包括 Tubi 在内的广告型点播流媒体服务,正在成为免费在线消费娱乐的重要组成部分。Tubi 拥有一个囊括电视剧、电影、体育和娱乐直播频道的海量视频内容库;同时,Tubi 为观众提供个性化的视频推荐,帮助观众快速找到想看的视频内容,这是确保用户体验的关键因素。然而,Tubi 的数百万月度活跃用户来自全球众多国家,在海量视频内容库中为用户挑选满足其主流或小众多样化需求的视频内容是极具挑战的。
Tubi 致力于为用户提供全方位的个性化体验,从用户观看的视频内容,到电影电视海报的选择,甚至在播放、详情展示等方面也会进行个性化处理。Tubi 运行着 70 多个机器学习模型以响应用户请求来构建主页。这些不同的模型分别用于新老用户,对用户相关的视频内容、主页上不同类别视频的集合以及自动播放的内容进行排序。
本文着重分享我们在召回方面的探索,以及这一过程中我们所做的各种设计选择。
召回
大多数现代推荐系统是基于两阶段推荐过程,第一阶段可将候选空间从数百万减少至用户可能感兴趣的较少数量的相关候选集,推荐系统的第二阶段是生成候选集的最终排名。
召回是 Tubi 推荐系统的关键组成部分,因其作为一个轻量的阶段,可减少候选集大小,从而在延迟上为复杂的排序模型提供更大的空间。我们往期已完成的实验表明,召回阶段的效率不仅体现于用户参与度和体验方面的改善,还将减少计算和存储成本。
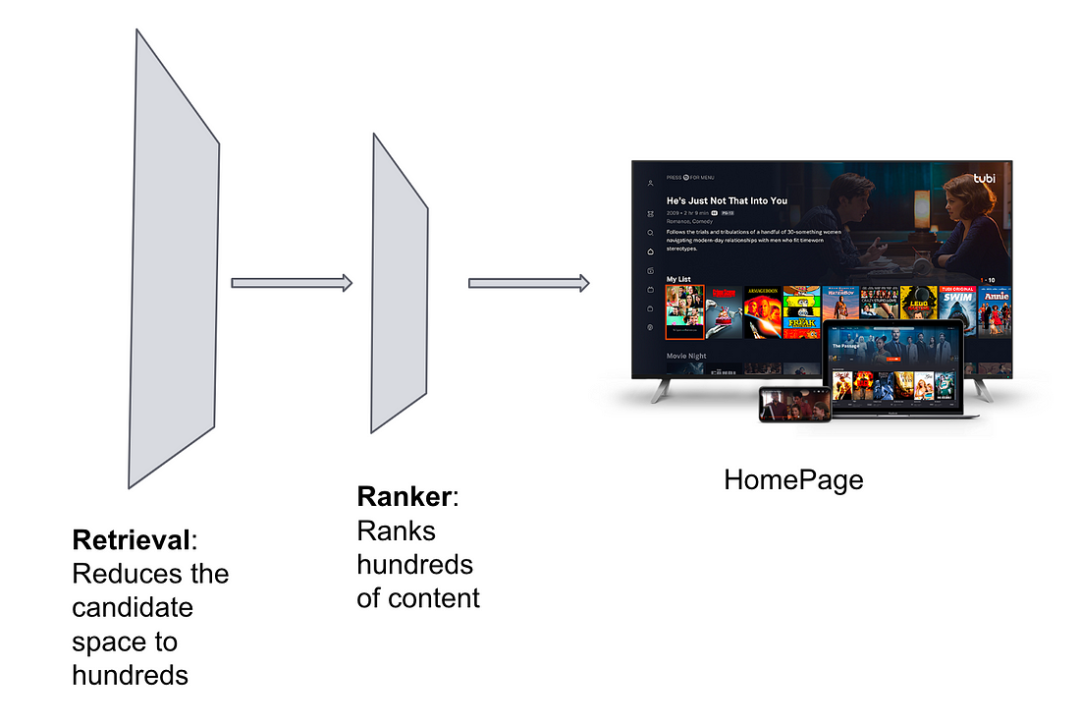
图一:典型的两阶段推荐流程
Tubi 的召回探索
Tubi 对个性化的探索开始于利用天级别的离线任务为每个用户计算内容排序。起初,Tubi 的内容和用户群体都较小,因此我们可以做到为所有用户对整个内容目录进行排名。此外,构建实时推荐的基础设施需要投入一定的成本。

图二:2016 年 Tubi 首页
随着 Tubi 越来越受欢迎,日活跃用户和视频数量也在持续增长,为所有用户进行整个内容目录的排序需要占用大量计算资源。为降低计算和数据同步成本,我们采取的方式是减少存储每个用户的排名结果;这种方式在降低计算和数据同步成本方面确实有帮助,但牺牲了用户的个性化体验。
