虚拟文件系统(VFS)的作用
虚拟文件系统(Virtual Filesystem)也可以称之为虚拟文件系统转换(Virtual Filesystem Switch,VFS),
是一个内核软件层,
用来处理与Unix标准文件系统相关的所有系统调用。
其健壮性表现在能为各种文件系统提供一个通用的接口。
VFS支持的文件系统可以划分为三种主要类型:
1.磁盘文件系统
这些文件系统管理在本地磁盘分区中可用的存储空间
或者其他可以起到磁盘作用的设备(比如说一个USB闪存)。
VFS支持的基于磁盘的某些著名文件系统还有:


2.网络文件系统
这些文件系统允许轻易地访问属于其他网络计算机的文件系统所包含的文件。
虚拟文件系统所支持的一些著名的网络文件系统有:
NFS、Coda、AFS(Andrew文件系统)、
CIFS(用于Microsoft Windows的通用网络文件系统)
以及NCP(Novell 公司的NetWare Core Protocol)。
3.特殊文件系统
这些文件系统不管理本地或者远程磁盘空间。
/proc文件系统是特殊文件系统的一个典型范例(参见稍后“特殊文件系统“一节)。根目录包含在根文件系统(root filesystem)中,
在Linux中这个根文件系统通常就是Ext2或Ext3类型。
其他所有的文件系统都可以被“安装“在根文件系统的子目录中基于磁盘的文件系统通常存放在硬件块设备中,
如硬盘、软盘或者CD-ROM。
Linux VFS 的一个有用特点是能够处理如/dev/loop0这样的虚拟块设备,
这种设备可以用来安装普通文件所在的文件系统。
作为一种可能的应用,用户可以保护自己的私有文件系统,
这可以通过把自己文件系统的加密版本存放在一个普通文件中来实现。
通用文件模型
VFS所隐含的主要思想在于引入了一个通用的文件模型(common file model),
这个模型能够表示所有支持的文件系统。
