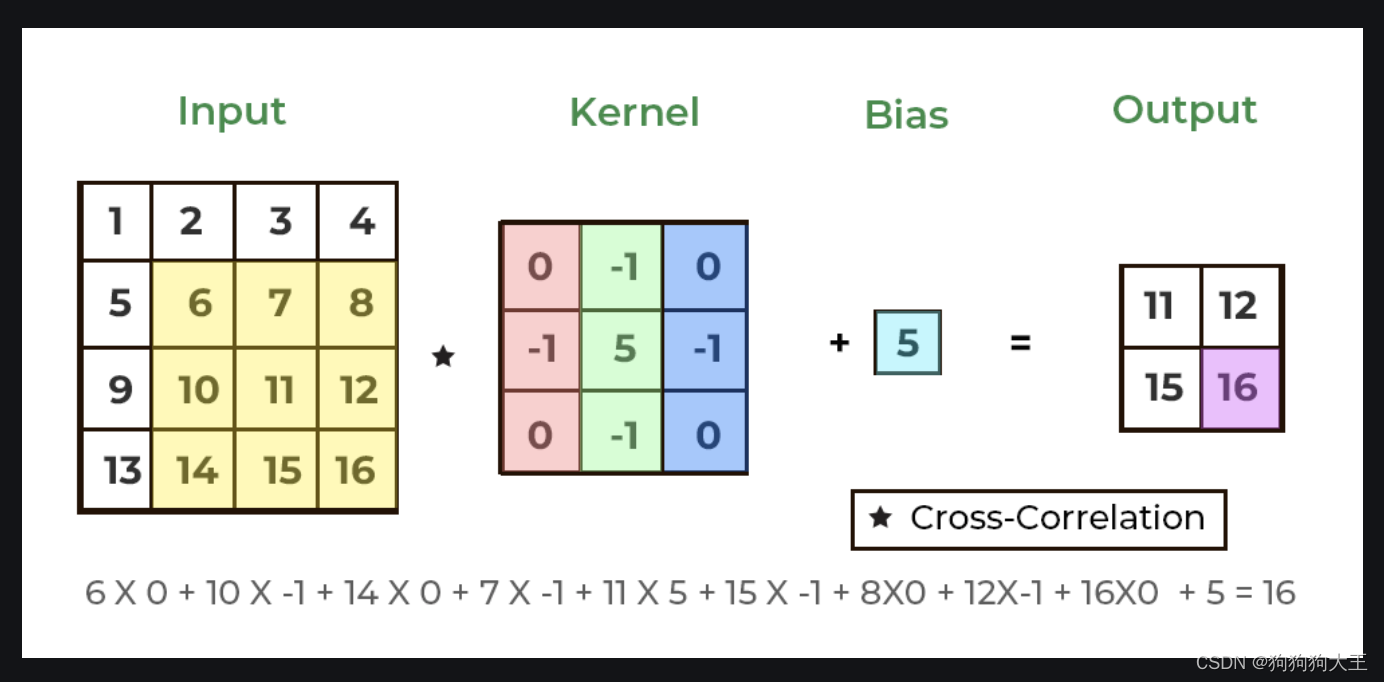
原文:
zh.annas-archive.org/md5/97bc15629f1b51a0671040c56db61b92译者:飞龙
协议:CC BY-NC-SA 4.0
第三章:迭代和做决定
“疯狂就是一遍又一遍地做同样的事情,却期待不同的结果。”- 阿尔伯特·爱因斯坦
在上一章中,我们看过了 Python 的内置数据类型。现在你已经熟悉了数据的各种形式和类型,是时候开始看看程序如何使用它了。
根据维基百科:
在计算机科学中,控制流(或者另一种说法是控制流程)指的是规定命令式程序的各个语句、指令或函数调用的执行或评估顺序。
为了控制程序的流程,我们有两个主要的武器:条件编程(也称为分支)和循环。我们可以以许多不同的组合和变化来使用它们,但在本章中,我不想以文档的方式介绍这两个结构的所有可能形式,我宁愿先给你一些基础知识,然后和你一起编写一些小脚本。在第一个脚本中,我们将看到如何创建一个基本的质数生成器,而在第二个脚本中,我们将看到如何根据优惠券为客户提供折扣。这样,你应该更好地了解条件编程和循环如何被使用。
在本章中,我们将涵盖以下内容:
-
条件编程
-
Python 中的循环
-
快速浏览 itertools 模块
条件编程
条件编程,或者分支,是你每天、每时每刻都在做的事情。它涉及评估条件:如果交通灯是绿色的,那么我可以过马路; 如果下雨了,那么我就带伞; 如果我上班迟到了,那么我会打电话给我的经理。
主要工具是if语句,它有不同的形式和颜色,但基本上它评估一个表达式,并根据结果选择要执行的代码部分。像往常一样,让我们看一个例子:
# conditional.1.py
late = True
if late: print('I need to call my manager!')
这可能是最简单的例子:当late被传递给if语句时,late充当条件表达式,在布尔上下文中进行评估(就像我们调用bool(late)一样)。如果评估的结果是True,那么我们就进入if语句后面的代码体。请注意,print指令是缩进的:这意味着它属于由if子句定义的作用域。执行这段代码会产生:
$ python conditional.1.py
I need to call my manager!
由于late是True,print语句被执行了。让我们扩展一下这个例子:
# conditional.2.py
late = False
if late: print('I need to call my manager!') #1
else: print('no need to call my manager...') #2
这次我将late = False,所以当我执行代码时,结果是不同的:
$ python conditional.2.py
no need to call my manager...
根据评估late表达式的结果,我们可以进入块#1或块#2,但不能同时进入。当late评估为True时,执行块#1,而当late评估为False时,执行块#2。尝试为late名称分配False/True值,并看看这段代码的输出如何相应地改变。
前面的例子还介绍了else子句,当我们想要在if子句中的表达式求值为False时提供一组替代指令时,它就非常方便。else子句是可选的,通过比较前面的两个例子就可以看出来。
一个特殊的 else - elif
有时,您只需要在满足条件时执行某些操作(简单的if子句)。在其他时候,您需要提供一个替代方案,以防条件为False(if/else子句),但有时候您可能有多于两条路径可供选择,因此,由于调用经理(或不调用他们)是一种二进制类型的示例(要么您打电话,要么您不打电话),让我们改变示例的类型并继续扩展。这次,我们决定税收百分比。如果我的收入低于$10,000,我将不支付任何税款。如果在$10,000 和$30,000 之间,我将支付 20%的税款。如果在$30,000 和$100,000 之间,我将支付 35%的税款,如果超过$100,000,我将(很高兴)支付 45%的税款。让我们把这一切都写成漂亮的 Python 代码:
# taxes.py
income = 15000
if income < 10000: tax_coefficient = 0.0 #1
elif income < 30000: tax_coefficient = 0.2 #2
elif income < 100000: tax_coefficient = 0.35 #3
else: tax_coefficient = 0.45 #4 print('I will pay:', income * tax_coefficient, 'in taxes')
执行上述代码产生:
$ python taxes.py
I will pay: 3000.0 in taxes
让我们逐行来看这个例子:我们首先设置收入值。在这个例子中,我的收入是$15,000。我们进入if子句。请注意,这次我们还引入了elif子句,它是else-if的缩写,与裸的else子句不同,它还有自己的条件。因此,income < 10000的if表达式评估为False,因此块#1不会被执行。
控制权转移到下一个条件评估器:elif income < 30000。这个评估为True,因此块#2被执行,因此,Python 在整个if/elif/elif/else子句之后恢复执行(我们现在可以称之为if子句)。if子句之后只有一条指令,即print调用,它告诉我们我今年将支付3000.0的税款(15,000 * 20%)。请注意,顺序是强制性的:if首先出现,然后(可选)是您需要的尽可能多的elif子句,然后(可选)是一个else子句。
有趣,对吧?无论每个块内有多少行代码,只要其中一个条件评估为True,相关块就会被执行,然后在整个子句之后执行。如果没有一个条件评估为True(例如,income = 200000),那么else子句的主体将被执行(块#4)。这个例子扩展了我们对else子句行为的理解。当前面的if/elif/…/elif表达式没有评估为True时,它的代码块将被执行。
尝试修改income的值,直到您可以轻松地按需执行所有块(每次执行一个块,当然)。然后尝试边界。这是至关重要的,每当您将条件表达为相等或不等式(==,!=,<,>,<=,>=)时,这些数字代表边界。彻底测试边界是至关重要的。我是否允许您在 18 岁或 17 岁时开车?我是否用age < 18或age <= 18检查您的年龄?您无法想象有多少次我不得不修复由于使用错误运算符而产生的微妙错误,因此继续并尝试使用上述代码进行实验。将一些<更改为<=,并将收入设置为边界值之一(10,000,30,000,100,000)以及之间的任何值。看看结果如何变化,并在继续之前对其有一个很好的理解。
现在让我们看另一个例子,它向我们展示了如何嵌套if子句。假设您的程序遇到错误。如果警报系统是控制台,我们打印错误。如果警报系统是电子邮件,我们根据错误的严重程度发送它。如果警报系统不是控制台或电子邮件,我们不知道该怎么办,因此我们什么也不做。让我们把这写成代码:
# errorsalert.py
alert_system = 'console' # other value can be 'email'
error_severity = 'critical' # other values: 'medium' or 'low'
error_message = 'OMG! Something terrible happened!' if alert_system == 'console': print(error_message) #1
elif alert_system == 'email': if error_severity == 'critical': send_email('admin@example.com', error_message) #2 elif error_severity == 'medium': send_email('support.1@example.com', error_message) #3 else: send_email('support.2@example.com', error_message) #4
上面的例子非常有趣,因为它很愚蠢。它向我们展示了两个嵌套的if子句(外部和内部)。它还向我们展示了外部if子句没有任何else,而内部if子句有。请注意,缩进是允许我们将一个子句嵌套在另一个子句中的原因。
如果alert_system == 'console',则执行#1部分,其他情况下,如果alert_system == 'email',则进入另一个if子句,我们称之为内部。在内部if子句中,根据error_severity,我们向管理员、一级支持或二级支持发送电子邮件(块#2、#3和#4)。在本例中,send_email函数未定义,因此尝试运行它会导致错误。在书的源代码中,您可以从网站上下载,我包含了一个技巧,将该调用重定向到常规的print函数,这样您就可以在控制台上进行实验,而不必实际发送电子邮件。尝试更改值,看看它是如何工作的。
三元运算符
在继续下一个主题之前,我想向您展示的最后一件事是三元运算符,或者通俗地说,if/else子句的简短版本。当根据某些条件分配名称的值时,有时使用三元运算符而不是适当的if子句更容易和更可读。在以下示例中,两个代码块完全相同:
# ternary.py
order_total = 247 # GBP # classic if/else form
if order_total > 100: discount = 25 # GBP
else: discount = 0 # GBP
print(order_total, discount) # ternary operator
discount = 25 if order_total > 100 else 0
print(order_total, discount)
对于这种简单情况,我发现能够用一行代码来表达逻辑非常好,而不是用四行。记住,作为编码人员,您花在阅读代码上的时间要比编写代码多得多,因此 Python 的简洁性是无价的。
您清楚三元运算符的工作原理吗?基本上,name = something if condition else something-else。因此,如果condition评估为True,则将name分配为something,如果condition评估为False,则将something-else分配给name。
现在您已经了解了如何控制代码的路径,让我们继续下一个主题:循环。
循环
如果您在其他编程语言中有循环的经验,您会发现 Python 的循环方式有些不同。首先,什么是循环?循环意味着能够根据给定的循环参数多次重复执行代码块。有不同的循环结构,用于不同的目的,Python 已将它们全部简化为只有两种,您可以使用它们来实现您需要的一切。这些是for和while语句。
虽然使用任何一种都可以实现您需要的一切,但它们用途不同,因此通常在不同的上下文中使用。我们将在本章中彻底探讨这种差异。
for循环
for循环用于循环遍历序列,例如列表、元组或一组对象。让我们从一个简单的例子开始,扩展概念,看看 Python 语法允许我们做什么:
# simple.for.py
for number in [0, 1, 2, 3, 4]: print(number)
当执行时,这段简单的代码打印出从0到4的所有数字。for循环接收列表[0, 1, 2, 3, 4],在每次迭代时,number从序列中获得一个值(按顺序迭代),然后执行循环体(打印行)。number的值在每次迭代时都会改变,根据序列中接下来的值。当序列耗尽时,for循环终止,代码的执行会在循环后恢复正常。
迭代范围
有时我们需要迭代一系列数字,如果在某处硬编码列表将会很不方便。在这种情况下,range函数就派上用场了。让我们看看前面代码片段的等价物:
# simple.for.py
for number in range(5): print(number)
在 Python 程序中,当涉及创建序列时,range函数被广泛使用:您可以通过传递一个值来调用它,该值充当stop(从0开始计数),或者您可以传递两个值(start和stop),甚至三个值(start、stop和step)。看看以下示例:
>>> list(range(10)) # one value: from 0 to value (excluded)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> list(range(3, 8)) # two values: from start to stop (excluded)
[3, 4, 5, 6, 7]
>>> list(range(-10, 10, 4)) # three values: step is added
[-10, -6, -2, 2, 6]
暂时忽略我们需要在list中包装range(...)的事实。range对象有点特殊,但在这种情况下,我们只是想了解它将向我们返回什么值。您可以看到,切片的处理方式也是一样的:start包括在内,stop不包括在内,还可以添加一个step参数,其默认值为1。
尝试修改我们simple.for.py代码中range()调用的参数,并查看打印出什么。熟悉一下。
在序列上进行迭代
现在我们有了所有迭代序列的工具,让我们在此基础上构建示例:
# simple.for.2.py
surnames = ['Rivest', 'Shamir', 'Adleman']
for position in range(len(surnames)): print(position, surnames[position])
前面的代码给游戏增加了一些复杂性。执行将显示以下结果:
$ python simple.for.2.py
0 Rivest
1 Shamir
2 Adleman
让我们使用从内到外的技术来分解它,好吗?我们从我们试图理解的最内部部分开始,然后向外扩展。因此,len(surnames)是surnames列表的长度:3。因此,range(len(surnames))实际上被转换为range(3)。这给我们一个范围[0, 3),基本上是一个序列(0,1,2)。这意味着for循环将运行三次迭代。在第一次迭代中,position将取值0,而在第二次迭代中,它将取值1,最后在第三次和最后一次迭代中取值2。如果不是(0,1,2),那么对surnames列表的可能索引位置是什么?在位置0,我们找到'Rivest',在位置1,'Shamir',在位置2,'Adleman'。如果您对这三个人一起创造了什么感到好奇,请将print(position, surnames[position])更改为print(surnames[position][0], end=''),在循环外添加最后一个print(),然后再次运行代码。
现在,这种循环方式实际上更接近于 Java 或 C++等语言。在 Python 中,很少看到这样的代码。您可以只是迭代任何序列或集合,因此无需获取位置列表并在每次迭代时从序列中检索元素。这是昂贵的,没有必要的昂贵。让我们将示例更改为更符合 Python 风格的形式:
# simple.for.3.py
surnames = ['Rivest', 'Shamir', 'Adleman']
for surname in surnames: print(surname)
现在这就是!它几乎是英语。for循环可以迭代surnames列表,并且它会在每次交互中按顺序返回每个元素。运行此代码将打印出三个姓氏,一个接一个。阅读起来更容易,对吧?