我们便从这里开始了对召回的探索。我们从一些简单的流行度指标入手,减少待排序的候选集;流行度可以基于国家、语言、类别和外部评估等标准来衡量。这样的召回方式特别适用于新用户,因为我们不熟悉其喜好,对他们的视频内容无法实现和对老用户一样的个性化。然而,对于老用户来说,这只是一个可用的初步筛选方案,因这一方案缺乏个性化,也加剧了流行度偏差。
基于 Embedding 的召回
与我们遇到的大多数其他问题一样,在这一过程中我们意识到个性化是关键。我们首先采用了协同过滤技术,根据用户过往的观看行为,利用”群体智慧”找到其可能想要观看的相关内容。
矩阵分解是实现协同过滤的传统方法之一,可以将 User Item 交互矩阵降维到低秩空间。User-Item 向量的内积就是用户对某一视频的偏好得分,这一内积也可以作为一个可用的初步召回方案。
由于每天进入系统的用户数量增加,我们在构建召回时遇到了如下问题:
1. 用于召回的用户向量需要大量存储空间
2. 并非所有用户的 User 向量质量都是可靠的,这是因为我们只采样部分用户用于训练模型。为此,我们转而依赖于 Item 向量进行召回,并选择一个用户表示(例如观看历史记录)来生成召回候选集。
与此同时,深度学习在计算机视觉、自然语言处理和语音识别等领域取得了巨大的进展,其中非常重要的一项技术是表示学习,也就是 Embedding 的生成。
Embedding 是基于神经网络,用于表征文本或者类别数据的稠密数值向量;它的功能强大,可以捕捉到对象之间关系的本质,并可用于下游应用。通过 Tubi 众多合作伙伴和非合作伙伴(如 IMDB、Gracenote、RottenTomatoes 和维基百科),我们可以获取丰富的元数据,用于生成各种 Embedding。

图三:与每个视频内容相关的元数据
我们创建了 Spock 平台以更好地理解视频内容,该平台生成从 Doc2Vec 到 BERT 的各种 Embedding。请参阅往期技术博客了解详细信息。
如何生成召回候选项?
