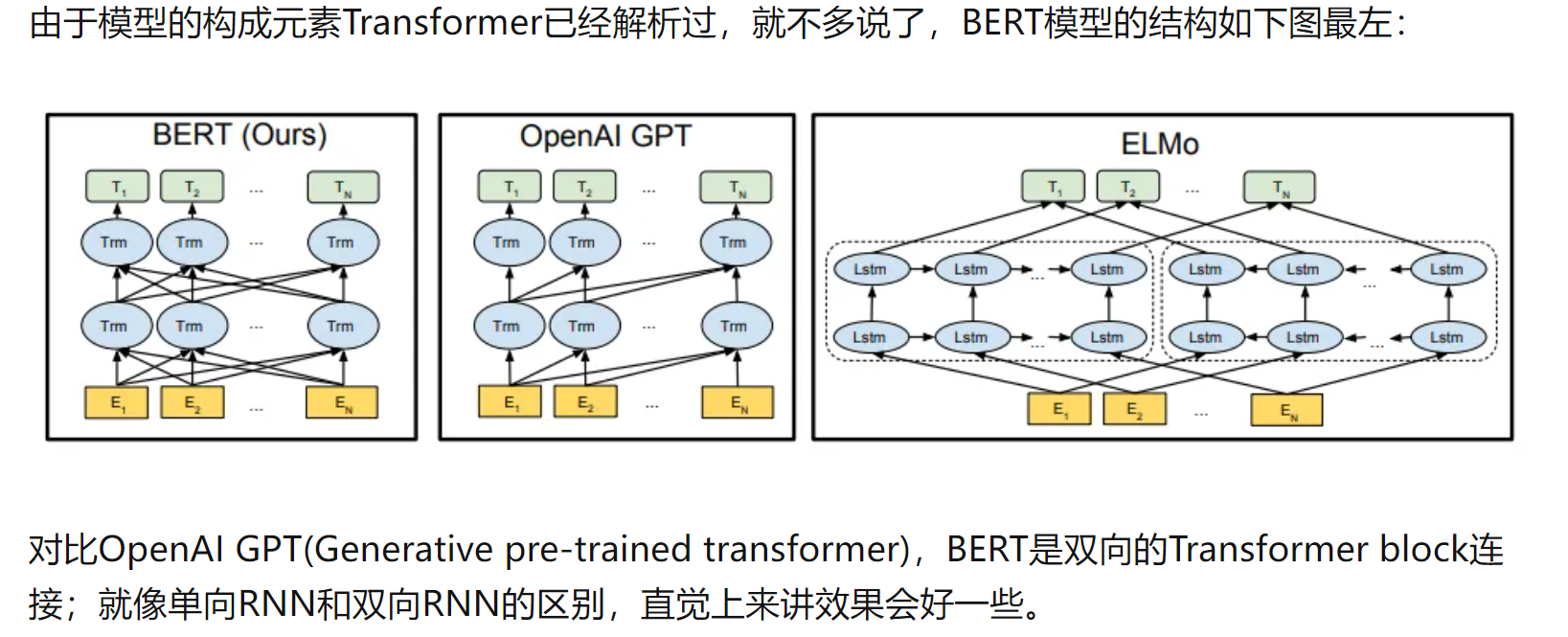
BERT概述
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不能获要预测的信息的。在大型语料库(Wikipedia + BookCorpus)上训练一个大型模型(12 层到 24 层 Transformer)很长时间(1M 更新步骤),这就是 BERT。
-
模型的主要创新点都在pre-train方法上,即用了
Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。- Masked LM --> word
- Next Sentence Prediction --> sentence
Mask掩码
在原始预处理代码中,我们随机选择 WordPiece 标记进行掩码。
例如:
Input Text: the man jumped up , put his basket on phil ##am ##mon ' s head
Original Masked Input: [MASK] man [MASK] up , put his [MASK] on phil [MASK] ##mon ' s head
全字掩码改进:
Whole Word Masked Input: the man [MASK] up , put his basket on [MASK] [MASK] [MASK] ' s head
改进思想:
训练是相同的——我们仍然独立预测每个屏蔽的 WordPiece 标记。改进来自于这样的事实:对于已拆分为多个 WordPieces 的单词,原始预测任务过于“简单”。
- 一次预测一个mask太简单了,把原来的mask周围的词全部都mask掉,提高难度。
Enmbedding
三种Embedding求和构成的:
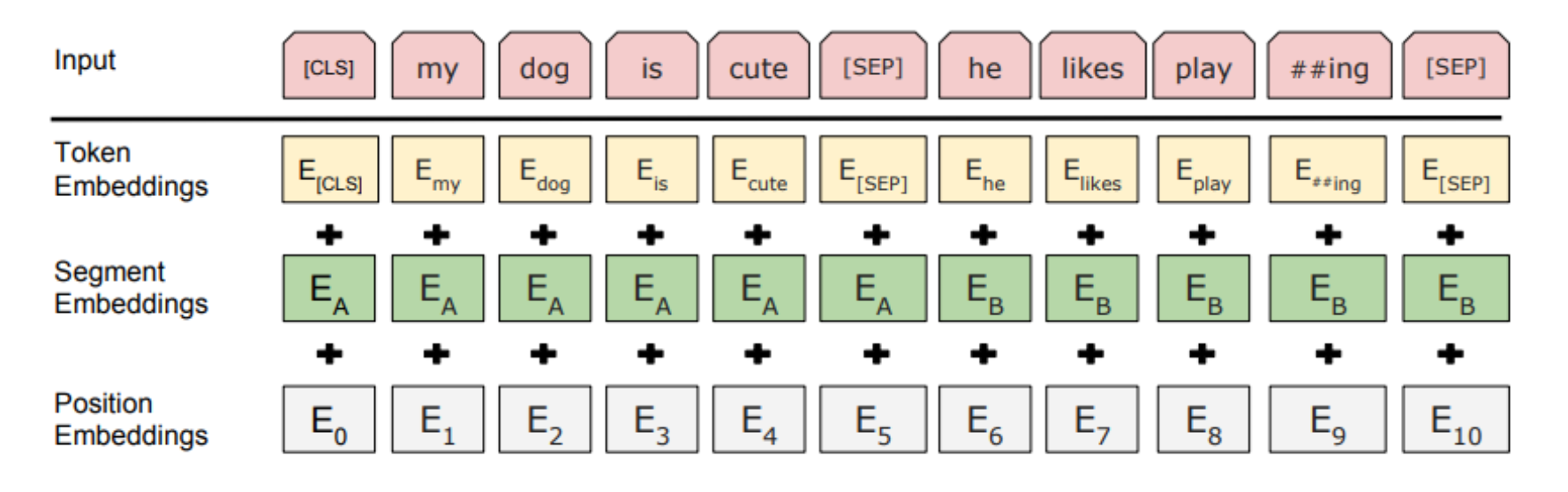
- Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任务