但是,如果您想要打印位置呢?或者如果您确实需要它呢?您应该回到range(len(...))形式吗?不。您可以使用enumerate内置函数,就像这样:
# simple.for.4.py
surnames = ['Rivest', 'Shamir', 'Adleman']
for position, surname in enumerate(surnames): print(position, surname)
这段代码也很有趣。请注意,enumerate在每次迭代时返回一个二元组(position, surname),但仍然比range(len(...))示例更可读(更有效)。您可以使用start参数调用enumerate,例如enumerate(iterable, start),它将从start开始,而不是从0开始。这只是另一个小事情,表明 Python 在设计时考虑了多少,以便使您的生活更轻松。
您可以使用for循环来迭代列表、元组和一般 Python 称为可迭代的任何东西。这是一个非常重要的概念,所以让我们再谈谈它。
迭代器和可迭代对象
根据 Python 文档(docs.python.org/3/glossary.html)的说法,可迭代对象是:
一个能够逐个返回其成员的对象。可迭代对象的示例包括所有序列类型(如列表、字符串和元组)和一些非序列类型,比如字典、文件对象和你用 iter()或 getitem()方法定义的任何类的对象。可迭代对象可以在 for 循环和许多其他需要序列的地方使用(zip()、map()等)。当将可迭代对象作为参数传递给内置函数 iter()时,它会返回该对象的迭代器。这个迭代器对一组值进行一次遍历。在使用可迭代对象时,通常不需要调用 iter()或自己处理迭代器对象。for 语句会自动为你创建一个临时的未命名变量来保存迭代器,以便在循环期间使用。
简而言之,当你写for k in sequence: ... body ...时,for循环会询问sequence下一个元素,得到返回值后,将其命名为k,然后执行其主体。然后,for循环再次询问sequence下一个元素,再次将其命名为k,再次执行主体,依此类推,直到序列耗尽。空序列将导致主体不执行。
一些数据结构在迭代时按顺序产生它们的元素,比如列表、元组和字符串,而另一些则不会,比如集合和字典(Python 3.6 之前)。Python 给了我们迭代可迭代对象的能力,使用一种称为迭代器的对象类型。
根据官方文档(docs.python.org/3/glossary.html),迭代器是:
表示数据流的对象。对迭代器的 next()方法进行重复调用(或将其传递给内置函数 next())会返回数据流中的连续项。当没有更多数据可用时,会引发 StopIteration 异常。此时,迭代器对象已耗尽,任何进一步调用其 next()方法都会再次引发 StopIteration。迭代器需要有一个返回迭代器对象本身的 iter()方法,因此每个迭代器也是可迭代的,并且可以在大多数接受其他可迭代对象的地方使用。一个值得注意的例外是尝试多次迭代的代码。容器对象(如列表)每次传递给 iter()函数或在 for 循环中使用时都会产生一个全新的迭代器。尝试对迭代器进行这样的操作只会返回相同的已耗尽的迭代器对象,使其看起来像一个空容器。
如果你不完全理解前面的法律术语,不要担心,你以后会理解的。我把它放在这里作为将来的方便参考。
实际上,整个可迭代/迭代器机制在代码后面有些隐藏。除非出于某种原因需要编写自己的可迭代或迭代器,否则你不必过多担心这个问题。但理解 Python 如何处理这一关键的控制流方面非常重要,因为它将塑造你编写代码的方式。
迭代多个序列
让我们看另一个例子,如何迭代两个相同长度的序列,以便处理它们各自的元素对。假设我们有一个人员列表和一个代表第一个列表中人员年龄的数字列表。我们想要打印所有人员的姓名/年龄对。让我们从一个例子开始,然后逐渐完善它:
# multiple.sequences.py
people = ['Conrad', 'Deepak', 'Heinrich', 'Tom']
ages = [29, 30, 34, 36]
for position in range(len(people)):person = people[position]age = ages[position]print(person, age)
到目前为止,这段代码应该对你来说非常简单。我们需要迭代位置列表(0、1、2、3),因为我们想要从两个不同的列表中检索元素。执行后我们得到以下结果:
$ python multiple.sequences.py
Conrad 29
Deepak 30
Heinrich 34
Tom 36
这段代码既低效又不符合 Python 的风格。它是低效的,因为根据位置检索元素可能是一个昂贵的操作,并且我们在每次迭代时都是从头开始做这个操作。邮递员在递送信件时不会每次都回到路的起点,对吧?他们是从一户到另一户。让我们尝试使用enumerate来改进一下:
# multiple.sequences.enumerate.py
people = ['Conrad', 'Deepak', 'Heinrich', 'Tom']
ages = [29, 30, 34, 36]
for position, person in enumerate(people):age = ages[position]print(person, age)
这样好一些,但还不完美。而且还有点丑。我们在people上进行了适当的迭代,但我们仍然使用位置索引来获取age,我们也想摆脱这一点。别担心,Python 给了你zip函数,记得吗?让我们使用它:
# multiple.sequences.zip.py
people = ['Conrad', 'Deepak', 'Heinrich', 'Tom']
ages = [29, 30, 34, 36]
for person, age in zip(people, ages):print(person, age)
啊!好多了!再次比较前面的代码和第一个例子,欣赏 Python 的优雅之处。我想展示这个例子的原因有两个。一方面,我想给你一个概念,即 Python 中更短的代码可以与其他语言相比,其中的语法不允许你像这样轻松地迭代序列或集合。另一方面,更重要的是,注意当for循环请求zip(sequenceA, sequenceB)的下一个元素时,它会得到一个元组,而不仅仅是一个单一对象。它会得到一个元组,其中包含与我们提供给zip函数的序列数量相同的元素。让我们通过两种方式扩展前面的例子,使用显式和隐式赋值:
# multiple.sequences.explicit.py
people = ['Conrad', 'Deepak', 'Heinrich', 'Tom']
ages = [29, 30, 34, 36]
nationalities = ['Poland', 'India', 'South Africa', 'England']
for person, age, nationality in zip(people, ages, nationalities):print(person, age, nationality)
在前面的代码中,我们添加了 nationalities 列表。现在我们向zip函数提供了三个序列,for 循环在每次迭代时都会返回一个三元组。请注意,元组中元素的位置与zip调用中序列的位置相对应。执行代码将产生以下结果:
$ python multiple.sequences.explicit.py
Conrad 29 Poland
Deepak 30 India
Heinrich 34 South Africa
Tom 36 England
有时,出于某些在简单示例中可能不太清楚的原因,你可能希望在for循环的主体中分解元组。如果这是你的愿望,完全可以这样做:
# multiple.sequences.implicit.py
people = ['Conrad', 'Deepak', 'Heinrich', 'Tom']
ages = [29, 30, 34, 36]
nationalities = ['Poland', 'India', 'South Africa', 'England']
for data in zip(people, ages, nationalities):person, age, nationality = dataprint(person, age, nationality)
基本上,它在某些情况下会自动为你做for循环所做的事情。但在某些情况下,你可能希望自己做。在这里,来自zip(...)的三元组data在for循环的主体中被分解为三个变量:person、age和nationality。
while 循环
在前面的页面中,我们看到了for循环的运行情况。当你需要循环遍历一个序列或集合时,它非常有用。需要记住的关键一点是,当你需要能够区分使用哪种循环结构时,for循环在你需要迭代有限数量的元素时非常有效。它可以是一个巨大的数量,但仍然是在某个点结束的东西。
然而,还有其他情况,当你只需要循环直到满足某个条件,甚至是无限循环直到应用程序停止时,比如我们真的没有东西可以迭代的情况,因此for循环会是一个不好的选择。但不用担心,对于这些情况,Python 为我们提供了while循环。
while循环类似于for循环,因为它们都会循环,并且在每次迭代时执行一系列指令。它们之间的不同之处在于while循环不会循环遍历一个序列(它可以,但你必须手动编写逻辑,而且没有任何意义,你只想使用for循环),而是在某个条件满足时循环。当条件不再满足时,循环结束。
和往常一样,让我们看一个例子,这将为我们澄清一切。我们想要打印一个正数的二进制表示。为了做到这一点,我们可以使用一个简单的算法,它收集除以2的余数(逆序),结果就是数字本身的二进制表示:
6 / 2 = 3 (remainder: 0)
3 / 2 = 1 (remainder: 1)
1 / 2 = 0 (remainder: 1)
List of remainders: 0, 1, 1\.
Inverse is 1, 1, 0, which is also the binary representation of 6: 110
让我们写一些代码来计算数字 39 的二进制表示:100111[2]:
# binary.py
n = 39
remainders = []
while n > 0:remainder = n % 2 # remainder of division by 2remainders.insert(0, remainder) # we keep track of remaindersn //= 2 # we divide n by 2print(remainders)
在上面的代码中,我突出了n > 0,这是保持循环的条件。我们可以通过使用divmod函数使代码变得更短(更符合 Python 风格),该函数使用一个数字和一个除数调用,并返回一个包含整数除法结果及其余数的元组。例如,divmod(13, 5)将返回(2, 3),确实5 * 2 + 3 = 13。
# binary.2.py
n = 39
remainders = []
while n > 0:n, remainder = divmod(n, 2)remainders.insert(0, remainder)print(remainders)
在上面的代码中,我们已经将n重新分配为除以2的结果和余数,一行代码完成。
请注意,在while循环中的条件是继续循环的条件。如果条件评估为True,则执行主体,然后进行另一个评估,依此类推,直到条件评估为False。当发生这种情况时,循环立即退出,而不执行其主体。
如果条件永远不会评估为False,则循环将成为所谓的无限循环。无限循环的用途包括从网络设备轮询时使用:您询问套接字是否有任何数据,如果有,则对其进行某些操作,然后您休眠一小段时间,然后再次询问套接字,一遍又一遍,永不停止。
能够循环遍历条件或无限循环是for循环单独不足的原因,因此 Python 提供了while循环。
顺便说一句,如果您需要数字的二进制表示,请查看bin函数。
只是为了好玩,让我们使用 while 逻辑来调整一个示例(multiple.sequences.py):
# multiple.sequences.while.py
people = ['Conrad', 'Deepak', 'Heinrich', 'Tom']
ages = [29, 30, 34, 36]
position = 0
while position < len(people):person = people[position]age = ages[position]print(person, age)position += 1
在上面的代码中,我突出了position变量的初始化、条件和更新,这使得可以通过手动处理迭代变量来模拟等效的for循环代码。所有可以使用for循环完成的工作也可以使用while循环完成,尽管您可以看到为了实现相同的结果,需要经历一些样板文件。相反的也是如此,但除非您有理由这样做,否则您应该使用正确的工具,99.9%的时间您都会没问题。
因此,总结一下,当您需要遍历可迭代对象时,请使用for循环,当您需要根据满足或不满足条件来循环时,请使用while循环。如果您记住这两种目的之间的区别,您将永远不会选择错误的循环结构。
现在让我们看看如何改变循环的正常流程。
中断和继续语句
根据手头的任务,有时您需要改变循环的正常流程。您可以跳过单个迭代(多次),也可以完全退出循环。跳过迭代的常见用例是,例如,当您遍历一个项目列表并且只有在验证了某些条件时才需要处理每个项目时。另一方面,如果您正在遍历一组项目,并且找到了满足某些需求的项目,您可能决定不再继续整个循环,因此退出循环。有无数可能的情景,因此最好看一些例子。
假设您想要对购物篮列表中所有今天到期的产品应用 20%的折扣。您实现这一点的方式是使用continue语句,该语句告诉循环结构(for或while)立即停止执行主体并转到下一个迭代(如果有的话)。这个例子将让我们深入了解一点,所以准备好跳下去:
# discount.py
from datetime import date, timedeltatoday = date.today()
tomorrow = today + timedelta(days=1) # today + 1 day is tomorrow
products = [{'sku': '1', 'expiration_date': today, 'price': 100.0},{'sku': '2', 'expiration_date': tomorrow, 'price': 50},{'sku': '3', 'expiration_date': today, 'price': 20},
]for product in products:if product['expiration_date'] != today:continueproduct['price'] *= 0.8 # equivalent to applying 20% discountprint('Price for sku', product['sku'],'is now', product['price'])
我们首先导入date和timedelta对象,然后设置我们的产品。那些sku为1和3的产品具有今天的到期日,这意味着我们希望对它们应用 20%的折扣。我们循环遍历每个产品并检查到期日。如果它不是(不等运算符,!=)today,我们不希望执行其余的主体套件,因此我们continue。
注意,continue语句放在主体套件的哪里并不重要(你甚至可以使用它多次)。当你到达它时,执行停止并返回到下一个迭代。如果我们运行discount.py模块,输出如下:
$ python discount.py
Price for sku 1 is now 80.0
Price for sku 3 is now 16.0
这向你展示了主体的最后两行没有被执行给sku编号为2。
现在让我们看一个退出循环的例子。假设我们想要判断列表中是否至少有一个元素在传递给bool函数时评估为True。鉴于我们需要知道是否至少有一个,当我们找到它时,就不需要继续扫描列表。在 Python 代码中,这意味着使用break语句。让我们把这写成代码:
# any.py
items = [0, None, 0.0, True, 0, 7] # True and 7 evaluate to Truefound = False # this is called "flag"
for item in items:print('scanning item', item)if item:found = True # we update the flagbreakif found: # we inspect the flagprint('At least one item evaluates to True')
else:print('All items evaluate to False')
前面的代码在编程中是一个常见的模式,你会经常看到它。当你以这种方式检查项目时,基本上你是设置一个flag变量,然后开始检查。如果你找到一个符合你条件的元素(在这个例子中,评估为True),然后你更新flag并停止迭代。迭代后,你检查flag并相应地采取行动。执行结果是:
$ python any.py
scanning item 0
scanning item None
scanning item 0.0
scanning item True
At least one item evaluates to True
看到True被找到后执行停止了吗?break语句的作用和continue一样,它立即停止执行循环主体,但也阻止其他迭代运行,有效地跳出循环。continue和break语句可以在for和while循环结构中一起使用,没有数量限制。
顺便说一下,没有必要编写代码来检测序列中是否至少有一个元素评估为True。只需要查看内置的any函数。
特殊的 else 子句
在 Python 语言中我看到的一个特性是在while和for循环后面能够有else子句的能力。这种用法非常少见,但是确实很有用。简而言之,你可以在for或while循环后面有一个else子句。如果循环正常结束,因为迭代器耗尽(for循环)或者条件最终不满足(while循环),那么else子句(如果存在)会被执行。如果执行被break语句中断,else子句就不会被执行。让我们举一个例子,一个for循环遍历一组项目,寻找满足某个条件的项目。如果我们找不到至少一个满足条件的项目,我们想要引发一个异常。这意味着我们想要中止程序的正常执行,并且表示出现了一个我们无法处理的错误或异常。异常将在后面的章节中讨论,所以如果你现在不完全理解它们也不用担心。只需要记住它们会改变代码的正常流程。
现在让我展示给你两个做同样事情的例子,但其中一个使用了特殊的for...else语法。假设我们想在一组人中找到一个可以开车的人:
# for.no.else.py
class DriverException(Exception):passpeople = [('James', 17), ('Kirk', 9), ('Lars', 13), ('Robert', 8)]
driver = None
for person, age in people:if age >= 18:driver = (person, age)breakif driver is None:raise DriverException('Driver not found.')
再次注意flag模式。我们将驱动程序设置为None,然后如果我们找到一个,我们更新driver标志,然后在循环结束时,我们检查它是否找到了一个。我有一种感觉,那些孩子会开一辆非常金属的车,但无论如何,注意如果没有找到驱动程序,将会引发DriverException,表示程序无法继续执行(我们缺少驱动程序)。
相同的功能可以用以下代码更加优雅地重写:
# for.else.py
class DriverException(Exception):passpeople = [('James', 17), ('Kirk', 9), ('Lars', 13), ('Robert', 8)]
for person, age in people:if age >= 18:driver = (person, age)break
else:raise DriverException('Driver not found.')
请注意,我们不再被迫使用flag模式。异常是作为for循环逻辑的一部分引发的,这是有道理的,因为for循环正在检查某些条件。我们只需要设置一个driver对象,以防我们找到一个,因为代码的其余部分将在某个地方使用这些信息。请注意,代码更短更优雅,因为逻辑现在正确地组合在一起。
在将代码转换为美观的 Python视频中,Raymond Hettinger 建议将与 for 循环关联的else语句的名称改为nobreak。如果你在记住else如何用于for循环时感到困难,只需记住这个事实就应该帮助你了。
把这一切放在一起
现在你已经看到关于条件和循环的所有内容,是时候稍微调剂一下,看看我在本章开头预期的那两个例子了。我们将在这里混合搭配,这样你就可以看到如何将所有这些概念结合起来使用。让我们先写一些代码来生成一个质数列表,直到某个限制为止。请记住,我将写一个非常低效和基本的算法来检测质数。对你来说重要的是要集中精力关注本章主题的代码部分。
一个质数生成器
根据维基百科:
质数(或质数)是大于 1 的自然数,除了 1 和它本身之外没有正的除数。大于 1 的自然数,如果不是质数,则称为合数。
根据这个定义,如果我们考虑前 10 个自然数,我们可以看到 2、3、5 和 7 是质数,而 1、4、6、8、9 和 10 不是。为了让计算机告诉你一个数N是否是质数,你可以将该数除以范围[2,N)内的所有自然数。如果其中任何一个除法的余数为零,那么这个数就不是质数。废话够多了,让我们开始做生意吧。我将写两个版本的代码,第二个版本将利用for...else语法:
# primes.py
primes = [] # this will contain the primes in the end
upto = 100 # the limit, inclusive
for n in range(2, upto + 1):is_prime = True # flag, new at each iteration of outer forfor divisor in range(2, n):if n % divisor == 0:is_prime = Falsebreak
if is_prime: # check on flagprimes.append(n)
print(primes)
在前面的代码中有很多值得注意的地方。首先,我们建立了一个空的primes列表,它将在最后包含质数。限制是100,你可以看到我们在外部循环中调用range()的方式是包容的。如果我们写range(2, upto),那就是*[2, upto),对吧?因此range(2, upto + 1)给我们[2, upto + 1) == [2, upto]*。
所以,有两个for循环。在外部循环中,我们循环遍历候选质数,也就是从2到upto的所有自然数。在外部循环的每次迭代中,我们设置一个标志(在每次迭代时设置为True),然后开始将当前的n除以从2到n - 1的所有数字。如果我们找到n的一个适当的除数,这意味着n是合数,因此我们将标志设置为False并中断循环。请注意,当我们中断内部循环时,外部循环会继续正常进行。我们在找到n的适当除数后中断的原因是,我们不需要任何进一步的信息就能告诉n不是质数。
当我们检查is_prime标志时,如果它仍然是True,这意味着我们在[2,n)中找不到任何适当的除数,因此n是一个质数。我们将n附加到primes列表中,然后进行另一个迭代,直到n等于100。
运行这段代码会产生:
$ python primes.py
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]
在我们继续之前,有一个问题:在外部循环的所有迭代中,有一个与其他所有迭代都不同。你能告诉哪一个,以及为什么吗?想一想,回到代码,试着自己找出答案,然后继续阅读。
你搞清楚了吗?如果没有,不要感到难过,这很正常。我让你做这个小练习,因为这是程序员一直在做的事情。通过简单地查看代码就能理解代码的功能是一种随着时间积累的技能。这非常重要,所以尽量在你能做的时候进行练习。我现在告诉你答案:与所有其他迭代不同的是第一个迭代。原因是因为在第一次迭代中,n是2。因此,最内层的for循环甚至不会运行,因为它是一个遍历range(2, 2)的for循环,那不就是[2, 2)吗?自己试一下,用这个可迭代对象写一个简单的for循环,放一个print在主体套件中,看看是否发生了什么(不会…)。
现在,从算法的角度来看,这段代码效率低下,所以让我们至少让它更美观:
# primes.else.py
primes = []
upto = 100
for n in range(2, upto + 1):for divisor in range(2, n):if n % divisor == 0:breakelse:primes.append(n)
print(primes)
更好了,对吧?is_prime标志已经消失,当我们知道内部的for循环没有遇到任何break语句时,我们将n附加到primes列表中。看看代码是不是更清晰,读起来更好了?
应用折扣
在这个例子中,我想向你展示一个我非常喜欢的技巧。在许多编程语言中,除了if/elif/else结构之外,无论以什么形式或语法,你都可以找到另一个语句,通常称为switch/case,在 Python 中缺少。它相当于一系列if/elif/…/elif/else子句,语法类似于这样(警告!JavaScript 代码!):
/* switch.js */
switch (day_number) {case 1:case 2:case 3:case 4:case 5:day = "Weekday";break;case 6:day = "Saturday";break;case 0:day = "Sunday";break;default:day = "";
alert(day_number + ' is not a valid day number.')
