=5, stride=1, padding=2, bias=False)def forward(self, x):x = self.conv1(x)return xnet = Net().eval()
x = torch.randn(1, 512, 256, 256) with torch.no_grad():torch.onnx.export(net, x, 'conv.onnx', opset_version=11, input_names=['input'], output_names=['output'], dynamic_axes={'input': {0: 'batch_size'}, 'output': {0: 'batch_size'}})卷积核计算量公式
FLOPs = 2×Cin×Hout×Wout×Cout×K2
FLOPs = 858993459200
mean = 10.9218 ms
FLOPS(实际) = FLOPs / percentile = 78.65 TFLOPS
矩阵乘计算量
M=600x200x8,N=1,K=64 (gemm)TFLOPs = 2MNK = 2 x 12x10^4 x 8 x 64 / 10^12
Compute_time = TFLOPs / FLOPS(实际) = 0.0000156 ms
gemm计算耗时
gemm_time = MAX(Memory_time, Compute_time) = 0.248 ms

我们算出来gemm的理论计算时间是 0.248ms,为什么trtexec这里平均用了 202.962ms 呢?
时间都去哪了?
Nsight system
# 先保存一份带有详细信息的engine,这样system 才能看到细节
trtexec --onnx=gemv.onnx --profilingVerbosity=detailed --saveEngine=gemv.engine 【trtexec】trtexec命令大全
# 用Nsystem分析
nsys profile -o gemv_profile --stat=true --capture-range cudaProfilerApi trtexec --loadEngine=gemv.engine --warmUp=0 --duration=0 --iterations=50【NsightSystem】Nsight System命令大全

从gpukernsum可以看出,gemm的实现是通过sm50架构的算子实现的, 这是NVIDIA第一代统一虚拟内存的架构;而本机4090的已经是最新架构Ada Lovelace,所以要解决这个问题,就需要手写Kernel算子,选择合适的并行方式去计算;
解决问题
写插件 - - ~
后续如何,下文分解