在当今这个由数据驱动和AI蓬勃发展的时代,数据科学作为一门融合多种学科的综合性领域,对于推动各行各业实现数字化转型升级起着至关重要的作用。近年来,大语言模型技术发展态势强劲,为数据科学的进步做出了巨大贡献。其中,ChatGPT作为大型预训练语言模型的代表之一,具备惊人的生成能力,可生成流畅且富有逻辑的文本,其在智能对话、自动写作、语言理解等众多领域已取得突破性应用。
作为数据科学的核心对象和AI发展的基石,数据为大型预训练语言模型提供了训练和优化的依据,通过对大量文本数据的学习,ChatGPT 等模型能够更好地理解和生成自然语言。因此,如何做好数据治理,发挥数据要素价值,成为企业竞争优势的关键。
百分点科技与清华大学出版社联袂打造的《数据科学技术:文本分析和知识图谱》一书,提供了一个全面而深入的视角,让我们能够更好地理解和把握数据科学。书中第十章介绍了以 ChatGPT 为代表的大语言模型(LLM),详尽阐述了其发展历程、现实原理及应用等。以下内容节选自原文:
ChatGPT是由OpenAI基于GPT(Generative Pre-trained Transformer)开发出来的大模型。其目标是实现与人类类似的自然对话交互,使机器能够理解用户输入并生成连贯、有意义的回复。随着人工智能技术的快速发展,对话系统成为研究和应用的热门领域之一。人们渴望建立能够与人类进行自然、流畅对话的机器智能。传统的对话系统通常使用规则和模板来生成回复,但在处理更复杂的对话场景时存在局限性。因此,基于深度学习和自然语言处理的对话生成技术逐渐崭露头角。
ChatGPT延续了GPT模型的优势,旨在进一步提升对话系统的自然性和流畅性。它的目标是理解上下文、生成连贯的回复,并在对话交互中创造更真实、有趣的体验。ChatGPT的研发旨在满足实际应用中对于对话系统的需求,例如虚拟客服、智能助手等。
ChatGPT的背后支撑着大规模的数据集和强大的计算资源。通过使用海量的对话数据进行预训练,ChatGPT能够学习常见的对话模式和语言表达方式。同时,ChatGPT的开发者借助云计算和分布式技术,建立了庞大的计算集群来训练和优化模型。这种大规模计算能力对于提升ChatGPT的生成质量和实时性发挥重要作用。
