Softmax 是深度学习模型中的常见算子。PyTorch 的 Softmax 算子直接调用 cuDNN 的接口。而 OneFlow 内部针对输入数据的类别数量,采用3个 kernel 来分别处理,在多数情况下都可以获得比 cuDNN 更优的性能表现。测试结果可见 如何实现一个高效的Softmax CUDA kernel?——OneFlow 性能优化分享。下面对其实现进行介绍。OneFlow 的静态分层结构如下图所示:
softmax
oneflow.nn.functional.softmax 直接调用了 C++的实现。
# ref https://github.com/pytorch/pytorch/blob/master/torch/nn/functional.py
def softmax(input: Tensor, dim: Optional[int] = None, dtype=None) -> Tensor:r"""Applies a softmax function.Softmax is defined as::math:`\text{Softmax}(x_{i}) = \frac{\exp(x_i)}{\sum_j \exp(x_j)}`It is applied to all slices along dim, and will re-scale them so that the elementslie in the range `[0, 1]` and sum to 1.See :class:`~oneflow.nn.Softmax` for more details.Args:input (Tensor): inputdim (int): A dimension along which softmax will be computed.dtype (:class:`oneflow.dtype`, optional): the desired data type of returned tensor.If specified, the input tensor is casted to :attr:`dtype` before the operationis performed. This is useful for preventing data type overflows. Default: None... note::This function doesn't work directly with NLLLoss,which expects the Log to be computed between the Softmax and itself.Use log_softmax instead (it's faster and has better numerical properties)."""if dtype is None:ret = flow._C.softmax(input, dim)else:ret = flow._C.softmax(input.to(dtype), dim)return ret
在 OneFlow 系统中存在两类算子(op):系统 op 和 user op。OneFlow user op 的定义及 kernel 实现分别在 oneflow/user/ops 和 oneflow/user/kernels 目录下。
OneFlow_SoftmaxOp
def OneFlow_SoftmaxOp : OneFlow_BaseOp<"softmax", [NoMemoryEffect, DeclareOpInterfaceMethods<UserOpCompatibleInterface>]> {let input = (insOneFlow_Tensor:$in);let output = (outsOneFlow_Tensor:$out);let has_logical_tensor_desc_infer_fn = 1;let has_physical_tensor_desc_infer_fn = 1;let has_get_sbp_fn = 1;let has_data_type_infer_fn = 1;let has_compute_complexity_fn = 1;
}
Functor 层作为 OneFlow 的基础设施,为 python 端和 C++端提供了 op 操作的统一入口。各种 op 在 Functor 层需要完成对输入tensor 的 shape、dtype、维度、元素个数等各种 check,以及对 op 特有的逻辑进行解析和处理。
oneflow/core/functional/impl/activation_functor.cpp 文件中 ONEFLOW_FUNCTION_LIBRARY 将 SoftmaxFunctor 注册为 Softmax 的实现。
SoftmaxFunctor
OpBuilder 用于构建 UserOp。
class SoftmaxFunctor : public SoftmaxFunctorBase {public:SoftmaxFunctor() {op_ = CHECK_JUST(one::OpBuilder("softmax").Input("in").Output("out").Build());}
};
SoftmaxFunctorBase
Tensor::shape 返回输入的 Shape。
Shape::NumAxes 调用 oneflow::Shape::NumAxes 返回维数。
class SoftmaxFunctorBase {public:Maybe<Tensor> operator()(const std::shared_ptr<one::Tensor>& input,const Optional<int64_t>& dim) const {const auto input_shape = input->shape();const int64_t num_axes = input_shape->NumAxes();
get_dim函数判断输入形状是否为2维。
const auto get_dim = [num_axes]() -> int64_t {const int64_t ndim = num_axes;if (ndim == 0 || ndim == 1 || ndim == 3) {return 0;} else {return 1;}};
JUST 宏能够得到表达式。
如果dim为0直接赋值给dim_,否则调用get_dim函数。
maybe_wrap_dim 的处理是支持正负数的。
如果dim_不是最后一维,在其前后调用 Transpose 进行转换。
sequence_function 宏创建一个 SequenceFunction 对象。
TransposeFunctor 为 Transpose 算子的实现。
OpInterpUtil::Dispatch 调度算子到设备上进行计算。
int64_t dim_ = dim ? JUST(dim) : get_dim();dim_ = JUST(maybe_wrap_dim(dim_, num_axes));if (dim_ != num_axes - 1) {std::vector<int> input_perm(input_shape->dim_vec().size(), 0);for (size_t i = 1; i < input_perm.size(); ++i) { input_perm[i] = i; }input_perm[dim_] = input_perm[input_perm.size() - 1];input_perm[input_perm.size() - 1] = dim_;return sequence_function(functional::Transpose).then([&](const std::shared_ptr<one::Tensor>& x) {return OpInterpUtil::Dispatch<Tensor>(*op_, {x});}).then(std::bind(functional::Transpose, std::placeholders::_1, input_perm)).call(input, input_perm);}return OpInterpUtil::Dispatch<Tensor>(*op_, {input});}
包含一个 OpExpr 指针。后者维护了op_name、input arg、output arg 信息。
protected:SoftmaxFunctorBase() = default;virtual ~SoftmaxFunctorBase() = default;std::shared_ptr<OpExpr> op_;
};
SoftmaxKernel
REGISTER_USER_KERNEL 可以注册 softmax kernel。
