这篇文章的作为前几篇RNN\LSTM\RNN的后续之作,主要就是补充一个这两个哥的变体,想详细了解RNN\LSTM\GRU的详细理论和公式推导以及代码的请前往下面链接:
算法学习笔记:循环神经网络(Recurrent Neural Network)-CSDN博客
算法学习笔记:长短期记忆网络(Long Short Term Memory Network)-CSDN博客
算法学习笔记:门控循环单元(Gate Recurrent Unit)-CSDN博客
一、Bi-LSTM
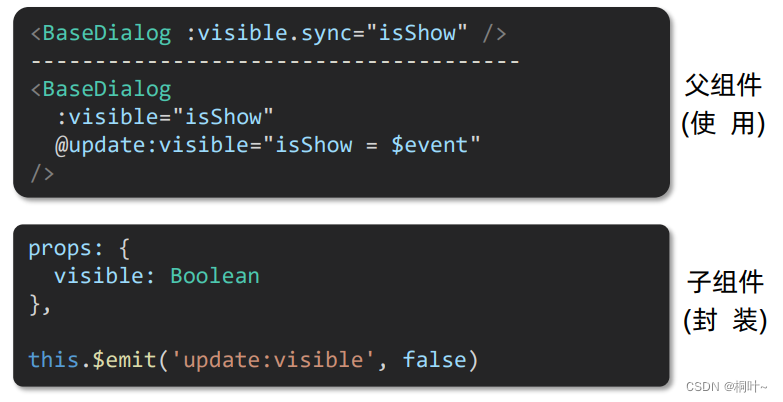
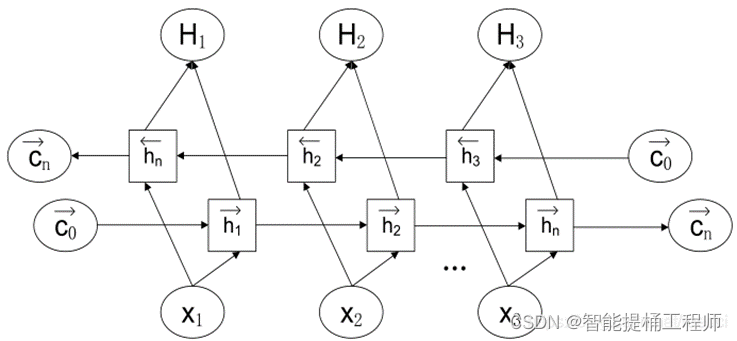
Bi-LSTM(Bidirectional Long Short Term Memory)网络是是一种基于长短期记忆网络(LSTM)的时间序列预测方法;它结合了双向模型和LSTM的门控机制,由2个独立的LSTM网络构成。当Bi-LSTM处理序列数据时,输入序列会分别以正序和逆序输入到2个LSTM网络中进行特征提取,并将将2个输出向量(即提取后的特征向量)进行拼接后形成的输出向量作为该时间步的最终输出。
(其实就是两个LSTM组合在一起,具体的原理和结构和LSTM一样啦)
Bi-LSTM的模型设计理念是使t时刻所获得特征数据同时拥有过去和将来之间的信息;此外,值得一提的是,Bi-LSTM中的2个LSTM网络参数是相互独立的,它们只共享同一批序列数据。
二、Bi-GRU
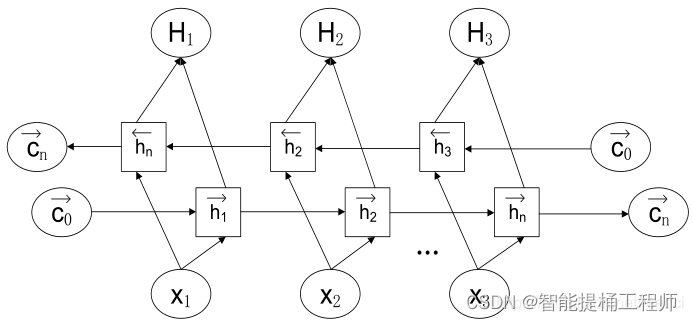
Bi-GRU(Bidirectional Gated Recurrent Unit)是一种基于门控循环单元(GRU)的时间序列预测方法;它结合了双向模型和门控机制,整体结构与单元体结构与GRU一致,因此也能够有效地捕捉时间序列数据中的时序关系。Bi-GRU的整体结构由两个方向的GRU网络组成,一个网络从前向后处理时间序列数据,另一个网络从后向前处理时间序列数据;这种双向结构可以同时捕捉到过去和未来的信息,从而更全面地建模时间序列数据中的时序关系。
(也就是两个GRU组会在一起啦,结构啥的都一样!)
