文章汇总
存在的问题
CoOp的一个关键问题:学习到的上下文不能推广到同一数据集中更广泛的未见类,这表明CoOp过拟合了训练期间观察到的基本类。
动机
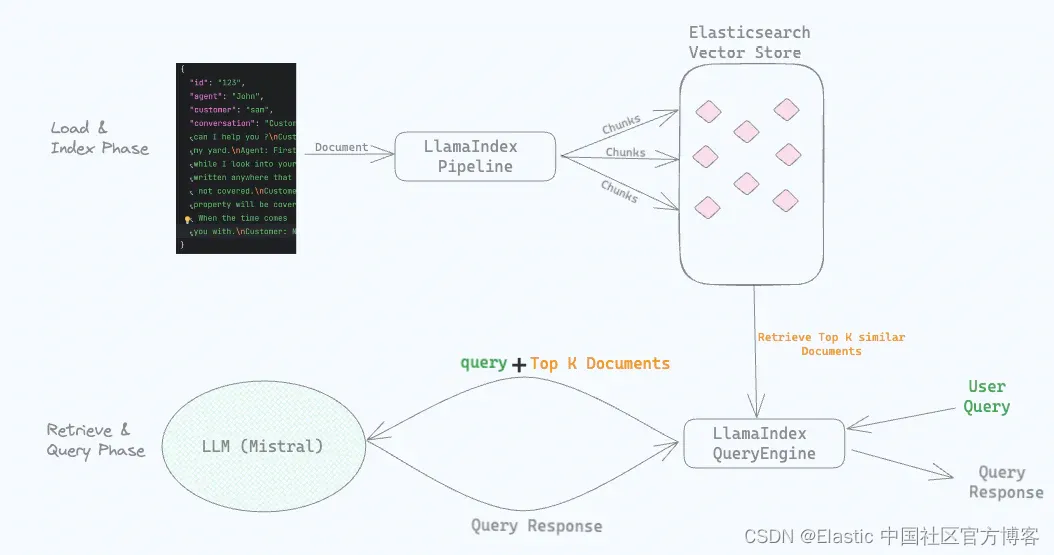
为了解决弱泛化问题,我们引入了一个新的概念:条件提示学习。关键思想是使提示取决于每个输入实例(图像),而不是一旦学习就固定。
解决办法
通过进一步学习一个轻量级神经网络来扩展CoOp,为每个图像生成一个输入条件令牌(向量),该令牌与可学习的上下文向量相结合。

核心思路:context tokens也可以有image embedding决定,其中
由meta-net决定
作者就认为说这个最优的template肯定跟这个图片的文本内容相关,那既然跟图片文本内容相关,那我就要把图片的embedding给引进来,然后就很容易就能够构建出把这个embedding给引过来,构建一个Meta net(其实就一个MLP)。
在这里也是不训Text Encoder和Image Encoder(CoOp也不训练Text Encoder和Image Encoder),只训左边黄色这些部分。
在这项工作中,Meta-Net采用两层瓶颈结构(Linear-ReLU-Linear)构建,其中隐藏层将输入维数降低了16倍。元网络的输入仅仅是图像编码器产生的输出特征。
摘要
随着像CLIP这样强大的预训练视觉语言模型的兴起,研究如何使这些模型适应下游数据集变得至关重要。最近提出的一种名为上下文优化(CoOp)的方法将提示学习(nlp的最新趋势)的概念引入视觉领域,以适应预训练的视觉语言模型。具体来说,CoOp将提示中的上下文单词转换为一组可学习的向量,并且仅使用少量标记的图像进行学习,可以实现比密集调整的手动提示的巨大改进。在我们的研究中,我们发现了CoOp的一个关键问题:学习到的上下文不能推广到同一数据集中更广泛的未见类,这表明CoOp过拟合了训练期间观察到的基本类。为了解决这个问题,我们提出了条件上下文优化(CoCoOp),它通过进一步学习一个轻量级神经网络来为每个图像生成一个输入条件token(向量)来扩展CoOp。与CoOp的静态提示相比,我们的动态提示适应每个实例,因此对类转移不那么敏感。大量实验表明,CoOp对未见类的泛化效果比CoOp好得多,甚至显示出超越单个数据集的有希望的可转移性;并且产生了更强的领域泛化性能。代码可在GitHub - KaiyangZhou/CoOp: Prompt Learning for Vision-Language Models (IJCV'22, CVPR'22)获得。
1. 介绍
最近在大规模视觉语言预训练方面的研究在零射击图像识别方面取得了惊人的成绩[13,24,33,40],表明了这种范式在学习开放世界视觉概念方面的潜力。设计的关键在于如何对视觉概念进行建模。在传统的监督学习中,标签是离散化的,每个类别都与一个随机初始化的权重向量相关联,该权重向量被学习以最小化与包含相同类别的图像的距离。这样的学习侧重于闭集视觉概念,将模型限制在预定义的类别列表中,并且在训练过程中看不到的新类别时无法扩展。
相比之下,对于CLIP[40]和ALIGN[24]等视觉语言模型,分类权值是由参数化文本编码器(例如Transformer[48])通过提示[34]直接生成的。例如,为了区分包含不同品种的狗和猫的宠物图像,可以采用“某类,某类宠物的照片”这样的提示模板作为文本编码器的输入,通过在“fclassg”令牌中填写真实的类名,就可以合成用于分类的类特定权重。与离散标签相比,视觉语言模型的监督来源来自自然语言,这允许对开放集视觉概念进行广泛的探索,并已被证明在学习可转移表征方面是有效的[24,40]。
