前言
HashMap 本身不是线程安全的.
在多线程环境下使用哈希表可以使用:
- Hashtable(不推荐使用)
- ConcurrentHashMap(推荐使用)
HashMap
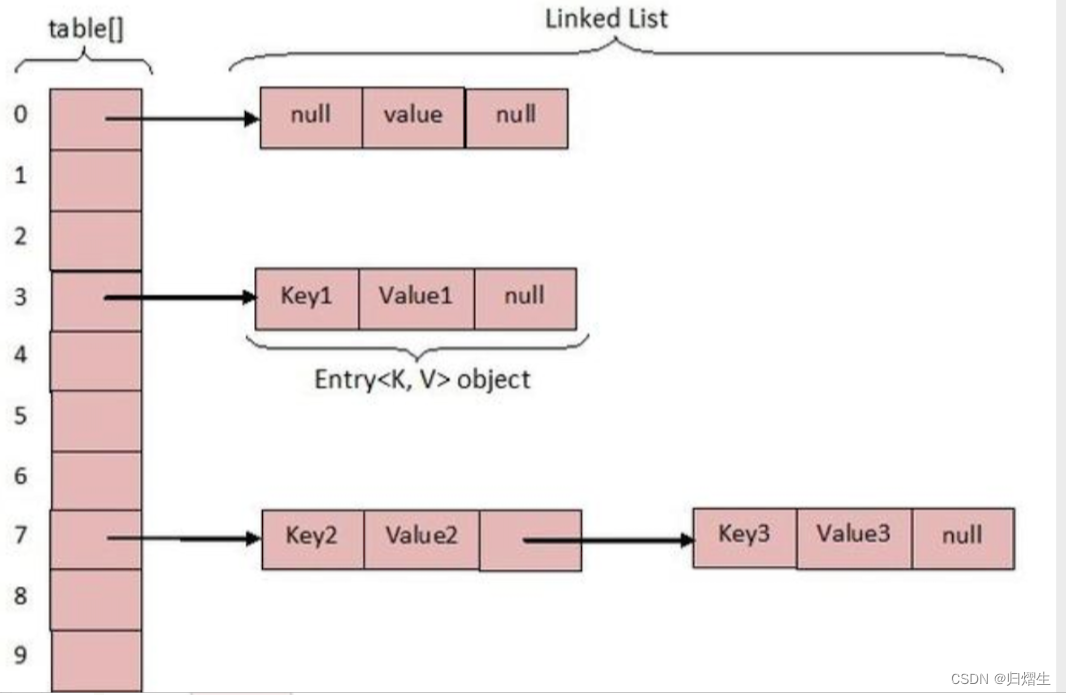
HashMap数据结构
根本: 数组 + 链表(jdk1.7)/数组+链表+红黑树(jdk1.8)(当链表长度超过阈值(8)将链表转为红黑树 时间复杂度降低为O(logn))
基本概念
容量(capacity ): 默认16 一个桶中的容量
加载因子(load factor): 默认0.75 即桶中的可利用大小
HashMap时间复杂度
若美好的状态下没有hash冲突 每个桶只有一个元素时间复杂度 O(1) ,最差是O(n) 红黑树则是O(logn)。
为什么HashMap非线程安全
1 put()时,若两个线程都put了同样的key,则值会被覆盖
(已被修复) 当A线程put()数据时都发现空间不够,执行resize()时,而同时B线程也put()数据也发现空间不够执行resize(),有可能在A线程rehash()生成新表时节点i->k,而B线程rehash()生成新表时又将节点k->j,导致生成了死循环(i.next=k;k.next=i;)当一旦进入这个链表,就会导致死循环。
扩容造成死循环和数据丢失
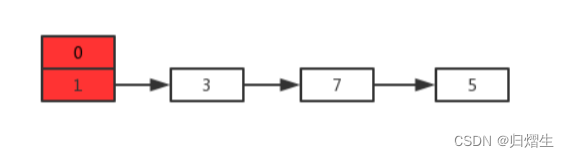
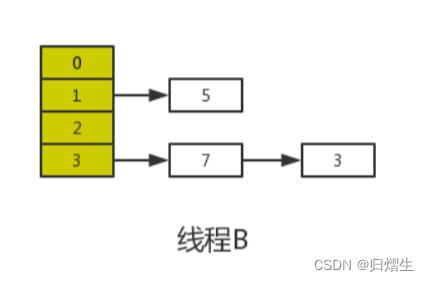
假设现在有两个线程A、B同时对下面这个HashMap进行扩容操作
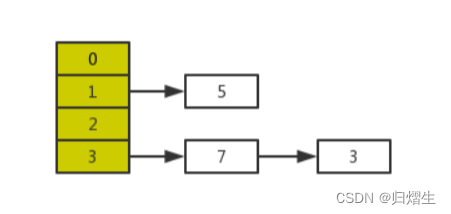