class SoftmaxKernel final : public user_op::OpKernel, public user_op::CudaGraphSupport {public:SoftmaxKernel() = default;~SoftmaxKernel() override = default;private:using user_op::OpKernel::Compute;
SoftmaxKernel::Compute
UserKernelComputeContext::Tensor4ArgNameAndIndex 根据参数名和索引返回对应的 Tensor。
BlobTensorView::shape_view 得到 ShapeView。
ConstShapeMixIn::NumAxes 得到维数。
NewSoftmaxPrimitive 函数创建一个 Softmax 对象。
调用 SoftmaxImpl::Launch 函数。
void Compute(user_op::KernelComputeContext* ctx) const override {const user_op::Tensor* in = ctx->Tensor4ArgNameAndIndex("in", 0);user_op::Tensor* out = ctx->Tensor4ArgNameAndIndex("out", 0);const ShapeView& in_shape = in->shape_view();const int64_t cols = in_shape.At(in_shape.NumAxes() - 1);const int64_t rows = in_shape.Count(0, in_shape.NumAxes() - 1);std::unique_ptr<ep::primitive::Softmax> primitive = NewSoftmaxPrimitive(ctx);CHECK(primitive);primitive->Launch(ctx->stream(), rows, cols, in->dptr(), out->mut_dptr());}bool AlwaysComputeWhenAllOutputsEmpty() const override { return false; }
};
NewSoftmaxPrimitive
NewPrimitive 使用 SoftmaxFactory 抽象工厂来创建。
template<typename Context>
std::unique_ptr<ep::primitive::Softmax> NewSoftmaxPrimitive(Context* ctx) {const DataType data_type = ctx->TensorDesc4ArgNameAndIndex("in", 0)->data_type();return ep::primitive::NewPrimitive<ep::primitive::SoftmaxFactory>(ctx->device_type(), data_type);
}
SoftmaxFactory
REGISTER_PRIMITIVE_FACTORY 宏会调用 REGISTER_CLASS 实例化一个 AutoRegistrationFactory::RawRegisterType 对象。
工厂的实现为 SoftmaxFactoryImpl,即 GenericSoftmaxFactoryImpl 模板类。GenericSoftmaxFactoryImpl 会调用 NewSoftmax 函数创建一个 SoftmaxImpl 对象。SoftmaxImpl 即 Softmax 的实现。
class SoftmaxFactory : public Factory<Softmax> {public:OF_DISALLOW_COPY_AND_MOVE(SoftmaxFactory);SoftmaxFactory() = default;~SoftmaxFactory() override = default;virtual std::unique_ptr<Softmax> New(DataType data_type) = 0;
};
SoftmaxImpl
SoftmaxImpl::Launch 函数调用 SoftmaxGpu
template<typename SoftmaxBase, Algorithm algorithm, typename T>
class SoftmaxImpl : public SoftmaxBase {public:OF_DISALLOW_COPY_AND_MOVE(SoftmaxImpl);SoftmaxImpl() = default;~SoftmaxImpl() override = default;void Launch(Stream* stream, size_t rows, size_t cols, const void* x, void* y) override {cudaStream_t cuda_stream = stream->As<CudaStream>()->cuda_stream();SoftmaxGpu<algorithm, T>(cuda_stream, rows, cols, reinterpret_cast<const T*>(x),reinterpret_cast<T*>(y));}
};
SoftmaxGpu
DefaultComputeType 默认使用原有类型,对于half和bfloat16使用float类型。
DirectLoad 和 DirectStore 结构体封装了源和目的片外地址。DirectLoad 首先加载源数据到临时变量中,然后转换为片上计算类型。
如果计算类型和源数据类型一致,是否还有必要使用临时变量来存储呢?
根据算法选择调用 DispatchSoftmax 或者 DispatchLogSoftmax 函数。
template<Algorithm algorithm, typename T>
void SoftmaxGpu(cudaStream_t cuda_stream, size_t rows, size_t cols, const T* x, T* y) {using ComputeType = typename cuda::softmax::DefaultComputeType<T>::type;oneflow::cuda::softmax::DirectLoad<T, ComputeType> load(x, cols);oneflow::cuda::softmax::DirectStore<ComputeType, T> store(y, cols);if (algorithm == Algorithm::kSoftmax) {OF_CUDA_CHECK((cuda::softmax::DispatchSoftmax<decltype(load), decltype(store), ComputeType>(cuda_stream, load, store, rows, cols)));} else if (algorithm == Algorithm::kLogSoftmax) {OF_CUDA_CHECK((cuda::softmax::DispatchLogSoftmax<decltype(load), decltype(store), ComputeType>(cuda_stream, load, store, rows, cols)));} else {UNIMPLEMENTED();}
}
DirectLoad
Pack 是一个联合体。
一次性读取N个元素,然后逐个按照DST类型赋值到dst中。
template<typename SRC, typename DST>
struct DirectLoad {DirectLoad(const SRC* src, int64_t row_size) : src(src), row_size(row_size) {}template<int N>__device__ void load(DST* dst, int64_t row, int64_t col) const {Pack<SRC, N> pack;const int64_t offset = (row * row_size + col) / N;pack.storage = *(reinterpret_cast<const PackType<SRC, N>*>(src) + offset);
#pragma unrollfor (int i = 0; i < N; ++i) { dst[i] = static_cast<DST>(pack.elem[i]); }}const SRC* src;int64_t row_size;
};
Pack
PackType 为 GetPackType
template<typename T, int N>
union Pack {static_assert(sizeof(PackType<T, N>) == sizeof(T) * N, "");__device__ Pack() {// do nothing}PackType<T, N> storage;T elem[N];
