目录
- 前言
- 泛读
- 摘要
- Introduction
- Related Work
- 小结
- 精读
- Model
- 3.1 学习对齐视觉与语言数据
- 图片表征
- 句子表征
- 对齐目标
- 损失函数
- 解码文本片段对齐图像
- MRNN生成描述
- 优化
- 实验
- 结论
- 代码
前言
本课程来自深度之眼《多模态》训练营,部分截图来自课程视频。
文章标题:Deep Visual-Semantic Alignments for Generating Image Descriptions
用于生成图像描述的深度视觉语义对齐
作者:AK和李飞飞
单位:斯坦福
发表时间:2015 CVPR
看过斯坦福cs231n课程的应该记得,有一次课外作业就是做这个。
泛读
摘要
We present a model that generates natural language descriptions of images and their regions.
开门见山第一句点题,同时也指出本文的目标是that从句中描述的事:我们提出了一个生成图像及其区域的自然语言描述的模型。
Our approach leverages datasets of images and their sentence descriptions to learn about the inter-modal correspondences between language and visual data. Our alignment model is based on a
novel combination of Convolutional Neural Networks over image regions, bidirectional Recurrent Neural Networks over sentences, and a structured objective that aligns the two modalities through a multimodal embedding. We then describe a Multimodal Recurrent Neural Network architecture that uses the inferred alignments to learn to generate novel descriptions of image regions.
用几句话简单介绍模型:我们的方法利用图像数据集及其句子描述来了解语言和视觉数据之间的模态间对应关系。 我们的对齐模型基于图像区域上的卷积神经网络、句子上的双向循环神经网络以及通过多模态嵌入对齐两种模态的结构化目标的新颖组合。 然后,我们描述了一种多模式递归神经网络架构,该架构使用推断的对齐来学习生成图像区域的新描述。
We demonstrate that our alignment model produces state of the art results in retrieval experiments on Flickr8K, Flickr30K and MSCOCO datasets. We then show that the generated descriptions significantly outperform retrieval baselines on both full images and on a new dataset of region-level annotations.
最后描述该模型的结果:我们证明我们的对齐模型在 Flickr8K、Flickr30K 和 MSCOCO 数据集的检索实验中产生了最先进的结果。 然后,我们展示了生成的描述在完整图像和区域级注释的新数据集上都显着优于检索基线。
目前存在的问题:
需要高capability的模型来处理图片信息,生成自然语言
模型需要摆脱硬编码模板和一些固定模式,仅仅从数据中学习
ground-truth数据不能精确到图片中的区域
Introduction
第一段先说对图片进行描述对于人类而言非常简单,但是在视觉识别研究上存在较大缺陷,主要表现在使用预先设置好的固定类别标记图像(类似数字识别、猫狗分类),没法与人类可以更加丰富的描述相提并论。
简单的说就是按照预先设定的分类对图片进行对号入座很容易,但是实际上的图片内容丰富,种类繁多,这样简单的分类是不够的
第二段对现有的解决方法进行总结,批判其不足,凸显自己的创新之处。
Some pioneering approaches that address the challenge of generating image descriptions have been developed.