该模型严格反映传统Unix文件系统提供的文件模型。
这并不奇怪,因为Linux希望以最小的额外开销运行它的本地文件系统。
不过,要实现每个具体的文件系统,
必须将其物理组织结构转换为虚拟文件系统的通用文件模型。例如,在通用文件模型中,每个目录被看作一个文件,
可以包含若干文件和其他的子目录。
但是,存在几个非Unix的基于磁盘的文件系统,
它们利用文件分配表(File Allocation Table,FAT)存放每个文件在目录树中的位置,
在这些文件系统中,存放的是目录而不是文件。
为了符合VFS的通用文件模型,
对上述基于FAT的文件系统的实现,
Linux必须在必要时能够快速建立对应于目录的文件。
这样的文件只作为内核内存的对象而存在。从本质上说,
Linux内核不能对一个特定的函数进行硬编码来执行诸如read()或ioct1()这样的操作,
而是对每个操作都必须使用一个指针,指向要访问的具体文件系统的适当函数。
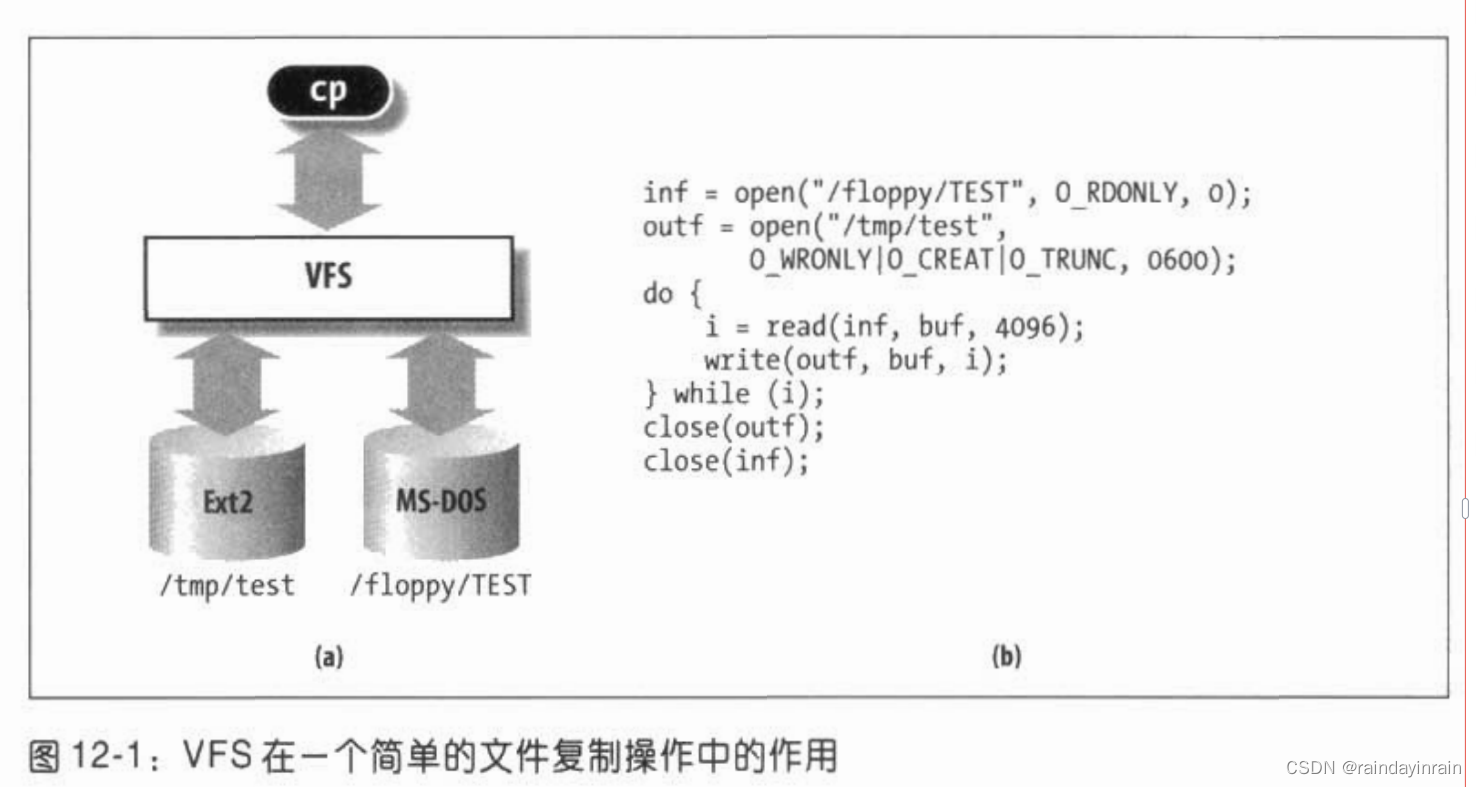
为了进一步说明这一概念,
参见图12-1,其中显示了内核如何把read()转换为专对MS-DOS文件系统的一个调用。
应用程序对read()的调用引起内核调用相应的sys_read()服务例程,
这与其他系统调用完全类似。
我们在本章后面会看到,
文件在内核内存中是由一个file数据结构来表示的。
这种数据结构中包含一个称为f_op的字段,
该字段中包含一个指向专对MS-DOS文件的函数指针,
当然还包括读文件的函数。
sys_read()查找到指向该函数的指针,并调用它。
这样一来,应用程序的read()就被转化为相对间接的调用:
file->f_op->read(...);
与之类似,write()操作也会引发一个与输出文件相关的Ext2写函数的执行。
简而言之,内核负责把一组合适的指针分配给与每个打开文件相关的file变量,