}
在上面的代码中,我们在一个名为day_number的变量上进行switch。这意味着我们获取它的值,然后决定它适用于哪种情况(如果有的话)。从1到5有一个级联,这意味着无论数字是多少,[1, 5]都会进入将day设置为"Weekday"的逻辑部分。然后我们有0和6的单个情况,以及一个default情况来防止错误,它警告系统day_number不是有效的日期数字,即不在[0, 6]中。Python 完全能够使用if/elif/else语句实现这样的逻辑:
# switch.py
if 1 <= day_number <= 5:day = 'Weekday'
elif day_number == 6:day = 'Saturday'
elif day_number == 0:day = 'Sunday'
else:day = ''raise ValueError(str(day_number) + ' is not a valid day number.')
在上面的代码中,我们使用if/elif/else语句在 Python 中复制了 JavaScript 片段的相同逻辑。我只是举了一个例子,如果day_number不在[0, 6]中,就会引发ValueError异常。这是一种可能的转换switch/case逻辑的方式,但还有另一种方式,有时称为分派,我将在下一个例子的最后版本中向你展示。
顺便问一下,你有没有注意到前面片段的第一行?你有没有注意到 Python 可以进行双重(实际上甚至是多重)比较?这太棒了!
让我们通过简单地编写一些代码来开始新的例子,根据顾客的优惠券价值为他们分配折扣。我会保持逻辑最低限度,记住我们真正关心的是理解条件和循环:
# coupons.py
customers = [dict(id=1, total=200, coupon_code='F20'), # F20: fixed, £20dict(id=2, total=150, coupon_code='P30'), # P30: percent, 30%dict(id=3, total=100, coupon_code='P50'), # P50: percent, 50%dict(id=4, total=110, coupon_code='F15'), # F15: fixed, £15
]
for customer in customers:code = customer['coupon_code']if code == 'F20':customer['discount'] = 20.0elif code == 'F15':customer['discount'] = 15.0elif code == 'P30':customer['discount'] = customer['total'] * 0.3elif code == 'P50':customer['discount'] = customer['total'] * 0.5else:customer['discount'] = 0.0for customer in customers:print(customer['id'], customer['total'], customer['discount'])
我们首先设置一些顾客。他们有一个订单总额,一个优惠券代码和一个 ID。我编造了四种不同类型的优惠券,两种是固定的,两种是基于百分比的。你可以看到,在if/elif/else级联中,我相应地应用折扣,并将其设置为customer字典中的'discount'键。
最后,我只是打印出部分数据,看看我的代码是否正常工作:
$ python coupons.py
1 200 20.0
2 150 45.0
3 100 50.0
4 110 15.0
这段代码很容易理解,但所有这些子句有点混乱。一眼看去很难看出发生了什么,我不喜欢。在这种情况下,你可以利用字典来优化,就像这样:
# coupons.dict.py
customers = [dict(id=1, total=200, coupon_code='F20'), # F20: fixed, £20dict(id=2, total=150, coupon_code='P30'), # P30: percent, 30%dict(id=3, total=100, coupon_code='P50'), # P50: percent, 50%dict(id=4, total=110, coupon_code='F15'), # F15: fixed, £15
]
discounts = {'F20': (0.0, 20.0), # each value is (percent, fixed)'P30': (0.3, 0.0),'P50': (0.5, 0.0),'F15': (0.0, 15.0),
}
for customer in customers:code = customer['coupon_code']percent, fixed = discounts.get(code, (0.0, 0.0))customer['discount'] = percent * customer['total'] + fixedfor customer in customers:print(customer['id'], customer['total'], customer['discount'])
运行前面的代码产生了与之前片段完全相同的结果。我们节省了两行,但更重要的是,我们在可读性方面获得了很多好处,因为现在for循环的主体只有三行,非常容易理解。这里的概念是使用字典作为分发器。换句话说,我们尝试根据一个代码(我们的coupon_code)从字典中获取一些东西,并通过使用dict.get(key, default),我们确保当code不在字典中并且我们需要一个默认值时,我们也能满足。
请注意,我必须应用一些非常简单的线性代数来正确计算折扣。每个折扣在字典中都有一个百分比和固定部分,由一个二元组表示。通过应用percent * total + fixed,我们得到正确的折扣。当percent为0时,该公式只给出固定金额,当固定为0时,它给出percent * total。
这种技术很重要,因为它也用于其他上下文中,例如函数,它实际上比我们在前面的片段中看到的要强大得多。使用它的另一个优势是,您可以以这样的方式编写代码,使得discounts字典的键和值可以动态获取(例如,从数据库中获取)。这将允许代码适应您拥有的任何折扣和条件,而无需修改任何内容。
如果它对您不是完全清楚,我建议您花时间进行实验。更改值并添加打印语句,以查看程序运行时发生了什么。
快速浏览itertools模块
关于可迭代对象、迭代器、条件逻辑和循环的章节,如果没有提到itertools模块,就不完整。如果您喜欢迭代,这是一种天堂。
根据 Python 官方文档(docs.python.org/2/library/itertools.html),itertools模块是:
这个模块实现了一些迭代器构建块,受到 APL、Haskell 和 SML 中的构造的启发。每个都以适合 Python 的形式重新表达。该模块标准化了一组核心的快速、内存高效的工具,这些工具本身或组合在一起都很有用。它们一起构成了一个“迭代器代数”,使得可以在纯 Python 中简洁高效地构建专门的工具。
在这里我无法向您展示在这个模块中可以找到的所有好东西,所以我鼓励您自己去查看,我保证您会喜欢它。简而言之,它为您提供了三种广泛的迭代器类别。我将给您展示每一种迭代器中取出的一个非常小的例子,只是为了让您稍微流口水。
无限迭代器
无限迭代器允许您以不同的方式使用for循环,就像它是一个while循环一样:
# infinite.py
from itertools import countfor n in count(5, 3):if n > 20:breakprint(n, end=', ') # instead of newline, comma and space
运行代码会得到这个结果:
$ python infinite.py
5, 8, 11, 14, 17, 20,
count工厂类创建一个不断计数的迭代器。它从5开始,然后不断加3。如果我们不想陷入无限循环,我们需要手动中断它。
在最短输入序列上终止的迭代器
这个类别非常有趣。它允许您基于多个迭代器创建一个迭代器,并根据某种逻辑组合它们的值。这里的关键是,在这些迭代器中,如果有任何一个比其他迭代器短,那么生成的迭代器不会中断,它将在最短的迭代器耗尽时停止。我知道这很理论化,所以让我用compress给您举个例子。这个迭代器根据选择器中的相应项目是True还是False,将数据返回给您:
compress('ABC', (1, 0, 1))会返回'A'和'C',因为它们对应于1。让我们看一个简单的例子:
# compress.py
from itertools import compress
data = range(10)
even_selector = [1, 0] * 10
odd_selector = [0, 1] * 10even_numbers = list(compress(data, even_selector))
odd_numbers = list(compress(data, odd_selector))print(odd_selector)
print(list(data))
print(even_numbers)
print(odd_numbers)
请注意,odd_selector 和 even_selector 长度为 20,而 data 只有 10 个元素。compress 会在 data 产生最后一个元素时停止。运行此代码会产生以下结果:
$ python compress.py
[0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[0, 2, 4, 6, 8]
[1, 3, 5, 7, 9]
这是一种非常快速和方便的方法,可以从可迭代对象中选择元素。代码非常简单,只需注意,我们使用 list() 而不是 for 循环来迭代压缩调用返回的每个值,它们的作用是相同的,但是 list() 不执行一系列指令,而是将所有值放入列表并返回。
组合生成器
最后但并非最不重要的,组合生成器。如果你喜欢这种东西,这些真的很有趣。让我们来看一个关于排列的简单例子。
根据 Wolfram Mathworld:
排列,也称为“排列数”或“顺序”,是将有序列表 S 的元素重新排列,使其与 S 本身形成一一对应的重新排列。
例如,ABC 有六种排列:ABC、ACB、BAC、BCA、CAB 和 CBA。
如果一个集合有 N 个元素,那么它们的排列数是 N! (N 阶乘)。对于 ABC 字符串,排列数为 3! = 3 * 2 * 1 = 6。让我们用 Python 来做一下:
# permutations.py
from itertools import permutations
print(list(permutations('ABC')))
这段非常简短的代码片段产生了以下结果:
$ python permutations.py
[('A', 'B', 'C'), ('A', 'C', 'B'), ('B', 'A', 'C'), ('B', 'C', 'A'), ('C', 'A', 'B'), ('C', 'B', 'A')]
当你玩排列时要非常小心。它们的数量增长速度与你要排列的元素的阶乘成比例,而这个数字可能会变得非常大,非常快。
总结
在本章中,我们迈出了扩展我们编码词汇的又一步。我们看到了如何通过评估条件来驱动代码的执行,以及如何循环和迭代序列和对象集合。这赋予了我们控制代码运行时发生的事情的能力,这意味着我们正在了解如何塑造它,使其做我们想要的事情,并对动态变化的数据做出反应。
我们还看到了如何在几个简单的例子中将所有东西组合在一起,最后,我们简要地看了一下 itertools 模块,其中充满了可以进一步丰富我们使用 Python 的有趣迭代器。
现在是时候换个方式,向前迈进一步,谈谈函数。下一章将全面讨论它们,因为它们非常重要。确保你对到目前为止所涵盖的内容感到舒适。我想给你提供一些有趣的例子,所以我会快一点。准备好了吗?翻页吧。
第四章:函数,代码的构建块
创建架构就是把东西放在一起。把什么放在一起?函数和对象。"– 勒·柯布西耶
在前几章中,我们已经看到 Python 中的一切都是对象,函数也不例外。但是,函数究竟是什么?函数是一系列执行任务的指令,打包成一个单元。然后可以在需要的地方导入并使用这个单元。使用函数在代码中有许多优点,我们很快就会看到。
在本章中,我们将涵盖以下内容:
-
函数——它们是什么,为什么我们应该使用它们
-
作用域和名称解析
-
函数签名——输入参数和返回值
-
递归和匿名函数
-
导入对象以重用代码
我相信这句话,一张图胜过千言万语,在向一个对这个概念新手解释函数时尤其正确,所以请看一下下面的图表:

如您所见,函数是一组指令,作为一个整体打包,就像一个盒子。函数可以接受输入参数并产生输出值。这两者都是可选的,我们将在本章的示例中看到。
在 Python 中,使用def关键字定义函数,随后是函数名称,后面跟着一对括号(可能包含或不包含输入参数),冒号(:)表示函数定义行的结束。紧接着,缩进四个空格,我们找到函数的主体,这是函数在调用时将执行的一组指令。
请注意,缩进四个空格不是强制性的,但这是PEP 8建议的空格数量,在实践中是最广泛使用的间距度量。
函数可能会返回输出,也可能不会。如果函数想要返回输出,它会使用return关键字,后面跟着期望的输出。如果您有鹰眼,您可能已经注意到在前面图表的输出部分的Optional后面有一个小*****。这是因为在 Python 中,函数总是返回一些东西,即使您没有明确使用return子句。如果函数在其主体中没有return语句,或者return语句本身没有给出值,函数将返回None。这种设计选择背后的原因超出了介绍性章节的范围,所以您需要知道的是,这种行为会让您的生活更轻松。一如既往,感谢 Python。
为什么要使用函数?
函数是任何语言中最重要的概念和构造之一,所以让我给你几个需要它们的原因:
-
它们减少了程序中的代码重复。通过将特定任务由一个良好的打包代码块处理,我们可以在需要时导入并调用它,无需重复其实现。
-
它们有助于将复杂的任务或过程分解为更小的块,每个块都成为一个函数。
-
它们隐藏了实现细节,使其用户不可见。
-
它们提高了可追溯性。
-
它们提高可读性。
让我们看一些示例,以更好地理解每一点。
减少代码重复
想象一下,您正在编写一段科学软件,需要计算素数直到一个限制,就像我们在上一章中所做的那样。您有一个很好的算法来计算它们,所以您将它复制并粘贴到需要的任何地方。然而,有一天,您的朋友B.黎曼给了您一个更好的算法来计算素数,这将为您节省大量时间。在这一点上,您需要检查整个代码库,并用新的代码替换旧的代码。
这实际上是一个不好的做法。这容易出错,你永远不知道你是不是误删或者误留了哪些代码行,当你把代码剪切粘贴到其他代码中时,你也可能会错过其中一个计算质数的地方,导致你的软件处于不一致的状态,同样的操作在不同的地方以不同的方式执行。如果你需要修复一个 bug 而不是用更好的版本替换代码,而你错过了其中一个地方呢?那将更糟糕。
那么,你应该怎么做?简单!你写一个函数get_prime_numbers(upto),在任何需要质数列表的地方使用它。当B. Riemann给你新代码时,你只需要用新实现替换该函数的主体,就完成了!其余的软件将自动适应,因为它只是调用函数。
你的代码会更短,不会受到旧方法和新方法执行任务的不一致性的影响,也不会因为复制粘贴失败或疏忽而导致未检测到的 bug。使用函数,你只会从中获益,我保证。
拆分复杂任务
函数还非常有用,可以将长或复杂的任务分解为较小的任务。最终结果是,代码从中受益,例如可读性、可测试性和重用性。举个简单的例子,想象一下你正在准备一份报告。你的代码需要从数据源获取数据,解析数据,过滤数据,整理数据,然后对其运行一系列算法,以产生将供Report类使用的结果。阅读这样的程序并不罕见,它们只是一个大大的do_report(data_source)函数。有数十行或数百行代码以return report结束。
这些情况在科学代码中更常见,这些代码在算法上可能很出色,但有时在编写风格上缺乏经验丰富的程序员的触觉。现在,想象一下几百行代码。很难跟进,找到事情改变上下文的地方(比如完成一个任务并开始下一个任务)。你有这个画面了吗?好了。不要这样做!相反,看看这段代码:
# data.science.example.py
def do_report(data_source):# fetch and prepare datadata = fetch_data(data_source)parsed_data = parse_data(data)filtered_data = filter_data(parsed_data)polished_data = polish_data(filtered_data)# run algorithms on datafinal_data = analyse(polished_data)# create and return reportreport = Report(final_data)return report
前面的例子当然是虚构的,但你能看出来如果需要检查代码会有多容易吗?如果最终结果看起来不对,逐个调试do_report函数中的单个数据输出将会非常容易。此外,暂时从整个过程中排除部分过程也更容易(你只需要注释掉需要暂停的部分)。这样的代码更容易处理。
隐藏实现细节
让我们继续使用前面的例子来谈谈这一点。你可以看到,通过阅读do_report函数的代码,你可以在不阅读一行实现的情况下获得相当好的理解。这是因为函数隐藏了实现细节。这意味着,如果你不需要深入了解细节,你就不必强制自己去了解,就像如果do_report只是一个庞大的函数一样。为了理解发生了什么,你必须阅读每一行代码。而使用函数,你就不需要这样做。这减少了你阅读代码的时间,而在专业环境中,阅读代码所花费的时间比实际编写代码的时间要多得多,因此尽可能减少这部分时间非常重要。
提高可读性
程序员有时候看不出来为什么要写一个只有一两行代码的函数,所以让我们看一个例子,告诉你为什么你应该这样做。
想象一下,你需要计算两个矩阵的乘积:

你更喜欢阅读这段代码吗:
# matrix.multiplication.nofunc.py
a = [[1, 2], [3, 4]]
b = [[5, 1], [2, 1]]c = [[sum(i * j for i, j in zip(r, c)) for c in zip(*b)]for r in a]
或者你更喜欢这个:
# matrix.multiplication.func.py
# this function could also be defined in another module
def matrix_mul(a, b):return [[sum(i * j for i, j in zip(r, c)) for c in zip(*b)]for r in a]a = [[1, 2], [3, 4]]
b = [[5, 1], [2, 1]]
c = matrix_mul(a, b)
在第二个例子中,更容易理解c是a和b之间的乘法结果。通过代码更容易阅读,如果您不需要修改该乘法逻辑,甚至不需要深入了解实现细节。因此,在这里提高了可读性,而在第一个片段中,您将不得不花时间尝试理解那个复杂的列表推导在做什么。
提高可追溯性
想象一下,您已经编写了一个电子商务网站。您在页面上展示了产品价格。假设您的数据库中的价格是不含增值税(销售税)的,但是您希望在网站上以 20%的增值税显示它们。以下是从不含增值税价格计算含增值税价格的几种方法:
# vat.py
price = 100 # GBP, no VAT
final_price1 = price * 1.2
final_price2 = price + price / 5.0
final_price3 = price * (100 + 20) / 100.0
final_price4 = price + price * 0.2
这四种不同的计算含增值税价格的方式都是完全可以接受的,我向您保证,这些年来我在同事的代码中找到了它们。现在,想象一下,您已经开始在不同的国家销售您的产品,其中一些国家有不同的增值税率,因此您需要重构您的代码(整个网站)以使增值税计算动态化。
您如何追踪所有进行增值税计算的地方?今天的编码是一个协作任务,您无法确定增值税是否仅使用了这些形式中的一种。相信我,这将是一场噩梦。
因此,让我们编写一个函数,该函数接受输入值vat和price(不含增值税),并返回含增值税的价格:
# vat.function.py
def calculate_price_with_vat(price, vat):return price * (100 + vat) / 100
现在您可以导入该函数,并在您的网站的任何地方使用它,需要计算含增值税的价格,并且当您需要跟踪这些调用时,您可以搜索calculate_price_with_vat。
请注意,在前面的例子中,假定price是不含增值税的,vat是一个百分比值(例如 19、20 或 23)。
作用域和名称解析
您还记得我们在第一章中谈到的作用域和命名空间吗,Python 的初级介绍?我们现在将扩展这个概念。最后,我们可以谈论函数,这将使一切更容易理解。让我们从一个非常简单的例子开始:
# scoping.level.1.py
def my_function():test = 1 # this is defined in the local scope of the functionprint('my_function:', test)test = 0 # this is defined in the global scope
my_function()
print('global:', test)
在前面的例子中,我在两个不同的地方定义了test名称。实际上它在两个不同的作用域中。一个是全局作用域(test = 0),另一个是my_function函数的局部作用域(test = 1)。如果您执行该代码,您会看到这个:
$ python scoping.level.1.py
my_function: 1
global: 0
很明显,test = 1覆盖了my_function中的test = 0赋值。在全局上下文中,test仍然是0,正如您从程序的输出中所看到的,但是我们在函数体中再次定义了test名称,并将其指向值为1的整数。因此,这两个test名称都存在,一个在全局作用域中,指向值为0的int对象,另一个在my_function作用域中,指向值为1的int对象。让我们注释掉test = 1的那一行。Python 会在下一个封闭的命名空间中搜索test名称(回想一下LEGB规则:local,enclosing,global,built-in,在第一章中描述,Python 的初级介绍),在这种情况下,我们将看到值0被打印两次。在您的代码中尝试一下。
现在,让我们提高一下难度:
# scoping.level.2.py
def outer():test = 1 # outer scopedef inner():test = 2 # inner scopeprint('inner:', test)inner()print('outer:', test)test = 0 # global scope
outer()
print('global:', test)
在前面的代码中,我们有两个级别的遮蔽。一个级别在函数outer中,另一个级别在函数inner中。这并不是什么难事,但可能会有些棘手。如果我们运行代码,我们会得到:
$ python scoping.level.2.py
inner: 2
outer: 1
global: 0
尝试注释掉test = 1行。您能猜到结果会是什么吗?嗯,当达到print('outer:', test)行时,Python 将不得不在下一个封闭范围中查找test,因此它将找到并打印0,而不是1。确保您也注释掉test = 2,以查看您是否理解发生了什么,以及 LEGB 规则是否清晰,然后再继续。
另一个需要注意的事情是,Python 允许您在另一个函数中定义一个函数。内部函数的名称在外部函数的命名空间中定义,就像任何其他名称一样。
global 和 nonlocal 语句
回到前面的例子,我们可以通过使用这两个特殊语句之一来更改对test名称的遮蔽:global和nonlocal。正如您从前面的例子中看到的,当我们在inner函数中定义test = 2时,我们既不会覆盖outer函数中的test,也不会覆盖全局范围中的test。如果我们在不定义它们的嵌套范围中使用它们,我们可以读取这些名称,但是我们不能修改它们,因为当我们编写赋值指令时,实际上是在当前范围中定义一个新名称。
我们如何改变这种行为呢?嗯,我们可以使用nonlocal语句。根据官方文档:
“nonlocal 语句使列出的标识符引用最近的封闭范围中先前绑定的变量,不包括全局变量。”
让我们在inner函数中引入它,看看会发生什么:
# scoping.level.2.nonlocal.py
def outer():test = 1 # outer scopedef inner():nonlocal testtest = 2 # nearest enclosing scope (which is 'outer')print('inner:', test)inner()print('outer:', test)test = 0 # global scope
outer()
print('global:', test)
请注意,在inner函数的主体中,我已经声明了test名称为nonlocal。运行此代码会产生以下结果:
$ python scoping.level.2.nonlocal.py
inner: 2
outer: 2
global: 0
哇,看看那个结果!这意味着,通过在inner函数中声明test为nonlocal,我们实际上得到了将test名称绑定到在outer函数中声明的名称。如果我们从inner函数中删除nonlocal test行并尝试在outer函数中尝试相同的技巧,我们将得到一个SyntaxError,因为nonlocal语句在封闭范围上运行,不包括全局范围。
那么有没有办法到达全局命名空间中的test = 0呢?当然,我们只需要使用global语句:
# scoping.level.2.global.py
def outer():test = 1 # outer scopedef inner():global testtest = 2 # global scopeprint('inner:', test)inner()print('outer:', test)test = 0 # global scope
outer()
print('global:', test)
请注意,我们现在已经声明了test名称为global,这基本上将其绑定到我们在全局命名空间中定义的名称(test = 0)。运行代码,您应该会得到以下结果:
$ python scoping.level.2.global.py
inner: 2
outer: 1
global: 2
这表明受test = 2赋值影响的名称现在是global。这个技巧在outer函数中也会起作用,因为在这种情况下,我们是在引用全局范围。自己尝试一下,看看有什么变化,熟悉作用域和名称解析,这非常重要。此外,您能告诉在前面的例子中如果在outer之外定义inner会发生什么吗?