ChatGPT的预训练和微调
GPT大模型通过预训练已经学习了许多技能,在使用中要有一种方法告诉它调用哪种技能。之前的方法就是提示模版(Prompt),在GPT-3的论文里,采用的是直接的提示模版和间接的Few-Shot示例。但是这两种方法都有问题,提示模版比较麻烦,不同的人表达相似的要求是有差异的,如果大模型要依赖各种提示模版的魔法咒语,那就和炼丹一样难以把握。
ChatGPT选择了不同的道路,以用户为中心,用他们最自然的方式来表达需求,但是模型如何识别用户的需求呢?其实并不复杂,标注样本数据,让模型来学习用户的需求表达方式,从而理解任务。另外,即使模型理解了人类的需求任务,但是生成的答案可能是错误、有偏见的,因此还需要教会模型生成合适的答案,这就是人类反馈学习,具体而言,这种反馈学习方法包括如下三步:
- 模型微调Supervised Fine-tuning(SFT):根据采集的SFT数据集对GPT-3进行有监督的微调(Supervised FineTune,SFT);这里本质上是Instruction-tuning。
- 训练奖励模型Reward Modeling(RM):收集人工标注的对比数据,训练奖励模型(Reword Model,RM);
- 强化学习Reinforcement Learning(RL):使用RM作为强化学习的优化目标,利用PPO算法微调SFT模型。
接下来的内容中,对这三个步骤进行具体阐述。
1. 模型微调SFT
在ChatGPT中,SFT通过对模型进行有监督的微调,使其能够更好地适应特定任务或指导。在模型微调的过程中,需要准备一个有监督的微调数据集。这个数据集由人工创建,包含了输入对话或文本以及期望的输出或回复。这些期望的输出可以是由人工提供的正确答案,或者是由人工生成的合适的回复。
接下来,根据这个有监督的微调数据集,我们对GPT模型进行微调。微调的过程可以通过反向传播和梯度下降算法实现,它们使得模型能够通过调整参数来更好地拟合数据集。在微调过程中,模型会根据输入对话或文本产生预测的输出或回复,并与期望的输出进行比较,计算损失函数。然后,通过最小化损失函数,模型会逐步调整参数,以使预测结果更接近期望输出。