批判:这些模型通常依赖于硬编码的视觉概念和句子模板,这限制了它们的多样性。
第三段进入主题,讲本文的工作:In our work…
在这项工作中,我们努力朝着生成图片描述的目标迈出一步(如图1)。实现这一目标的首要挑战是设计一个模型,该模型足够丰富,可以同时推理图像的内容及其在自然语言领域中的表示。此外,该模型不应假设特定的硬编码模板、规则或类别,而是依赖于从培训数据中学习。第二个实际挑战是,互联网上有大量即时图像字幕数据集,但这些描述对图像中位置未知的几个实体进行了多重提及。
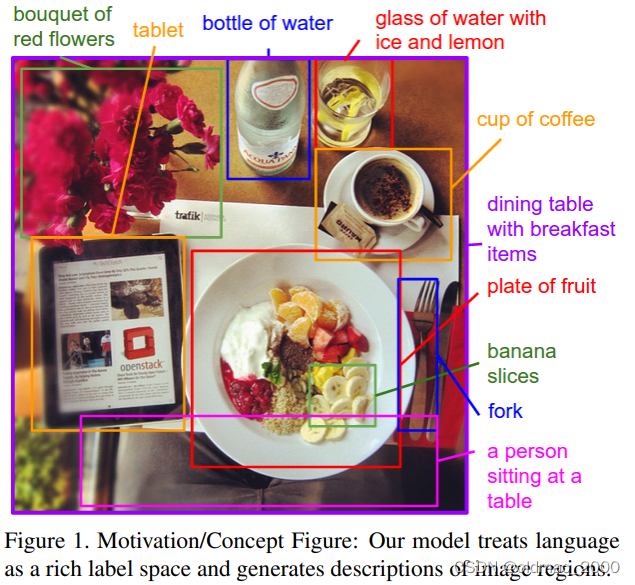
现在的模型对于标注数据非常依赖,生成多样化描述的语句是十分困难的,那我们就要解决这个问题。先是将标注数据中的单词和图片中的
具体物品相对应,把粒度做的更细;然后提出 multi-model RNN 来进行图片标注。
本文核心观点是,通过将句子视为弱标签,我们可以利用这些大型图像句子数据集,其中连续的词段对应于图像中某些特定但未知的位置。我们的方法是推断这些排列,并利用它们来学习描述的生成模型。
也就是解决两个问题:
(1)用文字搜索库中图片、用图片搜索库中的文字。
(2)对图片进行描述(Captioning)
针对要解决的问题(1), 采用了 RCNN + BRNN 框架,首先将图片和文字切成片段,然后将片段图片和片段文字都映射到同一个特征空间,然后利用两个向量在同一空间的相似度来描述整张图片与一段文字的相似度,取相似度较高的结果。
针对要解决的问题(2), 采用了VGGNet + RNN 的框架,开始输入一张图片,然后生成一段话。
Related Work
Dense caption:
我们的工作与我们之前的许多作品一样,都有一个高层次的目标,即密集地注释图像的内容。然而,这些工作的重点是用一组固定的类别正确标记场景、对象和区域,而我们的重点是更丰富和更高层次的区域描述。
说明:这里和introduction说的是一个意思,就是现在的caption都是固定分类,本文要做更丰富的表达。
Generating descriptions:
本文探索了用句子描述图像的任务。许多方法将这项任务视为一个检索问题,将训练集中最匹配的注释转移到测试图像中,或者将训练注释拆散并拼接在一起。有几种方法是根据图像内容或生成语法填充的固定模板生成图像标题,但这种方法限制了可能输出的多样性。与我们关系最密切的是 Kiros 等人开发的对数线性模型,该模型可以生成完整的图片句子说明,但他们的模型使用固定的窗口上下文,而我们的递归神经网络(RNN)模型则将句子中下一个单词的概率分布条件设定为之前生成的所有单词。在这项工作提交期间,Arxiv 上出现了多篇密切相关的预印本,其中一些也使用 RNN 生成图像描述。我们的 RNN 比这些方法中的大多数都要简单,但在性能上也有不足。我们在实验中对这种比较进行了量化。
Grounding natural language in images:
其他工作不细说,最后一句重点:与基于基础依赖树关系的模型相比,我们的模型对齐了句子的多个片段,这些片段更有意义,可解释,长度不固定。
Neural networks in visual and language domains:
在图像方面,卷积神经网络(CNN)最近已成为图像分类和目标检测的一类强大模型。在感知方面,我们的工作利用了预训练的词向量,以获得词的低维表示。最后,递归神经网络先前已用于语言建模,但在图像上对这些模型进行了附加条件。
小结