输入参数
在本章的开始,我们看到函数可以接受输入参数。在我们深入讨论所有可能类型的参数之前,让我们确保您清楚地理解了向函数传递参数的含义。有三个关键点需要记住:
-
参数传递只不过是将对象分配给本地变量名称
-
在函数内部将对象分配给参数名称不会影响调用者
-
更改函数中的可变对象参数会影响调用者
让我们分别看一下这些要点的例子。
参数传递
看一下以下代码。我们在全局范围内声明一个名称x,然后我们声明一个函数func(y),最后我们调用它,传递x:
# key.points.argument.passing.py
x = 3
def func(y):print(y)
func(x) # prints: 3
当使用x调用func时,在其局部范围内,创建了一个名为y的名称,并且它指向与x指向的相同对象。这可以通过以下图表更清楚地解释(不用担心 Python 3.3,这是一个未更改的功能):

前面图的右侧描述了程序在执行到结束后的状态,即func返回(None)后的状态。看一下 Frames 列,注意我们在全局命名空间(全局帧)中有两个名称,x和func,分别指向一个int(值为3)和一个function对象。在下面的名为func的矩形中,我们可以看到函数的局部命名空间,其中只定义了一个名称:y。因为我们用x调用了func(图的左侧第 5 行),y指向与x指向的相同的对象。这就是在将参数传递给函数时发生的情况。如果我们在函数定义中使用名称x而不是y,情况将完全相同(可能一开始有点混乱),函数中会有一个局部的x,而外部会有一个全局的x,就像我们在本章前面的作用域和名称解析部分中看到的那样。
总之,实际发生的是函数在其局部范围内创建了作为参数定义的名称,当我们调用它时,我们基本上告诉 Python 这些名称必须指向哪些对象。
分配给参数名称不会影响调用者
这一点一开始可能有点难以理解,所以让我们看一个例子:
# key.points.assignment.py
x = 3
def func(x):x = 7 # defining a local x, not changing the global one
func(x)
print(x) # prints: 3
在前面的代码中,当执行x = 7行时,在func函数的局部范围内,名称x指向一个值为7的整数,而全局的x保持不变。
更改可变对象会影响调用者
这是最后一点,非常重要,因为 Python 在处理可变对象时表现得似乎有所不同(尽管只是表面上)。让我们看一个例子:
# key.points.mutable.py
x = [1, 2, 3]
def func(x):x[1] = 42 # this affects the caller!func(x)
print(x) # prints: [1, 42, 3]
哇,我们实际上改变了原始对象!如果你仔细想想,这种行为并不奇怪。函数中的x名称被设置为通过函数调用指向调用者对象,在函数体内,我们没有改变x,也就是说,我们没有改变它的引用,换句话说,我们没有改变x指向的对象。我们访问该对象在位置 1 的元素,并更改其值。
记住输入参数部分下的第 2 点:在函数内将对象分配给参数名称不会影响调用者。如果这对你来说很清楚,下面的代码就不会让你感到惊讶:
# key.points.mutable.assignment.py
x = [1, 2, 3]
def func(x):x[1] = 42 # this changes the caller!x = 'something else' # this points x to a new string objectfunc(x)
print(x) # still prints: [1, 42, 3]
看一下我标记的两行。一开始,就像以前一样,我们再次访问调用者对象,位于位置 1,并将其值更改为数字42。然后,我们重新分配x指向'something else'字符串。这样留下了调用者不变,实际上,输出与前面片段的输出相同。
花点时间来玩弄这个概念,并尝试使用打印和调用id函数,直到你的思路清晰。这是 Python 的一个关键方面,必须非常清楚,否则你可能会在代码中引入微妙的错误。再次强调,Python Tutor 网站(www.pythontutor.com/)将通过可视化这些概念来帮助你很多。
现在我们对输入参数及其行为有了很好的理解,让我们看看如何指定它们。
如何指定输入参数
指定输入参数的五种不同方式:
-
位置参数
-
关键字参数
-
变量位置参数
-
可变关键字参数
-
仅关键字参数
让我们逐一来看看它们。
位置参数
位置参数从左到右读取,它们是最常见的参数类型:
# arguments.positional.py
def func(a, b, c):print(a, b, c)
func(1, 2, 3) # prints: 1 2 3
没有什么别的要说的。它们可以是任意多个,按位置分配。在函数调用中,1排在前面,2排在第二,3排在第三,因此它们分别分配给a、b和c。
关键字参数和默认值
关键字参数通过使用name=value语法进行分配:
# arguments.keyword.py
def func(a, b, c):print(a, b, c)
func(a=1, c=2, b=3) # prints: 1 3 2
关键字参数是按名称匹配的,即使它们不遵守定义的原始位置(当我们混合和匹配不同类型的参数时,稍后我们将看到这种行为的限制)。
关键字参数的对应物,在定义方面,是默认值。 语法是相同的,name=value,并且允许我们不必提供参数,如果我们对给定的默认值感到满意:
# arguments.default.py
def func(a, b=4, c=88):print(a, b, c)func(1) # prints: 1 4 88
func(b=5, a=7, c=9) # prints: 7 5 9
func(42, c=9) # prints: 42 4 9
func(42, 43, 44) # prints: 42, 43, 44
有两件非常重要的事情需要注意。 首先,你不能在位置参数的左边指定默认参数。 其次,在这些例子中,注意当参数在列表中没有使用argument_name=value语法时,它必须是列表中的第一个参数,并且总是分配给a。 还要注意,以位置方式传递值仍然有效,并且遵循函数签名顺序(示例的最后一行)。
尝试混淆这些参数,看看会发生什么。 Python 错误消息非常擅长告诉你出了什么问题。 例如,如果你尝试了这样的东西:
# arguments.default.error.py
def func(a, b=4, c=88):print(a, b, c)
func(b=1, c=2, 42) # positional argument after keyword one
你会得到以下错误:
$ python arguments.default.error.pyFile "arguments.default.error.py", line 4func(b=1, c=2, 42) # positional argument after keyword one^
SyntaxError: positional argument follows keyword argument
这会告诉你你错误地调用了函数。
可变位置参数
有时候你可能想要向函数传递可变数量的位置参数,Python 为你提供了这样的能力。 让我们看一个非常常见的用例,minimum函数。 这是一个计算其输入值的最小值的函数:
# arguments.variable.positional.py
def minimum(*n):# print(type(n)) # n is a tupleif n: # explained after the codemn = n[0]for value in n[1:]:if value < mn:mn = valueprint(mn)minimum(1, 3, -7, 9) # n = (1, 3, -7, 9) - prints: -7
minimum() # n = () - prints: nothing
正如你所看到的,当我们在参数名前面加上*时,我们告诉 Python 该参数将根据函数的调用方式收集可变数量的位置参数。 在函数内部,n是一个元组。 取消注释print(type(n)),自己看看并玩一会儿。
你是否注意到我们如何用简单的if n:检查n是否为空? 这是因为在 Python 中,集合对象在非空时求值为True,否则为False。 这对于元组,集合,列表,字典等都是成立的。
还有一件事要注意的是,当我们在没有参数的情况下调用函数时,我们可能希望抛出错误,而不是默默地什么都不做。 在这种情况下,我们不关心使这个函数健壮,而是理解可变位置参数。
让我们举个例子,展示两件事,根据我的经验,对于新手来说是令人困惑的:
# arguments.variable.positional.unpacking.py
def func(*args):print(args)values = (1, 3, -7, 9)
func(values) # equivalent to: func((1, 3, -7, 9))
func(*values) # equivalent to: func(1, 3, -7, 9)
好好看看前面例子的最后两行。 在第一个例子中,我们用一个参数调用func,一个四元组。 在第二个例子中,通过使用*语法,我们正在做一种叫做解包的事情,这意味着四元组被解包,函数被调用时有四个参数:1, 3, -7, 9。
这种行为是 Python 为你做的魔术的一部分,允许你在动态调用函数时做一些惊人的事情。
变量关键字参数
可变关键字参数与可变位置参数非常相似。 唯一的区别是语法(**而不是*),以及它们被收集在一个字典中。 集合和解包的工作方式相同,所以让我们看一个例子:
# arguments.variable.keyword.py
def func(**kwargs):print(kwargs)# All calls equivalent. They print: {'a': 1, 'b': 42}
func(a=1, b=42)
func(**{'a': 1, 'b': 42})
func(**dict(a=1, b=42))
在前面的例子中,所有的调用都是等价的。 你可以看到,在函数定义中在参数名前面添加**告诉 Python 使用该名称来收集可变数量的关键字参数。 另一方面,当我们调用函数时,我们可以显式地传递name=value参数,或者使用相同的**语法解包字典。
能够传递可变数量的关键字参数之所以如此重要的原因可能目前还不明显,那么,来一个更现实的例子怎么样?让我们定义一个连接到数据库的函数。我们希望通过简单调用这个函数而连接到默认数据库。我们还希望通过传递适当的参数来连接到任何其他数据库。在继续阅读之前,试着花几分钟时间自己想出一个解决方案:
# arguments.variable.db.py
def connect(**options):conn_params = {'host': options.get('host', '127.0.0.1'),'port': options.get('port', 5432),'user': options.get('user', ''),'pwd': options.get('pwd', ''),}print(conn_params)# we then connect to the db (commented out)# db.connect(**conn_params)connect()
connect(host='127.0.0.42', port=5433)
connect(port=5431, user='fab', pwd='gandalf')
注意在函数中,我们可以准备一个连接参数的字典(conn_params),使用默认值作为回退,允许在函数调用中提供时进行覆盖。有更好的方法可以用更少的代码行来实现,但我们现在不关心这个。运行上述代码会产生以下结果:
$ python arguments.variable.db.py
{'host': '127.0.0.1', 'port': 5432, 'user': '', 'pwd': ''}
{'host': '127.0.0.42', 'port': 5433, 'user': '', 'pwd': ''}
{'host': '127.0.0.1', 'port': 5431, 'user': 'fab', 'pwd': 'gandalf'}
注意函数调用和输出之间的对应关系。注意默认值是如何根据传递给函数的参数进行覆盖的。
仅限关键字参数
Python 3 允许一种新类型的参数:仅限关键字参数。我们只会简要地研究它们,因为它们的使用情况并不那么频繁。有两种指定它们的方式,要么在可变位置参数之后,要么在单独的*之后。让我们看一个例子:
# arguments.keyword.only.py
def kwo(*a, c):print(a, c)kwo(1, 2, 3, c=7) # prints: (1, 2, 3) 7
kwo(c=4) # prints: () 4
# kwo(1, 2) # breaks, invalid syntax, with the following error
# TypeError: kwo() missing 1 required keyword-only argument: 'c'def kwo2(a, b=42, *, c):print(a, b, c)kwo2(3, b=7, c=99) # prints: 3 7 99
kwo2(3, c=13) # prints: 3 42 13
# kwo2(3, 23) # breaks, invalid syntax, with the following error
# TypeError: kwo2() missing 1 required keyword-only argument: 'c'
如预期的那样,函数kwo接受可变数量的位置参数(a)和一个仅限关键字参数c。调用的结果很直接,您可以取消注释第三个调用以查看 Python 返回的错误。
相同的规则适用于函数kwo2,它与kwo不同之处在于它接受一个位置参数a,一个关键字参数b,然后是一个仅限关键字参数c。您可以取消注释第三个调用以查看错误。
现在你知道如何指定不同类型的输入参数了,让我们看看如何在函数定义中结合它们。
结合输入参数
只要遵循以下顺序规则,就可以结合输入参数:
-
在定义函数时,普通的位置参数先出现(
name),然后是任何默认参数(name=value),然后是可变位置参数(*name或简单的*),然后是任何关键字参数(name或name=value形式都可以),最后是任何可变关键字参数(**name)。 -
另一方面,在调用函数时,参数必须按照以下顺序给出:先是位置参数(
value),然后是任意组合的关键字参数(name=value),可变位置参数(*name),然后是可变关键字参数(**name)。
由于这在理论世界中留下来可能有点棘手,让我们看几个快速的例子:
# arguments.all.py
def func(a, b, c=7, *args, **kwargs):print('a, b, c:', a, b, c)print('args:', args)print('kwargs:', kwargs)func(1, 2, 3, *(5, 7, 9), **{'A': 'a', 'B': 'b'})
func(1, 2, 3, 5, 7, 9, A='a', B='b') # same as previous one
注意函数定义中参数的顺序,两个调用是等价的。在第一个调用中,我们使用了可迭代对象和字典的解包操作符,而在第二个调用中,我们使用了更明确的语法。执行这个函数会产生以下结果(我只打印了一个调用的结果,另一个结果相同):
$ python arguments.all.py
a, b, c: 1 2 3
args: (5, 7, 9)
kwargs: {'A': 'a', 'B': 'b'}
现在让我们看一个关键字参数的例子:
# arguments.all.kwonly.py
def func_with_kwonly(a, b=42, *args, c, d=256, **kwargs):print('a, b:', a, b)print('c, d:', c, d)print('args:', args)print('kwargs:', kwargs)# both calls equivalent
func_with_kwonly(3, 42, c=0, d=1, *(7, 9, 11), e='E', f='F')
func_with_kwonly(3, 42, *(7, 9, 11), c=0, d=1, e='E', f='F')
请注意我在函数声明中突出显示了仅限关键字参数。它们出现在*args可变位置参数之后,如果它们直接出现在单个*之后,情况也是一样的(在这种情况下就没有可变位置参数了)。
执行这个函数会产生以下结果(我只打印了一个调用的结果):
$ python arguments.all.kwonly.py
a, b: 3 42
c, d: 0 1
args: (7, 9, 11)
kwargs: {'e': 'E', 'f': 'F'}
还要注意的一件事是我给可变位置和关键字参数起的名字。你可以选择不同的名字,但要注意args和kwargs是这些参数的通用约定名称,至少是通用的。
额外的解包概括
Python 3.5 中引入的最近的新功能之一是能够扩展可迭代(*)和字典(**)解包操作符,以允许在更多位置、任意次数和额外情况下解包。我将给你一个关于函数调用的例子:
# additional.unpacking.py
def additional(*args, **kwargs):print(args)print(kwargs)args1 = (1, 2, 3)
args2 = [4, 5]
kwargs1 = dict(option1=10, option2=20)
kwargs2 = {'option3': 30}
additional(*args1, *args2, **kwargs1, **kwargs2)
在前面的例子中,我们定义了一个简单的函数,打印它的输入参数args和kwargs。新功能在于我们调用这个函数的方式。注意我们如何解包多个可迭代对象和字典,并且它们在args和kwargs下正确地合并。这个功能之所以重要的原因在于,它允许我们不必在代码中合并args1和args2,以及kwargs1和kwargs2。运行代码会产生:
$ python additional.unpacking.py
(1, 2, 3, 4, 5)
{'option1': 10, 'option2': 20, 'option3': 30}
请参考 PEP 448(www.python.org/dev/peps/pep-0448/)来了解这一新功能的全部内容,并查看更多示例。
避免陷阱!可变默认值
在 Python 中需要非常注意的一件事是,默认值是在def时创建的,因此,对同一个函数的后续调用可能会根据它们的默认值的可变性而表现得不同。让我们看一个例子:
# arguments.defaults.mutable.py
def func(a=[], b={}):print(a)print(b)print('#' * 12)a.append(len(a)) # this will affect a's default valueb[len(a)] = len(a) # and this will affect b's onefunc()
func()
func()
两个参数都有可变的默认值。这意味着,如果你影响这些对象,任何修改都会在后续的函数调用中保留下来。看看你能否理解这些调用的输出:
$ python arguments.defaults.mutable.py
[]
{}
############
[0]
{1: 1}
############
[0, 1]
{1: 1, 2: 2}
############
很有趣,不是吗?虽然这种行为一开始可能看起来很奇怪,但实际上是有道理的,而且非常方便,例如,在使用记忆化技术时(如果你感兴趣,可以搜索一下)。更有趣的是,当我们在调用之间引入一个不使用默认值的调用时,会发生什么:
# arguments.defaults.mutable.intermediate.call.py
func()
func(a=[1, 2, 3], b={'B': 1})
func()
当我们运行这段代码时,输出如下:
$ python arguments.defaults.mutable.intermediate.call.py
[]
{}
############
[1, 2, 3]
{'B': 1}
############
[0]
{1: 1}
############
这个输出告诉我们,即使我们用其他值调用函数,默认值仍然保留。一个让人想到的问题是,我怎样才能每次都得到一个全新的空值?嗯,惯例是这样的:
# arguments.defaults.mutable.no.trap.py
def func(a=None):if a is None:a = []# do whatever you want with `a` ...