微调之后,ChatGPT模型将能够更好地执行特定的任务,因为它在有监督的过程中学习到了任务的知识和要求。而这个有监督的微调过程本质上也是Instruction-tuning的一种形式,因为它可以根据人工提供的指导或期望输出来调整模型,具体步骤如图10-7所示。
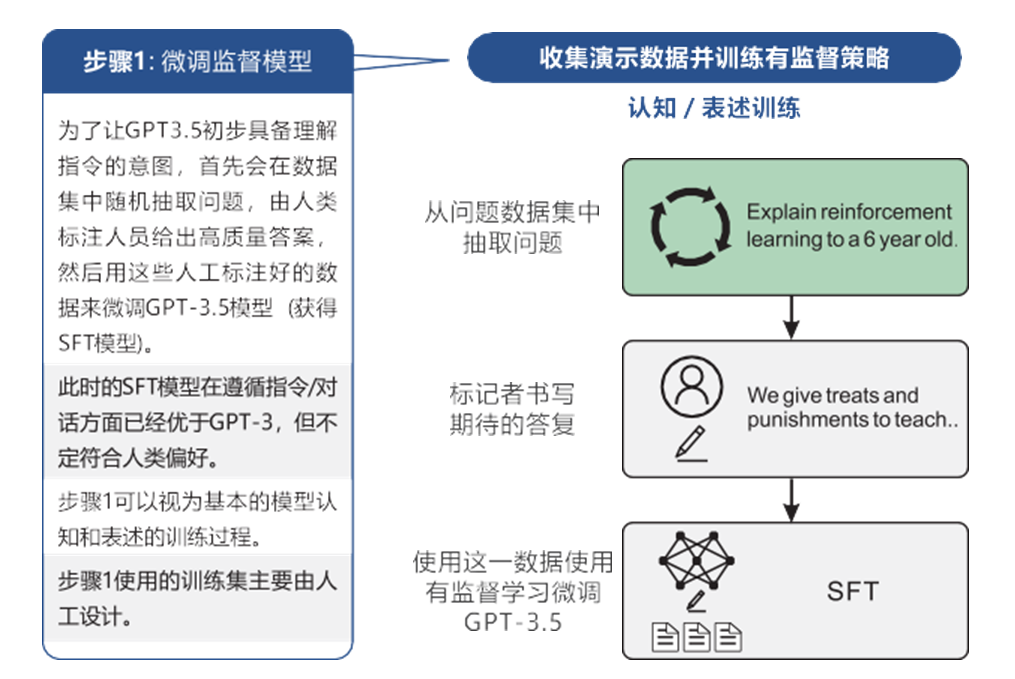
ChatGPT模型训练步骤1
2. 训练奖励模型RM
在ChatGPT中,通过收集人工标注的对比数据来训练一个奖励模型,用于指导GPT模型的优化过程,如图10-8所示。
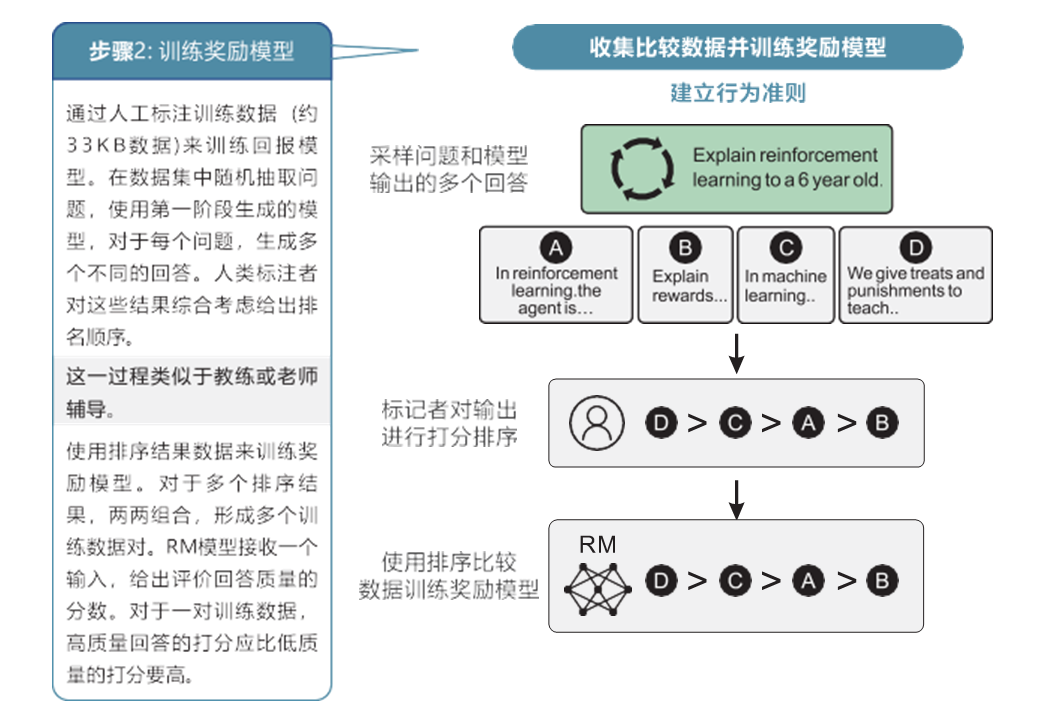
ChatGPT模型训练步骤2
为了训练奖励模型,我们需要准备一组对比数据。对比数据由人工创建,包含了多个对话或文本的对比实例,每个对比实例包含两个或多个不同的模型回复。人工对这些回复进行标注,给出每个回复的质量或好坏的评分。
接下来,我们使用对比数据训练奖励模型。奖励模型可以是一个分类模型,也可以是一个回归模型,它的输入是对话或文本的特征表示,输出是一个评分或奖励。奖励模型的目标是根据输入的对话或文本来预测模型回复的质量。
使用训练好的奖励模型,我们可以对GPT模型的回复进行评分,得到一个奖励值。这个奖励值可以用作强化学习的优化目标,以指导GPT模型在后续的对话中生成更优质的回复。
3. 强化学习RL
在ChatGPT中,强化学习是一种反馈学习方法,利用奖励模型作为强化学习的优化目标,通过使用PPO算法来微调SFT模型。
强化学习通过与环境的交互来学习一种策略,使得模型能够在给定环境下采取最优的行动。在ChatGPT中,环境可以看作是对话系统的对话环境,模型需要根据输入的对话来生成回复,并受到奖励模型提供的奖励信号的指导。
在强化学习中,我们使用PPO算法(Proximal Policy Optimization)来微调SFT模型。PPO算法是一种在强化学习中常用的策略优化算法,旨在寻找最优的行动策略,如图10-9所示。
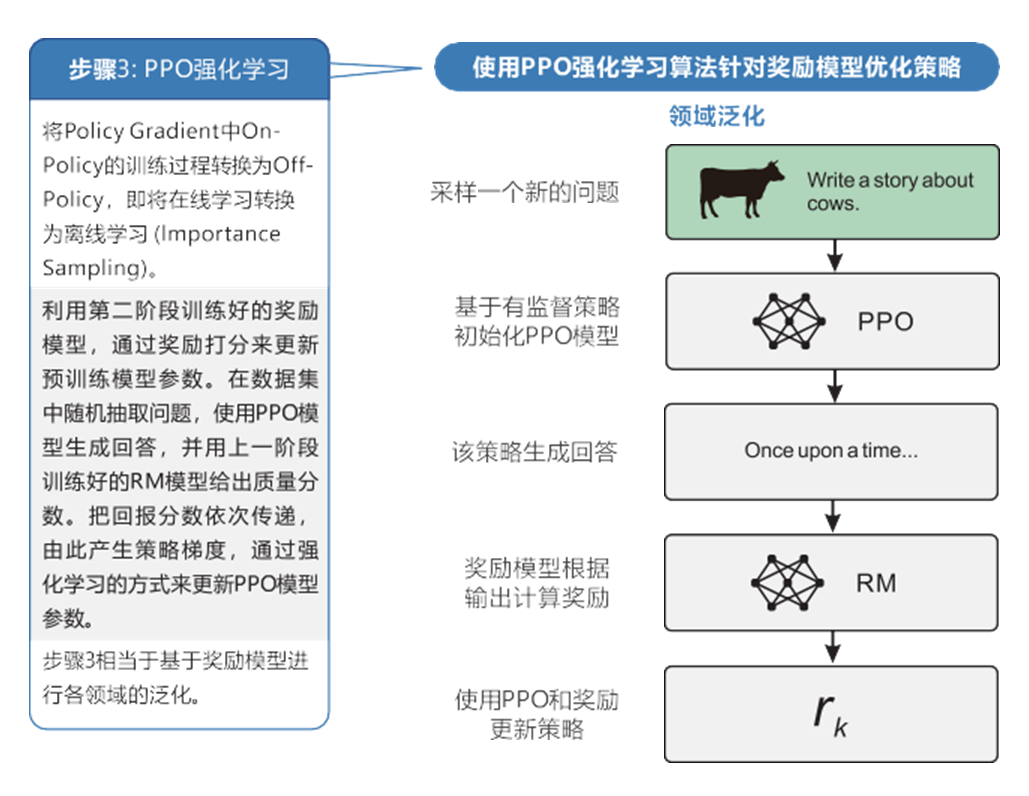
