目录
一、独热编码与标签编码的区别
二、创建数据集
三、独热编码实现
(一) 自动将所有分类变量进行独热编码
(二) 对指定列进行独热编码
(三) 对进行独热编码的列采用布尔型表示
四、查看数据类型
五、对数据进行独热编码后,数据变成了什么类型
一、独热编码与标签编码的区别
独热编码适用于类别之间无顺序或大小关系时,而标签编码适用于类别之间有明确的顺序关系时。
独热编码(One-Hot Encoding)和标签编码(Label Encoding)是数据预处理中的两种常见方法,它们主要用于处理分类数据。以下是具体分析:
1. 独热编码:
- 适用于类别之间没有顺序或大小关系的情况。它为每个类别创建一个新的二进制特征,对于每个样本,只有一个二进制特征为1(表示它属于该类别),其他特征为0。
- 这种方法可以防止模型错误地解释类别之间的顺序或大小关系,因为所有类别都是平等的,没有内在的顺序。
- 例如,如果一个特征是颜色,它有三个值:红、蓝、绿,独热编码会将它们分别表示为[1, 0, 0]、[0, 1, 0]、[0, 0, 1],这样模型就不会错误地认为红色小于蓝色等。
2. 标签编码:
- 适用于类别之间存在明确的顺序关系时。它将不同的类别使用唯一的数字来表示,例如,红=1,黄=2,蓝=3。
- 这种方法适用于类别之间有自然顺序的情况,比如评分等级(低、中、高)。
- 标签编码可能会导致模型学习到错误的关系,比如在上面的颜色例子中,模型可能会错误地认为“红<黄<蓝”,这可能不是我们想要模型学习的关系。
在实际应用中,选择哪种编码方式取决于数据的特点和模型的需求。如果类别之间没有顺序关系,或者你不希望模型学习到任何顺序关系,那么独热编码是更好的选择。如果类别之间有自然的顺序,或者你需要保持这种顺序,那么标签编码可能更合适。不过,在使用标签编码时,需要注意可能引入的模型偏差问题。
二、创建数据集
其中week和state这两列是分类变量
import pandas as pd
a=pd.DataFrame()
a["平均值"]=[123,456,789,159,357,852,159]
a["中位数"]=[159,159,258,369,357,159,852]
a["week"]=["星期一","星期二","星期三","星期四","星期五","星期六","星期日"]
a["state"]=["1","2","3","1","2","3","1"]
a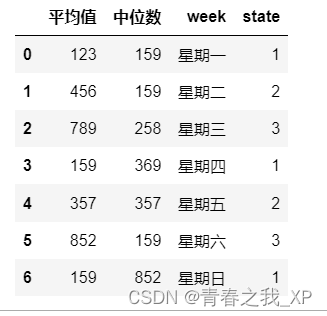
三、独热编码实现
(一) 自动将所有分类变量进行独热编码
这种方法是自动识别数据表中的分类变量,然后将所有的分类变量自动实现独热编码
# 独热编码 one-hot
a1 = pd.get_dummies(a)#帮你判断哪一列是字符串,自动地帮你把字符串直接展开
#a2 = pd.get_dummies(a).astype(int)#输出打印体会一下加不加.astype(int)的区别
a1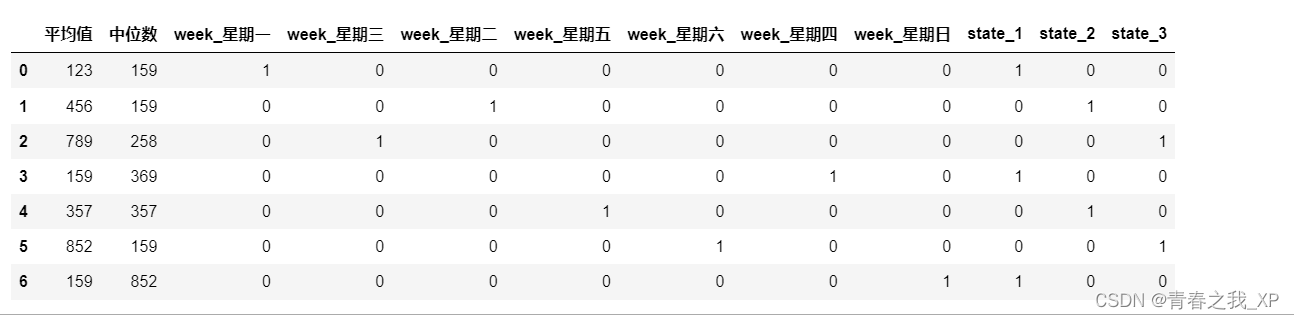
(二) 对指定列进行独热编码
a3 = pd.get_dummies(a, columns=['week'])
a3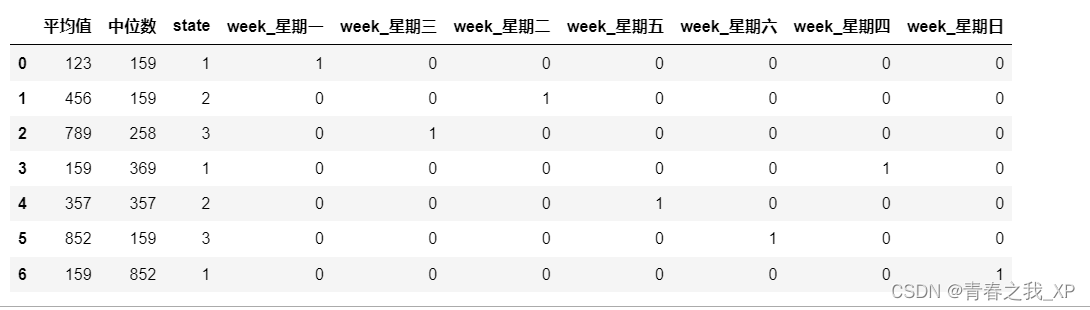
(三) 对进行独热编码的列采用布尔型表示
# 对'state'列进行独热编码
a_encoded = pd.get_dummies(a['state'])# 将独热编码后的整数型数据转换为布尔型
a_encoded_bool = a_encoded.astype(bool)# 将转换后的独热编码列和原始的DataFrame合并
a_final = pd.concat([a[['平均值', '中位数', 'week']], a_encoded_bool], axis=1)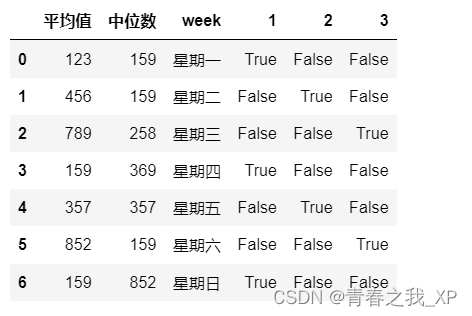