请注意,通过使用前面的技术,如果在调用函数时没有传递a,你总是会得到一个全新的空列表。
好了,输入就到此为止,让我们看看另一面,输出。
返回值
函数的返回值是 Python 领先于大多数其他语言的地方之一。通常函数允许返回一个对象(一个值),但在 Python 中,你可以返回一个元组,这意味着你可以返回任何你想要的东西。这个特性允许程序员编写在其他语言中要难得多或者肯定更加繁琐的软件。我们已经说过,要从函数中返回一些东西,我们需要使用return语句,后面跟着我们想要返回的东西。在函数体中可以有多个 return 语句。
另一方面,如果在函数体内部我们没有返回任何东西,或者调用了一个裸的return语句,函数将返回None。这种行为是无害的,尽管我在这里没有足够的空间详细解释为什么 Python 被设计成这样,但我只想告诉你,这个特性允许了几种有趣的模式,并且证实了 Python 是一种非常一致的语言。
我说这是无害的,因为你从来不会被迫收集函数调用的结果。我将用一个例子来说明我的意思:
# return.none.py
def func():pass
func() # the return of this call won't be collected. It's lost.
a = func() # the return of this one instead is collected into `a`
print(a) # prints: None
请注意,函数的整个主体只由pass语句组成。正如官方文档告诉我们的那样,pass是一个空操作。当它被执行时,什么都不会发生。当语法上需要一个语句,但不需要执行任何代码时,它是有用的。在其他语言中,我们可能会用一对花括号({})来表示这一点,定义一个空作用域,但在 Python 中,作用域是通过缩进代码来定义的,因此pass这样的语句是必要的。
还要注意,func函数的第一个调用返回一个值(None),我们没有收集。正如我之前所说,收集函数调用的返回值并不是强制性的。
现在,这很好但不是很有趣,那么我们来写一个有趣的函数吧?记住,在第一章中,Python 的初步介绍,我们谈到了函数的阶乘。让我们在这里写一个(为简单起见,我将假设函数总是以适当的值正确调用,因此我不会对输入参数进行健全性检查):
# return.single.value.py
def factorial(n):if n in (0, 1):return 1result = nfor k in range(2, n):result *= kreturn resultf5 = factorial(5) # f5 = 120
请注意我们有两个返回点。如果n是0或1(在 Python 中通常使用in类型的检查,就像我所做的那样,而不是更冗长的if n == 0 or n == 1:),我们返回1。否则,我们执行所需的计算并返回result。让我们尝试以更简洁的方式编写这个函数:
# return.single.value.2.py from functools import reduce
from operator import muldef factorial(n):return reduce(mul, range(1, n + 1), 1)f5 = factorial(5) # f5 = 120
我知道你在想什么:一行?Python 是优雅而简洁的!我认为这个函数即使你从未见过reduce或mul,也是可读的,但如果你无法阅读或理解它,请花几分钟时间在 Python 文档上做一些研究,直到它的行为对你清晰为止。能够在文档中查找函数并理解他人编写的代码是每个开发人员都需要能够执行的任务,所以把它当作一个挑战。
为此,请确保查找help函数,在控制台探索时会非常有帮助。
返回多个值
与大多数其他语言不同,在 Python 中很容易从函数返回多个对象。这个特性打开了一个全新的可能性世界,并允许你以其他语言难以复制的风格编码。我们的思维受到我们使用的工具的限制,因此当 Python 给予你比其他语言更多的自由时,实际上也在提高你自己的创造力。返回多个值非常容易,你只需使用元组(显式或隐式)。让我们看一个简单的例子,模仿divmod内置函数:
# return.multiple.py
def moddiv(a, b):return a // b, a % bprint(moddiv(20, 7)) # prints (2, 6)
我本可以将前面代码中的突出部分包装在括号中,使其成为一个显式的元组,但没有必要。前面的函数同时返回了结果和除法的余数。
在这个示例的源代码中,我留下了一个简单的测试函数的示例,以确保我的代码进行了正确的计算。
一些建议
在编写函数时,遵循指南非常有用,这样你就可以写得更好。我将快速指出其中一些:
-
函数应该只做一件事:只做一件事的函数很容易用一句简短的话来描述。做多件事的函数可以拆分成做一件事的较小函数。这些较小的函数通常更容易阅读和理解。还记得我们几页前看到的数据科学示例吗?
-
函数应该尽可能小:它们越小,测试和编写它们就越容易,以便它们只做一件事。
-
输入参数越少越好:接受大量参数的函数很快就变得难以管理(除其他问题外)。
-
函数的返回值应该是一致的:返回
False或None并不相同,即使在布尔上下文中它们都会评估为False。False表示我们有信息(False),而None表示没有信息。尝试编写函数以一致的方式返回,无论其主体发生了什么。 -
函数不应该有副作用:换句话说,函数不应该影响你调用它们的值。这可能是目前最难理解的陈述,所以我将给你一个使用列表的例子。在下面的代码中,请注意
sorted函数没有对numbers进行排序,它实际上返回了一个已排序的numbers的副本。相反,list.sort()方法是在numbers对象本身上操作,这是可以的,因为它是一个方法(属于对象的函数,因此有权修改它):
>>> numbers = [4, 1, 7, 5]
>>> sorted(numbers) # won't sort the original `numbers` list
[1, 4, 5, 7]
>>> numbers # let's verify
[4, 1, 7, 5] # good, untouched
>>> numbers.sort() # this will act on the list
>>> numbers
[1, 4, 5, 7]
遵循这些准则,你将编写更好的函数,这将为你服务。
递归函数
当一个函数调用自身来产生结果时,它被称为递归。有时,递归函数非常有用,因为它们使编写代码变得更容易。有些算法使用递归范式编写起来非常容易,而其他一些则不是。没有递归函数无法以迭代方式重写,因此通常由程序员选择处理当前情况的最佳方法。
递归函数的主体通常有两个部分:一个是返回值取决于对自身的后续调用,另一个是不取决于后续调用的情况(称为基本情况)。
例如,我们可以考虑(希望现在已经熟悉的)factorial函数,N!。基本情况是当N为0或1时。函数返回1,无需进一步计算。另一方面,在一般情况下,N!返回乘积1 * 2 * … * (N-1) * N。如果你仔细想想,N!可以这样重写:N! = (N-1)! * N。作为一个实际的例子,考虑5! = 1 * 2 * 3 * 4 * 5 = (1 * 2 * 3 * 4) * 5 = 4! * 5。
让我们用代码写下来:
# recursive.factorial.py
def factorial(n):if n in (0, 1): # base casereturn 1return factorial(n - 1) * n # recursive case
在编写递归函数时,始终考虑你进行了多少嵌套调用,因为有一个限制。有关此信息的更多信息,请查看sys.getrecursionlimit()和sys.setrecursionlimit()。
在编写算法时经常使用递归函数,它们编写起来非常有趣。作为练习,尝试使用递归和迭代方法解决一些简单问题。
匿名函数
我想谈谈的最后一种函数类型是匿名函数。这些函数在 Python 中称为lambda,通常在需要一个完全成熟的带有自己名称的函数会显得有些多余时使用,我们只需要一个快速、简单的一行代码来完成任务。
假设你想要一个包含* N *的所有倍数的列表。假设你想使用filter函数进行筛选,该函数接受一个函数和一个可迭代对象,并构造一个筛选对象,你可以对其进行迭代,从可迭代对象中返回True的元素。如果不使用匿名函数,你可以这样做:
# filter.regular.py
def is_multiple_of_five(n):return not n % 5def get_multiples_of_five(n):return list(filter(is_multiple_of_five, range(n)))
注意我们如何使用is_multiple_of_five来过滤前n个自然数。这似乎有点多余,任务很简单,我们不需要保留is_multiple_of_five函数以备其他用途。让我们使用 lambda 函数重新编写它:
# filter.lambda.py
def get_multiples_of_five(n):return list(filter(lambda k: not k % 5, range(n)))
逻辑完全相同,但现在过滤函数是一个 lambda。定义 lambda 非常简单,遵循这种形式:func_name = lambda [parameter_list]: expression。返回一个函数对象,等同于这个:def func_name([parameter_list]): return expression。
请注意,可选参数在常见的语法中用方括号括起来表示。
让我们再看看两种形式定义的等价函数的另外一些例子:
# lambda.explained.py
# example 1: adder
def adder(a, b):return a + b# is equivalent to:
adder_lambda = lambda a, b: a + b# example 2: to uppercase
def to_upper(s):return s.upper()# is equivalent to:
to_upper_lambda = lambda s: s.upper()
前面的例子非常简单。第一个例子是两个数字相加,第二个例子是生成字符串的大写版本。请注意,我将lambda表达式返回的内容分配给了一个名称(adder_lambda,to_upper_lambda),但在我们在filter示例中使用 lambda 时,没有必要这样做。
函数属性
每个函数都是一个完整的对象,因此它们有很多属性。其中一些是特殊的,可以用一种内省的方式在运行时检查函数对象。下面的脚本是一个例子,展示了其中一部分属性以及如何显示它们的值,用于一个示例函数:
# func.attributes.py
def multiplication(a, b=1):"""Return a multiplied by b. """return a * bspecial_attributes = ["__doc__", "__name__", "__qualname__", "__module__","__defaults__", "__code__", "__globals__", "__dict__","__closure__", "__annotations__", "__kwdefaults__",
]for attribute in special_attributes:print(attribute, '->', getattr(multiplication, attribute))
我使用内置的getattr函数来获取这些属性的值。getattr(obj, attribute)等同于obj.attribute,在我们需要在运行时使用字符串名称获取属性时非常方便。运行这个脚本会产生:
$ python func.attributes.py
__doc__ -> Return a multiplied by b.
__name__ -> multiplication
__qualname__ -> multiplication
__module__ -> __main__
__defaults__ -> (1,)
__code__ -> <code object multiplication at 0x10caf7660, file "func.attributes.py", line 1>
__globals__ -> {...omitted...}
__dict__ -> {}
__closure__ -> None
__annotations__ -> {}
__kwdefaults__ -> None
我省略了__globals__属性的值,因为它太大了。关于这个属性的含义的解释可以在Python 数据模型文档页面的Callable types部分找到(docs.python.org/3/reference/datamodel.html#the-standard-type-hierarchy)。如果你想看到一个对象的所有属性,只需调用dir(object_name),你将得到所有属性的列表。
内置函数
Python 自带了很多内置函数。它们可以在任何地方使用,你可以通过检查builtins模块的dir(__builtins__)来获取它们的列表,或者查看官方 Python 文档。不幸的是,我没有足够的空间在这里介绍所有这些函数。我们已经见过其中一些,比如any、bin、bool、divmod、filter、float、getattr、id、int、len、list、min、print、set、tuple、type和zip,但还有很多,你至少应该阅读一次。熟悉它们,进行实验,为每个函数编写一小段代码,并确保你能随时使用它们。
最后一个例子
在我们结束本章之前,最后一个例子怎么样?我在想我们可以编写一个函数来生成一个小于某个限制的质数列表。我们已经见过这个代码了,所以让我们把它变成一个函数,并且为了保持趣味性,让我们稍微优化一下。
事实证明,你不需要将一个数N除以从2到N-1 的所有数字来判断它是否是质数。你可以停在√N。此外,你不需要测试从2到√N的所有数字的除法,你可以只使用该范围内的质数。如果你感兴趣,我会留给你去弄清楚为什么这样可以,让我们看看代码如何改变:
# primes.py
from math import sqrt, ceildef get_primes(n):"""Calculate a list of primes up to n (included). """primelist = []for candidate in range(2, n + 1):is_prime = Trueroot = ceil(sqrt(candidate)) # division limitfor prime in primelist: # we try only the primesif prime > root: # no need to check any furtherbreakif candidate % prime == 0:is_prime = Falsebreakif is_prime:primelist.append(candidate)return primelist
代码和上一章的一样。我们改变了除法算法,所以我们只使用先前计算出的质数来测试可除性,并且一旦测试除数大于候选数的平方根,我们就停止了。我们使用primelist结果列表来获取除法的质数。我们使用一个花哨的公式来计算根值,即候选数的根的天花板的整数值。虽然一个简单的int(k ** 0.5) + 1也可以满足我们的目的,但我选择的公式更简洁,需要我使用一些导入,我想向你展示。查看math模块中的函数,它们非常有趣!