生成召回候选项的最快方法之一是查看用户过往喜欢观看的视频内容,生成更多类似的候选项;利用 Embedding,基于用户过往的观看历史来生成最近邻。后文我们将分享期间遇到的各种选择及现状。
版本 1:对 Embeddings 进行平均化
我们通过对用户观看历史的 Embeddings 进行平均,生成了用户 Embedding。平均化所带来的问题之一是信息丢失致使我们最终可能得到完全不相关的结果。例如,如果一个用户同时喜欢观看恐怖片和喜剧片,平均化可能会让结果既不落于恐怖片也不落于喜剧片类别。平均化的优势则是能得到简洁的用户表示,并且在计算最近邻时只需要考虑这一个平均后的向量表示。这样的召回方式意味着获取用户 Embeeding 的最近邻。
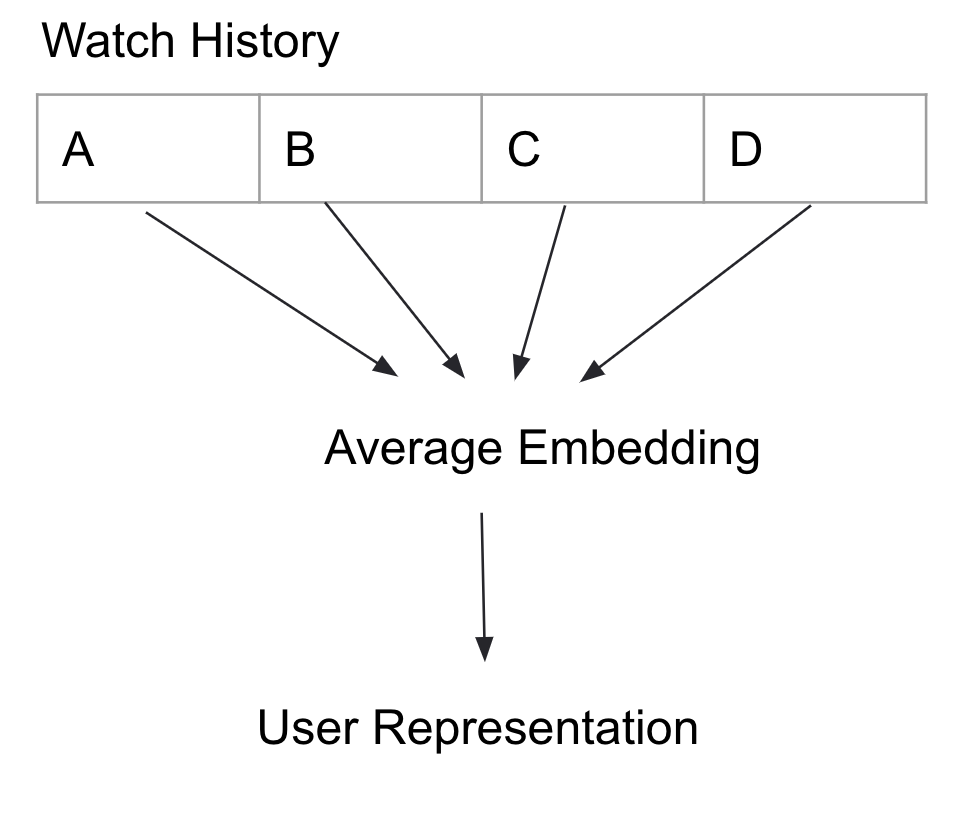
图四:将观看历史中的内容 Embedding 进行平均,生成用户 Embedding
版本 2:观看历史中每个视频的最近邻
除了平均化 Embedding,还可以对观看历史中的每个视频生成最近邻。这种做法的好处是每个视频内容都可以有自己的最近邻,坏处则是离线计算召回候选集和数据同步的任务将变得过于繁重,提取视频和计算检索的离线工作将变得过多,并且这一情况随着 Tubi 的增长也将变得更加严重。