随着这种强大的视觉语言模型的兴起,社区最近开始研究潜在的解决方案,以有效地使这些模型适应下游数据集[14,53,56,63]。为了适应网络规模的数据,比如CLIP使用的4亿对图像和文本,视觉语言模型被有意地设计成具有高容量,这意味着模型的大小将是巨大的,通常有数亿甚至数十亿个参数。因此,在深度学习研究中经常采用的对整个模型进行微调[18]是不切实际的,甚至可能会破坏已经学习好的表示空间。
一种更安全的方法是通过添加一些对任务有意义的上下文来调整提示,比如上面提到的宠物数据集的“一种宠物”,这在提高性能方面是有效的[40]。然而,提示工程非常耗时且效率低下,因为它必须基于反复试验,并且也不能保证最佳提示。为了自动化提示工程,Zhou等人[63]最近探索了提示学习的概念——NLP的最新趋势[15,25,30,32,44,60]——用于适应预训练的视觉语言模型。
他们的方法,上下文优化(CoOp),利用神经网络的可微特性,将文本中的提示词转化为一组可学习的向量。CoOp仅使用少量标记图像进行学习,在广泛的图像识别数据集上实现了比密集调整的手动提示的巨大改进。

图1所示。我们研究的动机:学习一般化的提示。这些图像是从SUN397[55]中随机选择的,SUN397是一个广泛使用的场景识别数据集。
在我们的研究中,我们发现了CoOp的一个关键问题:学习的上下文不能推广到同一任务中更广泛的未见类。图1说明了这个问题:CoOp学习的上下文在区分“到达门”和“大教堂”等基本类方面工作得很好,但是当它被转移到新的(看不见的)类(如“风力发电场”和“火车铁路”)时,准确性会显著下降——即使任务的性质保持不变,即识别场景。结果表明,学习到的上下文过度拟合基类,因此未能捕获对更广泛的场景识别至关重要的更一般化的元素。我们认为这样的问题是由CoOp的静态设计引起的:上下文,一旦学习就固定了,只针对一组特定的(训练)类进行优化。相反,zero-shot采用的手动设计提示符具有相对的通用性。
为了解决弱泛化问题,我们引入了一个新的概念:条件提示学习。关键思想是使提示取决于每个输入实例(图像),而不是一旦学习就固定。为了使模型参数有效,我们引入了一个简单而有效的条件提示学习实现。具体来说,我们通过进一步学习一个轻量级神经网络来扩展CoOp,为每个图像生成一个输入条件令牌(向量),该令牌与可学习的上下文向量相结合。我们称我们的方法为条件上下文优化(CoCoOp)图2显示了概述。有趣的是,CoCoOp的模式也是图片分隔类似的,这解释了为什么实例条件提示更具通用性:它们被优化为表征每个实例(对类转移更健壮),而不是仅为某些特定的类服务。
我们在11个数据集上进行了全面的实验,涵盖了一系列不同的视觉识别任务。具体来说,我们设计了一个从基础到新的泛化设置,其中首先使用基类学习模型,然后在全新的类上进行测试。与zero-shot方法[40]和CoOp[63]相比,我们的方法获得了最佳的整体性能(表1)。重要的是,CoCoOp在未见过的类中比CoOp获得了显著的改进(图3(a)),从而大大缩小了手动提示和基于学习的提示之间的差距。
在一个更具挑战性的场景中,从一个任务中学习到的上下文直接转移到具有完全不同类别的其他任务中,CoCoOp仍然以明显的优势击败CoOp(表2),这表明实例条件提示更具可转移性,并且有可能在更大的范围内取得成功。CoCoOp也获得了比CoOp更强的域泛化性能(表3),进一步证明了动态提示的优势。