文档化你的代码
我是一个不需要文档的代码的忠实粉丝。当你正确编程,选择正确的名称并注意细节时,你的代码应该是不言自明的,不需要文档。有时注释是非常有用的,文档也是如此。你可以在PEP 257 - Docstring conventions中找到 Python 文档的指南(www.python.org/dev/peps/pep-0257/),但我会在这里向你展示基础知识。
Python 使用字符串进行文档化,这些字符串被称为docstrings。任何对象都可以被文档化,你可以使用单行或多行 docstrings。单行的非常简单。它们不应该为函数提供另一个签名,而是清楚地说明其目的:
# docstrings.py
def square(n):"""Return the square of a number n. """return n ** 2def get_username(userid):"""Return the username of a user given their id. """return db.get(user_id=userid).username
使用三个双引号的字符串允许您以后轻松扩展。使用以句点结尾的句子,并且不要在前后留下空行。
多行注释的结构方式类似。应该有一个简短的一行说明对象大意的描述,然后是更详细的描述。例如,我已经使用 Sphinx 符号记录了一个虚构的connect函数,在下面的示例中:
def connect(host, port, user, password):"""Connect to a database.Connect to a PostgreSQL database directly, using the givenparameters.:param host: The host IP.:param port: The desired port.:param user: The connection username.:param password: The connection password.:return: The connection object."""# body of the function here...return connection
Sphinx 可能是创建 Python 文档最广泛使用的工具。事实上,官方 Python 文档就是用它编写的。值得花一些时间去了解它。
导入对象
现在您已经对函数有了很多了解,让我们看看如何使用它们。编写函数的整个目的是能够以后重用它们,在 Python 中,这意味着将它们导入到需要它们的命名空间中。有许多不同的方法可以将对象导入命名空间,但最常见的是import module_name和from module_name import function_name。当然,这些都是相当简单的例子,但请暂时忍耐。
import module_name 形式会找到module_name模块,并在执行import语句的本地命名空间中为其定义一个名称。from module_name import identifier 形式比这略微复杂一些,但基本上做的是相同的事情。它找到module_name并搜索属性(或子模块),并在本地命名空间中存储对identifier的引用。
两种形式都可以使用as子句更改导入对象的名称:
from mymodule import myfunc as better_named_func
只是为了让您了解导入的样子,这里有一个来自我的一个项目的测试模块的示例(请注意,导入块之间的空行遵循 PEP 8 的指南:标准库、第三方库和本地代码):
from datetime import datetime, timezone # two imports on the same line
from unittest.mock import patch # single importimport pytest # third party libraryfrom core.models import ( # multiline importExam,Exercise,Solution,
)
当您有一个从项目根目录开始的文件结构时,您可以使用点符号来获取您想要导入到当前命名空间的对象,无论是包、模块、类、函数还是其他任何东西。from module import语法还允许使用一个通配符子句,from module import *,有时用于一次性将模块中的所有名称导入当前命名空间,但出于多种原因,如性能和潜在的静默屏蔽其他名称的风险,这是不被赞成的。您可以在官方 Python 文档中阅读关于导入的所有内容,但在我们离开这个主题之前,让我给您一个更好的例子。
假设您在lib文件夹中的模块funcdef.py中定义了一对函数:square(n)和cube(n)。您希望在与lib文件夹处于相同级别的几个模块中使用它们,这些模块称为func_import.py和func_from.py。显示该项目的树结构会产生以下内容:
├── func_from.py
├── func_import.py
├── lib├── funcdef.py└── __init__.py在我展示每个模块的代码之前,请记住,为了告诉 Python 它实际上是一个包,我们需要在其中放置一个__init__.py模块。
关于__init__.py文件有两件事需要注意。首先,它是一个完整的 Python 模块,因此您可以像对待任何其他模块一样将代码放入其中。其次,从 Python 3.3 开始,不再需要它的存在来使文件夹被解释为 Python 包。
代码如下:
# funcdef.py
def square(n): return n ** 2
def cube(n): return n ** 3 # func_import.py import lib.funcdef
print(lib.funcdef.square(10))
print(lib.funcdef.cube(10)) # func_from.py
from lib.funcdef import square, cube
print(square(10))
print(cube(10))
这两个文件在执行时都会打印100和1000。您可以看到我们如何根据当前范围中导入的内容以及导入的方式和内容来访问square和cube函数的不同方式。
相对导入
到目前为止,我们所见过的导入被称为绝对导入,即它们定义了我们要导入的模块的整个路径,或者我们要从中导入对象的模块。在 Python 中还有另一种导入对象的方式,称为相对导入。在我们想要重新排列大型包的结构而不必编辑子包时,或者当我们想要使包内的模块能够自我导入时,这种方式非常有帮助。相对导入是通过在模块前面添加与我们需要回溯的文件夹数量相同数量的前导点来完成的,以便找到我们正在搜索的内容。简而言之,它就是这样的。
from .mymodule import myfunc
有关相对导入的完整解释,请参阅 PEP 328 (www.python.org/dev/peps/pep-0328/)。
总结
在本章中,我们探讨了函数的世界。它们非常重要,从现在开始,我们基本上会在任何地方使用它们。我们谈到了使用它们的主要原因,其中最重要的是代码重用和实现隐藏。
我们看到函数对象就像一个接受可选输入并产生输出的盒子。我们可以以许多不同的方式向函数提供输入值,使用位置参数和关键字参数,并对两种类型都使用变量语法。
现在你应该知道如何编写一个函数,对它进行文档化,将它导入到你的代码中,并调用它。
在下一章中,我们将看到如何处理文件以及如何以多种不同的方式和格式持久化数据。
第五章:文件和数据持久性
“持久性是我们称之为生活的冒险的关键。” - Torsten Alexander Lange
在之前的章节中,我们已经探索了 Python 的几个不同方面。由于示例具有教学目的,我们在简单的 Python shell 中运行它们,或者以 Python 模块的形式运行它们。它们运行,可能在控制台上打印一些内容,然后终止,留下了它们短暂存在的痕迹。
然而,现实世界的应用通常大不相同。它们当然仍然在内存中运行,但它们与网络、磁盘和数据库进行交互。它们还使用适合情况的格式与其他应用程序和设备交换信息。
在本章中,我们将开始逐渐接近现实世界,探索以下内容:
-
文件和目录
-
压缩
-
网络和流量
-
JSON 数据交换格式
-
使用 pickle 和 shelve 进行数据持久化,来自标准库
-
使用 SQLAlchemy 进行数据持久化
和往常一样,我会努力平衡广度和深度,这样在本章结束时,你将对基本原理有扎实的理解,并且知道如何在网络上获取更多信息。
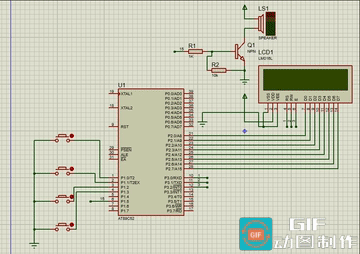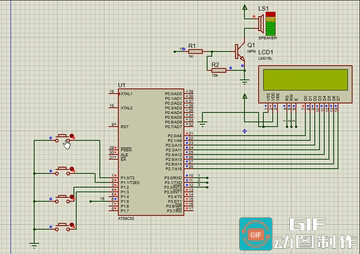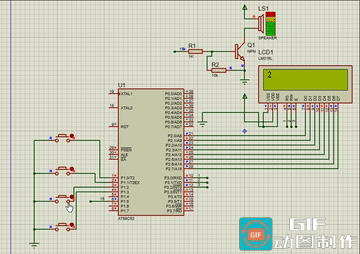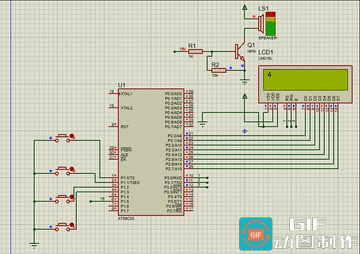
处理文件和目录
在处理文件和目录时,Python 提供了许多有用的工具。特别是在以下示例中,我们将利用os和shutil模块。因为我们将在磁盘上读写数据,我将使用一个名为fear.txt的文件,其中包含了《恐惧》(Fear)的节选,作者是 Thich Nhat Hanh,作为我们一些示例的实验对象。
打开文件
在 Python 中打开文件非常简单和直观。实际上,我们只需要使用open函数。让我们看一个快速的例子:
# files/open_try.py
fh = open('fear.txt', 'rt') # r: read, t: textfor line in fh.readlines():print(line.strip()) # remove whitespace and printfh.close()
前面的代码非常简单。我们调用open,传递文件名,并告诉open我们要以文本模式读取它。在文件名之前没有路径信息;因此,open会假定文件在运行脚本的同一文件夹中。这意味着如果我们从files文件夹外部运行此脚本,那么fear.txt将找不到。
一旦文件被打开,我们就会得到一个文件对象fh,我们可以用它来处理文件的内容。在这种情况下,我们使用readlines()方法来迭代文件中的所有行,并打印它们。我们对每一行调用strip()来去除内容周围的任何额外空格,包括末尾的行终止字符,因为print会为我们添加一个。这是一个快速而粗糙的解决方案,在这个例子中有效,但是如果文件的内容包含需要保留的有意义的空格,你将需要在清理数据时更加小心。在脚本的结尾,我们刷新并关闭流。
关闭文件非常重要,因为我们不希望冒着释放文件句柄的风险。因此,我们需要采取一些预防措施,并将之前的逻辑包装在try/finally块中。这样做的效果是,无论我们尝试打开和读取文件时可能发生什么错误,我们都可以放心close()会被调用:
# files/open_try.py
try:fh = open('fear.txt', 'rt')for line in fh.readlines():print(line.strip())
finally:fh.close()
逻辑完全相同,但现在也是安全的。
如果你现在不理解try/finally,不要担心。我们将在后面的章节中探讨如何处理异常。现在,只需说将代码放在try块的主体内会在该代码周围添加一个机制,允许我们检测错误(称为异常)并决定发生错误时该怎么办。在这种情况下,如果发生错误,我们实际上并不做任何事情,但通过在finally块中关闭文件,我们确保该行被执行,无论是否发生了任何错误。
我们可以这样简化前面的例子:
# files/open_try.py
try:fh = open('fear.txt') # rt is defaultfor line in fh: # we can iterate directly on fhprint(line.strip())
finally:fh.close()
正如你所看到的,rt是打开文件的默认模式,因此我们不需要指定它。此外,我们可以直接在fh上进行迭代,而不需要显式调用readlines()。Python 非常好,给了我们简化代码的快捷方式,使我们的代码更短、更容易阅读。
所有前面的例子都在控制台上打印文件(查看源代码以阅读整个内容):
An excerpt from Fear - By Thich Nhat HanhThe Present Is Free from FearWhen we are not fully present, we are not really living. We’re not really there, either for our loved ones or for ourselves. If we’re not there, then where are we? We are running, running, running, even during our sleep. We run because we’re trying to escape from our fear.
...
使用上下文管理器打开文件
让我们承认吧:不得不用try/finally块来传播我们的代码并不是最好的选择。像往常一样,Python 给了我们一个更好的方式以安全的方式打开文件:使用上下文管理器。让我们先看看代码:
# files/open_with.py
with open('fear.txt') as fh:for line in fh:print(line.strip())
前面的例子等同于之前的例子,但读起来更好。with语句支持由上下文管理器定义的运行时上下文的概念。这是使用一对方法__enter__和__exit__来实现的,允许用户定义的类定义在语句体执行之前进入的运行时上下文,并在语句结束时退出。open函数在由上下文管理器调用时能够生成一个文件对象,但它真正的美妙之处在于fh.close()会自动为我们调用,即使出现错误也是如此。
上下文管理器在几种不同的场景中使用,比如线程同步、文件或其他对象的关闭,以及网络和数据库连接的管理。您可以在contextlib文档页面中找到有关它们的信息(docs.python.org/3.7/library/contextlib.html)。
读写文件
现在我们知道如何打开文件了,让我们看看我们有几种不同的方式来读取和写入文件:
# files/print_file.py
with open('print_example.txt', 'w') as fw:print('Hey I am printing into a file!!!', file=fw)
第一种方法使用了print函数,你在前几章中已经见过很多次。在获取文件对象之后,这次指定我们打算写入它(“w”),我们可以告诉print调用将其效果定向到文件,而不是默认的sys.stdout,当在控制台上执行时,它会映射到它。
前面的代码的效果是:如果print_example.txt文件不存在,则创建它,或者如果存在,则将其截断,并将行Hey I am printing into a file!!!写入其中。
这很简单易懂,但不是我们通常写文件时所采用的方式。让我们看一个更常见的方法:
# files/read_write.py
with open('fear.txt') as f:lines = [line.rstrip() for line in f]with open('fear_copy.txt', 'w') as fw:fw.write('\n'.join(lines))
在前面的例子中,我们首先打开fear.txt并将其内容逐行收集到一个列表中。请注意,这次我调用了一个更精确的方法rstrip(),作为一个例子,以确保我只去掉每行右侧的空白。
在代码片段的第二部分中,我们创建了一个新文件fear_copy.txt,并将原始文件中的所有行写入其中,用换行符\n连接起来。Python 很慷慨,并且默认使用通用换行符,这意味着即使原始文件的换行符与\n不同,它也会在返回行之前自动转换为\n。当然,这种行为是可以自定义的,但通常它正是你想要的。说到换行符,你能想到副本中可能缺少的换行符吗?
以二进制模式读写
请注意,通过在选项中传递t来打开文件(或者省略它,因为它是默认值),我们是以文本模式打开文件。这意味着文件的内容被视为文本并进行解释。如果您希望向文件写入字节,可以以二进制模式打开它。当您处理不仅包含原始文本的文件时,这是一个常见的要求,比如图像、音频/视频和一般的任何其他专有格式。
要处理二进制模式的文件,只需在打开文件时指定b标志,就像下面的例子一样:
# files/read_write_bin.py
with open('example.bin', 'wb') as fw:fw.write(b'This is binary data...')with open('example.bin', 'rb') as f:print(f.read()) # prints: b'This is binary data...'
在这个例子中,我仍然使用文本作为二进制数据,但它可以是任何你想要的东西。你可以看到它被视为二进制数据的事实,因为在输出中你得到了b'This ...'前缀。
防止覆盖现有文件
Python 让我们有能力打开文件进行写入。通过使用w标志,我们打开一个文件并截断其内容。这意味着文件被覆盖为一个空文件,并且原始内容丢失。如果您希望仅在文件不存在时打开文件进行写入,可以改用x标志,如下例所示:
# files/write_not_exists.py
with open('write_x.txt', 'x') as fw:fw.write('Writing line 1') # this succeedswith open('write_x.txt', 'x') as fw:fw.write('Writing line 2') # this fails
如果您运行前面的片段,您将在您的目录中找到一个名为write_x.txt的文件,其中只包含一行文本。实际上,片段的第二部分未能执行。这是我在控制台上得到的输出:
$ python write_not_exists.py
Traceback (most recent call last):File "write_not_exists.py", line 6, in <module>with open('write_x.txt', 'x') as fw:
FileExistsError: [Errno 17] File exists: 'write_x.txt'
检查文件和目录是否存在
如果您想确保文件或目录存在(或不存在),则需要使用os.path模块。让我们看一个小例子:
# files/existence.py
import osfilename = 'fear.txt'
path = os.path.dirname(os.path.abspath(filename))print(os.path.isfile(filename)) # True
print(os.path.isdir(path)) # True
print(path) # /Users/fab/srv/lpp/ch5/files
前面的片段非常有趣。在使用相对引用声明文件名之后(因为缺少路径信息),我们使用abspath来计算文件的完整绝对路径。然后,我们通过调用dirname来获取路径信息(删除末尾的文件名)。结果如您所见,打印在最后一行。还要注意我们如何通过调用isfile和isdir来检查文件和目录的存在。在os.path模块中,您可以找到处理路径名所需的所有函数。
如果您需要以不同的方式处理路径,可以查看pathlib。虽然os.path使用字符串,但pathlib提供了表示适合不同操作系统的文件系统路径的类。这超出了本章的范围,但如果您感兴趣,请查看 PEP428(www.python.org/dev/peps/pep-0428/)及其在标准库中的页面。
操作文件和目录
让我们看一些关于如何操作文件和目录的快速示例。第一个示例操作内容:
# files/manipulation.py
from collections import Counter
from string import ascii_letterschars = ascii_letters + ' 'def sanitize(s, chars):return ''.join(c for c in s if c in chars)def reverse(s):return s[::-1]with open('fear.txt') as stream:lines = [line.rstrip() for line in stream]with open('raef.txt', 'w') as stream:stream.write('\n'.join(reverse(line) for line in lines))# now we can calculate some statistics
lines = [sanitize(line, chars) for line in lines]
whole = ' '.join(lines)
cnt = Counter(whole.lower().split())
print(cnt.most_common(3))
前面的例子定义了两个函数:sanitize和reverse。它们是简单的函数,其目的是从字符串中删除任何不是字母或空格的内容,并分别生成字符串的反转副本。
我们打开fear.txt,并将其内容读入列表。然后我们创建一个新文件raef.txt,其中将包含原始文件的水平镜像版本。我们使用join在新行字符上写入lines的所有内容。也许更有趣的是最后的部分。首先,我们通过列表推导将lines重新分配为其经过清理的版本。然后我们将它们放在whole字符串中,最后将结果传递给Counter。请注意,我们拆分字符串并将其转换为小写。这样,每个单词都将被正确计数,而不管其大小写,而且由于split,我们不需要担心任何额外的空格。当我们打印出最常见的三个单词时,我们意识到真正的 Thich Nhat Hanh 的重点在于其他人,因为we是文本中最常见的单词:
$ python manipulation.py
[('we', 17), ('the', 13), ('were', 7)]
现在让我们看一个更加面向磁盘操作的操作示例,其中我们使用shutil模块:
# files/ops_create.py
import shutil
import osBASE_PATH = 'ops_example' # this will be our base path
os.mkdir(BASE_PATH)path_b = os.path.join(BASE_PATH, 'A', 'B')
path_c = os.path.join(BASE_PATH, 'A', 'C')
path_d = os.path.join(BASE_PATH, 'A', 'D')os.makedirs(path_b)
os.makedirs(path_c)for filename in ('ex1.txt', 'ex2.txt', 'ex3.txt'):with open(os.path.join(path_b, filename), 'w') as stream:stream.write(f'Some content here in {filename}\n')shutil.move(path_b, path_d)shutil.move(os.path.join(path_d, 'ex1.txt'),
os.path.join(path_d, 'ex1d.txt')
)
在前面的代码中,我们首先声明一个基本路径,该路径将安全地包含我们将要创建的所有文件和文件夹。然后我们使用makedirs创建两个目录:ops_example/A/B和ops_example/A/C。(您能想到使用map来创建这两个目录的方法吗?)。
我们使用os.path.join来连接目录名称,因为使用/会使代码专门在目录分隔符为/的平台上运行,但是在具有不同分隔符的平台上,代码将失败。让我们委托给join来确定哪个是适当的分隔符的任务。
在创建目录之后,在一个简单的for循环中,我们放入一些代码,创建目录B中的三个文件。然后,我们将文件夹B及其内容移动到另一个名称D,最后,我们将ex1.txt重命名为ex1d.txt。如果你打开那个文件,你会看到它仍然包含来自for循环的原始文本。在结果上调用tree会产生以下结果:
$ tree ops_example/
ops_example/
└── A├── C└── D├── ex1d.txt├── ex2.txt└── ex3.txt
操作路径名
让我们通过一个简单的例子来更多地探索os.path的能力:
# files/paths.py
import osfilename = 'fear.txt'
path = os.path.abspath(filename)print(path)
print(os.path.basename(path))
print(os.path.dirname(path))
print(os.path.splitext(path))
print(os.path.split(path))readme_path = os.path.join(os.path.dirname(path), '..', '..', 'README.rst')print(readme_path)
print(os.path.normpath(readme_path))
阅读结果可能是对这个简单例子的足够好的解释:
/Users/fab/srv/lpp/ch5/files/fear.txt # path
fear.txt # basename
/Users/fab/srv/lpp/ch5/files # dirname
('/Users/fab/srv/lpp/ch5/files/fear', '.txt') # splitext
('/Users/fab/srv/lpp/ch5/files', 'fear.txt') # split
/Users/fab/srv/lpp/ch5/files/../../README.rst # readme_path
/Users/fab/srv/lpp/README.rst # normalized
临时文件和目录
有时,在运行一些代码时,能够创建临时目录或文件是非常有用的。例如,在编写影响磁盘的测试时,你可以使用临时文件和目录来运行你的逻辑并断言它是正确的,并确保在测试运行结束时,测试文件夹中没有任何剩余物。让我们看看在 Python 中如何做到这一点:
# files/tmp.py
import os
from tempfile import NamedTemporaryFile, TemporaryDirectorywith TemporaryDirectory(dir='.') as td:print('Temp directory:', td)with NamedTemporaryFile(dir=td) as t:name = t.nameprint(os.path.abspath(name))
上面的例子非常简单:我们在当前目录(.)中创建一个临时目录,并在其中创建一个命名的临时文件。我们打印文件名,以及它的完整路径:
$ python tmp.py
Temp directory: ./tmpwa9bdwgo
/Users/fab/srv/lpp/ch5/files/tmpwa9bdwgo/tmp3d45hm46
运行这个脚本将每次产生不同的结果。毕竟,我们在这里创建的是一个临时的随机名称,对吧?