};
GetPackType
类std::aligned_storage对象构造完成时,即分配了长度为Len个字节的内存,且该内存满足大小为 Align 的对齐要求。
template<typename T, int N>
struct GetPackType {using type = typename std::aligned_storage<N * sizeof(T), N * sizeof(T)>::type;
};
DirectStore
template<typename SRC, typename DST>
struct DirectStore {DirectStore(DST* dst, int64_t row_size) : dst(dst), row_size(row_size) {}template<int N>__device__ void store(const SRC* src, int64_t row, int64_t col) {Pack<DST, N> pack;const int64_t offset = (row * row_size + col) / N;
#pragma unrollfor (int i = 0; i < N; ++i) { pack.elem[i] = static_cast<DST>(src[i]); }*(reinterpret_cast<PackType<DST, N>*>(dst) + offset) = pack.storage;}DST* dst;int64_t row_size;
};
DispatchSoftmax
计算类型不是double的实现:
- 列数小于1024,则调用 DispatchSoftmaxWarpImpl;
- 否则调用 TryDispatchSoftmaxBlockSMemImpl;
- 如果 share memory 版本失败则调用 DispatchSoftmaxBlockUncachedImpl。
3种实现首先根据cols的奇偶确定pack_size为1或2。
DispatchSoftmaxWarpImplCols 根据cols的大小确定cols_per_thread、thread_group_width和rows_per_access3个参数的取值:
- 类别数量较小时,Warp 内对线程进一步分组来处理,每组处理1或2行数据,每个线程处理
pack_size个类别; - 类别数量较大时,Warp 内所有线程处理1行数据,每个线程处理
cols_per_thread个类别。
DispatchSoftmaxWarpImplPadding 根据cols是否能对齐 Warp 处理宽度确定是否需要对cols进行padding处理。
LaunchSoftmaxWarpImpl 中设置block_size为128,再根据不同硬件设置grid_size。
TryDispatchSoftmaxBlockSMemImplPackSize 调用 TryDispatchSoftmaxBlockSMemImplBlockSize 函数,cols为偶数时单次次处理两列,否则处理1列。
TryDispatchSoftmaxBlockSMemImplBlockSize 在给定硬件约束下确保 SM 可调度线程块数量最大,然后优选较大的block_size。
DispatchSoftmaxBlockUncachedImplPackSize 根据cols为奇数或者偶数调用 LaunchSoftmaxBlockUncachedImpl。
template<typename LOAD, typename STORE, typename ComputeType>
inline typename std::enable_if<!std::is_same<ComputeType, double>::value, cudaError_t>::type
DispatchSoftmax(cudaStream_t stream, LOAD load, STORE store, const int64_t rows,const int64_t cols) {if (cols <= 1024) {return DispatchSoftmaxWarpImpl<LOAD, STORE, ComputeType, Algorithm::kSoftmax>(stream, load, store, rows, cols);} else {bool dispatch_smem_impl_success;{cudaError_t err =TryDispatchSoftmaxBlockSMemImpl<LOAD, STORE, ComputeType, Algorithm::kSoftmax>(stream, load, store, rows, cols, &dispatch_smem_impl_success);if (err != cudaSuccess) { return err; }}if (!dispatch_smem_impl_success) {return DispatchSoftmaxBlockUncachedImpl<LOAD, STORE, ComputeType, Algorithm::kSoftmax>(stream, load, store, rows, cols);}return cudaSuccess;}
}
DispatchSoftmax
计算类型为double,则直接调用 DispatchSoftmaxBlockUncachedImpl。
template<typename LOAD, typename STORE, typename ComputeType>
inline typename std::enable_if<std::is_same<ComputeType, double>::value, cudaError_t>::type
DispatchSoftmax(cudaStream_t stream, LOAD load, STORE store, const int64_t rows,const int64_t cols) {return DispatchSoftmaxBlockUncachedImpl<LOAD, STORE, ComputeType, Algorithm::kSoftmax>(stream, load, store, rows, cols);
}
DispatchSoftmaxWarpImplCols
pack_size为1的版本。
template<typename LOAD, typename STORE, typename ComputeType, int pack_size, Algorithm algorithm>
typename std::enable_if<pack_size == 1, cudaError_t>::type DispatchSoftmaxWarpImplCols(cudaStream_t stream, LOAD load, STORE store, const int64_t rows, const int64_t cols) {if (cols <= 0) { return cudaErrorInvalidValue; }
DEFINE_ONE_ELIF宏尝试找到一个刚好能处理cols的thread_group_width值,然后以此调用 DispatchSoftmaxWarpImplPadding 函数。
#define DEFINE_ONE_ELIF(thread_group_width) \else if (cols <= (thread_group_width)*pack_size) { \if (rows % 2 == 0) { \return DispatchSoftmaxWarpImplPadding<LOAD, STORE, ComputeType, pack_size, pack_size, \thread_group_width, 2, algorithm>(stream, load, store, \rows, cols); \} else { \return DispatchSoftmaxWarpImplPadding<LOAD, STORE, ComputeType, pack_size, pack_size, \thread_group_width, 1, algorithm>(stream, load, store, \rows, cols); \} \}DEFINE_ONE_ELIF(1)DEFINE_ONE_ELIF(2)DEFINE_ONE_ELIF(4)DEFINE_ONE_ELIF(8)DEFINE_ONE_ELIF(16)DEFINE_ONE_ELIF(32)
#undef DEFINE_ONE_ELIF
kWarpSize 为线程束大小。
如果超过了单个 Warp 的处理能力,则找到刚好可以处理cols时每个 Warp 内的列数,然后仍然调用 DispatchSoftmaxWarpImplPadding 函数。