三、Bi-LSTM和Bi-GRU源码
import numpy as np
from numpy import savetxt
import pandas as pd
from pandas.plotting import register_matplotlib_converters
from pylab import rcParams
import matplotlib.pyplot as plt
from matplotlib import rc
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.metrics import r2_score
import tensorflow as tf
from tensorflow import keras
from keras.optimizers import Adam,RMSprop
import os
import tensorflow as tf
tf.config.set_visible_devices(tf.config.list_physical_devices('GPU'), 'GPU')
register_matplotlib_converters()
#plt.rcParams["font.sans-serif"] = [""]# 指定默认字体
pd.set_option('display.max_columns', None) # 结果显示所有列
pd.set_option('display.max_rows', None) # 结果显示所行行
#>>>>>>>>>>>>数据预处理
#1.训练集(New-train)数据处理
source = 'New-train.csv'
df_train = pd.read_csv(source, index_col=None)
df_train = df_train[['设置你的数据表头']] source = 'New-test.csv'
df_test = pd.read_csv(source, index_col=None)
df_test = df_test[['设置你的数据表头']] train_size = int(len(df_train))
test_size = int(len(df_test))
train = df_train.iloc[0:train_size]
test = df_test.iloc[0:test_size]
print(len(train), len(test))def training_data(X, y, time_steps=1):Xs, ys = [], []for i in range(len(X) - time_steps):v = X.iloc[i:(i + time_steps)].valuesXs.append(v)ys.append(y.iloc[i + time_steps])return np.array(Xs), np.array(ys)time_steps = 10
X_train, y_train = training_data(train.loc[:, '设置你的数据表头'], train.*, time_steps)
x_test, y_test = training_data(test.loc[:,'设置你的数据表头'], test.*, time_steps)#构建模型
# 单层双尾lstm
def model_BiLSTM(units):model = keras.Sequential()#Input Layermodel.add(keras.layers.Bidirectional(keras.layers.LSTM(units=units,activation="relu",input_shape=(X_train.shape[1], X_train.shape[2]))))model.add(keras.layers.Dropout(0.2))#Hidden Layermodel.add(keras.layers.Dense(1))model.compile(loss='mse', optimizer=Adam(learning_rate=0.001, clipvalue = 0.2))return model# 单层双尾GRU
def model_BiGRU(units):model = keras.Sequential()#inputmodel.add(keras.layers.Bidirectional(keras.layers.GRU(units=units,activation="relu",input_shape=(X_train.shape[1], X_train.shape[2]))))model.add(keras.layers.Dropout(0.2))model.add(keras.layers.Dense(1))model.compile(loss='mse', optimizer='adam')return model#训练模型
def fit_model(model):#早停机制,防止过拟合early_stop = keras.callbacks.EarlyStopping(monitor='val_loss',min_delta=0.0,#min_delta=0.0 表示如果训练过程中的指标没有发生任何改善,即使改善非常微小,也会被视为没有显著改善patience=2000)#表示如果在连续的 2000 个 epoch 中,指标没有超过 min_delta 的改善,训练将被提前停止history = model.fit( # 在调用model.fit()方法时,模型会根据训练数据进行参数更新,并在训练过程中逐渐优化模型的性能X_train, y_train, # 当训练完成后,模型的参数就被更新为训练过程中得到的最优值epochs=400, # 此时model已经是fit之后的model,直接model.predict即可(千万不要model=model.fit(),然后再model.predict)validation_split=0.1, batch_size=12600,shuffle=False,callbacks=[early_stop])return historylstm_n64 = model_BiLSTM(64)
GRU = model_BiGRU(64)
#这里只是写了训练模型的代码,预测的话要根据自己的数据结构以及想要的效果来写喔