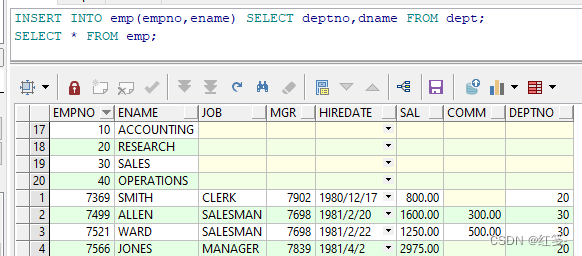
文章链接:https://arxiv.org/abs/1909.10351
背景
在自然语言处理(NLP)领域,预训练语言模型(如BERT)通过大规模的数据训练,已在多种NLP任务中取得了卓越的性能。尽管BERT模型在语言理解和生成任务中表现出色,其庞大的模型尺寸和高昂的计算成本限制了其在资源受限环境下的应用。
挑战
BERT等大型模型的计算成本高,不适合在移动设备或低资源环境中部署。因此,急需一种能将大型模型的能力转移到更小、更高效模型上的技术,这种技术被称为“知识蒸馏”。知识蒸馏的挑战在于如何在减小模型尺寸的同时,尽可能保留原模型的性能。
方法
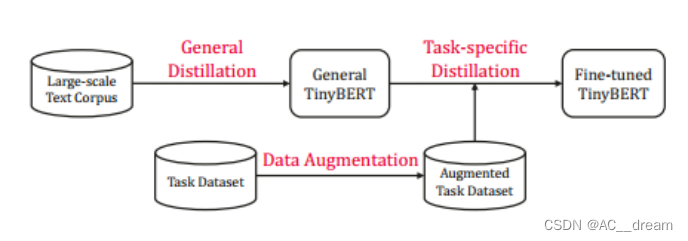
TinyBERT学习框架
TinyBERT通过以下步骤实现BERT的知识蒸馏:
1. Transformer蒸馏方法:针对Transformer基础的模型设计了一种新的知识蒸馏方法,旨在将大型BERT模型中编码的丰富知识有效转移到小型TinyBERT模型。
2. 两阶段学习框架:TinyBERT采用了一种新颖的两阶段学习框架,包括预训练阶段和具体任务学习阶段的蒸馏,确保TinyBERT模型不仅能捕获通用领域知识,还能捕获特定任务知识。
3. 数据增强和多样性:为了进一步提高TinyBERT在特定任务上的性能,引入数据增强技术,通过扩展训练样本来增加模型的泛化能力。
损失计算
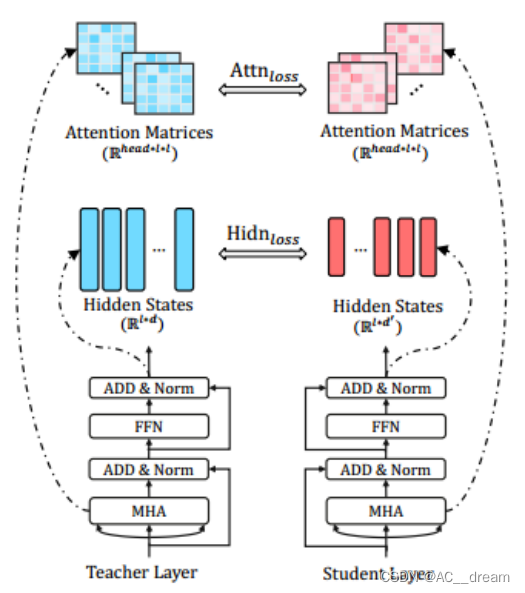
Transformer层中注意力矩阵和隐藏状态蒸馏示意图

其中Zs和Zt分别是学生和教师模型的逻辑输出,CE 代表交叉熵损失函数,t是一个软化温度参数,用于调整软标签的分布,使得学生模型可以从教师模型的预测中学习更多信息。
通过上述损失函数的组合,TinyBERT不仅学习了教师模型的最终输出,还学习了教师模型处理信息的内在方式,包括注意力机制和隐藏层的表示。这些损失函数的综合使用,确保了学生模型TinyBERT在显著减少模型大小和计算成本的同时,能够尽可能地保留教师模型BERT的性能。
和
矩阵说明:
目的:
尺寸转换:由于TinyBERT模型的隐藏层尺寸通常小于BERT模型的隐藏层尺寸,因此需要和
矩阵将学生模型的输出转换为与教师模型相同维度的空间,以便进行有效的比较。
信息转换:这个矩阵不仅仅是简单地改变尺寸,它还能帮助学生模型学习如何将其较小的、压缩的表示形式映射到一个更丰富的表示空间,这是教师模型所使用的。
获取方式(以为例):
通过训练过程中的反向传播得到的,具体步骤如下:
初始化:矩阵在训练前随机初始化
损失函数:通过定义一个损失函数来量化学生模型转换后的输出与教师模型输出之间的差异。常用的损失函数包括均方误差(MSE)。