四、查看数据类型
在Pandas中,object数据类型指的是字符串类型。
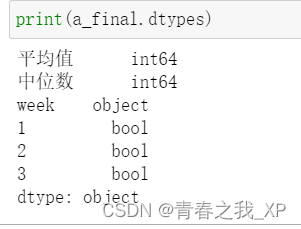
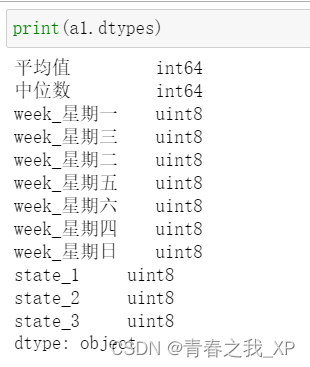
使用pd.get_dummies(a)进行独热编码后,数据类型出现了unit8类型,这可能是因为Pandas在进行独热编码时,默认将非零值转换为整数类型。这里的unit8实际上是指无符号的8位整数类型(uint8),它与标准整数类型(int)在存储和处理上有所不同。
首先,我们来解释一下为什么会出现uint8类型:
- 独热编码的默认行为:在使用
pd.get_dummies()函数进行独热编码时,如果没有指定dtype参数,Pandas会将生成的独热编码列的数据类型设置为布尔型(bool),即True和False。然而,在某些情况下,Pandas可能会将这些布尔值进一步转换为整数类型,以便于进行数学计算和提高存储效率。 - 数据类型的自动转换:Pandas在处理数据时,会根据数据的内容自动选择合适的数据类型。在这种情况下,由于独热编码后的列只包含0和1,因此Pandas选择了
uint8类型,这是最小宽度足以存储这些值的整数类型。
其次,如果您希望独热编码后的列使用标准的整数类型(int),可以通过指定dtype参数来实现:
- 指定
dtype参数:在调用pd.get_dummies()函数时,可以通过设置dtype=int来指定独热编码列的数据类型为整数型。例如:a1 = pd.get_dummies(a, dtype=int)。这样就可以确保独热编码后的列使用标准的整数类型。
总结来说,独热编码后出现uint8类型是因为Pandas在没有明确指定数据类型时,根据数据内容自动选择了最适合的整数类型。如果您希望使用标准的整数类型,可以在pd.get_dummies()函数中通过dtype参数来指定。
五、对数据进行独热编码后,数据变成了什么类型
对数据进行独热编码处理之后,原本的分类数据会被转换为数值型数据,具体来说,转化后的数据通常是以0和1组成的稀疏矩阵或DataFrame。在Pandas中,经过pd.get_dummies()函数处理后,产生的新列的数据类型通常是float64,这是因为即使所有值仅为0或1,Pandas也会默认使用浮点数类型来表示这些值。
然而,如果后续手动调用.astype(int)方法,则可以把这些0和1的值转换为整数类型int。在机器学习领域中,无论是浮点数类型还是整数类型对于大多数算法来说都可以被接受,因为0和1代表的含义是相同的——即类别是否存在或是否选择该特征。不过在某些情况下,特别是当你希望减少存储空间或者根据项目需求必须使用整数时,可能会选择将独热编码后的数据转换为整数类型。
对数据进行独热编码处理后,数据变成了稀疏的二元特征类型。
独热编码(One-Hot Encoding)是一种数据预处理技术,它主要用于将类别型特征转换成数值型特征,以便机器学习模型能够处理。具体来说,对于每一个特征,如果它有m个可能的值,那么经过独热编码后,就会变成m个二元特征,每个二元特征只有0和1两种状态。这些二元特征互斥,每次只有一个被激活,即只有一个特征值为1,其余都为0。这样的编码方式确保了算法是基于向量空间中的度量来进行计算,使得非偏序关系的变量取值不具有偏序性,并且在欧氏空间中是等距的。
在实际应用中,独热编码通常会导致数据集的维度显著增加,因为每个类别都会对应一个新的二元特征。例如,如果一个特征有5个可能的值,独热编码后会产生5个新的二元特征。这种高维稀疏数据结构在存储和计算上可能会带来挑战,但它有助于模型更好地理解和区分不同的类别。
总的来说,独热编码是一种有效的方法,用于将分类数据转换为模型可处理的数值型数据,尤其是在处理非数值型的类别特征时。然而,需要注意的是,在使用独热编码时,应该考虑到它可能会增加数据的维度,以及对存储和计算资源的影响。