前言
随着业务数据量的增加,原来所有的数据都是在一个数据库上的,网络IO及文件IO都集中在一个数据库上的,因此CPU、内存、文件IO、网络IO都可能会成为系统瓶颈。当业务系统的数据容量接近或超过单台服务器的容量、QPS/TPS接近或超过单个数据库实例的处理极限等,此时,往往是采用垂直和水平结合的数据拆分方法,把数据服务和数据存储分布到多台数据库服务器上。
容量瓶颈:
从性能⽅⾯来说,由于关系型数据库⼤多采⽤ B+ 树类型的索引,数据量超过一定大小,B+Tree 索引的高度就会增加,而每增加一层高度,整个索引扫描就会多一次 IO。在数据量超过阈值的情况下,索引深度的增加也将使得磁盘访问的 IO 次数增加,进而导致查询性能的下降。
就比如MySQL而言,存储容量取决于多个因素,其中包括:数据库引擎选项、操作系统限制、数据类型等。MySQL支持的存储引擎包括InnoDB、MyISAM、Memory等,其中,每种存储引擎的存储容量都不尽相同。
下面是各种MySQL存储引擎的存储容量:
- InnoDB:理论容量为64TB
- MyISAM:理论容量为256TB
- Memory:由于使用内存而不是磁盘进行存储,容量取决于可用内存的大小
以下是MySQL中一些常用数据类型的存储空间:
- TINYINT:1字节
- INT:4字节
- BIGINT:8字节
- VARCHAR:根据列的实际用途动态存储
MySQL的最大存储容量是由文件系统限制的,一般为 2 GB 或 32 位文件系统上的 4 GB。受每个MySQL table的最大长度限制(默认为4GB)。MySQL可以支持的表行数不受限制,因此只要服务器的配置足够,应用程序可以处理海量的记录。
如果表的结构简单,则能承受的数据量相对比结构复杂时大些。据D.V.B 团队以及Cmshelp 团队做CMS 系统评测时的结果来看,MySQL单表大约在2千万条记录(4G)下能够良好运行,经过数据库的优化后5千万条记录(10G)下运行良好。
吞吐量瓶颈:
同时⾼并发访问请求也使得集中式数据库成为系统的最⼤瓶颈。所以数据库的吞吐量很重要,以及能同时开启的数据连接也有限。
MySQL的最大吞吐量取决于多个因素,包括硬件配置、数据库设计、网络带宽、并发访问量等等。在大多数情况下,MySQL的最大吞吐量会受到CPU和磁盘I/O的限制,以及同时启用最大线程数为10。如果CPU或磁盘I/O达到极限,那么MySQL的性能就会明显下降。
**对于一般的Web应用程序来说,MySQL的最大吞吐量通常在几千到几万的QPS(每秒查询数)之间。**但是,如果需要处理大规模数据和高并发请求,MySQL的最大吞吐量可能会更高。在这种情况下,通常需要通过优化数据库设计、调整硬件配置等方式来提高MySQL的性能和吞吐量。
为了提高MySQL的吞吐量,可以采取以下措施:
优化数据库设计:合理的数据库设计可以减少查询次数和查询时间,
使用索引:索引可以加速查询过程,减少查询时间,
调整缓存设置:适当调整MySQL的缓存设置可以减少磁盘I/O,
使用分布式数据库:分布式数据库可以将数据分散存储在多个节点上,
调整硬件配置:合理的硬件配置可以提高MySQL的吞吐量,例如增加CPU核心数、增加内存容量等。
总的来说,MySQL的最大吞吐量是一个动态的指标,需要根据具体情况进行评估和优化。通过合理的数据库设计和优化措施,可以提高MySQL的吞吐量,满足不同规模和需求的应用程序的性能要求。
分而治之
分治模式在存储领域的使用:数据分⽚
数据分⽚指按照某个维度将存放在单⼀数据库中的数据, 分散地存放⾄多个数据库或表中以达到提升性能瓶颈以及可⽤性的效果。数据分⽚的有效⼿段是对关系型数据库进⾏分库和分表。分库能够⽤于有效的分散对数据库单点的访问量;分表能够⽤于有效的数据量超过可承受阈值而产⽣的查询瓶颈, 解决MySQL 单表性能问题。而数据分⽚的拆分⽅式⼜分为垂直分⽚和⽔平分⽚。
分库的合理的时机, 请参见 3 高架构秒杀部分内容。
分表的合理的时机, 请参见 3 高架构秒杀部分内容。