然后负责调用针对每个具体文件系统的函数(由f_op字段指向)。


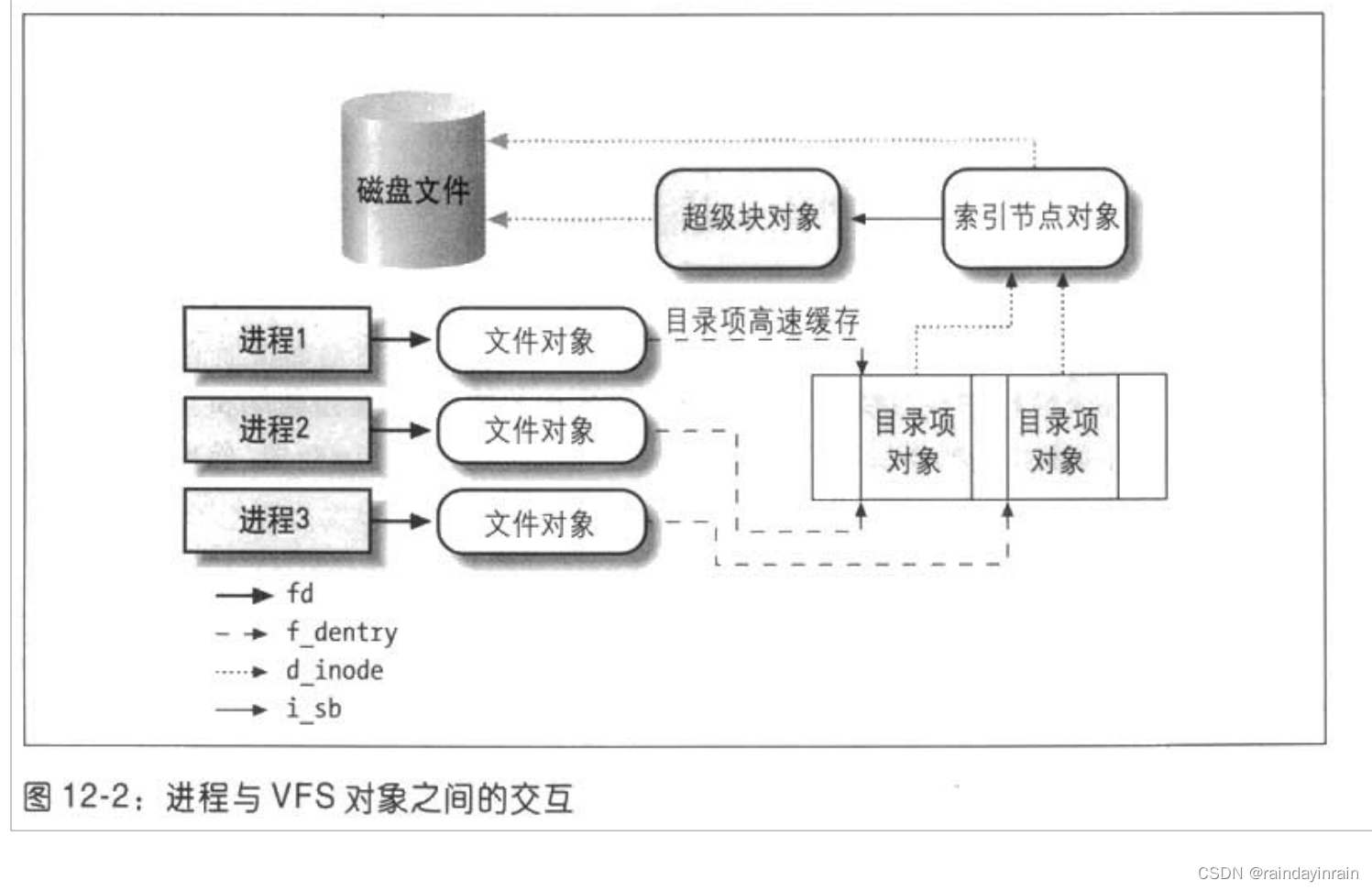
如图12-2所示是一个简单的示例,说明进程怎样与文件进行交互。
三个不同进程已经打开同一个文件,
其中两个进程使用同一个硬链接。
在这种情况下,其中的每个进程都使用自己的文件对象,
但只需要两个目录项对象,
每个硬链接对应一个目录项对象。
这两个目录项对象指向同一个索引节点对象,
该索引节点对象标识超级块对象,以及随后的普通磁盘文件。
VFS除了能为所有文件系统的实现提供一个通用接口外,
还具有另一个与系统性能相关的重要作用。
最近最常使用的目录项对象被放在所谓目录项高速缓存(dentrycache)的磁盘高速缓存中,
以加速从文件路径名到最后一个路径分量的索引节点的转换过程。一般说来,磁盘高速缓存(diskcache)属于软件机制,
它允许内核将原本存在磁盘上的某些信息保存在RAM中,
以便对这些数据的进一步访问能快速进行,而不必慢速访问磁盘本身。注意,磁盘高速缓存不同于硬件高速缓存或内存高速缓存,
后两者都与磁盘或其他设备无关。
硬件高速缓存是一个快速静态RAM,
它加快了直接对慢速动态RAM的请求(参见第二章中的“硬件高速缓存”一节)。
内存高速缓存是一种软件机制,
引入它是为了绕过内核内存分配器(参见第八章中的“slab分配器”一节)。除了目录项高速缓存和索引结点高速缓存之外,
Linux还使用其他磁盘高速缓存。
其中最重要的一种就是所谓的页高速缓存,我们将在第十五章中进行详细介绍。
VFS所处理的系统调用
表12-1列出了VFS的系统调用,
这些系统调用涉及文件系统、普通文件、目录文件以及符号链接文件。
另外还有少数几个由VFS处理的其他系统调用,
诸如ioperm()、ioct1()、pipe()和mknod(),涉及设备文件和管道文件,
这些将在后续章节中讨论。