- Segment Embeddings用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务
- Position Embeddings和之前文章中的Transformer不一样,不是三角函数而是学习出来的
Pre-training Task 1: Masked Language Model
为什么要bidirection?
意思就是如果使用预训练模型处理其他任务,那人们想要的肯定不止某个词左边的信息,而是左右两边的信息。
- 在训练过程中作者
随机mask 15%的token,而不是把像cbow一样把每个词都预测一遍。最终的损失函数只计算被mask掉那个token。
Input: the man went to the [MASK1] . he bought a [MASK2] of milk.
Labels: [MASK1] = store; [MASK2] = gallon
mask的技巧:
Mask如何做也是有技巧的,如果一直用标记[MASK]代替(在实际预测时是碰不到这个标记的)会影响模型,所以随机mask的时候10%的单词会被替代成其他单词,10%的单词不替换,剩下80%才被替换为[MASK]。
- 要注意的是Masked LM预训练阶段模型是不知道真正被mask的是哪个词,所以模型每个词都要关注。
sequence_length:
- 因为序列长度太大(512)会影响训练速度,所以90%的steps都用
seq_len=128训练,余下的10%步数训练512长度的输入。
Pre-training Task 2: Next Sentence Prediction
因为涉及到QA和NLI之类的任务,增加了第二个预训练任务
- 目的是让模型理解两个句子之间的联系。训练的输入是句子A和B,B有一半的几率是A的下一句,输入这两个句子,模型预测B是不是A的下一句。预训练的时候可以达到97-98%的准确度。
注意:作者特意说了语料的选取很关键,要选用document-level的而不是sentence-level的,这样可以具备抽象连续长序列特征的能力。
Sentence A: the man went to the store .