一般都是使⽤多主多从的分⽚⽅式,可以有效的避免数据单点,从而提升数据架构的可⽤性。通过分库和分表进⾏数据的拆分来使得各个表的数据量保持在阈值以下,以及对流量进⾏疏导应对⾼访问量,是应对⾼并发和海量数据系统的有效⼿段。
分库分表的问题
也就是分布式事务问题。
介绍
Sharding-JDBC 是当当网开源的适用于微服务的分布式数据访问基础类库,完整的实现了分库分表,读写分离和分布式主键功能,并初步实现了柔性事务。
**ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar这3款相互独立的产品组成。**他们均提供标准化的数据分片、分布式事务 和 数据库治理功能,可适用于如Java同构、异构语言、云原生等各种多样化的应用场景。**Apache ShardingSphere 定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。**Apache ShardingSphere 目前已提供数十个 SPI 作为系统的扩展点,仍在不断增加中。
优势
**1、Sharding-JDBC直接封装JDBC API。**可以理解为增强版的JDBC驱动,旧代码迁移成本几乎为零。
**2、可适用于任何基于Java的ORM框架。**如JPA、Hibernate、Mybatis、Spring JDBC Template或直接使用JDBC。
**3、可基于任何第三方的数据库连接池。**如DBCP、C3P0、 BoneCP、Druid等。理论上可支持任意实现JDBC规范的数据库。虽然目前仅支持MySQL,但已有支持Oracle、SQLServer等数据库的计划。
Sharding-JDBC定位为轻量Java框架,使用客户端直连数据库,以jar包形式提供服务,无proxy代理层,无需额外部署,无其他依赖,DBA也无需改变原有的运维方式。Sharding-JDBC分片策略灵活,可支持等号、between、in等多维度分片,也可支持多分片键。SQL解析功能完善,支持聚合、分组、排序、limit、or等查询,并支持Binding Table以及笛卡尔积表查询。
与常见开源产品对比
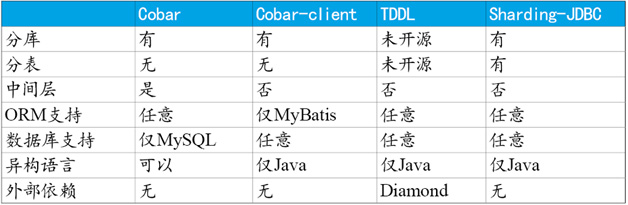
**通过以上表格可以看出,Cobar(MyCat)属于中间层方案,在应用程序和MySQL之间搭建一层Proxy。中间层介于应用程序与数据库间,需要做一次转发,而基于JDBC协议并无额外转发,直接由应用程序连接数据库,性能上有些许优势。**这里并非说明中间层一定不如客户端直连,除了性能,需要考虑的因素还有很多,中间层更便于实现监控、数据迁移、连接管理等功能。
Cobar-Client、TDDL和Sharding-JDBC均属于客户端直连方案。此方案的优势在于轻便、兼容性、性能以及对DBA影响小。其中Cobar-Client的实现方式基于ORM(Mybatis)框架,其兼容性与扩展性不如基于JDBC协议的后两者。
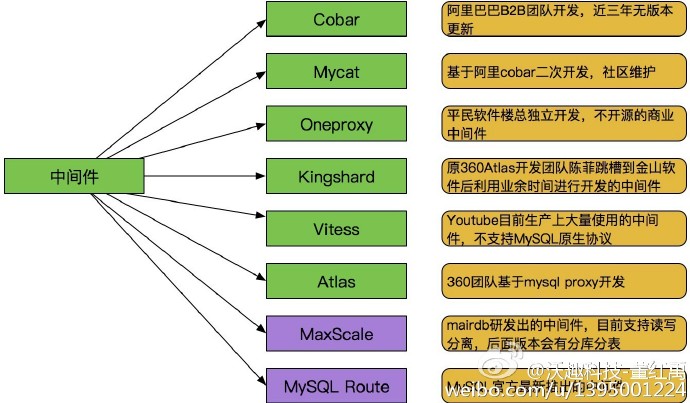
目前常用的就是Cobar(MyCat)与Sharding-JDBC两种方案
MyCAT
MyCAT它的后端可以支持MySQL, SQL Server, Oracle, DB2, PostgreSQL等主流数据库,也支持MongoDB这种新型NoSQL方式的存储,未来还会支持更多类型的存储。MyCAT是一个强大的数据库中间件,不仅仅可以用作读写分离,以及分表分库、容灾管理,而且可以用于多租户应用开发、云平台基础设施,让架构具备很强的适应性和灵活性,借助于MyCAT智能优化模块,系统的数据访问瓶颈和热点一目了然,根据这些统计分析数据,你可以自动或手工调整后端存储,将不同的表隐射到不同存储引擎上,而整个应用的代码一行也不用改变。
MyCAT是在Cobar基础上发展的版本,两个显著提高:
1、后端由BIO改为NIO,并发量有大幅提高;
2、增加了对Order By, Group By, Limit等聚合功能
Sharding-JDBC