最后一组由VFS处理的系统调用,
诸如socket()、connect()和bind()属于套接字系统调用,
并用于实现网络功能。
与表12-1列出的系统调用对应的一些内核服务例程,
我们会在本章或第十八章中陆续进行讨论。



前面我们已经提到,
VFS是应用程序和具体文件系统之间的一层。
不过,在某些情况下,一个文件操作可能由VFS本身去执行,无需调用低层函数。
例如,当某个进程关闭一个打开的文件时,并不需要涉及磁盘上的相应文件,
因此VFS只需释放对应的文件对象。
类似地,当系统调用lseek()修改一个文件指针,
而这个文件指针是打开文件与进程交互所涉及的一个属性时,
VFS就只需修改对应的文件对象,而不必访问磁盘上的文件,
因此,无需调用具体文件系统的函数。
从某种意义上说,
可以把VFS看成“通用“文件系统,它在必要时依赖某种具体文件系统。
VFS的数据结构
每个VFS对象都存放在一个适当的数据结构中,
其中包括对象的属性和指向对象方法表的指针。
内核可以动态地修改对象的方法,
因此可以为对象建立专用的行为。下面几节详细介绍VFS的对象及其内在关系。
超级块对象
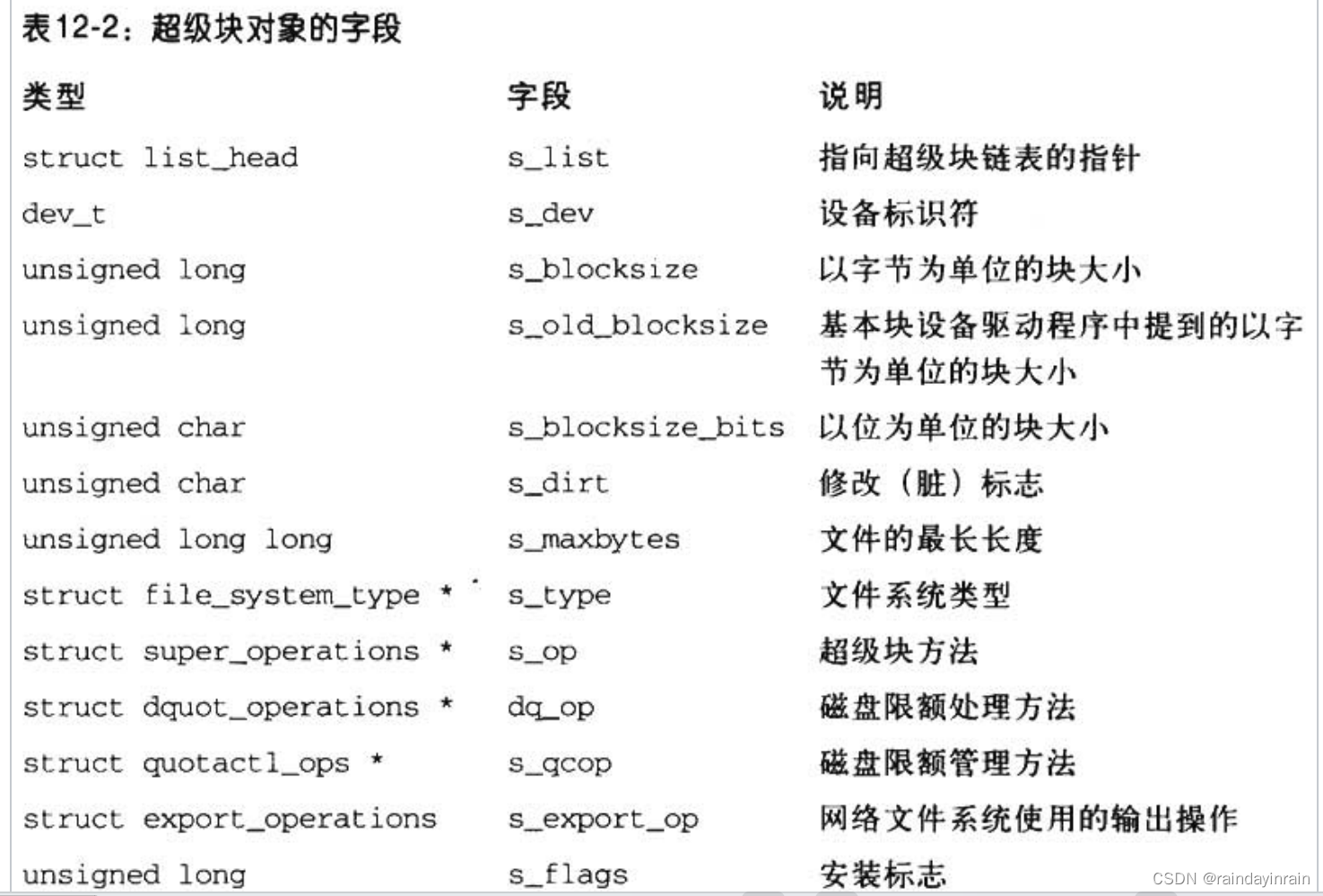
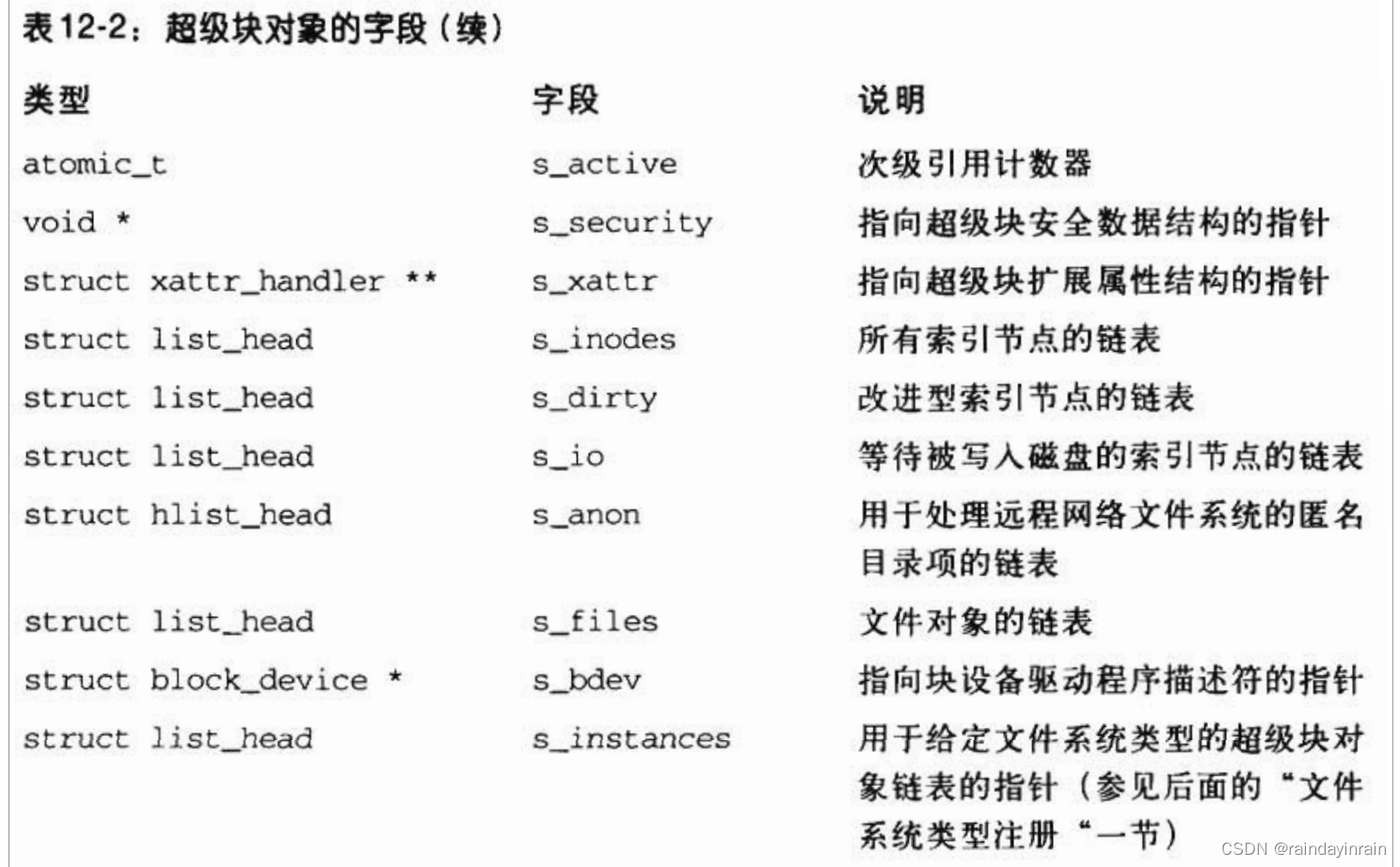
超级块对象由super_block结构组成,表12-2列举了其中的字段。


所有超级块对象都以双向循环链表的形式链接在一起。
链表中第一个元素用super_blocks变量来表示,
而超级块对象的s_list字段存放指向链表相邻元素的指针。
sb_lock自旋锁保护链表免受多处理器系统上的同时访问。s_fs_info字段指向属于具体文件系统的超级块信息;
例如,我们在第十八章将会看到,
假如超级块对象指的是Ext2文件系统,
该字段就指向ext2_sb_info数据结构,
