一、漏测原因总结
(1)需求评审质量低,需求设计简单、只是简单描述功能,功能逻辑较少
(2)需求变更频繁
(3)缺少需求分解(sql 文档、用例设计)
(4)测试人员思维局限,需求分解覆盖面不全,考虑不足
(5)测试人员执行过程不规范,人为漏测
(6)测试执行人员质量意识不足,发现的缺陷定义严重性程度低或不认为是问题
(7)测试环境与生产环境有较大出入
(8)测试环境或测试数据受限,无法模拟并覆盖执行所有正常和异常的场景分支
(9)功能回归策略问题
(10)测试资源有限
二、漏测预防或改进措施
(1)提高需求评审质量
需求评审至少有产品、开发和测试人员三方参加
需求评审必须安排业务熟悉和测试经验丰富的测试人员参加,对于不清楚的需求,要在会上提出更多逻辑疑问。
(2)需求变更要及时更新 sql 文档或者测试用例
一定要考虑到需求变更会不会导致其他模块(业务流程上考虑、参考业务流程图)
(3)需求分解(sql 文档、用例设计)及时更新维护
主要靠自觉性,如果实在没时间就写来源表、业务逻辑描述即可
(4)提高需求分解质量
数据来源(从哪来),业务逻辑(怎么做),数据写入(到哪去)
(5)测试流程要规范
冒烟测试:花少量时间对增、删、查、改功能进行流程测试
业务测试:按照测试需求分解、需求文档分别细测两遍以及数据库验证
回归测试:验证关闭 bug 时要把相关功能也测试到,避免开发因修改 bug 引出其他问题
系统复测:按照主业务流程复测较好,能涉及到大部分模块并且是用户用到较多的功能。(先不按照需求分解去测试,可能会想到之前想不到的业务逻辑),有时间再对 1、2 级 bug 复测。用例执行:在测试过程中严格按照测试用例执行
(6)测试环境要尽量贴近生产环境
(7)漏测的原因分析总结
根据每月漏测较多的项目,自己要总结原因,具体什么原因导致的漏测
(8)测试资源有限
时间不充足,导致一些功能点在测试过程中被忽略,可以根据里程碑节点来判断不同程度的测试
a、里程碑评审:保证主功能没问题,可以存在小的问题,即冒烟测试通过
b、系统演示:保证主要功能没问题,且界面数据显示要完整;次要功能可能不会演示到可先不改。
c、上线:禅道 1、2 级 bug 改完,优化类、功能完善类不影响客户使用可先不改
三、测试方法
1、全面校验
(1)起码需求清楚说明的,一定要各个字段全面验证正确性,不需要每个字段一条用例,可以一条用例覆盖所有字段,但是一定要验证到所有字段
(2)特殊验证:有的数据新提交的和继承表中数据可能存在一致的情况,我们必须要造不一致的数据来验证是否进行了继承和是否继承正确,并按需求逐字段校验(并不是造一条正向用例验证都正确了就行)
2、相关功能回归测试
(1) 先验证此问题是否已经解决
(2) 再验证相关模块或功能是否有新引入的 bug
(3) 公用模块或功能是否全面修改:如果该模块是专有模块,只有某一功能使用,针对该功能进行测试即可。如果该模块是公用模块,涉及功能较多,需针对所有使用情况进行全量覆盖
3、多组合测试
实际使用过程中会比我们测试过程中数据更多更复杂,所以要尽可能地造多种组合情况的数据进行测试,测试过程中可能会发现很多没有想到的问题或可优化完善的部分,不至于后期更多次地迭代发版(是否存在异常、是否全面、顺序是否正确)
四、测试坚持
先举个例子
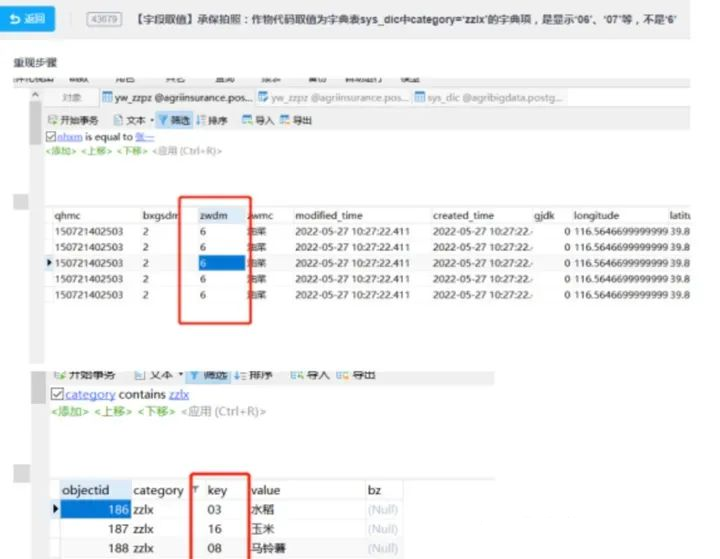

问题影响:这个作物代码 zwdm 是要和 web 端照片绑定关联的,如果 zwdm 值不对就会导致后期关联不上(产品人员给到开发人员的字典清单)
1、不予解决
字面意思:这是个 bug,但是开发不想解决,或者是开发认为不应该解决,或者有时候开发标注的时候容易和设计如此混淆。
解决办法:
(1)开发备注如下,并有聊天截图(也有没有的情况),但是也要和产品再次确认后确认是否关闭。(确认原因:每个人理解有偏差;觉得产品说的不太合理)
(3)测试对理解需求不透彻,尽量避免这类 bug 出现,并记录在 sql 文档中
(4)测试提 bug 之前,开发自己知道这个 bug 已经解决但没发版,有的开发标注已解决,有的标注不予解决,需要新版本确认好再关闭。
(5)有的 bug 现阶段可以先不解决,前提已经和产品确认过,产品也同意暂时不解决,可以降低优先级,bug 激活指给自己,但是不要删除。
2、设计如此
字面意思:这不是 bug,需求设计就是这样写的。
解决方法:
(1)需求已更改,测试不知道,需要查看最新版设计,需求上没有的话就要和产品确认。
(2)需求上没明确说明,要和产品确认需求,并了解开发代码逻辑,例如下面这个 bug,如果关联删除不止涉及此模块,还涉及其他模块,且开发代码有和项目编码关联,关联不上不会再 app 端显示的。
3、无法重现
字面意思:开发不能重现的 bug
解决办法:
(1)需要再次确认最新版本,看是否能重现,如果操作步骤复杂,最好能亲自给开发操作,或者录屏、打电话沟通,帮助开发复现。
(2)我们自己也复现不了的,尽量回忆当时自己的操作步骤,一般都是在特定条件下出现的,若操作了半个小时候还没复现,就激活指给自己,日后测试过程中注意下,看是否能复现。
(3)好多开发是在本地环境去复现问题,有时候本地、线上代码不一致,所以要让开发去线上复现问题
4、外部原因
字面意思:发版、数据库更改、数据问题、服务器、网络原因导致的。
解决办法:
(1)此单位是后台配置的,不是前端代码写的,是测试对需求理解不透彻导致的,且没有配置单位,属于数据问题。
(2)开发意思是库表数据太大导致,实际是开发不清楚库表单位,没换算导致。
五、对于开发不改的 bug 怎么沟通
1、提高自身测试能力,能通过抓包进行前后端 bug 定位
如果实在分不清楚指给前端人员,前端人员是有责任去定位问题,如果是后端问题,由前端人员再指给后端。
2、提高逻辑思维,不能被开发忽悠(最好懂点简单的代码)
解决办法:和开发沟通无效(原因:不会改;不想改),找开发负责人沟通修改,一般开发负责人在能力较强、态度负责。如果开发负责人也觉得不需要修改或者不会改,就要叫上产品人员沟通,此问题是否解决。
3、测试人员要主动
开发遇到不会改的 bug,我们需要借鉴下其他系统有没有类似功能,提供给开发;如果没有可找开发负责人协助解决。
六、测试心得
每一位测试人员在测试过程中都已经有了自己心中认定的正确与错误的想法,要带入自己的想法和坚持,产品说的或做的也不一定全部正确,已有的功能也不一定全部正确,如果是问题要坚持反馈,找到问题缘由,开发、产品都可以改相关内容,直到问题得到解决(如果不是问题的话,我们就当深入了解了更多的东西)。
测试我觉得就是细心 + 全面 + 深度, 要有测试策略(重点),对时间分配要明晰,测试过程那些是需要关心的重点关心,哪些是需要去推动开发处理的就尽快抛出问题,也就是不捂问题;接下来就是对软件测试过程中整体数据流转一定要清晰。
总结:
感谢每一个认真阅读我文章的人!!!
作为一位过来人也是希望大家少走一些弯路,如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助。
-
文档获取方式: -
加入我的软件测试交流群:680748947免费获取~(同行大佬一起学术交流,每晚都有大佬直播分享技术知识点)
这份文档,对于想从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!
以上均可以分享,只需要你搜索vx公众号:程序员雨果,即可免费领取