Sentence B: he bought a gallon of milk .
Label: IsNextSentence
Sentence A: the man went to the store .
Sentence B: penguins are flightless .
Label: NotNextSentence
fine-tuning
code:run_classifier.py / run_squad.py(tpu)
Sentence (and sentence-pair) classification tasks
在运行此示例之前,您必须通过运行此脚本下载 GLUE 数据并将其解压到某个目录 $GLUE_DIR 。接下来,下载 BERT-Base 检查点并将其解压缩到某个目录 $BERT_BASE_DIR 。
此示例代码在 Microsoft Research Paraphrase Corpus (MRPC) 语料库上微调 BERT-Base ,该语料库仅包含 3,600 个示例,并且可以在大多数 GPU 上在几分钟内进行微调。
export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12
export GLUE_DIR=/path/to/gluepython run_classifier.py \--task_name=MRPC \--do_train=true \--do_eval=true \--data_dir=$GLUE_DIR/MRPC \--vocab_file=$BERT_BASE_DIR/vocab.txt \--bert_config_file=$BERT_BASE_DIR/bert_config.json \--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \--max_seq_length=128 \--train_batch_size=32 \--learning_rate=2e-5 \--num_train_epochs=3.0 \--output_dir=/tmp/mrpc_output/
***** Eval results *****eval_accuracy = 0.845588eval_loss = 0.505248global_step = 343loss = 0.505248
训练完分类器后,您可以使用 --do_predict=true 命令在推理模式下使用它。输入文件夹中需要有一个名为 test.tsv 的文件。输出将在输出文件夹中名为 test_results.tsv 的文件中创建。每行将包含每个样本的输出,列是类概率。
export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12
export GLUE_DIR=/path/to/glue
export TRAINED_CLASSIFIER=/path/to/fine/tuned/classifierpython run_classifier.py \--task_name=MRPC \--do_predict=true \--data_dir=$GLUE_DIR/MRPC \--vocab_file=$BERT_BASE_DIR/vocab.txt \--bert_config_file=$BERT_BASE_DIR/bert_config.json \--init_checkpoint=$TRAINED_CLASSIFIER \--max_seq_length=128 \--output_dir=/tmp/mrpc_output/
影响内存使用的因素有:
-
max_seq_length :发布的模型使用高达 512 的序列长度进行训练,但您可以使用更短的最大序列长度进行微调以节省大量内存。这是由示例代码中的 max_seq_length 标志控制的。
-
train_batch_size :内存使用量也与批量大小成正比。
-
模型类型, BERT-Base 与 BERT-Large : BERT-Large 模型比 BERT-Base 需要更多的内存。
-
优化器:BERT的默认优化器是Adam,它需要大量额外的内存来存储 m 和 v 向量。切换到内存效率更高的优化器可以减少内存使用量,但也会影响结果。我们还没有尝试过其他优化器进行微调。
代码详解
class InputExample(object):"""A single training/test example for simple sequence classification."""def __init__(self, guid, text_a, text_b=None, label=None):"""Constructs a InputExample.Args:guid: Unique id for the example.text_a: string. The untokenized text of the first sequence. For singlesequence tasks, only this sequence must be specified.text_b: (Optional) string. The untokenized text of the second sequence.Only must be specified for sequence pair tasks.label: (Optional) string. The label of the example. This should bespecified for train and dev examples, but not for test examples."""self.guid = guidself.text_a = text_aself.text_b = text_bself.label = label
class DataProcessor(object):"""Base class for data converters for sequence classification data sets."""def get_train_examples(self, data_dir):"""Gets a collection of `InputExample`s for the train set."""raise NotImplementedError()def get_dev_examples(self, data_dir):"""Gets a collection of `InputExample`s for the dev set."""raise NotImplementedError()def get_test_examples(self, data_dir):"""Gets a collection of `InputExample`s for prediction."""raise NotImplementedError()def get_labels(self):"""Gets the list of labels for this data set."""raise NotImplementedError()@classmethoddef _read_tsv(cls, input_file, quotechar=None):"""Reads a tab separated value file."""with tf.gfile.Open(input_file, "r") as f:reader = csv.reader(f, delimiter="\t", quotechar=quotechar)lines = []for line in reader:lines.append(line)return lines