与最早期的m-RNN等模型相比,本文要leverage每张训练图片和对应的标注,并找出它们的对应关系。我们以前看到的标注都是简短的句子直接描述了一整幅图片的大体信息,对图片中的细节信息,比如包含的物体、动作等都基本上直接忽略,是直接从图像层面进行caption。但是这和人类理解图像的直观感受不一样,人类都是要先看图像中有什么,在做什么,才最终搞懂了他们在干什么。本文即从object detection出发,进行的image caption工作。
精读
Model
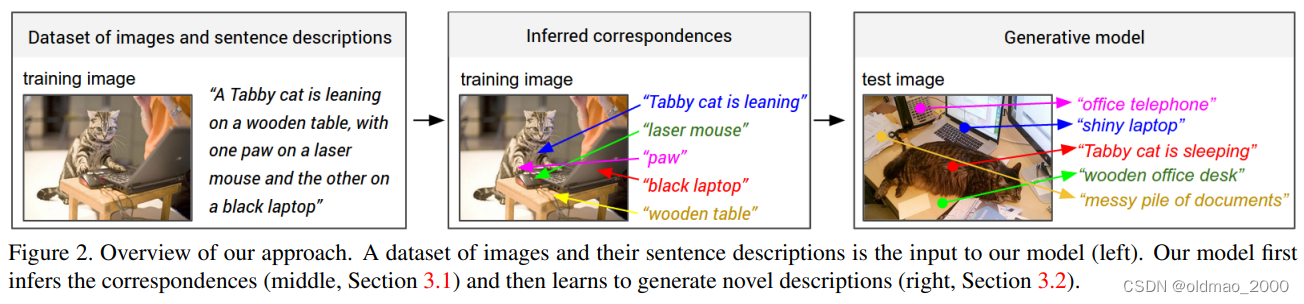
我们模型的最终目标是生成图像区域的描述。 在训练期间,我们模型的输入是一组图像及其对应的句子描述(下图左边部分)。 我们首先提出了一个模型,该模型将句子片段与它们通过多模态嵌入描述的视觉区域对齐(下图中间部分)。 然后,我们将这些对应关系视为第二个多模态递归神经网络模型的训练数据,该模型学习生成片段(下图右边部分)。
3.1 学习对齐视觉与语言数据
Our key insight is that sentences written by people make frequent references to some particular, but unknown location in the image.
人类描述图片时,通常会频繁提及图像中某些特定但未知的位置。
我们的对齐模型假定有一个图像及其句子描述的输入数据集。我们的关键见解是,人们写的句子经常提到图像中某些特定的、但未知的位置。例如,在图2中,"虎皮猫靠着 " 指的是猫,"木桌 "指的是桌子,等等。我们希望推断出这些潜在的对应关系,最终目的是为了模型能够学习从图像区域中生成这些片段。我们以Karpathy等人的方法为基础,他们以排名为目标,学习将依赖树关系植入图像区域。我们的贡献在于使用双向递归神经网络来计算句子中的单词表征,免除了计算依赖树的需要,并允许单词和它们在句子中的上下文进行无限制的交互。我们还大大简化了他们的目标,并表明这两种修改都能提高排名性能。
然后,我们将介绍我们的新目标,即学习嵌入表征,从而使两种模式中语义相似的概念占据空间的邻近区域。
采用了 RCNN + BRNN 框架,首先将图片和文字切成片段,然后将片段图片和片段文字都映射到同一个特征空间,然后利用两个向量在同一空间的相似度来描述整张图片与一段文字的相似度,取相似度较高的结果。
图片表征
本文使用Region CNN(RCNN)来编码图片,CNN在ImageNet上预训练,且在ImageNet Detection Challenge的200类上作了fine-tune, 选择top19的location和整张图片来计算图片的表达(19个local和整个图片一起20个向量),将图片编码成20个的向量。下面是每个向量的计算公式。
v = W m [ C N N θ c ( I b ) ] + b m v=W_m[CNN_{\theta_c}(I_b)]+b_m v=Wm[CNNθc(Ib)]+bm

句子表征
为了建立RCNN所产生的20个h维向量(即图片的20个部分)与给定描述中部分词组的关系,我们还需要把句中的词组也变成h维向量。我们能想到最简单的方法就是把这些单词接投影到向量中,然而这样的方法没有考虑到单词不是与20个图像顺序对应的,同时也没有考虑到单词特定语境下蕴含的其他信息。当然还有一些其他的改进如将单词改为词组,这些方法都不能取得我们理想的效果。
为了解决这个问题,我们需要用到BRNN(双向RNN)。BRNN在把每个单词变为h维向量的同时还会用一个index t t t来记录每个单词在句子中的位置,至于这个 t t t是怎么代表语境下的特殊意义的,我们先来看一下完整的公式:
x t = W w I t e t = f ( W e x t + b e ) h t f = f ( e t + W f h t − 1 f + b f ) h t b = f ( e t + W b h t + 1 b + b b ) s t = f ( w d ( h t f + h t b ) + b d ) \begin{align*}x_t&=W_w \mathbb{I}_t\\ e_t&=f(W_ex_t+b_e)\\ h_t^f&=f(e_t+W_fh_{t-1}^f+b_f)\\ h_t^b&=f(e_t+W_bh_{t+1}^b+b_b)\\ s_t&=f(w_d(h_t^f+h_t^b)+b_d) \end{align*} xtethtfhtbst=WwIt=f(Wext+be)=f(et+Wfht−1f+bf)=f(et+Wbht+1b+bb)=f(wd(htf+htb)+bd)
第一个公式里的 I t \mathbb{I}_t It是一个列向量指示器,在单词表的第t个单词的索引都有一个值。用 word2vec 将单词转为300维的向量表示,即权重 W w W_w Ww。这一步是准备工作,到了第二个公式则是将这些一股脑儿输入进BRNN模型里面。而公式三四代表着BRNN中的两个方向的RNN,最后得出的 s t s_t st中既包含了单词的位置,又包含在语境中的特殊含义,在最后用ReLU作为激活函数。
对齐目标
有了前面的两步,我们已经分别将图片与描述都转为h维向量,接下来就是要两两对应了。本文提出一种得分机制来当作不同单词在各个区域的得分。最匹配的对应关系当然是所有对应的总得分最高的时候。那么这个得分是如何计算的呢?
这里该文章作者借用另外一篇文章的计算方法,即计算第i个图像部分的向量表示与第 t t t个单词的点积,然后通过下面这个公式来定义最终得分:
S k l = ∑ t ∈ g l ∑ i ∈ g k m a x ( 0 , v i T s t ) S_{kl}=\sum_{t\in g_l}\sum_{i\in g_k}max(0,v_i^Ts_t) Skl=t∈gl∑i∈gk∑max(0,viTst)
其中 g k g_k gk与 g l g_l gl分别为图片k与句子l中的片段。连同其附加的“多实例学习”目标一起,该分数可解释为只要点积为正,句子片段就会与图像区域的子集对齐。当然,作者还对此公式进行了简化,同时减轻了对其他目标及其超参数的需求。
S k l = ∑ t ∈ g l m a x i ∈ g k v i T s t S_{kl}=\sum_{t\in g_l}max_{i\in g_k}v_i^Ts_t Skl=t∈gl∑maxi∈gkviTst
损失函数
C ( θ ) = ∑ k [ ∑ l m a x ( 0 , S k l − S k k + 1 ) ⏟ rank images + ∑ l m a x ( 0 , S l k − S k k + 1 ) ⏟ rank sentences ] \mathit{C}(\theta)=\sum_k[\underset{\text{rank images}}{\underbrace{\sum_lmax(0,S_{kl}-S_{kk}+1)}}+\underset{\text{rank sentences}}{\underbrace{\sum_lmax(0,S_{lk}-S_{kk}+1)}}] C(θ)=k∑[rank images l∑max(0,Skl−Skk+1)+rank sentences l∑max(0,Slk−Skk+1)]