正常扩容后的结果是下面这样的:
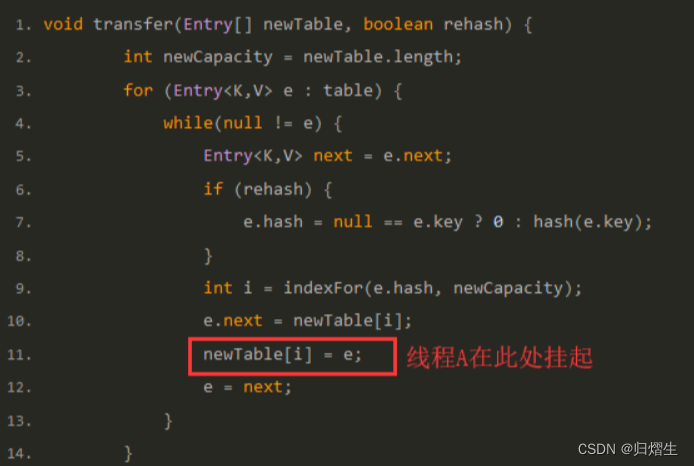
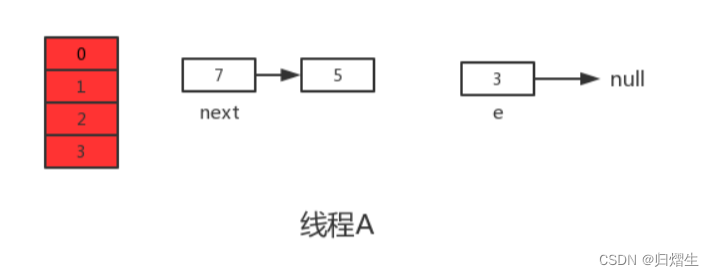
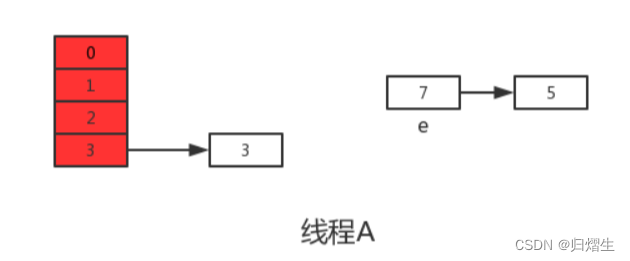
但是当线程A执行到上面transfer函数的第11行代码时,CPU时间片耗尽,线程A被挂起。即如下图中位置所示:
此时线程A中:e=3、next=7、e.next=null
当线程A的时间片耗尽后,CPU开始执行线程B,并在线程B中成功的完成了数据迁移
重点来了,根据Java内存模式可知,线程B执行完数据迁移后,此时主内存中newTable和table都是最新的,也就是说:7.next=3、3.next=null。
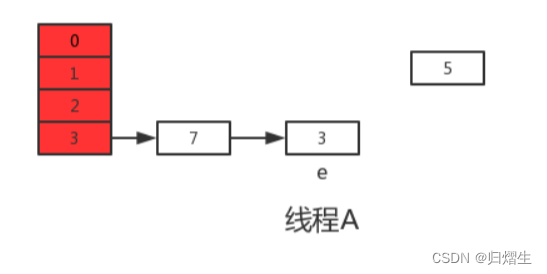
随后线程A获得CPU时间片继续执行newTable[i] = e,将3放入新数组对应的位置,执行完此轮循环后线程A的情况如下:
接着继续执行下一轮循环,此时e=7,从主内存中读取e.next时发现主内存中7.next=3,此时next=3,并将7采用头插法的方式放入新数组中,并继续执行完此轮循环,结果如下:
此时没任何问题。
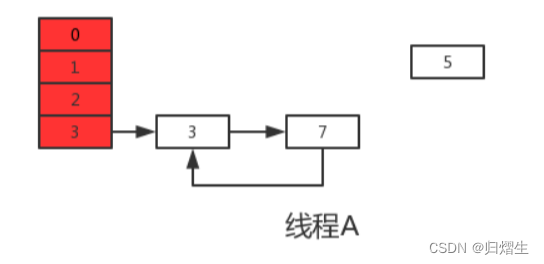
上轮next=3,e=3,执行下一次循环可以发现,3.next=null,所以此轮循环将会是最后一轮循环。
接下来当执行完e.next=newTable[i]即3.next=7后,3和7之间就相互连接了,当执行完newTable[i]=e后,3被头插法重新插入到链表中,执行结果如下图所示:
上面说了此时e.next=null即next=null,当执行完e=null后,将不会进行下一轮循环。到此线程A、B的扩容操作完成,很明显当线程A执行完后,HashMap中出现了环形结构,当在以后对该HashMap进行操作时会出现死循环。
并且从上图可以发现,元素5在扩容期间被莫名的丢失了,这就发生了数据丢失的问题。
其中第六行代码是判断是否出现hash碰撞,假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的,当线程A执行完第六行代码后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
除此之前,还有就是代码的第38行处有个++size,我们这样想,还是线程A、B,这两个线程同时进行put操作时,假设当前HashMap的zise大小为10,当线程A执行到第38行代码时,从主内存中获得size的值为10后准备进行+1操作,但是由于时间片耗尽只好让出CPU,线程B快乐的拿到CPU还是从主内存中拿到size的值10进行+1操作,完成了put操作并将size=11写回主内存,然后线程A再次拿到CPU并继续执行(此时size的值仍为10),当执行完put操作后,还是将size=11写回内存,此时,线程A、B都执行了一次put操作,但是size的值只增加了1,所有说还是由于数据覆盖又导致了线程不安全。
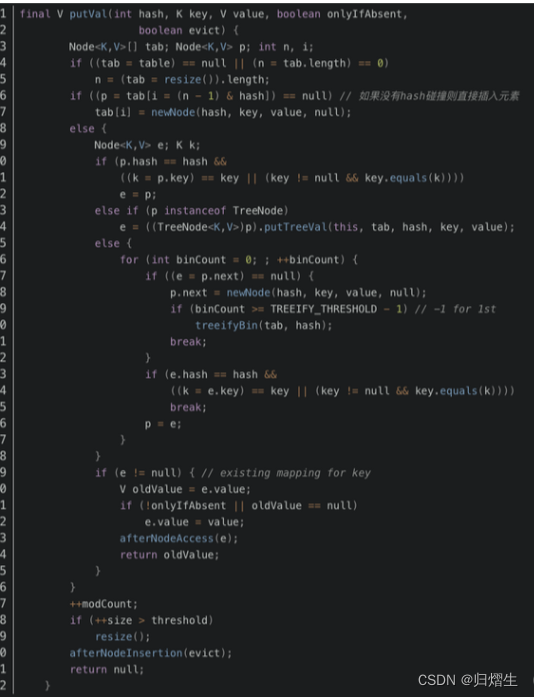
具体
- 首先HashMap本身线程不安全
- 其次HashMap的key值可以为空
下面是HashMap的hash方法,可以看出如果key值为空,hash方法的返回值为0