ChatGPT模型训练步骤3
首先,我们使用SFT模型生成对话回复。然后,使用奖励模型对这些回复进行评分,得到一个奖励值。这个奖励值可以指示模型回复的质量和适应度。
接下来,利用PPO算法来微调SFT模型。PPO算法采用基于策略梯度的优化方法,通过最大化期望回报或奖励来更新模型的参数。具体来说,PPO算法使用短期的策略梯度优化模型的策略,以获得更好的回报。通过不断迭代这个过程,模型的策略会逐渐改进,生成更优质的对话回复。
在强化学习中,模型会通过与环境(对话环境)的交互来学习,根据奖励模型提供的奖励信号和PPO算法中的策略梯度更新方法不断调整模型的参数。模型的目标是找到一种策略,使得在给定对话环境下,生成的回复能够获得最大化的奖励或回报。
通过以上三个步骤:模型微调(SFT)、训练奖励模型(RM)、强化学习(RL),ChatGPT可以通过反馈学习方法不断优化和提升,使其在生成对话回复时更准确、合理和人性化。这种反馈学习方法的应用,可以使ChatGPT具备更强的适应性和可控性,让其适应不同的任务和场景,并根据用户的反馈不断改进和提升自身的表现。
ChatGPT是数据科学领域具有革命性和划时代意义的里程碑技术,展望未来,其为大数据和人工智能等技术的新突破、新发展带来无限机遇与挑战。
点击了解更多数据科学相关技术与实践
书籍背景:
本书由百分点科技与清华大学出版社联合出版。百分点科技成立于2009年,是领先的数据科学基础平台及数据智能应用提供商,总部位于北京,在上海、沈阳、深圳、广州、武汉、济南、香港等地设有十八家分子公司,业务覆盖全球多个国家和地区。百分点科技以“用数据科学构建更智能的世界”为使命,为政府和企业提供端到端的场景化解决方案,在数字城市、应急、公安、统计、生态环境、零售快消、媒体报业等多个领域,助力客户智能化转型。百分点科技是国家高新技术企业、北京市企业科技研发机构、全国信标委大数据标准工作组&人工智能分委会成员单位。



![[蓝桥杯 | 暴搜] 学会暴搜之路](https://img-blog.csdnimg.cn/direct/3ffb2a8342f443b59400979335511b44.png)