Sharding-JDBC定位为轻量Java框架,使用客户端直连数据库,以jar包形式提供服务,无proxy代理层,无需额外部署,无其他依赖,DBA也无需改变原有的运维方式。适用于中小企业、或者中小团队。Sharding-JDBC分片策略灵活,可支持等号、between、in等多维度分片,也可支持多分片键。SQL解析功能完善,支持聚合、分组、排序、limit、or等查询,并支持Binding Table以及笛卡尔积表查询。
一般情况下,开发维度的数据分片,大多是以水平切分模式(水平分库、分表)为基础来说的,垂直分片主要在于运维维度,或者做存储的深级改造的时候。
简单来说,数据分片的工作分为两大工作,分片的拆分和分片的路由。
Sharding-JDBC数据分片
数据分片就是按照分片规则(分片算法)把数据分到若干个shard、partition当中。主要的分片算法有精确分片算法、范围分片算法、复合分片算法、Hint分片算法。
分片算法类型
1、精确分片算法
精确分片算法(PreciseShardingAlgorithm)用于单个字段作为分片键,SQL中有 = 与 IN 等条件的分片,需要在标准分片策略(StandardShardingStrategy )下使用。
2、范围分片算法
范围分片算法(RangeShardingAlgorithm)用于单个字段作为分片键,SQL中有 BETWEEN AND、>、<、>=、<= 等条件的分片,需要在标准分片策略(StandardShardingStrategy )下使用。
3、复合分片算法
复合分片算法(ComplexKeysShardingAlgorithm)用于多个字段作为分片键的分片操作,同时获取到多个分片健的值,根据多个字段处理业务逻辑。需要在复合分片策略(ComplexShardingStrategy )下使用。
4、Hint分片算法
Hint分片算法(HintShardingAlgorithm)稍有不同,上边的算法中我们都是解析SQL 语句提取分片键,并设置分片策略进行分片。但有些时候我们并没有使用任何的分片键和分片策略,可还想将 SQL 路由到目标数据库和表,就需要通过手动干预指定SQL的目标数据库和表信息,这也叫强制路由。
算法与算法类
sharding-jdbc 提供了多种分片算法,其内部实现依据抽象分片算法类:ShardingAlgorithm
精确分片算法:对应PreciseShardingAlgorithm类,主要用于处理 = 和 IN的分片;
区间分片算法:对应RangeShardingAlgorithm类,主要用于处理 BETWEEN AND, >, <, >=, <= 分片;
复合分片算法:对应ComplexKeysShardingAlgorithm类,用于处理使用多键作为分片键进行分片的场景;
Hint分片算法:对应HintShardingAlgorithm类,用于处理使用 Hint 行分片的场景;
分片策略
分片策略是一种抽象的概念,实际分片操作的是由分片算法和分片健来完成的。
1、标准分片策略
标准分片策略适用于单分片键,此策略支持 PreciseShardingAlgorithm 和 RangeShardingAlgorithm 两个分片算法。其中 PreciseShardingAlgorithm 是必选的,用于处理 = 和 IN 的分片。RangeShardingAlgorithm 是可选的,用于处理BETWEEN AND, >, <,>=,<= 条件分片,如果不配置RangeShardingAlgorithm,SQL中的条件等将按照全库路由处理。
2、复合分片策略
复合分片策略,对照ComplexShardingStrategy。同样支持对 SQL语句中的 =,>, <, >=, <=,IN和 BETWEEN AND 的分片操作。不同的是它支持多分片键,具体分配片细节完全由应用开发者实现。
3、行表达式分片策略(inline内联分片策略)
行表达式分片策略,支持对 SQL语句中的 = 和 IN 的分片操作,但只支持单分片键。这种策略通常用于简单的分片,不需要自定义分片算法,可以直接在配置文件中接着写规则。t_order_$->{t_order_id % 4} 代表 t_order 对其字段 t_order_id取模,拆分成4张表,而表名分别是t_order_0 到 t_order_3。