- HashMap 扩容是等某一次 put 后发现负载因子不达标后开始扩容, 新建一个表, 重新将元素哈希(具体细节有机会再讲)

HashTable
- Hashtable源码中的put方法中的key如果为空,hashCode方法会抛出空指针异常
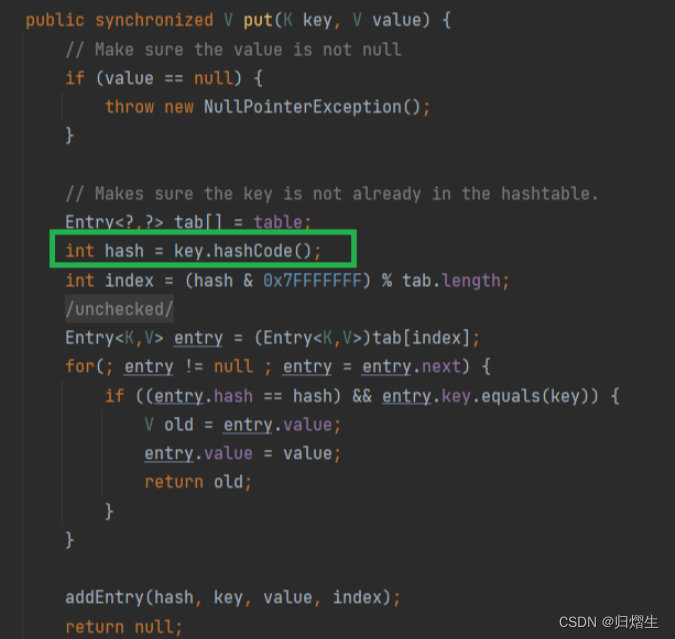
2.1**HashTable的线程安全只是简单的把关键方法加上了 synchronized 关键字. **

- 相当于直接针对 Hashtable 对象本身加锁.
- 如果多线程访问同一个 Hashtable 就会直接造成锁冲突.
- size 属性也是通过 synchronized 来控制同步, 也是比较慢的.
- 一旦触发扩容, 就由该线程完成整个扩容过程. 这个过程会涉及到大量的元素拷贝, 效率会非常低.
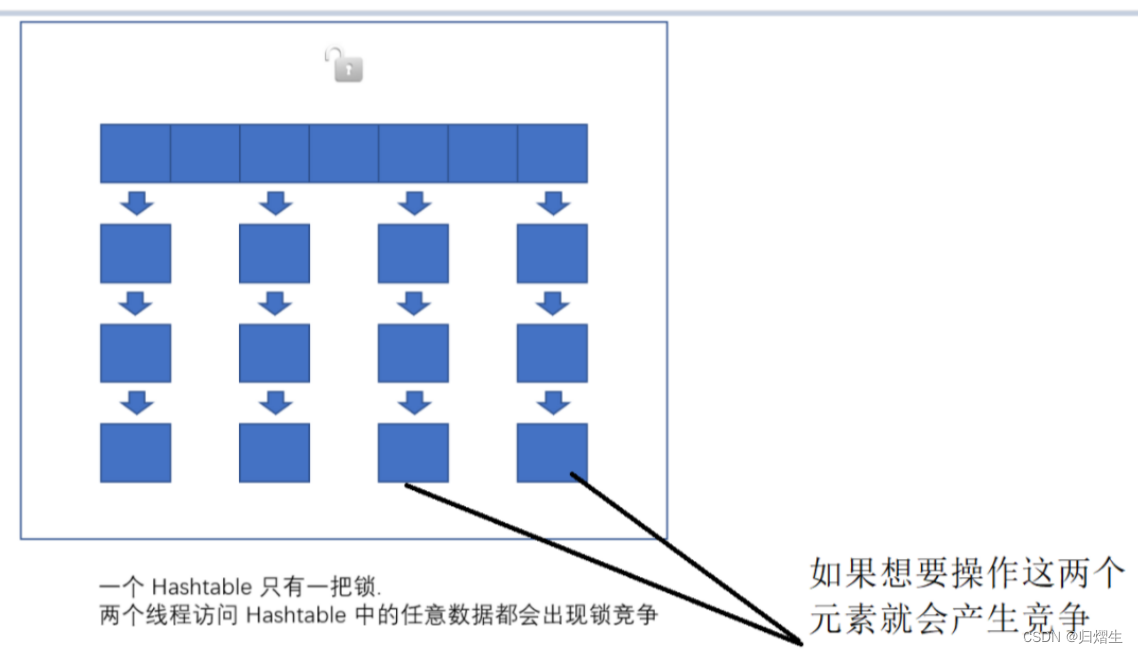
- 一个Hashtable只有一把锁,两个线程访问Hashtable中的任意数据都会出现锁竞争,就如上图,有两个线程要操作这两个元素,由于是一把大锁,就会产生竞争,但是仔细分析,这两操作在不同的哈希桶上,不牵扯修改同一个变量,因此就不会发生线程安全,所以上面的锁竞争是没有必要的。
- 如果两个修改落到同一个哈希桶上,有线程安全风险
ConcurrentHashMap
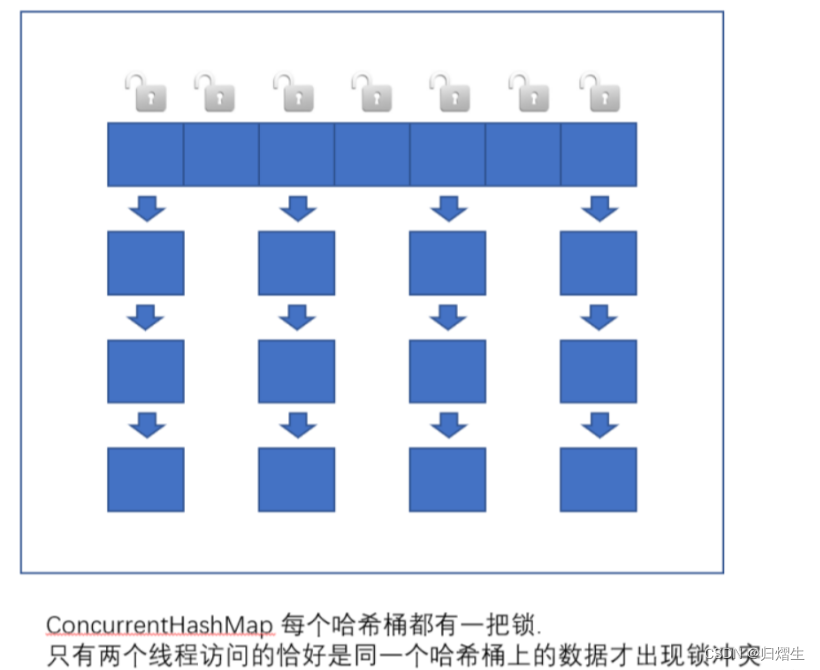
相比之下ConcurrentHashMap就做出了重大的改进,把锁的粒度细化了