- XNLI(Cross-lingual Natural Language Inference)数据集是一个用于跨语言自然语言推理任务的数据集。它是在自然语言推理(NLI)任务的基础上进行扩展,旨在促进多语言之间的推理能力研究和跨语言模型的发展。
- XNLI数据集是在原始的英语NLI数据集SNLI(Stanford Natural Language Inference)的基础上构建的。它包含来自15种不同语言的句子对,涵盖了多种语言家族,如印欧语系、南亚语系、尼日尔-刚果语系等。每个语言都有约5,000个训练样本和2,500个开发样本。
- XNLI数据集的目标是通过将SNLI数据集翻译成其他语言,从而为多语言推理任务提供一个统一的基准。对于给定的句子对,模型需要判断它们之间的关系是蕴含(entailment)、矛盾(contradiction)还是中性(neutral)。通过在多语言上进行推理,可以评估模型在不同语言之间的泛化能力和跨语言理解能力。XNLI数据集的发布促进了跨语言自然语言处理的研究和发展,为构建能够处理多语言文本的模型提供了基准和评估标准。
- 取数据,注意是官方数据集的输入格式
class XnliProcessor(DataProcessor):"""Processor for the XNLI data set."""def __init__(self):self.language = "zh"def get_train_examples(self, data_dir):"""See base class."""lines = self._read_tsv(os.path.join(data_dir, "multinli","multinli.train.%s.tsv" % self.language))examples = []for (i, line) in enumerate(lines):if i == 0:continueguid = "train-%d" % (i)text_a = tokenization.convert_to_unicode(line[0])text_b = tokenization.convert_to_unicode(line[1])label = tokenization.convert_to_unicode(line[2])if label == tokenization.convert_to_unicode("contradictory"):label = tokenization.convert_to_unicode("contradiction")examples.append(InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label))return examplesdef get_dev_examples(self, data_dir):"""See base class."""lines = self._read_tsv(os.path.join(data_dir, "xnli.dev.tsv"))examples = []for (i, line) in enumerate(lines):if i == 0:continueguid = "dev-%d" % (i)language = tokenization.convert_to_unicode(line[0])if language != tokenization.convert_to_unicode(self.language):continuetext_a = tokenization.convert_to_unicode(line[6])text_b = tokenization.convert_to_unicode(line[7])label = tokenization.convert_to_unicode(line[1])examples.append(InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label))return examplesdef get_labels(self):"""See base class."""return ["contradiction", "entailment", "neutral"]
- 单条数据的输入格式
class InputFeatures(object):"""A single set of features of data."""def __init__(self,input_ids,input_mask,segment_ids,label_id,is_real_example=True):self.input_ids = input_idsself.input_mask = input_maskself.segment_ids = segment_idsself.label_id = label_idself.is_real_example = is_real_example- 转化成token的处理函数
def convert_single_example(ex_index, example, label_list, max_seq_length,tokenizer):"""Converts a single `InputExample` into a single `InputFeatures`."""# 如果是TPU上的话,要把每一个batch填满,需要padding的sentenceif isinstance(example, PaddingInputExample):return InputFeatures(input_ids=[0] * max_seq_length,input_mask=[0] * max_seq_length,segment_ids=[0] * max_seq_length,label_id=0,is_real_example=False)# id和label的一个映射关系label_map = {}for (i, label) in enumerate(label_list):label_map[label] = i# 句子变成token序列tokens_a = tokenizer.tokenize(example.text_a)tokens_b = Noneif example.text_b:tokens_b = tokenizer.tokenize(example.text_b)if tokens_b:# Modifies `tokens_a` and `tokens_b` in place so that the total# length is less than the specified length.