总之,我们的研究为快速学习中的泛化问题提供了及时的见解,并且至关重要的是,证明了一个简单的想法在各种问题场景中的有效性。我们希望我们的方法和在这项工作中提出的发现可以为未来的推广和转移提示学习的研究铺平道路。

图3。CoCoOp和CoOp在基础到新概化设置下的综合比较。(a) CoCoOp能够在所有数据集上的未见类中获得比CoOp一致的改进。(b) CoCoOp的基本精度下降大多在3%以下,这远远超过了泛化的收益。
2. 相关工作
提示学习
这个话题起源于自然语言处理领域。其动机是将预训练的语言模型(如BERT[8]或GPT[41])视为知识库,从中可以获得对下游任务有用的信息[39]。具体来说,给定一个预训练的语言模型,该任务通常被制定为“填空”完形测试,例如要求模型预测“没有理由观看”中的被屏蔽标记。它是[MASK]”作为“积极”或“消极”的情绪分类。关键在于如何以模型熟悉的格式设计带下划线的部分,即提示符(模板)。
与手动设计提示不同,提示学习研究的目标是在可负担的标签数据的帮助下实现过程的自动化。Jiang等[25]使用文本挖掘和意译生成一组候选提示,从中选择具有最高训练精度的最佳提示。Shin等人[44]提出了AutoPrompt,这是一种基于梯度的方法,它从词汇表中选择引起最大变化在基于标签可能性的梯度。我们的研究与连续提示学习方法最相关[30,32,60],其主要思想是将提示转换为一组连续向量,可以针对目标函数进行端到端优化。更全面的调查请参见Liu等[34]。
在计算机视觉中,提示学习是一个新兴的研究方向,直到最近才被探索[27,42,56,58,63]。我们的研究建立在CoOp的基础上[63],这是最早将持续的提示学习引入视觉领域以适应预训练的视觉语言模型的工作。至关重要的是,我们的方法解决了CoOp的弱泛化问题[63],基于一个简单的条件提示学习的想法——据我们所知,这在NLP的背景下也是新颖的,因此也可能引起NLP社区的兴趣。
Zero-Shot Learning
零样本学习(Zero-Shot Learning, ZSL)是另一个相关的研究领域,其目标与我们的相似,即通过仅训练基础类来识别新类[3,51,54,57]。此外,在基类上训练的模型在新类上经常失败的泛化问题也与ZSL文献中提出的“视类偏差”问题有关[54]。ZSL最常见的方法是基于辅助信息(如属性[23]或词嵌入[12,52])来学习语义空间。与现有的ZSL方法不同,我们的工作解决了适应大型视觉语言模型的新问题,并使用了基于提示的截然不同的技术。
3. 方法
我们的方法概述如图2所示。下面我们首先对本文使用的基础模型CLIP[40]和CoOp[63]进行简要回顾。然后,我们将介绍我们的方法的技术细节以及设计背后的基本原理。与CoOp一样,我们的方法适用于更广泛的类似clip的视觉语言模型。
图2。我们的方法,条件上下文优化(CoCoOp),由两个可学习的组件组成:一组上下文向量和一个轻量级神经网络(Meta-Net),为每个图像生成一个输入条件令牌。
3.1. 对CLIP和CoOp的回顾
对比语言-图像预训练
对比语言图像预训练被称为CLIP[41],已经很好地证明了学习开放集视觉概念的潜力。CLIP使用两个编码器构建,一个用于图像,另一个用于文本,如图2所示。图像编码器可以是ResNet[18],也可以是ViT[9],用于将图像转换为特征向量。文本编码器是一个Transformer[48],它将单词标记序列作为输入,并再次产生矢量化表示。