该结构包括磁盘分配位掩码和其他与VFS的通用文件模型无关的数据。
通常,为了效率起见,由s_fs_info字段所指向的数据被复制到内存。
任何基于磁盘的文件系统都需要访问和更改自己的磁盘分配位图,
以便分配或释放磁盘块。
VFS允许这些文件系统直接对内存超级块的s_fs_info字段进行操作,
而无需访问磁盘。但是,这种方法带来一个新问题:
有可能VFS超级块最终不再与磁盘上相应的超级块同步。
因此,有必要引入一个s_dirt标志来表示该超级块是否是脏的
——那磁盘上的数据是否必须要更新。
缺乏同步还会导致产生我们熟悉的一个问题:
当一台机器的电源突然断开而用户来不及正常关闭系统时,
就会出现文件系统崩溃。
我们将会在第十五章的“把脏页写入磁盘“一节中看到,
Linux是通过周期性地将所有“脏“的超级块写回磁盘来减少该问题带来的危害。与超级块关联的方法就是所谓的超级块操作。
这些操作是由数据结构super_operations 来描述的,
该结构的起始地址存放在超级块的s_op字段中。
每个具体的文件系统都可以定义自己的超级块操作。
当VFS需要调用其中一个操作时,比如说read_inode(),
它执行下列操作:
sb->s_op->read_inode(inode);
这里sb存放所涉及超级块对象的地址。
super_operations表的read_inode字段存放这一函数的地址,
因此,这一函数被直接调用。
让我们简要描述一下超级块操作,
其中实现了一些高级操作,
比如删除文件或安装磁盘。
下面这些操作按照它们在super_operation表中出现的顺序来排列:




前述的方法对所有可能的文件系统类型均是可用的。
但是,只有其中的一个子集应用到每个具体的文件系统;
未实现的方法对应的字段置为NULL。
注意,系统没有定义get_super方法来读超级块,
那么,内核如何能够调用一个对象的方法而从磁盘读出该对象?