#define DEFINE_ONE_ELIF(col) \else if (cols <= (col)*kWarpSize) { \return DispatchSoftmaxWarpImplPadding<LOAD, STORE, ComputeType, pack_size, col, kWarpSize, 1, \algorithm>(stream, load, store, rows, cols); \}DEFINE_ONE_ELIF(2)DEFINE_ONE_ELIF(3)DEFINE_ONE_ELIF(4)DEFINE_ONE_ELIF(5)DEFINE_ONE_ELIF(6)DEFINE_ONE_ELIF(7)DEFINE_ONE_ELIF(8)DEFINE_ONE_ELIF(9)DEFINE_ONE_ELIF(10)DEFINE_ONE_ELIF(11)DEFINE_ONE_ELIF(12)DEFINE_ONE_ELIF(13)DEFINE_ONE_ELIF(14)DEFINE_ONE_ELIF(15)DEFINE_ONE_ELIF(16)DEFINE_ONE_ELIF(17)DEFINE_ONE_ELIF(18)DEFINE_ONE_ELIF(19)DEFINE_ONE_ELIF(20)DEFINE_ONE_ELIF(21)DEFINE_ONE_ELIF(22)DEFINE_ONE_ELIF(23)DEFINE_ONE_ELIF(24)DEFINE_ONE_ELIF(25)DEFINE_ONE_ELIF(26)DEFINE_ONE_ELIF(27)DEFINE_ONE_ELIF(28)DEFINE_ONE_ELIF(29)DEFINE_ONE_ELIF(30)DEFINE_ONE_ELIF(31)DEFINE_ONE_ELIF(32)
#undef DEFINE_ONE_ELIFelse {return cudaErrorInvalidValue;}
}
LaunchSoftmaxWarpImpl
template<typename LOAD, typename STORE, typename ComputeType, int pack_size, int cols_per_thread,int thread_group_width, int rows_per_access, bool padding, Algorithm algorithm>
inline cudaError_t LaunchSoftmaxWarpImpl(cudaStream_t stream, LOAD load, STORE store,const int64_t rows, const int64_t cols) {
block_dim是固定的128大小。可以参考 如何设置CUDA Kernel中的grid_size和block_size? 中的介绍。
waves是期望的作业次数。
thread_group_width为代表处理元素的线程组的宽度,是 kWarpSize 的因数。
thread_groups_per_block为 block 内部划分的线程组数量。
num_blocks为任务支持的最大分块数。
rows_per_access是单次处理的 batch 数。
constexpr int block_size = 128;constexpr int waves = 32;static_assert(block_size % thread_group_width == 0, "");constexpr int thread_groups_per_block = block_size / thread_group_width;dim3 block_dim(thread_group_width, thread_groups_per_block);const int64_t num_blocks =(rows / rows_per_access + thread_groups_per_block - 1) / thread_groups_per_block;
GetNumBlocks 函数查询设备的 SM 数量以及每个 SM 支持的最大线程数计算 block 数量。
int grid_dim_x;{cudaError_t err = GetNumBlocks(block_size, num_blocks, waves, &grid_dim_x);if (err != cudaSuccess) { return err; }}
Grid 是一维的,Block 是两维的。
启动 SoftmaxWarpImpl 在 Warp 内完成一行的计算。
SoftmaxWarpImpl<LOAD, STORE, ComputeType, pack_size, cols_per_thread, thread_group_width,rows_per_access, padding, algorithm><<<grid_dim_x, block_dim, 0, stream>>>(load, store, rows, cols);return cudaPeekAtLastError();
}
GetNumBlocks
cudaGetDevice 返回当前正在使用的设备。
inline cudaError_t GetNumBlocks(int64_t block_size, int64_t max_blocks, int64_t waves,int* num_blocks) {int dev;{cudaError_t err = cudaGetDevice(&dev);if (err != cudaSuccess) { return err; }}
cudaDeviceGetAttribute 返回有关设备的信息。
得到设备上的多处理器数量和每个多处理器的最大常驻线程数。
int sm_count;{cudaError_t err = cudaDeviceGetAttribute(&sm_count, cudaDevAttrMultiProcessorCount, dev);if (err != cudaSuccess) { return err; }}int tpm;{cudaError_t err = cudaDeviceGetAttribute(&tpm, cudaDevAttrMaxThreadsPerMultiProcessor, dev);if (err != cudaSuccess) { return err; }}
根据整个 GPU 上的最大常驻线程数计算出 block 块数。
*num_blocks =std::max<int>(1, std::min<int64_t>(max_blocks, sm_count * tpm / block_size * waves));return cudaSuccess;
}
SoftmaxWarpImpl
template<typename LOAD, typename STORE, typename ComputeType, int pack_size, int cols_per_thread,int thread_group_width, int rows_per_access, bool padding, Algorithm algorithm>
__global__ void SoftmaxWarpImpl(LOAD load, STORE store, const int64_t rows, const int64_t cols) {static_assert(cols_per_thread % pack_size == 0, "");static_assert(thread_group_width <= kWarpSize, "");static_assert(kWarpSize % thread_group_width == 0, "");
num_packs是每个线程需要处理的数据包的个数。
rows_per_access是单次处理的 batch 数。
buf用于存储输入 x x x 以及分子项 e x i e^{x_i} exi、 e x i − α e^{x_i -\alpha} exi−α。
blockIdx.x为 block 在行方向上的索引。blockDim.y为 Block 内划分的线程组数量。global_thread_group_id为全局线程组索引,在 Block 内编号是连续的。
num_global_thread_group为全局线程组数量。
lane_id为线程束内的线程 id。
step是 GPU 所有线程单次可处理的 batch 数。令该数值尽可能大,从而利于合并访存。