目录内容
使用 Python,你也可以检查目录的内容。我将向你展示两种方法:
# files/listing.py
import oswith os.scandir('.') as it:for entry in it:print(entry.name, entry.path,'File' if entry.is_file() else 'Folder')
这个片段使用os.scandir,在当前目录上调用。我们对结果进行迭代,每个结果都是os.DirEntry的一个实例,这是一个暴露有用属性和方法的好类。在代码中,我们访问了其中的一部分:name、path和is_file()。运行代码会产生以下结果(为了简洁起见,我省略了一些结果):
$ python listing.py
fixed_amount.py ./fixed_amount.py File
existence.py ./existence.py File
...
ops_example ./ops_example Folder
...
扫描目录树的更强大的方法是由os.walk提供的。让我们看一个例子:
# files/walking.py
import osfor root, dirs, files in os.walk('.'):print(os.path.abspath(root))if dirs:print('Directories:')for dir_ in dirs:print(dir_)print()if files:print('Files:')for filename in files:print(filename)print()
运行上面的片段将产生当前所有文件和目录的列表,并且对每个子目录都会执行相同的操作。
文件和目录压缩
在我们离开这一部分之前,让我给你举个例子,说明如何创建一个压缩文件。在本书的源代码中,我有两个例子:一个创建一个 ZIP 文件,而另一个创建一个tar.gz文件。Python 允许你以几种不同的方式和格式创建压缩文件。在这里,我将向你展示如何创建最常见的一种,ZIP:
# files/compression/zip.py
from zipfile import ZipFilewith ZipFile('example.zip', 'w') as zp:zp.write('content1.txt')zp.write('content2.txt')zp.write('subfolder/content3.txt')zp.write('subfolder/content4.txt')with ZipFile('example.zip') as zp:zp.extract('content1.txt', 'extract_zip')zp.extract('subfolder/content3.txt', 'extract_zip')
在上面的代码中,我们导入ZipFile,然后在上下文管理器中,我们向其中写入四个虚拟上下文文件(其中两个在子文件夹中,以显示 ZIP 保留了完整路径)。之后,作为一个例子,我们打开压缩文件并从中提取一些文件到extract_zip目录中。如果你有兴趣了解更多关于数据压缩的知识,一定要查看标准库中的数据压缩和归档部分(docs.python.org/3.7/library/archiving.html),在那里你将能够学习到关于这个主题的所有知识。
数据交换格式
现代软件架构倾向于将应用程序分成几个组件。无论你是否采用面向服务的架构范式,或者将其推进到微服务领域,这些组件都必须交换数据。但即使你正在编写一个单体应用程序,其代码库包含在一个项目中,也有可能你必须与 API、其他程序交换数据,或者简单地处理网站前端和后端部分之间的数据流,这些部分很可能不会说相同的语言。
选择正确的格式来交换信息至关重要。特定于语言的格式的优势在于,语言本身很可能会为您提供所有工具,使序列化和反序列化变得轻而易举。然而,您将失去与使用不同版本的相同语言或完全不同语言编写的其他组件进行交流的能力。无论未来如何,只有在给定情况下这是唯一可能的选择时,才应选择特定于语言的格式。
一个更好的方法是选择一种与语言无关的格式,可以被所有(或至少大多数)语言使用。在我领导的团队中,我们有来自英格兰、波兰、南非、西班牙、希腊、印度、意大利等国家的人。我们都说英语,因此无论我们的母语是什么,我们都可以彼此理解(嗯…大多数情况下!)。
在软件世界中,一些流行的格式近年来已成为事实上的标准。最著名的可能是 XML、YAML 和 JSON。Python 标准库包括xml和json模块,而在 PyPI(docs.python.org/3.7/library/archiving.html)上,您可以找到一些不同的包来处理 YAML。
在 Python 环境中,JSON 可能是最常用的。它胜过其他两种格式,因为它是标准库的一部分,而且它很简单。如果您曾经使用过 XML,您就知道它可能是多么可怕。
使用 JSON
JSON是JavaScript 对象表示法的缩写,它是 JavaScript 语言的一个子集。它已经存在了将近二十年,因此它是众所周知的,并且基本上被所有语言广泛采用,尽管它实际上是与语言无关的。您可以在其网站上阅读有关它的所有信息(www.json.org/),但我现在将为您快速介绍一下。
JSON 基于两种结构:名称/值对的集合和值的有序列表。您会立即意识到这两个对象分别映射到 Python 中的字典和列表数据类型。作为数据类型,它提供字符串、数字、对象和值,例如 true、false 和 null。让我们看一个快速的示例来开始:
# json_examples/json_basic.py
import sys
import jsondata = {'big_number': 2 ** 3141,'max_float': sys.float_info.max,'a_list': [2, 3, 5, 7],
}json_data = json.dumps(data)
data_out = json.loads(json_data)
assert data == data_out # json and back, data matches
我们首先导入sys和json模块。然后我们创建一个包含一些数字和一个列表的简单字典。我想测试使用非常大的数字进行序列化和反序列化,包括int和float,所以我放入了2³¹⁴¹和我的系统可以处理的最大浮点数。
我们使用json.dumps进行序列化,它将数据转换为 JSON 格式的字符串。然后将该数据输入到json.loads中,它执行相反的操作:从 JSON 格式的字符串中,将数据重构为 Python。在最后一行,我们确保原始数据和通过 JSON 进行序列化/反序列化的结果匹配。
让我们在下一个示例中看看,如果我们打印 JSON 数据会是什么样子:
# json_examples/json_basic.py
import jsoninfo = {'full_name': 'Sherlock Holmes','address': {'street': '221B Baker St','zip': 'NW1 6XE','city': 'London','country': 'UK',}
}print(json.dumps(info, indent=2, sort_keys=True))
在这个示例中,我们创建了一个包含福尔摩斯的数据的字典。如果您和我一样是福尔摩斯的粉丝,并且在伦敦,您会在那个地址找到他的博物馆(我建议您去参观,它虽小但非常好)。
请注意我们如何调用json.dumps。我们已经告诉它用两个空格缩进,并按字母顺序排序键。结果是这样的:
$ python json_basic.py
{"address": {"city": "London","country": "UK","street": "221B Baker St","zip": "NW1 6XE"},"full_name": "Sherlock Holmes"
}
与 Python 的相似性非常大。唯一的区别是,如果您在字典的最后一个元素上放置逗号,就像我在 Python 中所做的那样(因为这是习惯的做法),JSON 会抱怨。
让我给你展示一些有趣的东西:
# json_examples/json_tuple.py
import jsondata_in = {'a_tuple': (1, 2, 3, 4, 5),
}json_data = json.dumps(data_in)
print(json_data) # {"a_tuple": [1, 2, 3, 4, 5]}
data_out = json.loads(json_data)
print(data_out) # {'a_tuple': [1, 2, 3, 4, 5]}
在这个例子中,我们放了一个元组,而不是一个列表。有趣的是,从概念上讲,元组也是一个有序的项目列表。它没有列表的灵活性,但从 JSON 的角度来看,它仍然被认为是相同的。因此,正如你可以从第一个print中看到的那样,在 JSON 中,元组被转换为列表。因此,丢失了它是元组的信息,当反序列化发生时,在data_out中,a_tuple实际上是一个列表。在处理数据时,重要的是要记住这一点,因为经历一个涉及只包括你可以使用的数据结构子集的格式转换过程意味着会有信息丢失。在这种情况下,我们丢失了类型(元组与列表)的信息。
这实际上是一个常见的问题。例如,你不能将所有的 Python 对象序列化为 JSON,因为不清楚 JSON 是否应该还原它(或者如何还原)。想想datetime,例如。该类的实例是 JSON 不允许序列化的 Python 对象。如果我们将其转换为字符串,比如2018-03-04T12:00:30Z,这是带有时间和时区信息的日期的 ISO 8601 表示,当进行反序列化时,JSON 应该怎么做?它应该说这实际上可以反序列化为一个 datetime 对象,所以最好这样做,还是应该简单地将其视为字符串并保持原样?那些可以以多种方式解释的数据类型呢?
答案是,在处理数据交换时,我们经常需要在将对象序列化为 JSON 之前将其转换为更简单的格式。这样,当我们对它们进行反序列化时,我们将知道如何正确地重构它们。
然而,在某些情况下,主要是为了内部使用,能够序列化自定义对象是有用的,因此,只是为了好玩,我将向您展示两个例子:复数(因为我喜欢数学)和datetime对象。
使用 JSON 进行自定义编码/解码
在 JSON 世界中,我们可以将编码/解码等术语视为序列化/反序列化的同义词。它们基本上都意味着转换为 JSON,然后再从 JSON 转换回来。在下面的例子中,我将向您展示如何对复数进行编码:
# json_examples/json_cplx.py
import jsonclass ComplexEncoder(json.JSONEncoder):def default(self, obj):if isinstance(obj, complex):return {'_meta': '_complex','num': [obj.real, obj.imag],}return json.JSONEncoder.default(self, obj)data = {'an_int': 42,'a_float': 3.14159265,'a_complex': 3 + 4j,
}json_data = json.dumps(data, cls=ComplexEncoder)
print(json_data)def object_hook(obj):try:if obj['_meta'] == '_complex':return complex(*obj['num'])except (KeyError, TypeError):return objdata_out = json.loads(json_data, object_hook=object_hook)
print(data_out)
首先,我们定义一个ComplexEncoder类,它需要实现default方法。这个方法被传递给所有需要被序列化的对象,一个接一个地,在obj变量中。在某个时候,obj将是我们的复数3+4j。当这种情况发生时,我们返回一个带有一些自定义元信息的字典,以及一个包含实部和虚部的列表。这就是我们需要做的,以避免丢失复数的信息。
然后我们调用json.dumps,但这次我们使用cls参数来指定我们的自定义编码器。结果被打印出来:
{"an_int": 42, "a_float": 3.14159265, "a_complex": {"_meta": "_complex", "num": [3.0, 4.0]}}
一半的工作已经完成。对于反序列化部分,我们本可以编写另一个类,它将继承自JSONDecoder,但是,只是为了好玩,我使用了一种更简单的技术,并使用了一个小函数:object_hook。
在object_hook的主体内,我们找到另一个try块。重要的部分是try块本身内的两行。该函数接收一个对象(注意,只有当obj是一个字典时才调用该函数),如果元数据与我们的复数约定匹配,我们将实部和虚部传递给complex函数。try/except块只是为了防止格式不正确的 JSON 破坏程序(如果发生这种情况,我们只需返回对象本身)。
最后一个打印返回:
{'an_int': 42, 'a_float': 3.14159265, 'a_complex': (3+4j)}
你可以看到a_complex已经被正确反序列化。
现在让我们看一个稍微更复杂(没有刻意的意思)的例子:处理datetime对象。我将把代码分成两个块,序列化部分和反序列化部分:
# json_examples/json_datetime.py
import json
from datetime import datetime, timedelta, timezonenow = datetime.now()
now_tz = datetime.now(tz=timezone(timedelta(hours=1)))class DatetimeEncoder(json.JSONEncoder):def default(self, obj):if isinstance(obj, datetime):try:off = obj.utcoffset().secondsexcept AttributeError:off = Nonereturn {'_meta': '_datetime','data': obj.timetuple()[:6] + (obj.microsecond, ),'utcoffset': off,}return json.JSONEncoder.default(self, obj)data = {'an_int': 42,'a_float': 3.14159265,'a_datetime': now,'a_datetime_tz': now_tz,
}json_data = json.dumps(data, cls=DatetimeEncoder)
print(json_data)
这个例子略微复杂的原因在于 Python 中的datetime对象可以是时区感知的,也可以不是;因此,我们需要更加小心。流程基本上与之前相同,只是处理的是不同的数据类型。我们首先获取当前的日期和时间信息,分别使用不带时区信息的(now)和带时区信息的(now_tz),只是为了确保我们的脚本能够正常工作。然后我们像之前一样定义自定义编码器,并再次实现default方法。在该方法中的重要部分是如何获取时间偏移(off)信息(以秒为单位),以及如何构造返回数据的字典。这次,元数据表示它是datetime信息,然后我们将时间元组的前六个项目(年、月、日、小时、分钟和秒)以及微秒保存在data键中,然后是偏移。您能看出data的值是元组的连接吗?如果您能,干得好!
当我们有了自定义的编码器后,我们继续创建一些数据,然后进行序列化。print语句返回(在我进行了一些美化之后):
{"a_datetime": {"_meta": "_datetime","data": [2018, 3, 18, 17, 57, 27, 438792],"utcoffset": null},"a_datetime_tz": {"_meta": "_datetime","data": [2018, 3, 18, 18, 57, 27, 438810],"utcoffset": 3600},"a_float": 3.14159265,"an_int": 42
}
有趣的是,我们发现None被翻译为null,这是它的 JavaScript 等效项。此外,我们可以看到我们的数据似乎已经被正确编码。让我们继续脚本的第二部分:
# json_examples/json_datetime.py
def object_hook(obj):try:if obj['_meta'] == '_datetime':if obj['utcoffset'] is None:tz = Noneelse:tz = timezone(timedelta(seconds=obj['utcoffset']))return datetime(*obj['data'], tzinfo=tz)except (KeyError, TypeError):return objdata_out = json.loads(json_data, object_hook=object_hook)
再次,我们首先验证元数据告诉我们这是一个datetime,然后我们继续获取时区信息。一旦我们有了时区信息,我们将 7 元组(使用*来解包其值)和时区信息传递给datetime调用,得到我们的原始对象。让我们通过打印data_out来验证一下:
{'a_datetime': datetime.datetime(2018, 3, 18, 18, 1, 46, 54693),'a_datetime_tz': datetime.datetime(2018, 3, 18, 19, 1, 46, 54711,tzinfo=datetime.timezone(datetime.timedelta(seconds=3600))),'a_float': 3.14159265,'an_int': 42
}
正如您所看到的,我们正确地得到了所有的东西。作为一个练习,我想挑战您编写相同逻辑,但针对一个date对象,这应该更简单。
在我们继续下一个主题之前,我想提个小小的警告。也许这有违直觉,但是处理datetime对象可能是最棘手的事情之一,所以,尽管我非常确定这段代码正在按照预期的方式运行,我还是想强调我只进行了非常轻微的测试。所以,如果您打算使用它,请务必进行彻底的测试。测试不同的时区,测试夏令时的开启和关闭,测试纪元前的日期等等。您可能会发现,本节中的代码需要一些修改才能适应您的情况。
让我们现在转到下一个主题,IO。
IO、流和请求
IO代表输入/输出,它广泛地指的是计算机与外部世界之间的通信。有几种不同类型的 IO,这章节的范围之外,无法解释所有,但我仍然想给您提供一些例子。
使用内存流
第一个将向您展示io.StringIO类,这是一个用于文本 IO 的内存流。而第二个则会逃离我们计算机的局限,向您展示如何执行 HTTP 请求。让我们看看第一个例子:
# io_examples/string_io.py
import iostream = io.StringIO()
stream.write('Learning Python Programming.\n')
print('Become a Python ninja!', file=stream)contents = stream.getvalue()
print(contents)stream.close()
在前面的代码片段中,我们从标准库中导入了io模块。这是一个非常有趣的模块,其中包含许多与流和 IO 相关的工具。其中之一是StringIO,它是一个内存缓冲区,我们将在其中使用两种不同的方法写入两个句子,就像我们在本章的第一个例子中处理文件一样。我们既可以调用StringIO.write,也可以使用print,并告诉它将数据传送到我们的流中。
通过调用getvalue,我们可以获取流的内容(并打印它),最后我们关闭它。调用close会立即丢弃文本缓冲区。
有一种更加优雅的方法来编写前面的代码(在您查看之前,您能猜到吗?):
# io_examples/string_io.py
with io.StringIO() as stream:stream.write('Learning Python Programming.\n')print('Become a Python ninja!', file=stream)contents = stream.getvalue()print(contents)
是的,这又是一个上下文管理器。就像open一样,io.StringIO在上下文管理器块内工作得很好。注意与open的相似之处:在这种情况下,我们也不需要手动关闭流。
内存对象在许多情况下都很有用。内存比磁盘快得多,对于少量数据来说,可能是完美的选择。
运行脚本时,输出为:
$ python string_io.py
Learning Python Programming.
Become a Python ninja!
进行 HTTP 请求
现在让我们探索一些关于 HTTP 请求的例子。我将使用requests库进行这些示例,你可以使用pip进行安装。我们将对httpbin.org API 执行 HTTP 请求,有趣的是,这个 API 是由 Kenneth Reitz 开发的,他是requests库的创建者。这个库在全世界范围内被广泛采用:
import requestsurls = {'get': 'https://httpbin.org/get?title=learn+python+programming','headers': 'https://httpbin.org/headers','ip': 'https://httpbin.org/ip','now': 'https://now.httpbin.org/','user-agent': 'https://httpbin.org/user-agent','UUID': 'https://httpbin.org/uuid',
}def get_content(title, url):resp = requests.get(url)print(f'Response for {title}')print(resp.json())for title, url in urls.items():get_content(title, url)print('-' * 40)
前面的片段应该很容易理解。我声明了一个 URL 字典,我想要执行“请求”。我已经将执行请求的代码封装到一个小函数中:get_content。正如你所看到的,我们非常简单地执行了一个 GET 请求(使用requests.get),并打印了响应的标题和 JSON 解码版本的正文。让我多说一句关于最后一点。
当我们对网站或 API 执行请求时,我们会得到一个响应对象,这个对象非常简单,就是服务器返回的内容。所有来自httpbin.org的响应正文都是 JSON 编码的,所以我们不需要通过resp.text获取正文然后手动解码,而是通过响应对象上的json方法将两者结合起来。requests包变得如此广泛被采用有很多原因,其中一个绝对是它的易用性。
现在,当你在应用程序中执行请求时,你会希望有一个更加健壮的方法来处理错误等,但在本章中,一个简单的例子就足够了。
回到我们的代码,最后,我们运行一个for循环并获取所有的 URL。当你运行它时,你会在控制台上看到每个调用的结果,就像这样(为了简洁起见,进行了美化和修剪):
$ python reqs.py
Response for get
{"args": {"title": "learn python programming"},"headers": {"Accept": "*/*","Accept-Encoding": "gzip, deflate","Connection": "close","Host": "httpbin.org","User-Agent": "python-requests/2.19.0"},"origin": "82.47.175.158","url": "https://httpbin.org/get?title=learn+python+programming"
}
... rest of the output omitted ...