上式里面有 S l k S_{lk} Slk,这就解释了刚才的优化为什么只针对每个图像最大的点积,这个 S l k S_{lk} Slk则是针对每个句子片段的最大点积,而 S k k S_{kk} Skk是一个得分标准。后面的+1是为防止没有与标准值特别符合的(因为点积和大于0即代表合格,分越大越好),便只能从不合格里面选出最接近的了(打篮球高个子不够,只能从矮个子里面选最高的),当然又不能点积分过低,于是实在找不到就从点积和(-1,0)之间找个最好的。
解码文本片段对齐图像
将单词与候选框进行对应的过程中,存在很多单词(句子片段)对应一个候选框的情况,作者在这里用马尔可夫随机场来解决这个问题。因为一个region对应一个word当然不行啊,而且word会毫无规律地分给region,这样跑出来的结果难以看懂。于是又使用了马尔可夫随机场进行进一步的修正,使得每一个region可以对应一小句解释。
由于我们最终对生成文本片段而不是单个单词感兴趣,因此我们希望将单词的扩展、连续序列对齐到单个边界框。现在出现另外一个问题,我们光是追求讲每个单词放入得分最高的区域是不行的,这会导致单词会没有意义地分散开来。
要解决这个问题,我们将真正的配对视为马尔可夫随机场(MRF)中的潜在变量,这个马尔可夫随机场其实就是对相邻单词在同一图片区域比对有额外加分。那么给定N个单词与M个边界的图片,我们用如下公式来顺着句子用一个链式结构来建立一个马尔可夫随机场(MRF):
E ( a ) = ∑ j = 1 ⋯ N ψ j U ( a j ) + ∑ j = 1 ⋯ N − 1 ψ j B ( a j , a j + 1 ) ψ j U ( a j = t ) = v i T s t ψ j B ( a j , a j + 1 ) = β I [ a j = a j + 1 ] E(\mathbf{a})=\sum_{j=1\cdots N}\psi_j^U(a_j)+\sum_{j=1\cdots N-1}\psi_j^B(a_j,a_{j+1})\\ \psi_j^U(a_j=t)=v_i^Ts_t\\ \psi_j^B(a_j,a_{j+1})=\beta\mathbb{I}[a_j=a_{j+1}] E(a)=j=1⋯N∑ψjU(aj)+j=1⋯N−1∑ψjB(aj,aj+1)ψjU(aj=t)=viTstψjB(aj,aj+1)=βI[aj=aj+1]
其中,超参数 β β β是用来对较长词组会有额外加分,即鼓励尽量用多单词的词组进行匹配。这个参数的设置允许在只有一个单词对应时( β = 0 β=0 β=0)进行另外插值,当 β β β很大时允许将整个句子对应到某个得分最高的区域。最终输出是一组带有文本片段的图像区域。
MRNN生成描述
这一节主要解决第二个问题,该问题关键在于模型的设计,而该模型在收到一张图片后能预测出可变长度的输出序列。在写这篇文章前类似这样的工作是这样做的:给定一个单词以及先前时间步的其他语境意义时,定义该输出序列中下一个单词的概率分布。作者在此基础上做了一个简单有效的扩展,即额外训练输入图像内容的生成过程。