constexpr int num_packs = cols_per_thread / pack_size;assert(cols <= cols_per_thread * thread_group_width);ComputeType buf[rows_per_access][cols_per_thread];const int global_thread_group_id = blockIdx.x * blockDim.y + threadIdx.y;const int num_global_thread_group = gridDim.x * blockDim.y;const int lane_id = threadIdx.x;const int64_t step = num_global_thread_group * rows_per_access;
thread_max用于存储最大类别概率。首先初始化为 -inf。
Inf 能够返回不同类型的 inf 值。
col为当前需要处理的列。
如果不需要padding或者col在cols范围内,则调用 DirectLoad::load 加载输入数据。求出线程负责列的最大值。
否则,将row_buf设置为-inf。
for (int64_t row = global_thread_group_id * rows_per_access; row < rows; row += step) {ComputeType thread_max[rows_per_access];
#pragma unrollfor (int row_id = 0; row_id < rows_per_access; ++row_id) {thread_max[row_id] = -Inf<ComputeType>();ComputeType* row_buf = buf[row_id];
#pragma unrollfor (int pack_id = 0; pack_id < num_packs; ++pack_id) {const int pack_offset = pack_id * pack_size;const int col = (pack_id * thread_group_width + lane_id) * pack_size;if (!padding || col < cols) {load.template load<pack_size>(row_buf + pack_offset, row + row_id, col);
#pragma unrollfor (int i = 0; i < pack_size; ++i) {thread_max[row_id] = max(thread_max[row_id], row_buf[pack_offset + i]);}} else {
#pragma unrollfor (int i = 0; i < pack_size; ++i) { row_buf[pack_offset + i] = -Inf<ComputeType>(); }}}}
WarpAllReduce 函数调用 MaxOp 规约得到线程组内的最大值。
thread_group_width参数可以实现 Warp 内的线程组分组处理。
ComputeType warp_max[rows_per_access];
#pragma unrollfor (int row_id = 0; row_id < rows_per_access; ++row_id) {warp_max[row_id] = WarpAllReduce<MaxOp, ComputeType, thread_group_width>(thread_max[row_id]);}
row_buf中保存 e x i − α e^{x_i -\alpha} exi−α。
线程内求和,thread_sum保存线程内的 ∑ j e x j − α \sum_j e^{x_j -\alpha} ∑jexj−α 。
可以通过从任何设备线程调用__trap()函数来启动 trap 操作。内核的执行被中止并在主机程序中引发中断。
ComputeType thread_sum[rows_per_access];
#pragma unrollfor (int row_id = 0; row_id < rows_per_access; ++row_id) {thread_sum[row_id] = 0;ComputeType* row_buf = buf[row_id];
#pragma unrollfor (int i = 0; i < cols_per_thread; ++i) {if (algorithm == Algorithm::kSoftmax) {row_buf[i] = Exp(row_buf[i] - warp_max[row_id]);thread_sum[row_id] += row_buf[i];} else if (algorithm == Algorithm::kLogSoftmax) {row_buf[i] -= warp_max[row_id];thread_sum[row_id] += Exp(row_buf[i]);} else {__trap();}}}
调用 WarpAllReduce 函数得到各行的warp_sum。
ComputeType warp_sum[rows_per_access];
#pragma unrollfor (int row_id = 0; row_id < rows_per_access; ++row_id) {warp_sum[row_id] = WarpAllReduce<SumOp, ComputeType, thread_group_width>(thread_sum[row_id]);}
Div 和 Log 有快速计算实现。
计算 Softmax ( x i ) = e x i − α ∑ j e x j − α \text{Softmax}(x_i) = \frac{e^{x_i -\alpha}}{\sum_j e^{x_j -\alpha}} Softmax(xi)=∑jexj−αexi−α 或者 LogSoftmax ( x i ) = log ( e x i − α ∑ j e x j − α ) = x i − α − log ( ∑ j e x j − α ) \text{LogSoftmax}(x_{i}) = \log\left(\frac{e^{x_i-\alpha} }{ \sum_j e^{x_j-\alpha}} \right) = x_i-\alpha - \log({ \sum_j e^{x_j-\alpha}}) LogSoftmax(xi)=log(∑jexj−αexi−α)=xi−α−log(∑jexj−α)
DirectStore::store 保存结果。
#pragma unrollfor (int row_id = 0; row_id < rows_per_access; ++row_id) {ComputeType* row_buf = buf[row_id];
#pragma unrollfor (int i = 0; i < cols_per_thread; ++i) {if (algorithm == Algorithm::kSoftmax) {row_buf[i] = Div(row_buf[i], warp_sum[row_id]);} else if (algorithm == Algorithm::kLogSoftmax) {row_buf[i] -= Log(warp_sum[row_id]);} else {__trap();}}
#pragma unrollfor (int i = 0; i < num_packs; ++i) {const int col = (i * thread_group_width + lane_id) * pack_size;if (!padding || col < cols) {store.template store<pack_size>(row_buf + i * pack_size, row + row_id, col);}}}}
}
WarpAllReduce
__shfl_xor_sync基于自身通道 ID 的按位异或从通道复制。
不断减半mask,实现蝶型归约。实现为下图的逆序过程。
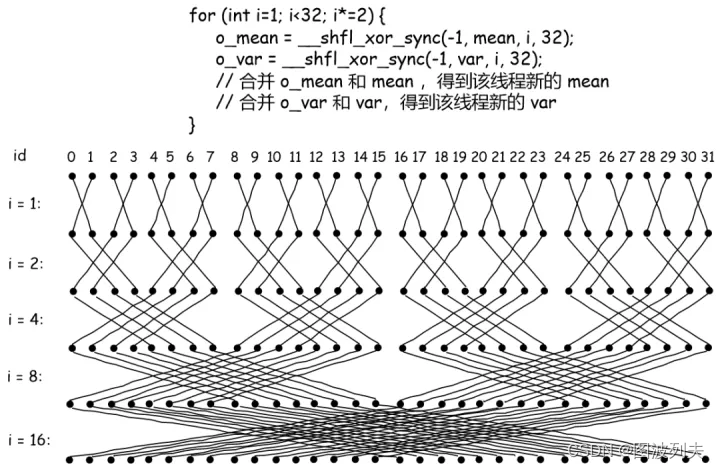
template<template<typename> class ReductionOp, typename T, int thread_group_width = kWarpSize>
__inline__ __device__ T WarpAllReduce(T val) {for (int mask = thread_group_width / 2; mask > 0; mask /= 2) {val = ReductionOp<T>()(val, __shfl_xor_sync(0xffffffff, val, mask));}return val;
}
DispatchSoftmaxWarpImplCols
pack_size为2的版本。
template<typename LOAD, typename STORE, typename ComputeType, int pack_size, Algorithm algorithm>
