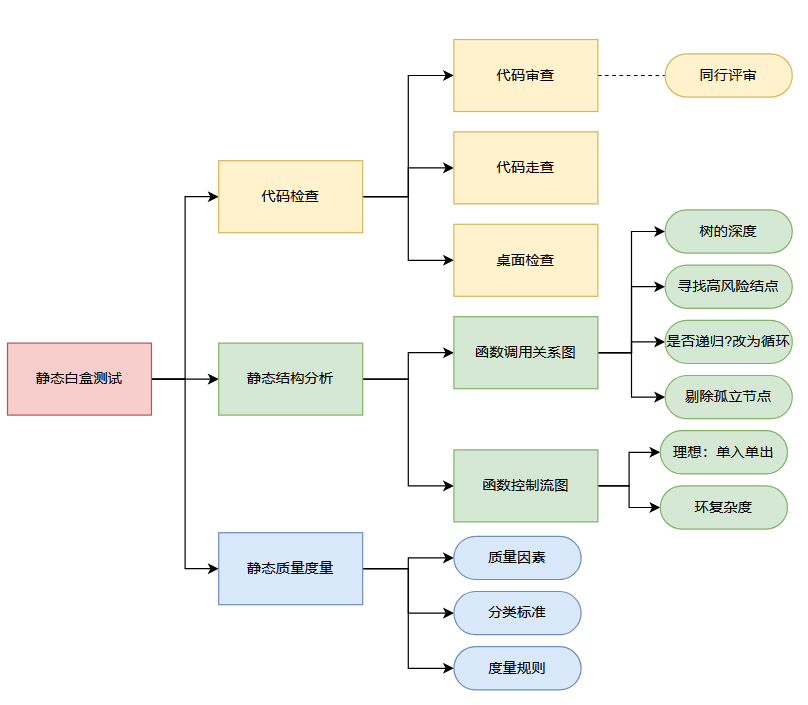
文章目录
- 前言
- 一、基本使用
- 1.1 文本生成词云
- 1.2 配置项
- 二、进阶用法
- 2.1 自定义形状
- 2.2 自定义着色
- 2.3 自定义词频
- 2.4 中文
- 三、实际案例
- 3.1 工作报告词云
- 3.2 周杰伦歌词词云
- 四、总结
- 4.1 优点和局限性
- 4.2 展望未来发展
- 参考
前言
当我们需要将大量文本数据可视化展示时,WordCloud 库是一个非常有用的工具。它能够将文本中的关键词以词云的形式呈现出来,使得人们可以直观地了解文本的主题和关键词。WordCloud 库不仅能够简单地生成词云,还提供了丰富的配置选项,使用户可以根据自己的需求定制词云的外观和布局。作为Python开源库中的一员,WordCloud 库已经被广泛应用于各种领域,包括数据分析、自然语言处理、社交媒体分析等。
在本文中,我们将深入探讨WordCloud库的使用方法、实际应用案例实践,帮助读者更好地理解和利用这一强大的工具。
- github:https://github.com/amueller/word_cloud
- 文档:https://amueller.github.io/word_cloud/
安装
pip install wordcloud
一、基本使用
1.1 文本生成词云
import osfrom os import path
from wordcloud import WordCloud# 获取当前py文件路径
d = path.dirname(__file__) if "__file__" in locals() else os.getcwd()# 读取文本
text = open(path.join(d, 'constitution.txt')).read()wordcloud = WordCloud().generate(text)wordcloud.to_file('1.jpg')
image = wordcloud.to_image()
image.show()