反向传播更新:在训练过程中,使用梯度下降方法(或其他优化算法)根据损失函数的结果来调整矩阵的值,以最小化学生和教师模型输出之间的差异。
训练过程:在Transformer层蒸馏的上下文中,每当输入一个训练样本,学生模型(TinyBERT)和教师模型(BERT)都会计算各自的隐藏状态。然后,使用矩阵将TinyBERT的隐藏状态转换到与BERT相同的维度,接着计算和反向传播这两者之间的差异,不断更新
矩阵以及其他相关的模型参数。通过这样的过程,
矩阵最终能够有效地帮助TinyBERT模仿BERT的行为和输出,尽管TinyBERT的模型尺寸更小,参数更少。这种方法是蒸馏技术中减小模型尺寸同时保持性能的关键步骤之一。
数据增强

输入x:一个单词序列(句子或文本片段)
参数:
:阈值概率,决定是否对单词进行替换的门槛。
:每个样本生成的增强样本数量。
K:候选集大小,即为每个单词生成的可能替换词的数量。
输出D’:增强后的数据集
算法过程:
1.初始化计数器n为0,并创建空的增强数据集列表D’。
2.当n小于需要生成的样本数量时,执行循环
3.将输入序列x赋值给,以开始对其进行增强。
4.遍历序列x中的每个单词x[i]:
如果x[i]是一个单片词(即不可分割的词),就执行两步操作,第一步是将[i]替换为特殊标记[MASK],第二步是使用BERT模型找出当
[i]是[MASK]时,K个最有可能的单词,然后把这个集合赋值给集合C
反之如果x[i]不是一个单片词,使用GloVe模型找出与x[i]最相似的K个单词,并赋值给集合C
5.从[0,1]中均匀采样一个概率值p,如果p≤,就在集合C中随机选择一个单词替换
[i]
6.替换操作完成后,继续遍历中的下一个单词
7.当所有单词都遍历完,将增强后的序列添加到D中
8.增加计数器n 的值
9.如果n<,则重复上述操作
10.当所有增强样本都生成后就返回增强后的数据集D
总的来说,这个算法通过在原始文本序列中替换一些单词,来生成新的文本样本。这些替换基于BERT或GloVe模型的输出,取决于待替换的词是否是单片词。通过这种方式,它创造出与原始样本在语义上保持一致,但在表述上有所变化的新样本。这有助于学生模型在训练过程中获得更广泛的语言表达能力,以及更好的泛化性能。
结果
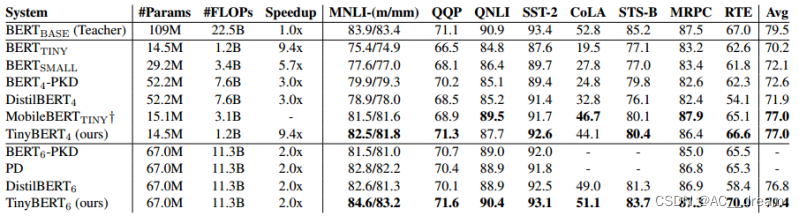
TinyBERT在GLUE基准测试中表现出色,与教师模型BERT相比,TinyBERT在模型大小和推理速度上均有显著改进,同时保持了相近的性能。例如,TinyBERT在模型大小上缩小了7.5倍,在推理速度上提高了9.4倍,而在性能上能达到教师模型的96.8%。
总结
TinyBERT的成功证明了通过精心设计的知识蒸馏方法和两阶段学习框架,可以有效地将大型模型的能力转移到更小、更高效的模型上,从而在保持性能的同时显著减少计算资源的需求。这为在资源受限的环境下部署高性能NLP模型提供了可能。