typename std::enable_if<pack_size == 2, cudaError_t>::type DispatchSoftmaxWarpImplCols(cudaStream_t stream, LOAD load, STORE store, const int64_t rows, const int64_t cols) {if (cols <= 0) { return cudaErrorInvalidValue; }
尝试找到一个刚好能处理cols的thread_group_width值,然后以此调用 DispatchSoftmaxWarpImplPadding 函数。奇数处理1行,偶数处理两行。
#define DEFINE_ONE_ELIF(thread_group_width) \else if (cols <= (thread_group_width)*pack_size) { \if (rows % 2 == 0) { \return DispatchSoftmaxWarpImplPadding<LOAD, STORE, ComputeType, pack_size, pack_size, \thread_group_width, 2, algorithm>(stream, load, store, \rows, cols); \} else { \return DispatchSoftmaxWarpImplPadding<LOAD, STORE, ComputeType, pack_size, pack_size, \thread_group_width, 1, algorithm>(stream, load, store, \rows, cols); \} \}DEFINE_ONE_ELIF(1)DEFINE_ONE_ELIF(2)DEFINE_ONE_ELIF(4)DEFINE_ONE_ELIF(8)DEFINE_ONE_ELIF(16)DEFINE_ONE_ELIF(32)
#undef DEFINE_ONE_ELIF
如果cols较大,Warp 内所有线程处理1行数据,每个线程处理cols_per_thread个类别。
#define DEFINE_ONE_ELIF(col) \else if (cols <= (col)*kWarpSize) { \return DispatchSoftmaxWarpImplPadding<LOAD, STORE, ComputeType, pack_size, col, kWarpSize, 1, \algorithm>(stream, load, store, rows, cols); \}DEFINE_ONE_ELIF(4)DEFINE_ONE_ELIF(6)DEFINE_ONE_ELIF(8)DEFINE_ONE_ELIF(10)DEFINE_ONE_ELIF(12)DEFINE_ONE_ELIF(14)DEFINE_ONE_ELIF(16)DEFINE_ONE_ELIF(18)DEFINE_ONE_ELIF(20)DEFINE_ONE_ELIF(22)DEFINE_ONE_ELIF(24)DEFINE_ONE_ELIF(26)DEFINE_ONE_ELIF(28)DEFINE_ONE_ELIF(30)DEFINE_ONE_ELIF(32)
#undef DEFINE_ONE_ELIFelse {return cudaErrorInvalidValue;}
}
TryDispatchSoftmaxBlockSMemImplBlockSize
根据cols计算出需要的 Shared Memory 大小。
template<typename LOAD, typename STORE, typename ComputeType, int pack_size, Algorithm algorithm>
inline cudaError_t TryDispatchSoftmaxBlockSMemImplBlockSize(cudaStream_t stream, LOAD load,STORE store, const int64_t rows,const int64_t cols, bool* success) {constexpr int block_size_conf_1 = 128;constexpr int block_size_conf_2 = 256;constexpr int block_size_conf_3 = 512;constexpr int block_size_conf_4 = 1024;const size_t smem = cols * sizeof(ComputeType);
cudaOccupancyMaxActiveBlocksPerMultiprocessor 返回设备函数的占用。
SoftmaxBlockSMemImpl 为 kernel 函数。
smem超过 SM 内 Shared Memory 的大小时,kernel 会无法启动。
优先让 SM 同时调度的 block 数量达到最大,其次让 block_size 达到最大。从而提高硬件的利用率。
int max_active_blocks_conf_1;{cudaError_t err = cudaOccupancyMaxActiveBlocksPerMultiprocessor(&max_active_blocks_conf_1,SoftmaxBlockSMemImpl<LOAD, STORE, ComputeType, pack_size, block_size_conf_1, algorithm>,block_size_conf_1, smem);if (err != cudaSuccess) { return err; }}if (max_active_blocks_conf_1 <= 0) {*success = false;return cudaSuccess;}int max_active_blocks_conf_4;{cudaError_t err = cudaOccupancyMaxActiveBlocksPerMultiprocessor(&max_active_blocks_conf_4,SoftmaxBlockSMemImpl<LOAD, STORE, ComputeType, pack_size, block_size_conf_4, algorithm>,block_size_conf_4, smem);if (err != cudaSuccess) { return err; }}
如果block_size_conf_1和block_size_conf_4获得的占用相等,则选择较大的max_active_blocks_conf_4。
LaunchSoftmaxBlockSMemImpl 启动在 Block 内处理一行的 kernel。
if (max_active_blocks_conf_4 == max_active_blocks_conf_1) {*success = true;return LaunchSoftmaxBlockSMemImpl<LOAD, STORE, ComputeType, pack_size, block_size_conf_4,algorithm>(stream, load, store, smem, rows, cols);}
依次向下尝试max_active_blocks_conf_3和max_active_blocks_conf_2。
int max_active_blocks_conf_3;{cudaError_t err = cudaOccupancyMaxActiveBlocksPerMultiprocessor(&max_active_blocks_conf_3,SoftmaxBlockSMemImpl<LOAD, STORE, ComputeType, pack_size, block_size_conf_3, algorithm>,block_size_conf_3, smem);if (err != cudaSuccess) { return err; }}if (max_active_blocks_conf_3 == max_active_blocks_conf_1) {*success = true;return LaunchSoftmaxBlockSMemImpl<LOAD, STORE, ComputeType, pack_size, block_size_conf_3,algorithm>(stream, load, store, smem, rows, cols);}int max_active_blocks_conf_2;{cudaError_t err = cudaOccupancyMaxActiveBlocksPerMultiprocessor(&max_active_blocks_conf_2,SoftmaxBlockSMemImpl<LOAD, STORE, ComputeType, pack_size, block_size_conf_2, algorithm>,block_size_conf_2, smem);if (err != cudaSuccess) { return err; }}if (max_active_blocks_conf_2 == max_active_blocks_conf_1) {*success = true;return LaunchSoftmaxBlockSMemImpl<LOAD, STORE, ComputeType, pack_size, block_size_conf_2,algorithm>(stream, load, store, smem, rows, cols);}*success = true;return LaunchSoftmaxBlockSMemImpl<LOAD, STORE, ComputeType, pack_size, block_size_conf_1,algorithm>(stream, load, store, smem, rows, cols);