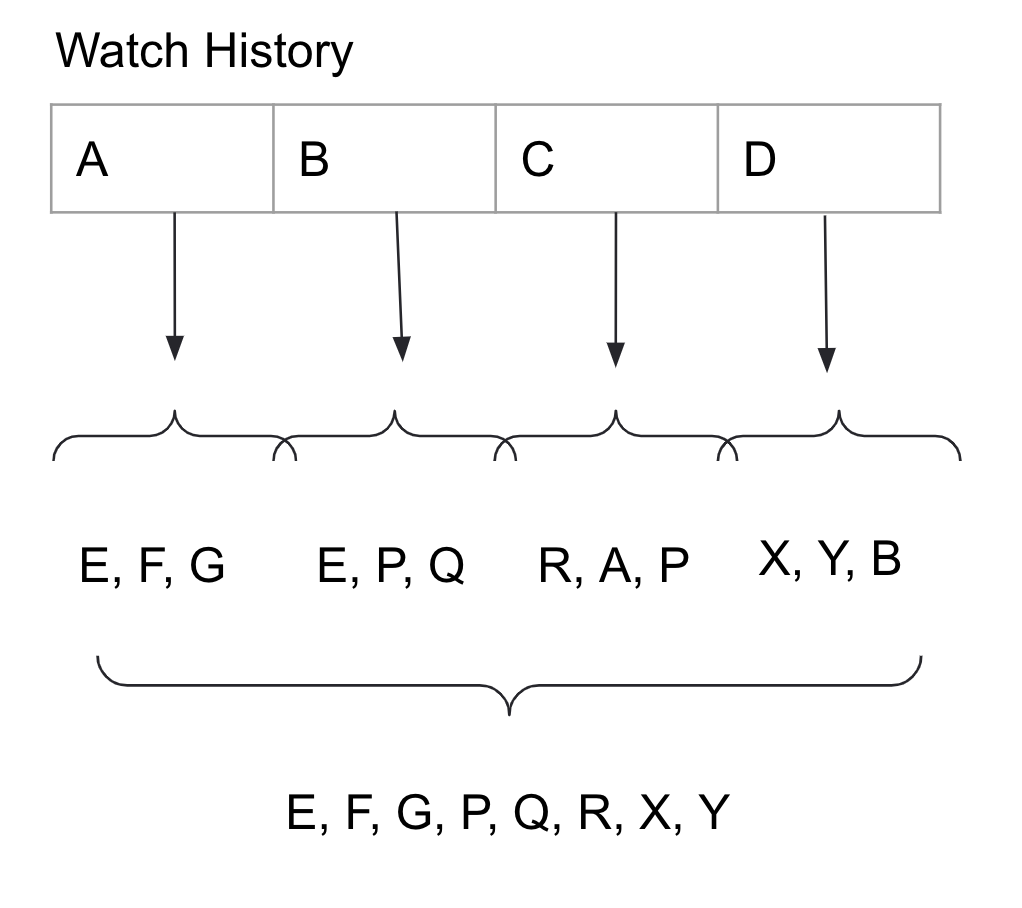
图五:计算观看历史中每个视频的最近邻,而非对 Embedding 进行平均化
版本 3: 多模态用户喜好
我们在观察用户的观看行为时发现了一个十分关键的点,那就是用户的观看行为呈现聚类模式,如图六所示。受 Pal 等人在 PinnerSage 中想法的启发,我们决定对用户的观看行为进行聚类,以得到一种简洁的、基于中心点的用户表示形式。
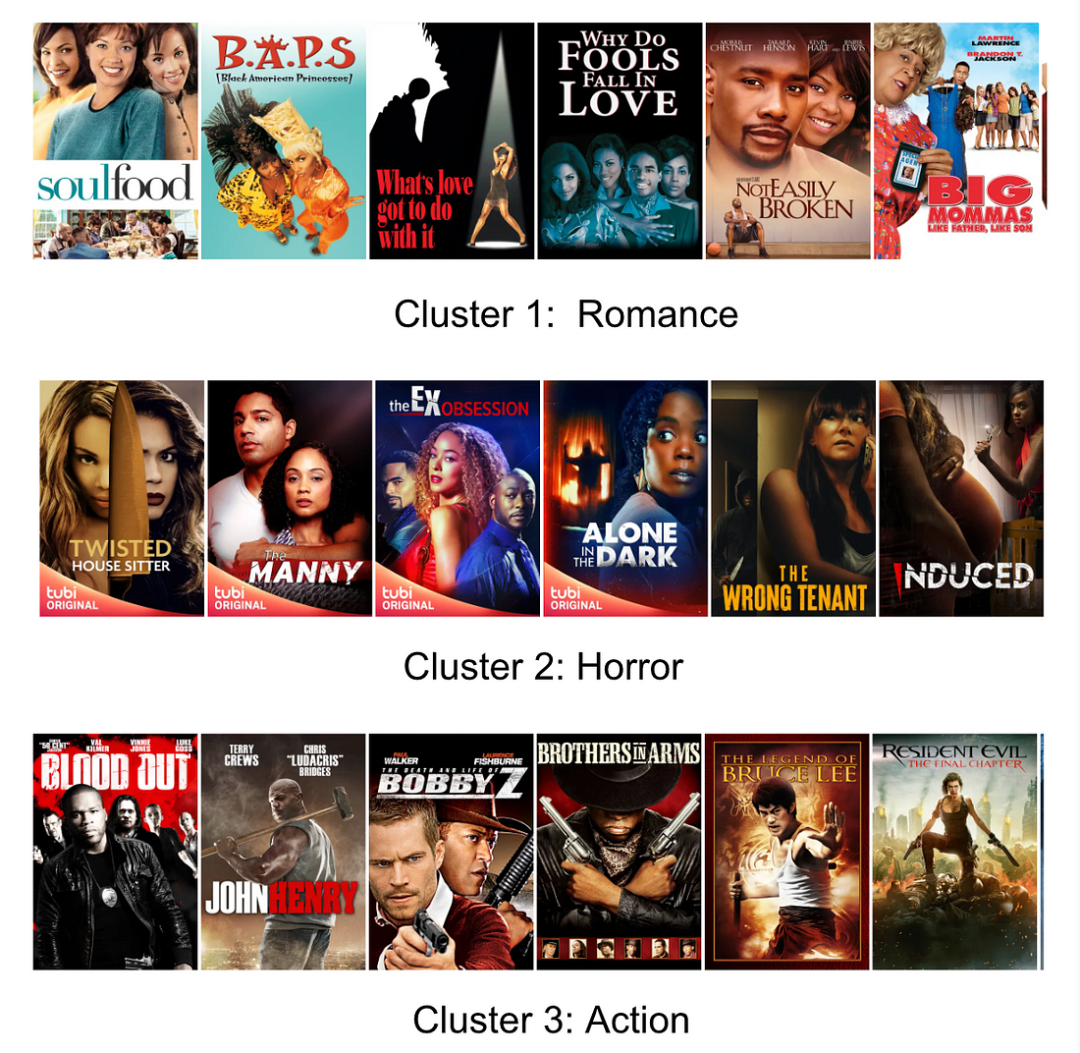
图六:某一用户观看行为的聚类
中心点能抓住聚类的特征,是可以代表这个聚类的一个聚类成员。正如这篇文章所提到的,使用中心点是表示聚类的一个更省钱的方式,因其无需像质心那样存储 Embedding,对异常值也不太敏感。
我们使用层级聚类来生成每个用户观看历史的聚类,并基于此来计算它们的最近邻。实验结果显示,这种方式显著提升了用户观看,同时还降低了数据同步成本。
版本 4:实时
至此,我们已经讨论了在捕捉用户多模态喜好方面的创新实践,但此时整个系统依然是以 batch 的模式运行的。随着用户、内容和 Embedding 数量的增加,每日需要同步的召回候选集数量很快就难以应对了。为解决这一问题,我们实现了实时排名和计算最近邻。为此,我们基于 FAISS 和 HSNW 技术搭建了一个内部系统,实现了向实时的迁移,这一过程节省了大量非必要的计算和存储成本。
版本 5:基于上下文的探索与采样
一旦我们完成了每个用户的聚类,就可以计算聚类的重要性,可查看这篇文章了解更多内容。聚类重要性可以很好地捕捉不同聚类在规模大小、最近观看内容和观看时长方面的不同特点,有助于我们对每个用户请求进行探索和采样,以便推荐上下文相关的内容,同时也使推荐结果是动态变化的。
版本 6:来接受挑战吧!
一旦实现了实时排名和最近邻计算,我们便可以做出更多酷炫的尝试了,例如自适应实时聚类、使用更多的用户反馈信号以及基于不同标准的聚类重要性。变革是当今时代的主题,我们正在这样做,甚至还会做更多。
作者:Jaya Kawale, Tubi Vice President of Engineering, Machine Learning
译者:Honghong Zhao, Senior Engineer, Machine Learning
校对:Shengwu Yang, Director, Machine Learning
如果你对类似项目感兴趣,欢迎加入 Tubi!
- 查看热招岗位
- 关注微信公众号