我们将在描述文件系统类型的另一个对象中找到等价的get_sb方法
(参见后面的“文件系统类型注册“一节)。
索引节点对象
文件系统处理文件所需要的所有信息都放在一个名为索引节点的数据结构中。
文件名可以随时更改,但是索引节点对文件是唯一的,
并且随文件的存在而存在。
内存中的索引节点对象由一个inode数据结构组成,其字段如表12-3所示。
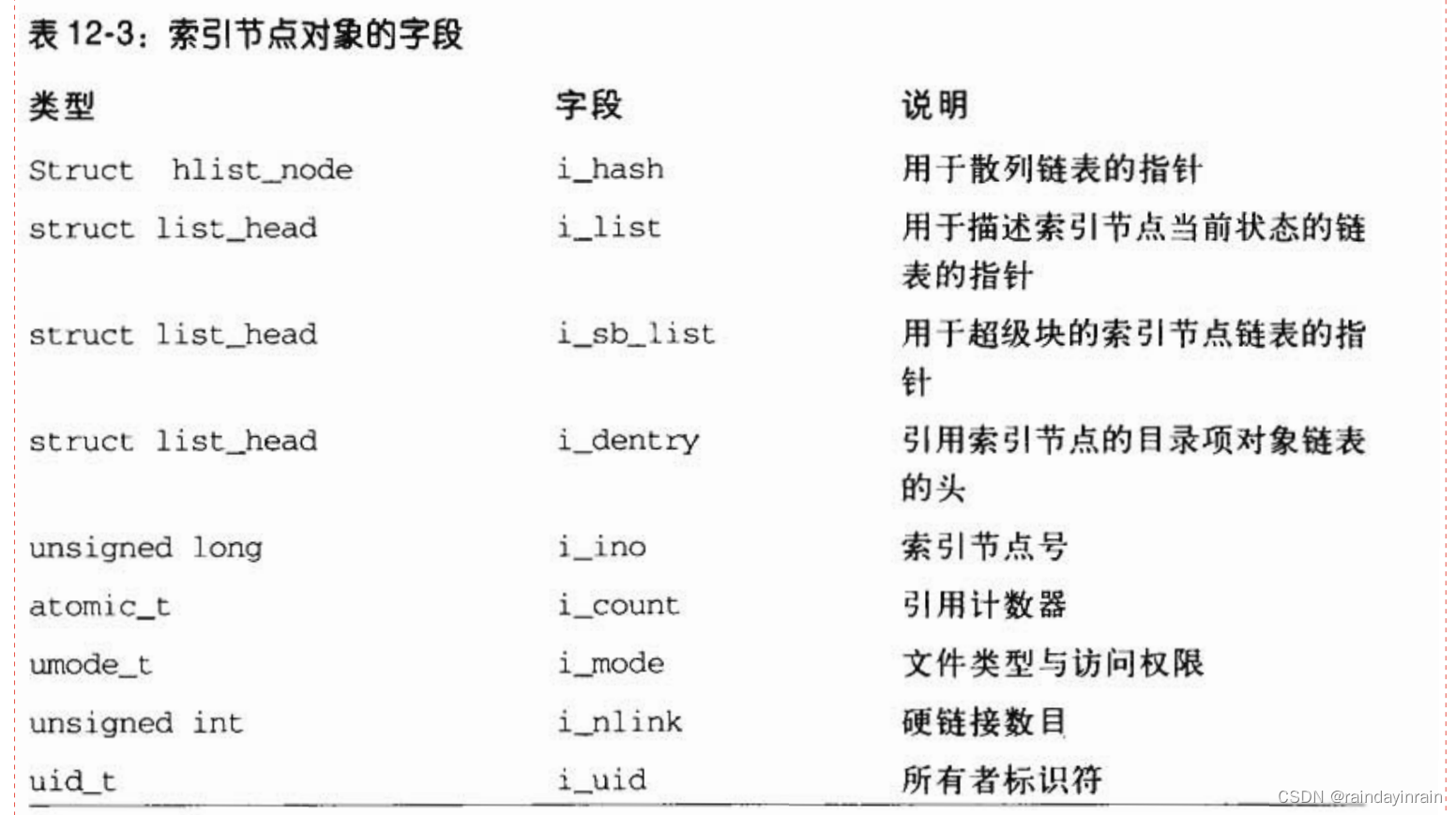


每个索引节点对象都会复制磁盘索引节点包含的一些数据,
比如分配给文件的磁盘块数。
如果i_state字段的值等于I_DIRTY_SYNC、I_DIRTY_DATASYNC或I_DIRTY_PAGES,该索引节点就是“脏“的,
也就是说,对应的磁盘索引节点必须被更新。
I_DIRTY宏可以用来立即检查这三个标志的值(详细内容参见后面)。
i_state字段的其他值有I_LOCK(涉及的索引节点对象处于I/O传送中)、I_FREEING(索引节点对象正在被释放)、
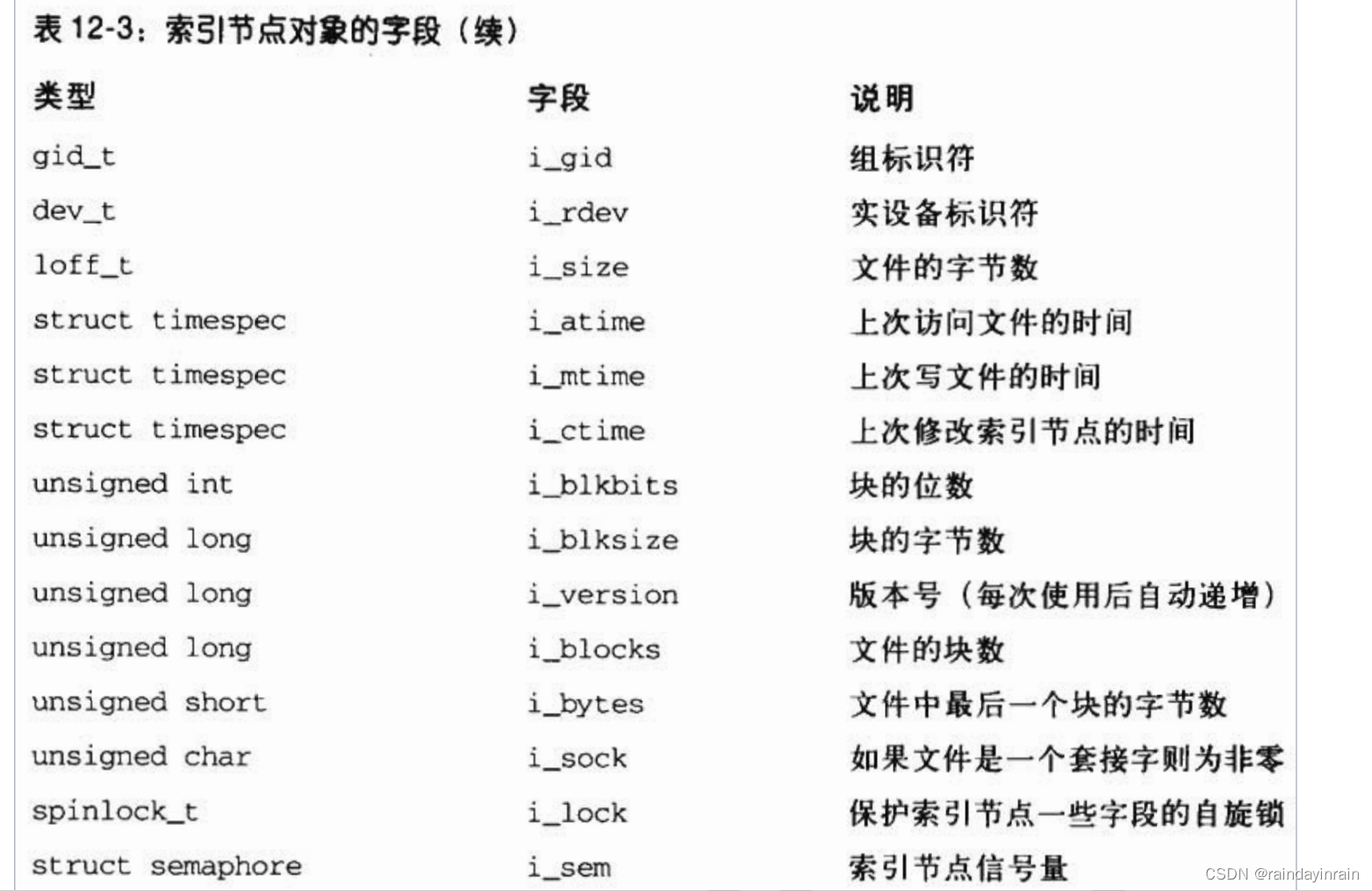
I_CLEAR(索引节点对象的内容不再有意义)以及I_NEW(索引节点对象已经分配但还没有用从磁盘索引节点读取来的数据填充)。每个索引节点对象总是出现在下列双向循环链表的某个链表中(所有情况下,指向相邻元素的指针存放在i_list字段中):