}
```## [SoftmaxBlockSMemImpl](https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/core/cuda/softmax.cuh#L482)
```mermaid
graph TD
SoftmaxBlockSMemImpl-->BlockAllReduce
一个 Block 处理一行元素。
使用动态分配的共享内存。以double类型来对齐,即64-bit。ComputeType仅可能是float。
template<typename LOAD, typename STORE, typename ComputeType, int pack_size, int block_size,Algorithm algorithm>
__global__ void SoftmaxBlockSMemImpl(LOAD load, STORE store, const int64_t rows,const int64_t cols) {extern __shared__ __align__(sizeof(double)) unsigned char shared_buf[];auto* buf = reinterpret_cast<ComputeType*>(shared_buf);const int tid = threadIdx.x;assert(cols % pack_size == 0);const int num_packs = cols / pack_size;
每次处理gridDim.x行。
thread_max用于存储最大类别概率。首先初始化为 -inf。
先将输入加载到pack,再拷贝到buf共享内存中。
buf的形状为[pack_size, num_packs],这样pack_size内不是连续的,需要逐个存。
for (int64_t row = blockIdx.x; row < rows; row += gridDim.x) {ComputeType thread_max = -Inf<ComputeType>();for (int pack_id = tid; pack_id < num_packs; pack_id += block_size) {ComputeType pack[pack_size];load.template load<pack_size>(pack, row, pack_id * pack_size);
#pragma unrollfor (int i = 0; i < pack_size; ++i) {buf[i * num_packs + pack_id] = pack[i];thread_max = max(thread_max, pack[i]);}}
BlockAllReduce 函数调用 cub::BlockReduce 需要两块内存。
row_max为类别最大值 α \alpha α。buf中保存 e x i − α e^{x_i -\alpha} exi−α。
线程内求和,thread_sum保存线程内的 ∑ j e x j − α \sum_j e^{x_j -\alpha} ∑jexj−α 。
const ComputeType row_max = BlockAllReduce<MaxOp, ComputeType, block_size>(thread_max);ComputeType thread_sum = 0;for (int col = tid; col < cols; col += block_size) {if (algorithm == Algorithm::kSoftmax) {const ComputeType exp_x = Exp(buf[col] - row_max);buf[col] = exp_x;thread_sum += exp_x;} else {const ComputeType x = buf[col] - row_max;buf[col] = x;thread_sum += Exp(x);}}
再次调用 BlockAllReduce 函数得到所有类别的和。
计算 Softmax ( x i ) = e x i − α ∑ j e x j − α \text{Softmax}(x_i) = \frac{e^{x_i -\alpha}}{\sum_j e^{x_j -\alpha}} Softmax(xi)=∑jexj−αexi−α 或者 LogSoftmax ( x i ) = log ( e x i − α ∑ j e x j − α ) = x i − α − log ( ∑ j e x j − α ) \text{LogSoftmax}(x_{i}) = \log\left(\frac{e^{x_i-\alpha} }{ \sum_j e^{x_j-\alpha}} \right) = x_i-\alpha - \log({ \sum_j e^{x_j-\alpha}}) LogSoftmax(xi)=log(∑jexj−αexi−α)=xi−α−log(∑jexj−α)
const ComputeType row_sum = BlockAllReduce<SumOp, ComputeType, block_size>(thread_sum);for (int pack_id = tid; pack_id < num_packs; pack_id += block_size) {ComputeType pack[pack_size];
#pragma unrollfor (int i = 0; i < pack_size; ++i) {if (algorithm == Algorithm::kSoftmax) {pack[i] = Div(buf[i * num_packs + pack_id], row_sum);} else if (algorithm == Algorithm::kLogSoftmax) {pack[i] = buf[i * num_packs + pack_id] - Log(row_sum);} else {__trap();}}store.template store<pack_size>(pack, row, pack_id * pack_size);}}
}
LaunchSoftmaxBlockUncachedImpl
不使用 Shared Memory 时,需要多次访问 Global Memory。函数设置较大的block_size。因为block_size越大,SM 中能同时并行执行的 Block 数就越少,对 cache 的请求次数就越少,就有更多机会命中 Cache。
GetNumBlocks 函数查询设备的 SM 数量以及每个 SM 支持的最大线程数计算 block 数量。
template<typename LOAD, typename STORE, typename ComputeType, int pack_size, Algorithm algorithm>
inline cudaError_t LaunchSoftmaxBlockUncachedImpl(cudaStream_t stream, LOAD load, STORE store,const int64_t rows, const int64_t cols) {constexpr int block_size = 1024;constexpr int waves = 32;int grid_dim_x;{cudaError_t err = GetNumBlocks(block_size, rows, waves, &grid_dim_x);if (err != cudaSuccess) { return err; }}
启动 SoftmaxBlockUncachedImpl kernel 函数。
SoftmaxBlockUncachedImpl<LOAD, STORE, ComputeType, pack_size, block_size, algorithm><<<grid_dim_x, block_size, 0, stream>>>(load, store, rows, cols);return cudaPeekAtLastError();