b v = W h i [ C N N θ c ( I ) ] h t = f ( W h x x t + W h h h t − 1 + b h + I ( t = 1 ) ⊙ b v ) y t = s o f t m a x ( W o h h t + b o ) \begin{align*}b_v&=W_{hi}[CNN_{\theta_c}(I)]\\ h_t&=f(W_{hx}x_t+W_{hh}h_{t-1}+b_h+\mathbb{I}(t=1)\odot b_v)\\ y_t&=softmax(W_{oh}h_t+b_o) \end{align*} bvhtyt=Whi[CNNθc(I)]=f(Whxxt+Whhht−1+bh+I(t=1)⊙bv)=softmax(Wohht+bo)
x t x_t xt为t时刻的输入; h t h_t ht为t时刻的语境意义,会带入到t+1时刻计算; y t y_t yt为下一个输出单词。
从下图可以直观地看出RNN地训练过程:每一步RNN都接受上一步的单词与语境义,同时在句中下一个单词基础上定义一个分布。RNN在第一个时间步的输入取决于图像信息。
要注意的是训练的时候每一时刻输入的是标准答案,测试的时候的输入是上一时刻概率最大的单词。

就是图片经过VGG,得到结果加上START再经过RNN得到描述。
优化
我们使用 SGD 和 100 个图像-句子对的小批量和 0.9 的动量来优化对齐模型。 我们交叉验证学习率和权重衰减。 我们还在所有层中使用 dropout 正则化,除了循环层 和在 5 处逐元素裁剪梯度(重要)。 由于稀有词和常用词(例如“a”或 END 标记)之间的词频差异,生成 RNN 更难以优化。 我们使用 RMSprop 取得了最好的结果,这是一种自适应步长方法,通过其梯度范数的运行平均值来缩放每个权重的更新。
实验
用了三个数据集:Flickr8K、Flickr30K 和 MSCOCO,分别包含8000、31000、123000张图片,每张图片都有五句描述。对于Flickr8K 和 Flickr30K 采用1000张图片作为验证集,1000张图片作为测试集。对于MSCOCO采用5000张图片作为验证集,5000张作为测试集。
预处理:将所有句子转为小写,然后选取出现不少于五次的单词,对于三个数据集分别得到 2538,7414,8791个单词。
用图片搜句子和用句子搜图片得到的结果是:
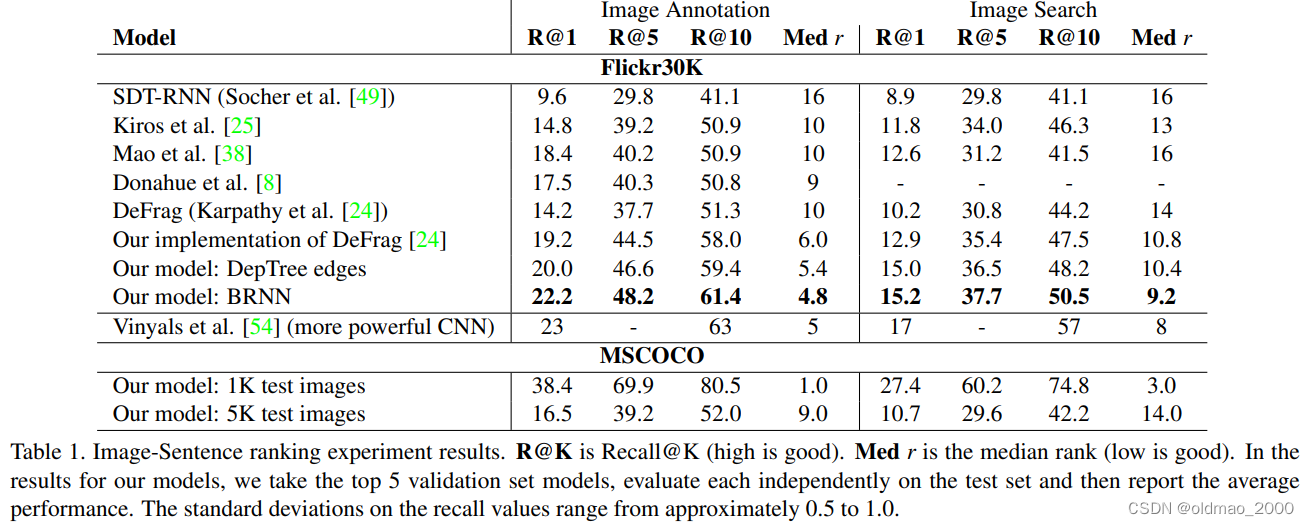
表1中前面三个是recall K指标,就是看前K个查找结果是否与ground truth对应,因此K越大结果越大,结果越大越好,说明命中率越高。
对齐预测结果:

还有两个小节分别从Fulframe和Region两个方面将模型与其他工作进行了比较,中规中矩的给出了陈述,值得借鉴。
最后还给出了Limitation,这个也是很多审稿人要求的一个部分,甚至还需要给出大概的解决方案。
结论
1.提出了描述性的区域对应,并达到sota;
2.描述了一种RNN框架,用来生成图像描述。
代码
当时论文发表时代码是neuraltalk,后来AK在16年改版升级到neuraltalk2(python 2.x+torch)。
misc下的utils.lua,lua是用c编写的脚本文件,这个文件主要包含读写json文件,获取指定opt选项等功能。还有将dic他中键值对中的值替换为平均值的操作(dict_average);统计KEY的个数(count_keys)
net_utils.lua,这个文件主要是使用caffe框架创建VGG模型,当然这里面用到了上面utils的函数。
DataLoader.lua加载数据
lstm.lua,大神手搓的LSTM
LanguageModel.lua:图片生成caption模型
其他训练和test的细节看KA的github
https://github.com/karpathy/neuraltalk2