1.2 配置项
WordCloud() 可通过下面这些配置项定制词云的外观和布局
| 配置项 | 类型 | 默认值 | 含义 |
|---|---|---|---|
| font_path | string | 字体路径 | |
| width | int | 400 | 画布宽度 |
| height | int | 200 | 画布高度 |
| margin | int | 2 | 词云图像的边距大小,以像素为单位 |
| prefer_horizontal | float | 0.9 | 词语水平排列的偏好程度,>=1 水平排列 |
| mask | nd-array or None | None | 词云的形状遮罩,使得词云图像能够按照指定的形状排列词语 |
| contour_width | float | 0 | 轮廓线的宽度 |
| contour_color | color value | “black” | 轮廓线的颜色 |
| scale | float | 1 | 词云图像的缩放比例,即词云图像计算出来的大小相对于形状遮罩或者画布的大小的比例 |
| min_font_size | int | 4 | 最小字体大小 |
| font_step | int | 1 | 字体的步长,关系词语间大小间隔 |
| max_words | number | 200 | 词语最大数量 |
| stopwords | set of strings or None | STOPWORDS | 要排除的词语 |
| random_state | int | None | 随机数生成器的种子 |
| background_color | color value | ”black” | 背景颜色 |
| max_font_size | int or None | None | 最大字体大小 |
| mode | string | ”RGB” | 主要有"RGB",“RGBA”,后者可以控制透明度 |
| relative_scaling | float | ‘auto’ | 单词频率对字体大小影响,较大的值将增加词语之间的大小差异 |
| color_func | callable | None | 自定义的颜色函数,该函数决定了词云中每个词语的颜色 |
| regexp | string or None | None | 从输入文本中提取满足正则的词语,可选 |
| collocations | bool | True | 是否考虑词组 |
| colormap | string or matplotlib colormap | ”viridis” | 词云的颜色映射,即词云中每个词语的颜色分布。常见的颜色映射包括单色映射(如灰度"gray")、渐变映射(“viridis”、“magma” 和 “inferno”) |
| normalize_plurals | bool | True | 通过结尾为s 判断复数形式是否被视为同一个词 |
| repeat | bool | False | 词语是否重复出现 |
| include_numbers | bool | False | 是否包含数字 |
| min_word_length | int | 0 | 个单词必须包含的最小字母数 |
| collocation_threshold | int | 30 | 词语搭配(Collocations)的显示阈值 |
二、进阶用法
2.1 自定义形状
先通过一张普通图片制作mask
import cv2
import numpy as np
from PIL import Image# 读取普通照片
image = cv2.imread('alice_color.png')# 将图像转换为灰度图
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)# 二值化图像,将图像转换为黑白二值图像
_, mask_image = cv2.threshold(gray_image, 250, 255, cv2.THRESH_BINARY)# 保存生成的蒙版图像
cv2.imwrite('mask_image.png', mask_image)import matplotlib.pyplot as pltplt.figure(figsize=(10, 5))# 显示第一张图片
plt.subplot(1, 2, 1)
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.title('Color Image')
plt.axis('off')# 显示第二张图片
plt.subplot(1, 2, 2)
plt.imshow(cv2.cvtColor(mask_image, cv2.COLOR_BGR2RGB))
plt.title('Mask Image')
plt.axis('off')# 显示图片
plt.show()

from os import path
from PIL import Image
import numpy as np
import osfrom wordcloud import WordCloud, STOPWORDSd = path.dirname(__file__) if "__file__" in locals() else os.getcwd()text = open(path.join(d, 'alice.txt')).read()alice_mask = np.array(Image.open(path.join(d, "mask_image.png")))stopwords = set(STOPWORDS)
stopwords.add("said")wc = WordCloud(background_color="white", max_words=2000, mask=alice_mask,stopwords=stopwords, contour_width=3, contour_color='steelblue')wc.generate(text)wc.to_file("alice.png")image = wc.to_image()
image.show()

2.2 自定义着色
from os import path
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import osfrom wordcloud import WordCloud, STOPWORDS, ImageColorGeneratord = path.dirname(__file__) if "__file__" in locals() else os.getcwd()# Read the whole text.
text = open(path.join(d, 'alice.txt')).read()alice_coloring = np.array(Image.open(path.join(d, "alice_color.png")))
stopwords = set(STOPWORDS)
stopwords.add("said")wc = WordCloud(background_color="white", max_words=2000, mask=alice_coloring,stopwords=stopwords, max_font_size=40, random_state=42)
# generate word cloud
wc.generate(text)# create coloring from image
image_colors = ImageColorGenerator(alice_coloring)# show
fig, axes = plt.subplots(1, 3)
axes[0].imshow(wc, interpolation="bilinear")
# recolor wordcloud and show
# we could also give color_func=image_colors directly in the constructor
axes[1].imshow(wc.recolor(color_func=image_colors), interpolation="bilinear")
axes[2].imshow(alice_coloring, cmap=plt.cm.gray, interpolation="bilinear")
for ax in axes:ax.set_axis_off()
plt.show()