}
SoftmaxBlockUncachedImpl
对于cols没有任何限制。
template<typename LOAD, typename STORE, typename ComputeType, int pack_size, int block_size,Algorithm algorithm>
__global__ void SoftmaxBlockUncachedImpl(LOAD load, STORE store, const int64_t rows,const int64_t cols) {const int tid = threadIdx.x;assert(cols % pack_size == 0);const int num_packs = cols / pack_size;
每个 Block 处理一行元素。
每个线程处理pack_size个类别。
首先求出线程内的最大值,然后调用 BlockAllReduce 归约得到全局最大值。
for (int64_t row = blockIdx.x; row < rows; row += gridDim.x) {ComputeType thread_max = -Inf<ComputeType>();for (int pack_id = tid; pack_id < num_packs; pack_id += block_size) {ComputeType pack[pack_size];load.template load<pack_size>(pack, row, pack_id * pack_size);
#pragma unrollfor (int i = 0; i < pack_size; ++i) { thread_max = max(thread_max, pack[i]); }}const ComputeType row_max = BlockAllReduce<MaxOp, ComputeType, block_size>(thread_max);
分两步得到 ∑ j e x j − α \sum_j e^{x_j -\alpha} ∑jexj−α 。
ComputeType thread_sum = 0;for (int pack_id = tid; pack_id < num_packs; pack_id += block_size) {ComputeType pack[pack_size];load.template load<pack_size>(pack, row, pack_id * pack_size);
#pragma unrollfor (int i = 0; i < pack_size; ++i) { thread_sum += Exp(pack[i] - row_max); }}const ComputeType row_sum = BlockAllReduce<SumOp, ComputeType, block_size>(thread_sum);
计算 Softmax ( x i ) = e x i − α ∑ j e x j − α \text{Softmax}(x_i) = \frac{e^{x_i -\alpha}}{\sum_j e^{x_j -\alpha}} Softmax(xi)=∑jexj−αexi−α 或者 LogSoftmax ( x i ) = log ( e x i − α ∑ j e x j − α ) = x i − α − log ( ∑ j e x j − α ) \text{LogSoftmax}(x_{i}) = \log\left(\frac{e^{x_i-\alpha} }{ \sum_j e^{x_j-\alpha}} \right) = x_i-\alpha - \log({ \sum_j e^{x_j-\alpha}}) LogSoftmax(xi)=log(∑jexj−αexi−α)=xi−α−log(∑jexj−α)
for (int pack_id = tid; pack_id < num_packs; pack_id += block_size) {ComputeType pack[pack_size];load.template load<pack_size>(pack, row, pack_id * pack_size);
#pragma unrollfor (int i = 0; i < pack_size; ++i) {if (algorithm == Algorithm::kSoftmax) {pack[i] = Div(Exp(pack[i] - row_max), row_sum);} else if (algorithm == Algorithm::kLogSoftmax) {pack[i] = (pack[i] - row_max) - Log(row_sum);} else {__trap();}}store.template store<pack_size>(pack, row, pack_id * pack_size);}}
}
参考资料:
- CUDA优化之LayerNorm性能优化实践
- 如何实现一个高效的Softmax CUDA kernel?
- 如何实现一个高效的Softmax CUDA kernel?——OneFlow 性能优化分享
- 用Welford算法实现LN的方差更新
- OneFlow是如何做到世界最快深度学习框架的
- OneFlow源码解析:基础计算接口Primitive
- 【BBuf的CUDA笔记】八,对比学习OneFlow 和 FasterTransformer 的 Softmax Cuda实现
- 【BBuf的CUDA笔记】九,使用newbing(chatgpt)解析oneflow softmax相关的fuse优化
- 【oneflow】算子在深度学习框架中的执行及interpreter
- 计算机视觉大型攻略 —— CUDA(3)内存模型(一)CUDA内存
- 计算机视觉大型攻略 —— CUDA(3)内存模型(二)Aligned and Coalesced内存访问
- CUDA Data Alignment
- CUDA编程入门之 Grid-Stride Loops
- 【BBuf 的 CUDA 笔记】一,解析 OneFlow Element-Wise 算子实现
- 【BBuf的CUDA笔记】三,reduce优化入门学习笔记
- 简单谈谈CUDA Reduce
- cuda的shared momery
- C++11的模板类型判断——std::is_same和std::decay
- 深入了解 | 内存对齐之 alignof、alignas 、aligned_storage、align 深度剖析
- CUDA小妙招:这种快捷查询设备属性的方法你知道吗?
- pybind11使用指南
- Pybind11 理解
- PyBind11:基本用法和底层实现
- pybind笔记_入门
- 一文理解 PyTorch 中的 SyncBatchNorm
- CUDA笔记 线程束洗牌函数
- Building a Numerically Stable Softmax
- How to assign INFINITY to variables in CUDA code?
- Way to get floating-point special values in CUDA?
- CUDA C++ Programming Guide
- CUDA编程入门之Parallel Reductions
- CUDA编程入门之Warp-Level Primitives
- CUDA中的Warp Shuffle
- 附录B – 对C++扩展的详细描述
- 在LLVM后端实现跨通道数据搬移
- CUDA 编程手册系列 附录B – 对C++扩展的详细描述(三)
- Lecture 4 Warp shuffles, reduction and scan operations
- 一文理解 PyTorch 中的 SyncBatchNorm
- 6.CUDA编程手册中文版—附录A&B
- CUDA编程笔记——chapter5 共享内存和常量内存
- 在 CUDA C / C ++ 中使用共享内存
- cub 库(七)BlockReduce 类共享内存申请方法和Global Mem to 寄存器数组
- CUDA Pro Tip: Increase Performance with Vectorized Memory Access
- Optimizing CUDA
- Advanced CUDA Programming
- cuda编程中,转为float4是什么?
- 【CUDA编程】OneFlow Softmax 算子源码解读之WarpSoftmax
- 【CUDA编程】OneFlow Softmax算子源码解读之BlockSoftmax
- CUDA 编程手册系列第五章: 性能指南