在训练过程中,CLIP采用对比损失来学习两种模态的联合嵌入空间。具体来说,对于一小批图像-文本对,CLIP最大化每个图像与匹配文本的余弦相似度,同时最小化与所有其他不匹配文本的余弦相似度,并且每个文本的损失也以类似的方式计算。经过训练,CLIP可以用于zero-shot图像识别。设x为图像编码器生成的图像特征,设为文本编码器生成的一组权重向量,每个向量代表一个类别(假设总共有K个类别)。特别是,每个
都是从一个提示符派生的,例如“一个{class}的照片”,其中“{class}”令牌用第i个类名填充。
预测概率为

在sim(·;·)表示余弦相似度,是学习到的温度参数。
上下文优化(CoOp)
上下文优化(Context Optimization, CoOp)旨在克服即时工程中的低效率问题,使预训练的视觉语言模型更好地适应下游应用[63]。CoOp的关键思想是使用可以从数据端到端学习的连续向量对每个上下文令牌建模。具体来说,CoOp没有使用“a photo of a”作为上下文,而是引入了M个可学习的上下文向量,,每个与单词嵌入具有相同的维数。第
类的提示符(用
表示)现在变成了
虚拟机;其中
是类名的嵌入词。上下文向量在所有类之间共享设g(·)表示文本编码器,则预测概率为

为了使CLIP适应下游图像识别数据集,可以使用交叉熵损失作为学习目标。由于文本编码器g(·)是可微的,所以
梯度可以一路传播回来更新上下文向量。请注意,CLIP的基本模型在整个训练过程中是冻结的(我们的也是)。
3.2. CoCoOp:条件上下文优化
CoOp是一种数据高效的方法,允许仅使用下游数据集中的少数标记图像来训练上下文向量。然而,如前所述,CoOp不能推广到同一任务中更广泛的不可见类。我们认为实例条件上下文可以更好地泛化,因为它将焦点从特定的类集(为了减少过拟合)转移到每个输入实例,从而转移到整个任务。
实现CoCoOp的一种直接方法是构建M个神经网络来获得M个上下文令牌。然而,这样的设计需要神经网络的大小,这比在CoOp中拥有M个上下文向量要大得多。在这里,我们提出了一种参数有效的设计,在实践中效果很好。具体来说,在M上下文向量之上,我们进一步学习一个轻量级的神经网络,称为Meta-Net,为每个输入生成一个条件令牌(向量),然后与上下文向量结合。请参见图2以获得该体系结构的草图。
设表示由θ参数化的元网络,每个上下文令牌现在由
得到,其中
。因此,第
类的提示符取决于输入,即
。预测概率计算为

在训练过程中,我们将上下文向量与元网络的参数θ一起更新。在这项工作中,Meta-Net采用两层瓶颈结构(Linear-ReLU-Linear)构建,其中隐藏层将输入维数降低了16倍。元网络的输入仅仅是图像编码器产生的输出特征。我们把探索更先进的设计留给未来的工作。
4. 实验
我们的方法主要在以下三个问题设置中进行评估:1)在数据集中从基本类到新类的泛化(第4.1节);2)跨数据集传输(章节4.2);3)域概化(章节4.3)。我们实验中使用的所有模型都是基于开源的CLIP [40]在讨论结果之前,我们提供实验设置的细节如下。
数据集