请注意,你可能会在版本号和 IP 方面得到略有不同的输出,这是正常的。现在,GET 只是 HTTP 动词中的一个,它绝对是最常用的。第二个是无处不在的 POST,当你需要向服务器发送数据时,就会发起这种类型的请求。每当你在网上提交表单时,你基本上就是在发起一个 POST 请求。所以,让我们尝试以编程方式进行一个:
# io_examples/reqs_post.py
import requestsurl = 'https://httpbin.org/post'
data = dict(title='Learn Python Programming')resp = requests.post(url, data=data)
print('Response for POST')
print(resp.json())
前面的代码与我们之前看到的代码非常相似,只是这一次我们不调用get,而是调用post,因为我们想要发送一些数据,我们在调用中指定了这一点。requests库提供的远不止这些,它因其提供的美丽 API 而受到社区的赞扬。这是一个我鼓励你去了解和探索的项目,因为你最终会一直使用它。
运行上一个脚本(并对输出进行一些美化处理)得到了以下结果:
$ python reqs_post.py
Response for POST
{ 'args': {},'data': '','files': {},'form': {'title': 'Learn Python Programming'},'headers': { 'Accept': '*/*','Accept-Encoding': 'gzip, deflate','Connection': 'close','Content-Length': '30','Content-Type': 'application/x-www-form-urlencoded','Host': 'httpbin.org','User-Agent': 'python-requests/2.7.0 CPython/3.7.0b2 ''Darwin/17.4.0'},'json': None,
'origin': '82.45.123.178','url': 'https://httpbin.org/post'}
请注意,现在标头已经不同了,我们在响应正文的form键值对中找到了我们发送的数据。
我希望这些简短的例子足以让你开始,特别是对于请求部分。网络每天都在变化,所以值得学习基础知识,然后不时地进行复习。
现在让我们继续讨论本章的最后一个主题:以不同格式将数据持久化到磁盘上。
将数据持久化到磁盘
在本章的最后一节中,我们将探讨如何以三种不同的格式将数据持久化到磁盘上。我们将探索pickle、shelve,以及一个涉及使用 SQLAlchemy 访问数据库的简短示例,SQLAlchemy 是 Python 生态系统中最广泛采用的 ORM 库。
使用 pickle 对数据进行序列化
Python 标准库中的pickle模块提供了将 Python 对象转换为字节流以及反之的工具。尽管pickle和json公开的 API 存在部分重叠,但两者是完全不同的。正如我们在本章中之前看到的,JSON 是一种文本格式,人类可读,与语言无关,并且仅支持 Python 数据类型的受限子集。另一方面,pickle模块不是人类可读的,转换为字节,是特定于 Python 的,并且由于 Python 的出色内省能力,它支持大量的数据类型。
尽管存在这些差异,但当您考虑使用其中一个时,您应该知道最重要的问题是pickle存在的安全威胁。从不受信任的来源unpickling错误或恶意数据可能非常危险,因此如果您决定在应用程序中使用它,您需要格外小心。
也就是说,让我们通过一个简单的例子来看看它的运作方式:
# persistence/pickler.py
import pickle
from dataclasses import dataclass@dataclass
class Person:first_name: strlast_name: strid: intdef greet(self):print(f'Hi, I am {self.first_name} {self.last_name}'f' and my ID is {self.id}')people = [Person('Obi-Wan', 'Kenobi', 123),Person('Anakin', 'Skywalker', 456),
]# save data in binary format to a file
with open('data.pickle', 'wb') as stream:pickle.dump(people, stream)# load data from a file
with open('data.pickle', 'rb') as stream:peeps = pickle.load(stream)for person in peeps:person.greet()
在前面的例子中,我们使用dataclass装饰器创建了一个Person类(我们将在后面的章节中介绍如何做到这一点)。我写这个数据类的例子的唯一原因是向您展示pickle如何毫不费力地处理它,而无需我们为更简单的数据类型做任何事情。
该类有三个属性:first_name,last_name和id。它还公开了一个greet方法,它只是打印一个带有数据的问候消息。
我们创建了一个实例列表,然后将其保存到文件中。为此,我们使用pickle.dump,将要pickled的内容和要写入的流传递给它。就在那之后,我们从同一文件中读取,并通过使用pickle.load将整个流内容转换回 Python。为了确保对象已正确转换,我们在两个对象上都调用了greet方法。结果如下:
$ python pickler.py
Hi, I am Obi-Wan Kenobi and my ID is 123
Hi, I am Anakin Skywalker and my ID is 456
pickle模块还允许您通过dumps和loads函数(注意两个名称末尾的s)将对象转换为(和从)字节对象。在日常应用中,当我们需要持久保存不应与另一个应用程序交换的 Python 数据时,通常会使用pickle。我最近遇到的一个例子是flask插件中的会话管理,它在将会话对象发送到Redis之前对其进行pickle。但实际上,您不太可能经常使用这个库。
另一个可能使用得更少但在资源短缺时非常有用的工具是shelve。
使用shelve保存数据
shelf是一种持久的类似字典的对象。它的美妙之处在于,您保存到shelf中的值可以是您可以pickle的任何对象,因此您不像使用数据库时那样受限。尽管有趣且有用,但在实践中shelve模块很少使用。为了完整起见,让我们快速看一下它的工作原理:
# persistence/shelf.py
import shelveclass Person:def __init__(self, name, id):self.name = nameself.id = idwith shelve.open('shelf1.shelve') as db:db['obi1'] = Person('Obi-Wan', 123)db['ani'] = Person('Anakin', 456)db['a_list'] = [2, 3, 5]db['delete_me'] = 'we will have to delete this one...'print(list(db.keys())) # ['ani', 'a_list', 'delete_me', 'obi1']del db['delete_me'] # gone!print(list(db.keys())) # ['ani', 'a_list', 'obi1']print('delete_me' in db) # Falseprint('ani' in db) # Truea_list = db['a_list']a_list.append(7)db['a_list'] = a_listprint(db['a_list']) # [2, 3, 5, 7]
除了围绕它的布线和样板之外,前面的例子类似于使用字典进行练习。我们创建一个简单的Person类,然后在上下文管理器中打开一个shelve文件。如您所见,我们使用字典语法存储四个对象:两个Person实例,一个列表和一个字符串。如果我们打印keys,我们会得到一个包含我们使用的四个键的列表。打印完后,我们从shelf中删除(恰当命名的)delete_me键/值对。再次打印keys会显示删除成功删除。然后我们测试了一对键的成员资格,最后,我们将数字7附加到a_list。请注意,我们必须从shelf中提取列表,修改它,然后再次保存它。
如果不希望出现这种行为,我们可以采取一些措施:
# persistence/shelf.py
with shelve.open('shelf2.shelve', writeback=True) as db:db['a_list'] = [11, 13, 17]db['a_list'].append(19) # in-place append!print(db['a_list']) # [11, 13, 17, 19]
通过以writeback=True打开架子,我们启用了writeback功能,这使我们可以简单地将a_list追加到其中,就好像它实际上是常规字典中的一个值。这个功能默认情况下不激活的原因是,它会以内存消耗和更慢的架子关闭为代价。
现在我们已经向与数据持久性相关的标准库模块致敬,让我们来看看 Python 生态系统中最广泛采用的 ORM:SQLAlchemy。
将数据保存到数据库
对于这个例子,我们将使用内存数据库,这将使事情对我们来说更简单。在书的源代码中,我留下了一些注释,以向您展示如何生成一个 SQLite 文件,所以我希望您也会探索这个选项。
您可以在sqlitebrowser.org找到一个免费的 SQLite 数据库浏览器。如果您对此不满意,您将能够找到各种工具,有些免费,有些不免费,可以用来访问和操作数据库文件。
在我们深入代码之前,让我简要介绍一下关系数据库的概念。
关系数据库是一种允许您按照 1969 年 Edgar F. Codd 发明的关系模型保存数据的数据库。在这个模型中,数据存储在一个或多个表中。每个表都有行(也称为记录或元组),每个行代表表中的一个条目。表还有列(也称为属性),每个列代表记录的一个属性。每个记录通过一个唯一键来标识,更常见的是主键,它是表中一个或多个列的联合。举个例子:想象一个名为Users的表,具有列id、username、password、name和surname。这样的表非常适合包含我们系统的用户。每一行代表一个不同的用户。例如,具有值3、gianchub、my_wonderful_pwd、Fabrizio和Romano的行将代表我在系统中的用户。
这个模型被称为关系,是因为您可以在表之间建立关系。例如,如果您向我们虚构的数据库添加一个名为PhoneNumbers的表,您可以向其中插入电话号码,然后通过关系建立哪个电话号码属于哪个用户。
为了查询关系数据库,我们需要一种特殊的语言。主要标准称为SQL,代表结构化查询语言。它源于一种称为关系代数的东西,这是一组用于模拟按照关系模型存储的数据并对其进行查询的非常好的代数。您通常可以执行的最常见操作包括对行或列进行过滤,连接表,根据某些标准对结果进行聚合等。举个英语的例子,我们想要查询我们想象中的数据库:获取所有用户名以“m”开头且最多有一个电话号码的用户(用户名、名字、姓氏)。在这个查询中,我们要求获取User表中的一部分列。我们通过用户名以字母m开头进行过滤,并且进一步筛选出最多有一个电话号码的用户。
在我还是帕多瓦的学生时,我花了整个学期学习关系代数语义和标准 SQL(还有其他东西)。如果不是我在考试当天遇到了一次重大的自行车事故,我会说这是我准备过的最有趣的考试之一。
现在,每个数据库都有自己的 SQL风味。它们都在某种程度上遵守标准,但没有一个完全遵守,并且它们在某些方面都不同。这在现代软件开发中是一个问题。如果我们的应用程序包含 SQL 代码,那么如果我们决定使用不同的数据库引擎,或者可能是同一引擎的不同版本,很可能我们会发现我们的 SQL 代码需要修改。
这可能会很痛苦,特别是因为 SQL 查询可能会变得非常复杂。为了稍微减轻这种痛苦,计算机科学家(感谢他们)已经创建了将特定语言的对象映射到关系数据库表的代码。毫不奇怪,这种工具的名称是对象关系映射(ORM)。
在现代应用程序开发中,通常会通过使用 ORM 来开始与数据库交互,如果你发现自己无法通过 ORM 执行需要执行的查询,那么你将会直接使用 SQL。这是在完全没有 SQL 和不使用 ORM 之间的一个很好的折衷,这最终意味着专门化与数据库交互的代码,具有前面提到的缺点。
在这一部分,我想展示一个利用 SQLAlchemy 的例子,这是最流行的 Python ORM。我们将定义两个模型(Person和Address),它们分别映射到一个表,然后我们将填充数据库并对其执行一些查询。
让我们从模型声明开始:
# persistence/alchemy_models.py
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import (Column, Integer, String, ForeignKey, create_engine)
from sqlalchemy.orm import relationship
一开始,我们导入一些函数和类型。然后我们需要做的第一件事是创建一个引擎。这个引擎告诉 SQLAlchemy 我们选择的数据库类型是什么:
# persistence/alchemy_models.py
engine = create_engine('sqlite:///:memory:')
Base = declarative_base()class Person(Base):__tablename__ = 'person'id = Column(Integer, primary_key=True)name = Column(String)age = Column(Integer)addresses = relationship('Address',back_populates='person',order_by='Address.email',cascade='all, delete-orphan')def __repr__(self):return f'{self.name}(id={self.id})'class Address(Base):__tablename__ = 'address'id = Column(Integer, primary_key=True)email = Column(String)person_id = Column(ForeignKey('person.id'))person = relationship('Person', back_populates='addresses')def __str__(self):return self.email__repr__ = __str__Base.metadata.create_all(engine)
然后每个模型都继承自Base表,在这个例子中,它由declarative_base()返回的默认值组成。我们定义了Person,它映射到一个名为person的表,并公开id、name和age属性。我们还声明了与Address模型的关系,通过声明访问addresses属性将获取与我们正在处理的特定Person实例相关的address表中的所有条目。cascade选项影响创建和删除的工作方式,但这是一个更高级的概念,所以我建议你现在先略过它,也许以后再进行更深入的调查。
我们声明的最后一件事是__repr__方法,它为我们提供了对象的官方字符串表示。这应该是一个可以用来完全重建对象的表示,但在这个例子中,我只是用它来提供一些输出。Python 将repr(obj)重定向到对obj.__repr__()的调用。
我们还声明了Address模型,其中包含电子邮件地址,以及它们所属的人的引用。你可以看到person_id和person属性都是用来设置Address和Person实例之间关系的。注意我如何在Address上声明了__str__方法,然后给它分配了一个别名,叫做__repr__。这意味着在Address对象上调用repr和str最终将导致调用__str__方法。这在 Python 中是一种常见的技术,所以我抓住机会在这里向你展示。
在最后一行,我们告诉引擎根据我们的模型在数据库中创建表。
对这段代码的更深入理解需要比我能承受的空间更多,所以我鼓励你阅读有关数据库管理系统(DBMS)、SQL、关系代数和 SQLAlchemy 的资料。
现在我们有了我们的模型,让我们用它们来保存一些数据!
让我们看看下面的例子:
# persistence/alchemy.py
from alchemy_models import Person, Address, engine
from sqlalchemy.orm import sessionmakerSession = sessionmaker(bind=engine)
session = Session()
首先我们创建session,这是我们用来管理数据库的对象。接下来,我们继续创建两个人:
anakin = Person(name='Anakin Skywalker', age=32)
obi1 = Person(name='Obi-Wan Kenobi', age=40)
然后我们向它们两个添加了电子邮件地址,使用了两种不同的技术。一种是将它们分配给一个列表,另一种是简单地将它们附加到列表中:
obi1.addresses = [Address(email='obi1@example.com'),Address(email='wanwan@example.com'),
]anakin.addresses.append(Address(email='ani@example.com'))
anakin.addresses.append(Address(email='evil.dart@example.com'))
anakin.addresses.append(Address(email='vader@example.com'))
我们还没有触及数据库。只有当我们使用会话对象时,它才会真正发生变化:
session.add(anakin)
session.add(obi1)
session.commit()
添加这两个Person实例就足以添加它们的地址(这要归功于级联效应)。调用commit实际上告诉 SQLAlchemy 提交事务并将数据保存到数据库中。事务是提供类似于沙盒的操作,但在数据库上下文中。只要事务尚未提交,我们就可以回滚对数据库所做的任何修改,从而恢复到事务开始之前的状态。SQLAlchemy 提供了更复杂和细粒度的处理事务的方式,你可以在其官方文档中学习,因为这是一个非常高级的主题。
我们现在使用like查询所有以Obi开头的人,这将连接到 SQL*中的LIKE运算符:
obi1 = session.query(Person).filter(Person.name.like('Obi%')
).first()
print(obi1, obi1.addresses)
我们获取该查询的第一个结果(我们知道我们只有 Obi-Wan),并打印它。然后我们通过使用他的名字进行精确匹配来获取anakin(只是为了向你展示另一种过滤方式):
anakin = session.query(Person).filter(Person.name=='Anakin Skywalker'
).first()
print(anakin, anakin.addresses)
然后我们捕获了 Anakin 的 ID,并从全局框架中删除了anakin对象:
anakin_id = anakin.id
del anakin
我们这样做是因为我想向你展示如何通过其 ID 获取对象。在我们这样做之前,我们编写了display_info函数,我们将使用它来显示数据库的全部内容(从地址开始获取,以演示如何通过使用 SQLAlchemy 中的关系属性来获取对象):
def display_info():# get all addresses firstaddresses = session.query(Address).all()# display resultsfor address in addresses:print(f'{address.person.name} <{address.email}>')# display how many objects we have in totalprint('people: {}, addresses: {}'.format(session.query(Person).count(),session.query(Address).count()))
display_info函数打印所有地址,以及相应人的姓名,并在最后产生关于数据库中对象数量的最终信息。我们调用该函数,然后获取并删除anakin(想想Darth Vader,你就不会因删除他而感到难过),然后再次显示信息,以验证他确实已经从数据库中消失了。
display_info()anakin = session.query(Person).get(anakin_id)
session.delete(anakin)
session.commit()display_info()
所有这些片段一起运行的输出如下(为了方便起见,我已将输出分成四个块,以反映实际产生该输出的四个代码块):
$ python alchemy.py
Obi-Wan Kenobi(id=2) [obi1@example.com, wanwan@example.com]
Anakin Skywalker(id=1) [ani@example.com, evil.dart@example.com, vader@example.com]Anakin Skywalker <ani@example.com>
Anakin Skywalker <evil.dart@example.com>
Anakin Skywalker <vader@example.com>
Obi-Wan Kenobi <obi1@example.com>
Obi-Wan Kenobi <wanwan@example.com>
people: 2, addresses: 5Obi-Wan Kenobi <obi1@example.com>
Obi-Wan Kenobi <wanwan@example.com>
people: 1, addresses: 2
从最后两个块中可以看出,删除anakin已经删除了一个Person对象,以及与之关联的三个地址。这是因为在删除anakin时发生了级联。
这结束了我们对数据持久性的简要介绍。这是一个广阔而且有时复杂的领域,我鼓励你尽可能多地探索学习理论。在涉及数据库系统时,缺乏知识或适当的理解可能会带来真正的困扰。
总结
在本章中,我们已经探讨了如何处理文件和目录。我们已经学会了如何打开文件进行读写,以及如何通过使用上下文管理器更优雅地进行操作。我们还探讨了目录:如何递归和非递归地列出它们的内容。我们还学习了路径名,这是访问文件和目录的入口。
然后我们简要地看到了如何创建 ZIP 存档,并提取其内容。该书的源代码还包含了一个不同压缩格式的示例:tar.gz。
我们谈到了数据交换格式,并深入探讨了 JSON。我们乐在其中为特定的 Python 数据类型编写自定义编码器和解码器。
然后我们探索了 IO,包括内存流和 HTTP 请求。
最后,我们看到了如何使用pickle、shelve和 SQLAlchemy ORM 库来持久化数据。
现在你应该对处理文件和数据持久性有了相当好的了解,我希望你会花时间自己更深入地探索这些主题。
从下一章开始,我们将开始探索数据结构和算法,首先从算法设计原则开始。