2.3 自定义词频
当已经有了词频统计好的数据,或者想要自定义词语的词频时,可以使用 generate_from_frequencies() 函数实现自定义词频
import multidict as multidictimport numpy as npimport os
import re
from PIL import Image
from os import path
from wordcloud import WordCloud
import matplotlib.pyplot as pltdef getFrequencyDictForText(sentence):fullTermsDict = multidict.MultiDict()tmpDict = {}# making dict for counting frequenciesfor text in re.sub(r'\n', ' ', sentence).split(" "):if re.match("a|the|an|the|to|in|for|of|or|by|with|is|on|that|be", text):continueval = tmpDict.get(text, 0)tmpDict[text.lower()] = val + 1for key in tmpDict:fullTermsDict.add(key, tmpDict[key])return fullTermsDictdef makeImage(text):alice_mask = np.array(Image.open("mask_image.png"))wc = WordCloud(background_color="white", max_words=1000, mask=alice_mask)# generate word cloudwc.generate_from_frequencies(text)# showplt.imshow(wc, interpolation="bilinear")plt.axis("off")plt.show()# get data directory (using getcwd() is needed to support running example in generated IPython notebook)
d = path.dirname(__file__) if "__file__" in locals() else os.getcwd()text = open(path.join(d, 'alice.txt'), encoding='utf-8')
text = text.read()
makeImage(getFrequencyDictForText(text))
2.4 中文
import jieba
from os import path
from imageio import imread
import matplotlib.pyplot as plt
import osfrom wordcloud import WordCloud, ImageColorGeneratorstopwords_path = 'stopwords_cn_en.txt'
font_path = r'C:\Windows\Fonts\simfang.ttf'# Read the whole text.
text = open('CalltoArms.txt', encoding = 'utf-8').read()mask = imread('LuXun_mask.png')userdict_list = ['阿Q', '孔乙己', '单四嫂子']def jieba_processing_txt(text):for word in userdict_list:jieba.add_word(word)mywordlist = []seg_list = jieba.cut(text, cut_all=False)liststr = "/ ".join(seg_list)with open(stopwords_path, encoding='utf-8') as f_stop:f_stop_text = f_stop.read()f_stop_seg_list = f_stop_text.splitlines()for myword in liststr.split('/'):if not (myword.strip() in f_stop_seg_list) and len(myword.strip()) > 1:mywordlist.append(myword)return ' '.join(mywordlist)wc = WordCloud(font_path=font_path, background_color="white", max_words=2000, mask=mask,max_font_size=100, random_state=42, width=1000, height=860, margin=2,)wc.generate(jieba_processing_txt(text))
wc.to_file('LuXun.png')


三、实际案例
3.1 工作报告词云
数据来源:https://python123.io/resources/pye/%E6%96%B0%E6%97%B6%E4%BB%A3%E4%B8%AD%E5%9B%BD%E7%89%B9%E8%89%B2%E7%A4%BE%E4%BC%9A%E4%B8%BB%E4%B9%89.txt
import jieba
from os import path
from imageio import imread
import matplotlib.pyplot as plt
import osfrom wordcloud import WordCloud, ImageColorGeneratorstopwords_path = 'stopwords_cn_en.txt'
font_path = r'C:\Windows\Fonts\simfang.ttf'# Read the whole text.
text = open('新时代.txt', encoding = 'utf-8').read()mask = imread('china_mask.png')# The function for processing text with Jieba
def jieba_processing_txt(text):mywordlist = []seg_list = jieba.cut(text, cut_all=False)liststr = "/ ".join(seg_list)with open(stopwords_path, encoding='utf-8') as f_stop:f_stop_text = f_stop.read()f_stop_seg_list = f_stop_text.splitlines()for myword in liststr.split('/'):if not (myword.strip() in f_stop_seg_list) and len(myword.strip()) > 1:mywordlist.append(myword)return ' '.join(mywordlist)wc = WordCloud(font_path=font_path, background_color="white", max_words=2000, mask=mask,max_font_size=100, random_state=42, width=1000, height=860, margin=2,)wc.generate(jieba_processing_txt(text))
wc.to_file('时代.png')