对于前两个设置,即base-to-new泛化和跨数据集传输,我们使用11个图像识别数据集,如Zhou等人[63],涵盖了多种识别任务。具体来说,基准包括ImageNet[6]和Caltech101[11],用于对一般对象进行分类;OxfordPets [38], StanfordCars [28], Flowers102 [36], Food101[2]和fgvc - aircraft [35];SUN397[55]用于场景识别;UCF101[46]用于动作识别;DTD[5]用于纹理分类;最后是EuroSAT[19],用于卫星图像识别。在领域泛化实验中,我们使用ImageNet作为源数据集,并使用包含不同类型领域偏移的ImageNet的另外四个变体作为目标数据集,即ImageNetV2[43]、ImageNetSketch[50]、ImageNet- a[22]和ImageNet- r[21]。
按照Zhou等人[63]的做法,我们在使用原始测试集进行测试的同时,对每个数据集随机抽取几个训练集。我们只评估Zhou等[63]研究的最高shot次数,即16-shot,这足以证明我们的方法是正确的。对于基于学习的模型,结果是三次运行的平均值。
Baselines
与我们的方法直接竞争的是CoOp[63],它本质上学习静态提示(与我们的动态提示相比)。还比较了基于手动提示的零样本方法CLIP[40]。值得一提的是,每个数据集的手动提示都是使用测试数据中的所有类进行密集调优的[40]。
训练细节
我们的实现是基于CoOp的代码在整个实验中,我们使用了CLIP中可用的最佳视觉骨干,即VITB/16。Zhou等[63]提出,更短的上下文长度和良好的初始化可以带来更好的性能和更强的域移位鲁棒性。因此,我们将上下文长度固定为4,并使用CoOp和CoOp的“a photo of a”的预训练词嵌入来初始化上下文向量。由于实例条件设计,我们的方法训练速度很慢,并且比CoOp消耗更多的GPU内存。因此,为了保证模型能够适应GPU,同时减少训练时间,我们以batch size为1的方式训练CoCoOp 10 epoch。第5节将更详细地讨论这种限制。
4.1. 从基类到新类的泛化
解决CoOp的弱泛化问题是本研究的重点。在11个数据集上,我们将类平均分成两组,一组作为基类,另一组作为新类。基于学习的模型,即CoOp和CoOp,仅使用基类进行训练,而分别对基类和新类进行评估以测试泛化性。具体结果如表1所示。

表1。CLIP、CoOp和CoCoOp在基础到新泛化设置下的比较。对于基于学习的方法(CoOp和CoCoOp),它们的提示是从基类(16-shot)中学习的。研究结果有力地证明了条件提示学习的强泛化性。H:调和均值(以突出泛化权衡[54])。
CoOp在看不见的类中的失败
分割并不能保证这两个类组同样困难,正如CLIP不稳定的结果所证明的那样:基本精度和新的精度数字有很大的不同尽管如此,在几乎所有数据集上,CoOp的新准确率始终远低于基本准确率,平均差距接近20%(82.69%对63.22%)。尽管在平均性能方面保持了优于CLIP的优势,但CoOp在基类中的收益几乎被新类中的灾难性失败抵消了,这突出表明需要改进基于学习的提示的泛化性。
CoCoOp显著缩小了泛化差距
如表1(a)所示,CoCoOp将未见类的准确率从63.22%提高到71.69%,这在很大程度上减少了与手动提示的差距。结果证实,实例条件提示更具泛化性。图3(A)显示了每个数据集改进的更详细细分,其中我们观察到超过10%的提升在11个数据集中的5个的准确性。值得注意的是,在具有挑战性的ImageNet数据集上,CoCoOp从67.88%激增到70.43%代表了一个不小的进步(70.43%的准确率甚至超过了CLIP的68.14%)。
图3。CoCoOp和CoOp在基础到新概化设置下的综合比较。(a) CoCoOp能够在所有数据集上的未见类中获得比CoOp一致的改进。(b) CoCoOp的基本精度下降大多在3%以下,这远远超过了泛化的收益。