# Account for [CLS], [SEP], [SEP] with "- 3"_truncate_seq_pair(tokens_a, tokens_b, max_seq_length - 3)else:# Account for [CLS] and [SEP] with "- 2"if len(tokens_a) > max_seq_length - 2:tokens_a = tokens_a[0:(max_seq_length - 2)]# The convention in BERT is:# (a) For sequence pairs:# tokens: [CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP]# type_ids: 0 0 0 0 0 0 0 0 1 1 1 1 1 1# (b) For single sequences:# tokens: [CLS] the dog is hairy . [SEP]# type_ids: 0 0 0 0 0 0 0## Where "type_ids" are used to indicate whether this is the first# sequence or the second sequence. The embedding vectors for `type=0` and# `type=1` were learned during pre-training and are added to the wordpiece# embedding vector (and position vector). This is not *strictly* necessary# since the [SEP] token unambiguously separates the sequences, but it makes# it easier for the model to learn the concept of sequences.## For classification tasks, the first vector (corresponding to [CLS]) is# used as the "sentence vector". Note that this only makes sense because# the entire model is fine-tuned.# 加入cls和sep到token中,构成inputtokens = []segment_ids = []tokens.append("[CLS]")segment_ids.append(0)for token in tokens_a:tokens.append(token)segment_ids.append(0)tokens.append("[SEP]")segment_ids.append(0)if tokens_b:for token in tokens_b:tokens.append(token)segment_ids.append(1)tokens.append("[SEP]")segment_ids.append(1)input_ids = tokenizer.convert_tokens_to_ids(tokens)# The mask has 1 for real tokens and 0 for padding tokens. Only real# tokens are attended to.input_mask = [1] * len(input_ids)# Zero-pad up to the sequence length.while len(input_ids) < max_seq_length:input_ids.append(0)input_mask.append(0)segment_ids.append(0)assert len(input_ids) == max_seq_lengthassert len(input_mask) == max_seq_lengthassert len(segment_ids) == max_seq_lengthlabel_id = label_map[example.label]if ex_index < 5:tf.logging.info("*** Example ***")tf.logging.info("guid: %s" % (example.guid))tf.logging.info("tokens: %s" % " ".join([tokenization.printable_text(x) for x in tokens]))tf.logging.info("input_ids: %s" % " ".join([str(x) for x in input_ids]))tf.logging.info("input_mask: %s" % " ".join([str(x) for x in input_mask]))tf.logging.info("segment_ids: %s" % " ".join([str(x) for x in segment_ids]))tf.logging.info("label: %s (id = %d)" % (example.label, label_id))feature = InputFeatures(input_ids=input_ids,input_mask=input_mask,segment_ids=segment_ids,label_id=label_id,is_real_example=True)return feature
- 句子对的任务
def _truncate_seq_pair(tokens_a, tokens_b, max_length):"""Truncates a sequence pair in place to the maximum length.这段代码是一个用于截断序列对的函数。它的作用是将序列对(tokens_a和tokens_b)截断到最大长度(max_length)。函数使用了一个简单的启发式方法来截断序列。它会逐个删除一个token,直到序列对的总长度小于等于最大长度。如果tokens_a的长度大于tokens_b的长度,则删除tokens_a的最后一个token;否则,删除tokens_b的最后一个token。这个截断函数的目的是确保序列对的总长度不超过最大长度,以便在处理序列对时能够满足模型的输入要求。通过逐个删除token,可以保留较长序列中更多的信息,从而更好地处理不同长度的序列对。"""# This is a simple heuristic which will always truncate the longer sequence# one token at a time. This makes more sense than truncating an equal percent# of tokens from each, since if one sequence is very short then each token# that's truncated likely contains more information than a longer sequence.while True:total_length = len(tokens_a) + len(tokens_b)if total_length <= max_length:breakif len(tokens_a) > len(tokens_b):tokens_a.pop()else:tokens_b.pop()
- 构建模型