3.2 周杰伦歌词词云
数据来源:https://github.com/ShusenTang/Dive-into-DL-PyTorch/blob/master/data/jaychou_lyrics.txt.zip
import jieba
from os import path
from imageio import imread
import cv2
import numpy as np
import matplotlib.pyplot as plt
import osfrom wordcloud import WordCloud, ImageColorGeneratorstopwords_path = 'stopwords_cn_en.txt'
font_path = r'C:\Windows\Fonts\simfang.ttf'# Read the whole text.
text = open('jaychou_lyrics.txt', encoding = 'utf-8').read()image = imread('jay.jpg')
mask = imread('jay_mask.png')# The function for processing text with Jieba
def jieba_processing_txt(text):mywordlist = []seg_list = jieba.cut(text, cut_all=False)liststr = "/ ".join(seg_list)with open(stopwords_path, encoding='utf-8') as f_stop:f_stop_text = f_stop.read()f_stop_seg_list = f_stop_text.splitlines()for myword in liststr.split('/'):if not (myword.strip() in f_stop_seg_list) and len(myword.strip()) > 1:mywordlist.append(myword)return ' '.join(mywordlist)wc = WordCloud(font_path=font_path, background_color="white", max_words=2000, mask=mask,max_font_size=100, random_state=42, width=1000, height=860, margin=2,)wc.generate(jieba_processing_txt(text))image_colors = ImageColorGenerator(np.array(image))
color = wc.recolor(color_func=image_colors)plt.figure(figsize=(10, 5))# 显示第一张图片
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.title('Color Image')
plt.axis('off')# 显示第二张图片
plt.subplot(1, 2, 2)
plt.imshow(color)
plt.title('WordCloud Image')
plt.axis('off')# 显示图片
plt.show()

四、总结
4.1 优点和局限性
优点有:
- 直观:通过生成词云图像,直观展示了文本数据中的关键词和热点内容,使得信息一目了然。
- 灵活性:可通过调整参数和样式,定制化生成符合需求的词云图像,满足不同场景下的需求。
- 便捷性:提供了简单易用的API接口,方便用户快速生成词云,无需复杂的编程知识。
在以下方面有局限性:
-
可解释性有限:词云图像虽然直观,但对于详细的数据分析并不足够,无法提供每个词语在文本中的具体含义和背景。
-
数据处理能力有限:在处理大规模文本数据时,WordCloud 库的性能可能受到限制,无法处理过大的数据集
4.2 展望未来发展
随着数据可视化技术的不断发展和应用场景的扩展,WordCloud 库可能会朝着以下方向发展:
- 智能化:未来的WordCloud库可能会引入更多的自动化和智能化功能,如基于自然语言处理技术的关键词提取和主题分析,使得生成的词云更加准确和有针对性。
- 多模态融合:未来的词云图像可能会与其他形式的可视化技术进行融合,如图表、地图等,实现多模态数据展示,提供更加全面和丰富的信息呈现。
- 数据互动性:未来的 WordCloud 库可能会加强与用户的交互性,支持用户对词云图像进行实时调整和定制,以及与其他数据进行联动分析,提升用户体验和数据分析效率。
参考
- Python—— 文件和数据格式化(模块6: wordcloud库的使用)(实例:自动轨迹绘制&政府工作报告词云)



![[lesson33]C++中的字符串类](https://img-blog.csdnimg.cn/direct/8ec2075e3c5a4a799ddf7bf4fc606012.png#pic_center)