4、强制分片策略 (Hint分片策略)
**Hint 分片策略,通过指定分片健而非从 SQL 中提取分片健的方式进行分片的策略。**对于分⽚值⾮ SQL 决定,不是来自于分片建,甚至连分片建都没有 ,而由其他外置条件决定的场景,可使⽤Hint 分片策略 。Hint 分片算法,是手工设置的⽅式,进⾏分⽚的策略。
5、不分片策略
对应 NoneShardingStrategy。不分⽚的策略。这种严格来说不算是一种分片策略了,只是ShardingSphere也提供了这么一个配置。
核心概念
分片键
**分⽚键⽤于分⽚的字段,是将数据库(表)⽔平拆分的关键字段。**在对表中的数据进行分片时,首先要选出一个分片键(Shard Key),即用户可以通过这个字段进行数据的水平拆分。
说明
- 除了使用单个字段作为分片件, sharding-jdbc 还支持根据多个字段作为分片健进行分片。
- SQL 中如果⽆分⽚字段,将执⾏全路由,性能较差。
数据节点
数据节点是分库分表中一个不可再分的最小数据单元(表),它由数据源名称和数据表组成。
逻辑表
逻辑表是指一组具有相同逻辑和数据结构表的总称。
真实表
真实表也就是 t_order_n 数据库中真实存在的物理表。
数据执行过程
执行过程
数据分片之后,数据查询执行过程为:
SQL 解析 -> 查询优化 -> SQL 路由 -> SQL 改写 -> SQL 执⾏ -> 结果归并。
1、SQL 解析
将用户提交的 SQL 查询语句解析为数据库可以理解的语法结构,以便后续处理。说白了就是将拆分后的SQL转换为抽象语法树,通过对抽象语法树遍历,提炼出分片所需的上下文。上下文包含查询字段信息(Field)、表信息(Table)、查询条件(Condition)、排序信息(Order By)、分组信息(Group By)以及分页信息(Limit)等,并标记出 SQL中有可能需要改写的位置。
Sharding-JDBC有提供专门的SQL解析引擎,支持多种方言的MySQL、PostgreSQL、SQLServer、Oracle、SQL92。
抽象语法树。解析过程分为词法解析和语法解析。词法解析器⽤于将 SQL 拆解为不可再分的原⼦符号,称为 Token。并根据不同数据库⽅⾔所提供的字典,将其归类为关键字,表达式,字⾯量和操作符。再使⽤语法解析器将 SQL 转换为抽象语法树。
2、查询优化
对解析后的查询进行优化,选择最优的执行计划(待确定是否存在获取表结构、索引数据),以便在执行查询时能够高效地访问数据。
3、SQL 路由
SQL 路由通过解析分片上下文,匹配到用户配置的分片策略,并生成路由路径。简单点理解就是可以根据我们配置的分片策略计算出 SQL该在哪个库的哪个表中执行,而SQL路由又根据有无分片健区分出 分片路由 和 广播路由。
其中有分⽚键的路由叫分片路由,细分为直接路由、标准路由和笛卡尔积路由这3种类型。

直接路由(暗示路由)
通过使用 HintAPI 直接将 SQL路由到指定⾄库表的一种分⽚方式,而且直接路由可以⽤于分⽚键不在SQL中的场景,还可以执⾏包括⼦查询、⾃定义函数等复杂情况的任意SQL。因此它的兼容性最好,可以执行包括子查询、自定义函数等复杂情况的任意 SQL。直接路由还可以用于分片键不在 SQL 中的场景。例如,设置用于数据库分片的值为 3
标准路由
标准路由是最推荐也是最为常⽤的分⽚⽅式,它的适⽤范围是不包含关联查询或仅包含绑定表之间关联查询的SQL。
- 当 SQL分片健的运算符为
=时,路由结果将落⼊单库(表),路由策略返回的是单个的目标。 - 当分⽚运算符是
BETWEEN或IN等范围时,路由结果则不⼀定落⼊唯⼀的库(表),因此⼀条逻辑SQL最终可能被拆分为多条⽤于执⾏的真实SQL。
笛卡尔积路由
笛卡尔路由是由非绑定表之间的关联查询产生的,查询性能较低尽量避免走此路由模式。笛卡尔路由是最复杂的情况,它无法根据绑定表的关系定位分片规则,因此非绑定表之间的关联查询需要拆解为笛卡尔积组合执行。