def model_fn_builder(bert_config, num_labels, init_checkpoint, learning_rate,num_train_steps, num_warmup_steps, use_tpu,use_one_hot_embeddings):"""Returns `model_fn` closure for TPUEstimator."""def model_fn(features, labels, mode, params): # pylint: disable=unused-argument"""The `model_fn` for TPUEstimator."""tf.logging.info("*** Features ***")for name in sorted(features.keys()):tf.logging.info(" name = %s, shape = %s" % (name, features[name].shape))input_ids = features["input_ids"]input_mask = features["input_mask"]segment_ids = features["segment_ids"]label_ids = features["label_ids"]is_real_example = Noneif "is_real_example" in features:is_real_example = tf.cast(features["is_real_example"], dtype=tf.float32)else:is_real_example = tf.ones(tf.shape(label_ids), dtype=tf.float32)is_training = (mode == tf.estimator.ModeKeys.TRAIN)(total_loss, per_example_loss, logits, probabilities) = create_model(bert_config, is_training, input_ids, input_mask, segment_ids, label_ids,num_labels, use_one_hot_embeddings)tvars = tf.trainable_variables()initialized_variable_names = {}scaffold_fn = Noneif init_checkpoint:(assignment_map, initialized_variable_names) = modeling.get_assignment_map_from_checkpoint(tvars, init_checkpoint)if use_tpu:def tpu_scaffold():tf.train.init_from_checkpoint(init_checkpoint, assignment_map)return tf.train.Scaffold()scaffold_fn = tpu_scaffoldelse:tf.train.init_from_checkpoint(init_checkpoint, assignment_map)tf.logging.info("**** Trainable Variables ****")for var in tvars:init_string = ""if var.name in initialized_variable_names:init_string = ", *INIT_FROM_CKPT*"tf.logging.info(" name = %s, shape = %s%s", var.name, var.shape,init_string)output_spec = Noneif mode == tf.estimator.ModeKeys.TRAIN:train_op = optimization.create_optimizer(total_loss, learning_rate, num_train_steps, num_warmup_steps, use_tpu)output_spec = tf.contrib.tpu.TPUEstimatorSpec(mode=mode,loss=total_loss,train_op=train_op,scaffold_fn=scaffold_fn)elif mode == tf.estimator.ModeKeys.EVAL:def metric_fn(per_example_loss, label_ids, logits, is_real_example):predictions = tf.argmax(logits, axis=-1, output_type=tf.int32)accuracy = tf.metrics.accuracy(labels=label_ids, predictions=predictions, weights=is_real_example)loss = tf.metrics.mean(values=per_example_loss, weights=is_real_example)return {"eval_accuracy": accuracy,"eval_loss": loss,}eval_metrics = (metric_fn,[per_example_loss, label_ids, logits, is_real_example])output_spec = tf.contrib.tpu.TPUEstimatorSpec(mode=mode,loss=total_loss,eval_metrics=eval_metrics,scaffold_fn=scaffold_fn)else:output_spec = tf.contrib.tpu.TPUEstimatorSpec(mode=mode,predictions={"probabilities": probabilities},scaffold_fn=scaffold_fn)return output_specreturn model_fn
Using BERT to extract fixed feature vectors
在某些情况下,与其对整个预训练模型进行端到端的微调,不如获得预训练的上下文嵌入,这些嵌入是从预训练的隐藏层生成的每个输入标记的固定上下文表示。 -训练有素的模型。这也应该可以缓解大部分内存不足问题。
# Sentence A and Sentence B are separated by the ||| delimiter for sentence
# pair tasks like question answering and entailment.
# For single sentence inputs, put one sentence per line and DON'T use the
# delimiter.
echo 'Who was Jim Henson ? ||| Jim Henson was a puppeteer' > /tmp/input.txtpython extract_features.py \--input_file=/tmp/input.txt \--output_file=/tmp/output.jsonl \--vocab_file=$BERT_BASE_DIR/vocab.txt \--bert_config_file=$BERT_BASE_DIR/bert_config.json \--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \--layers=-1,-2,-3,-4 \--max_seq_length=128 \--batch_size=8
If you need to maintain alignment between the original and tokenized words (for projecting training labels), see the Tokenization section below.