1.有效未使用的索引节点链表,
典型的如那些镜像有效的磁盘索引节点,且当前未被任何进程使用。
这些索引节点不为脏,且它们的i_count字段置为0。
链表中的首元素和尾元素是由变量inode_unused的next字段和prev字段分别指向的。
这个链表用作磁盘高速缓存。
2.正在使用的索引节点链表,也就是那些镜像有效的磁盘索引节点,
且当前被某些进程使用。
这些索引节点不为脏,但它们的i_count字段为正数。
链表中的首元素和尾元素是由变量inode_in_use引用的。
3.脏索引节点的链表。
链表中的首元素和尾元素是由相应超级块对象的s_dirty字段引用的。
这些链表都是通过适当的索引节点对象的i_list字段链接在一起的。此外,每个索引节点对象也包含在每文件系统(per-filesystem)的双向循环链表中,
链表的头存放在超级块对象的s_inodes字段中;
索引节点对象的i_sb_list字段存放了指向链表相邻元素的指针。最后,索引节点对象也存放在一个称为inode_hashtable的散列表中。
散列表加快了对索引节点对象的搜索,
前提是系统内核要知道索引节点号及文件所在文件系统对应的超级块对象的地址。
由于散列技术可能引发冲突,
所以索引节点对象包含一个i_hash字段,
该字段中包含向前和向后的两个指针,
分别指向散列到同一地址的前一个索引节点和后一个索引节点;
该字段因此创建了由这些索引节点组成的一个双向链表。与索引节点对象关联的方法也叫索引节点操作。
它们由inode_operations结构来描述,该结构的地址存放在i_op字段中。
以下是索引节点的操作,以它们在inode_operations表中出现的次序来排列:




上述列举的方法对所有可能的索引节点和文件系统类型都是可用的。
不过,只有其中的一个子集应用到某一特定的索引节点和文件系统;
未实现的方法对应的字段被置为NULL。
文件对象
文件对象描述进程怎样与一个打开的文件进行交互。
文件对象是在文件被打开时创建的,由一个file结构组成,
其中包含的字段如表12-4所示。
注意,文件对象在磁盘上没有对应的映像,因此file结构中没有设置“脏“字段来表示文件对象是否已被修改。
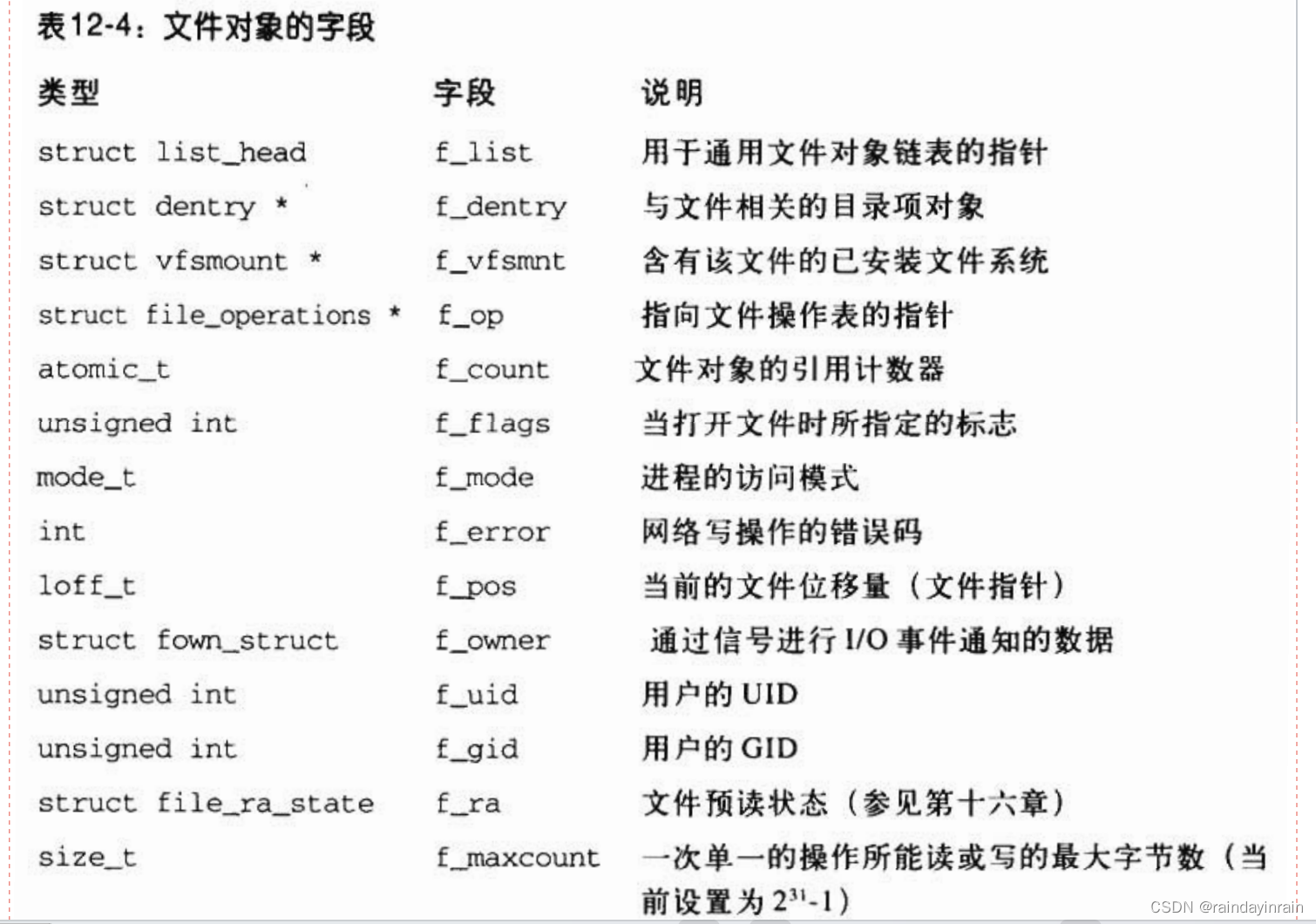

存放在文件对象中的主要信息是文件指针,
即文件中当前的位置,下一个操作将在该位置发生。
由于几个进程可能同时访问同一文件,因此文件指针必须存放在文件对象而不是索引节点对象中。