例如:SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
广播路由
无分⽚键的路由又叫做广播路由,可以划分为全库表路由、全库路由、 全实例路由、单播路由和阻断路由这 5种类型。
全库表路由
全库表路由针对的是数据库 DQL和 DML,以及 DDL等操作,当执行一条逻辑表 t_order SQL时,在所有分片库中对应的真实表 t_order_0 ··· t_order_n 内逐一执行。
全库路由
全库路由主要是对数据库层面的操作,比如数据库 SET 类型的数据库管理命令,以及 TCL 这样的事务控制语句。对逻辑库设置 autocommit 属性后,所有对应的真实库中都执行该命令。
全实例路由
全实例路由是针对数据库实例的 DCL 操作(设置或更改数据库用户或角色权限),比如:创建一个用户 order ,这个命令将在所有的真实库实例中执行,以此确保 order 用户可以正常访问每一个数据库实例。
单播路由
单播路由用来获取某一真实表信息,比如获得表的描述信息:
阻断路由
⽤来屏蔽SQL对数据库的操作,例如:USE order_db;这个命令不会在真实数据库中执⾏,因为 ShardingSphere 采⽤的是逻辑 Schema(数据库的组织和结构) ⽅式,所以无需将切换数据库的命令发送⾄真实数据库中。
4、SQL 改写
在数据库分片中,由于数据分布在多个节点上,可能需要对原始查询进行改写,以便在每个分片节点上执行局部查询,然后合并结果。当分库分表以后真实数据库中 t_order 表就不存在了,而是被拆分成多个子表 t_order_n 分散在不同的数据库内,还按原SQL执行显然是行不通的,这时需要将分表配置中的逻辑表名称改写为路由之后所获取的真实表名称。
5、SQL 执行
在各个分片节点上执行局部查询。
6、结果归并
将分片节点上的局部查询结果进行合并,生成最终的查询结果。而我们SQL中的排序、分组、分页和聚合等语法,均是在归并后的结果集上进行操作的。
小结
数据库分片的引入主要是为了处理大规模数据集和高并发负载,以提高数据库的扩展性和性能。然而,分片架构也会引入一些复杂性和管理难题,因此在设计和实施分片时需要仔细考虑各个方面,包括数据分布、查询路由、数据一致性等。
原理分析
从源码上看,Sharding-JDBC对原有的 DataSource、Connection 等接口扩展成 ShardingDataSource、ShardingConnection,而对外暴露的分片操作接口与 JDBC 规范中所提供的接口完全一致,只要熟悉 JDBC 就可以轻松应用 Sharding-JDBC 来实现分库分表。
疑问
1、分库分表后,模糊条件查询怎么处理?
目前绝大部分公司的核心数据都是:以RDBMS存储为主,NoSQL/NewSQL存储为辅!RDBMS互联网公司又以MySQL为主,NoSQL比较具有代表性的是MongoDB,es;NewSQL比较具有代表性的是TiDB。
但是,MySQL单表可以存储10亿级数据,行业认可的,MySQL单表容量在1KW以下, 所以必然要分库分表,以sharding-jdbc为例,有多少个分库分表,就要并发路由到多少个分库分表中执行,然后对结果进行合并。尤其是有些模糊条件查询,或者上十个条件筛选。这种条件查询相对于有sharding column的条件查询性能很明显会下降很多。所以建议有sharding column的查询走分库分表,一些模糊查询,或者多个不固定条件筛选则走es,海量存储则交给HBase。
HBase特点:
所有字段的全量数据保存到HBase中,Hadoop体系下的HBase存储能力是海量的,rowkey查询速度快,快如闪电(可以优化到50Wqps甚至更高)。
es特点:
es的多条件检索能力非常强大。可能参与条件检索的字段索引到ES中。这个方案把es和HBase的优点发挥的淋漓尽致,同时又规避了它们的缺点,可以说是一个扬长避免的最佳实践。这就是经典的ES+HBase组合方案,即索引与数据存储隔离的方案。
总结
合理的利用中间件,若是数据库单表承受压力快达到上限了,可以采用分库分表。