注意:您可能会看到类似 Could not find trained model in model_dir: /tmp/tmpuB5g5c, running initialization to predict. 的消息 此消息是预期的,它仅意味着我们正在使用 init_from_checkpoint() API 而不是保存的模型 API。如果您不指定检查点或指定无效的检查点,该脚本将会抱怨。
tokenalization
-
实例化 tokenizer = tokenization.FullTokenizer 的实例
-
使用 tokens = tokenizer.tokenize(raw_text) 对原始文本进行标记。
-
截断至最大序列长度。 (您最多可以使用 512 个,但出于内存和速度原因,您可能希望使用更短的长度。)
-
在正确的位置添加 [CLS] 和 [SEP] 标记。
在我们描述处理单词级任务的一般方法之前,了解我们的分词器到底在做什么非常重要。它有三个主要步骤:
-
(1) 文本规范化:将所有空白字符转换为空格,并(对于 Uncased 模型)将输入小写并去掉重音标记。例如, John Johanson’s, → john johanson’s, 。
-
(2) 标点符号分割:分割两侧的所有标点符号(即在所有标点符号周围添加空格)。标点符号定义为 (a) 任何具有 P* Unicode 类的字符,(b) 任何非字母/数字/空格 ASCII 字符(例如,像 $ 这样的字符在技术上不是标点)。例如, john johanson’s, → john johanson ’ s ,
-
(3) WordPiece 标记化:将空格标记化应用于上述过程的输出,并对每个标记单独应用 WordPiece 标记化。 (我们的实现直接基于 tensor2tensor 中的实现,该实现是链接的)。例如, john johanson ’ s , → john johan ##son ’ s ,
### Input
orig_tokens = ["John", "Johanson", "'s", "house"]
labels = ["NNP", "NNP", "POS", "NN"]### Output
bert_tokens = []# Token map will be an int -> int mapping between the `orig_tokens` index and
# the `bert_tokens` index.
orig_to_tok_map = []tokenizer = tokenization.FullTokenizer(vocab_file=vocab_file, do_lower_case=True)bert_tokens.append("[CLS]")