- 读操作没有加锁(但是使用了 volatile 保证从内存读取结果), 只对写操作进行加锁. 加锁的方式仍然 是是用 synchronized, 但是不是锁整个对象, 而是 “锁桶” (用每个链表的头结点作为锁对象), 大大降 低了锁冲突的概率.
- 充分利用 CAS 特性. 比如 size 属性通过 CAS 来更新. 避免出现重量级锁的情况.
- 优化了扩容方式: 化整为零
「
发现需要扩容的线程, 只需要创建一个新的数组, 同时只搬几个元素过去.
扩容期间, 新老数组同时存在.
后续每个来操作 ConcurrentHashMap 的线程, 都会参与搬家的过程. 每个操作负责搬运一小 部分元素.
搬完最后一个元素再把老数组删掉.
这个期间, 插入只往新数组加.
这个期间, 查找需要同时查新数组和老数组」
此时一个哈希表上面的桶的个数可能会非常多,导致出现锁冲突的概率,大大降低了
扩容=申请更大的内存+搬运元素(搬运元素过程肯定要重新哈希)
上面讲的都是基于Java 8里的;在Java1.7里,ConcurrentHashMap不是每个桶一个锁,而是“分段锁”一个锁管若干个桶
- ConcurrenHashMap的key也不可以为空,看下面的源码中的put方法,如果key==null则会抛出空指针异常

总结
- HashMap: 线程不安全. key 允许为 null
- Hashtable: 线程安全. 使用 synchronized 锁 Hashtable 对象, 就是一把大锁,锁冲突极高,效率较低. key 不允许为 null.
- ConcurrentHashMap: 线程安全. 使用 synchronized 锁每个链表头结点, 锁冲突概率低, 充分利用 CAS 机制. 优化了扩容方式. key 不允许为 null