CoCoOp在泛化方面的收益远远大于在基础精度方面的损失
与CoOp相比,在大多数数据集上,CoOp的基类性能下降(参见图3(b))。这是合理的,因为CoOp专门针对基类进行优化,而CoOp针对每个实例进行优化,以便在整个任务中获得更多的泛化。但值得注意的是,在CoCoOp的基本精度低于CoOp的9个数据集上,大多数损失都在3%以下(准确地说,9个数据集中的6个),这远远超过了图3(a)所示的未见类的收益;即使对于那些CoCoOp损失最大的职业,泛化的提升也足以将平均值转化为正数,例如,斯坦福汽车的基本准确率下降幅度最大,为-7.63%,但在新职业中,准确率提高了13.19%,排名第三,这为CoCoOp带来了5.56%的积极提升。

CoCoOp比Clip更具吸引力
当考虑到基类和新类时,cooop比CLIP (75.83% vs 71.70)的增益超过4%,这表明实例条件提示在捕获与识别任务相关的更一般化的元素方面具有更好的潜力。从理论上讲,基于学习的提示比手动提示有更高的过拟合基类的风险。因此,CLIP是一个强大的竞争对手,可以在看不见的类中击败。与CoOp不同的是,我们对CoCoOp :CoCoOp在11个数据集(即ImageNet, OxfordPets, Food101和SUN397)中的4个数据集上,准确率甚至比CLIP更好,并且与其他数据集的CLIP相差不远,除了FGVCAircraft,其中手动和基于学习的提示之间的差距通常很大。在对上下文长度的烧蚀研究中,我们发现FGVCAircraft受益于更长的上下文,这与Zhou等人[63]的研究结果一致。为了缩小甚至推翻在隐性课堂中手工提示和基于学习的提示之间的差距,我们需要付出更多的努力,我们希望本研究中提出的见解可以帮助社区解决提示学习中的泛化问题。
6. 讨论与结论
我们的研究解决了一个重要的问题,即如何使大型预训练的人工智能模型适应下游应用。这些模型,也被称为基础模型[1],在视觉和NLP社区中受到学术界和工业界越来越多的关注,因为它们在各种下游任务方面的能力非常强大。
然而,就数据规模和计算资源而言,基础模型的预训练成本很高;通常包含大量的参数,以发展足够的能力。例如,我们实验中使用的基于VITI - B /16的CLIP模型[40],其参数大小高达150M。这些因素共同突出了研究基础模型民主化的有效适应方法的必要性。
我们的研究遵循了参数高效提示学习[63]的思路,及时洞察了静态提示的泛化问题,更重要的是,证明了基于条件提示学习的简单设计在各种问题场景中表现出色,包括从基本类到新类的泛化、跨数据集提示转移和领域泛化。
就未来的工作而言,一个方向是进一步发展条件提示学习,并可能更有效地实施,以加速训练,并增强可泛化性。跨数据集传输实验表明,与静态提示相比,实例条件提示在不同性质的任务之间更具可移植性。因此,看看这样的想法是否可以扩展到,例如,更大的元网络模型尺寸,更大规模的训练图像,甚至是混合了不同数据集的异构训练数据,这将是很有趣的。
参考资料
论文下载(CVPR 2022)
https://arxiv.org/abs/2203.05557
📎Conditional Prompt Learning for Vision-Language Models.pdf

代码地址
GitHub - KaiyangZhou/CoOp: Prompt Learning for Vision-Language Models (IJCV'22, CVPR'22)