for orig_token in orig_tokens:orig_to_tok_map.append(len(bert_tokens))bert_tokens.extend(tokenizer.tokenize(orig_token))
bert_tokens.append("[SEP]")# bert_tokens == ["[CLS]", "john", "johan", "##son", "'", "s", "house", "[SEP]"]
# orig_to_tok_map == [1, 2, 4, 6]
分类任务

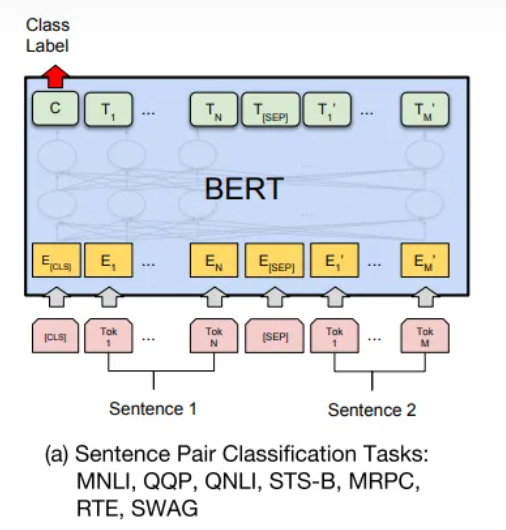
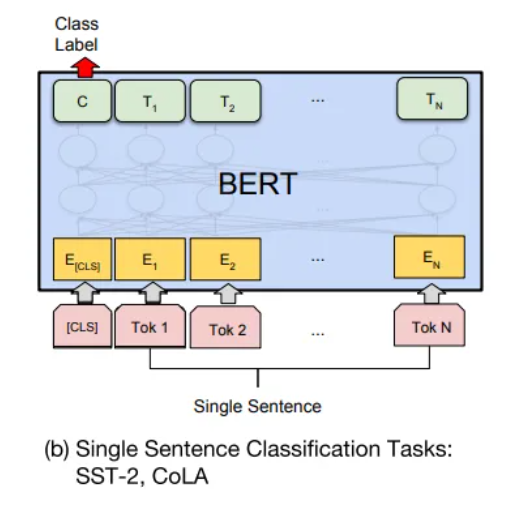
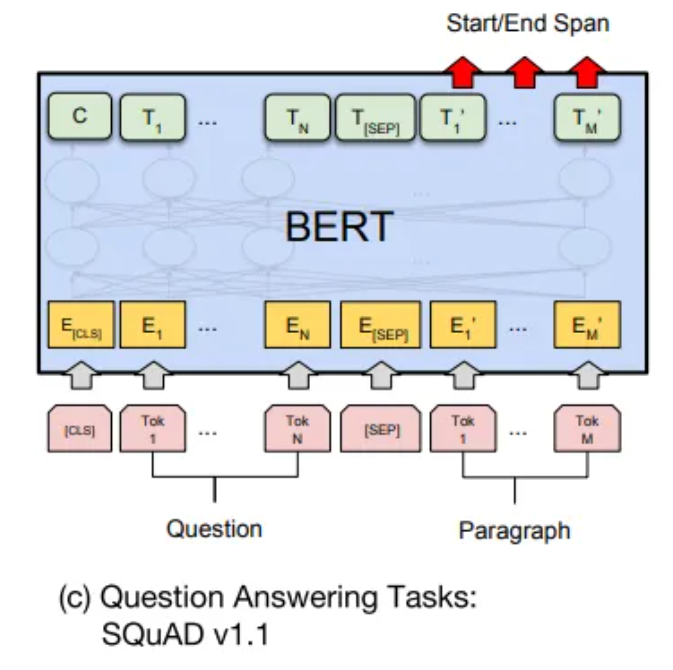
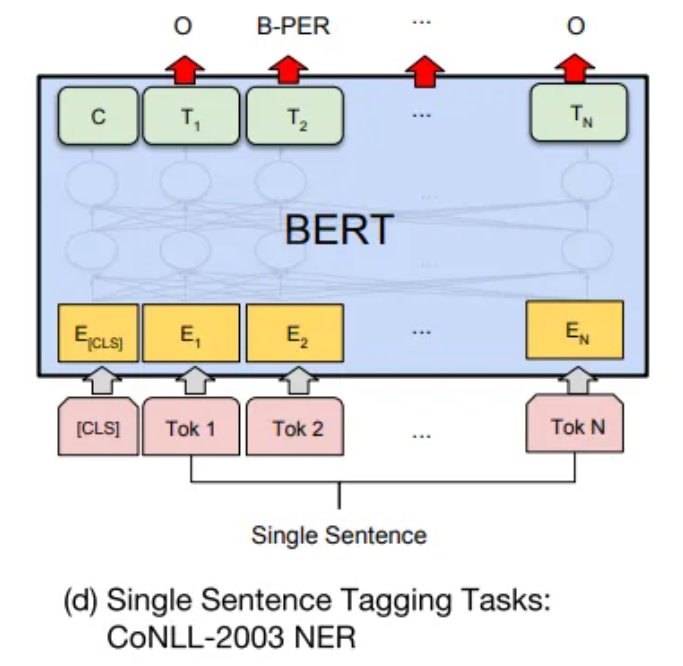
预训练模型
每个 .zip 文件包含三项:
-
包含预训练权重(实际上是 3 个文件)的 TensorFlow 检查点 ( bert_model.ckpt )。
-
用于将 WordPiece 映射到单词 id 的词汇文件 ( vocab.txt )。
-
指定模型超参数的配置文件 ( bert_config.json )。
代码详解
https://github.com/google-research/bert/blob/master/run_classifier.py
输入组成:
- guid: Unique id for the example.
text_a: string. The untokenized text of the first sequence. For single sequence tasks, only this sequence must be specified.
text_b: (Optional) string. The untokenized text of the second sequence. Only must be specified for sequence pair tasks.
label: (Optional) string. The label of the example. This should be specified for train and dev examples, but not for test examples.