说说你对线程池的了解?
线程池,是对一系列线程进行管理的资源池,当有任务来时,我们可以使用线程池中的线程,完成任务时不需要被销毁,会重新回到池子中,等待下一次的复用。
为什么要使用线程池?
池化技术,主要的核心思想是降低资源的损耗,提高资源的利用率。
当然它也可以
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
线程池中线程复用原理
线程池将线程和任务进行解耦,线程是线程,任务是任务,摆脱了之前通过Thiread创建线程时的一个线程必
须对应一个任务的限制。
在线程池中,同一个线程可以从阻塞队列中不断获取新任务来执行,其核心原理在于线程池对Thread进行了
封装,并不是每次执行任务都会调用Thread.start() 来创建新线程,而是让每个线程去执行一个循环任务”", 在这个“循环任务"中不停检查是否有任务需要被执行,如果有则直接执行,也就是调用任务中的run方法,将run方
法当成一个普通的方法执行,通过这种方式只使用固定的线程就将所有任务的run方法串联起来。
线程池中阻塞队列的作用?为什么是先添加列队而不是先创建最大线程?
1、一般的队列只能保证作为一个有限长度的缓冲区,如果超出了缓冲长度,就无法保留当前的任务了,阻塞队列
通过阻塞可以保留住当前想要继续入队的任务。
阻塞队列可以保证任务队列中没有任务时阻塞获取任务的线程,使得线程进入wait状态,释放cpu资源。
并且我们的阻塞队列可以自己阻塞和唤醒线程,无需额外的资源去维护核心线程的存活。
这个其实回到了我们线程池设计的初衷,在创建线程时需要获取全局锁,会阻塞其他线程,影响整体效率。当我们的核心线程数满了,如果任务过来,我们先创建线程的话,假设这时某个核心线程完成任务了空闲出了,那么这个新创建出来的线程其实是在无端的消耗我们的资源,这与我们设计线程池的初衷不符,所以合理的选择是让任务稍微积压,先添加进入队列进行阻塞等待。
线程池的创建方式?
1.通过ThreadPoolExecutor构造函数来创建(推荐)
2.通过 Executor 框架的工具类 Executors 来创建
创立线程的几种方式
- 继承Thread创建线程
- 实现Runnable接口创建线程
- 实现ExecutorService、Callable和Future接口创建线程
- 使用线程池创建(使用java.util.concurrent.Executor)
线程池常见的参数有哪些?
/*** 用给定的初始参数创建一个新的ThreadPoolExecutor。*/
public ThreadPoolExecutor(int corePoolSize,//线程池的核心线程数量int maximumPoolSize,//线程池的最大线程数long keepAliveTime,//当线程数大于核心线程数时,多余的空闲线程存活的最长时间TimeUnit unit,//时间单位BlockingQueue<Runnable> workQueue,//任务队列,用来储存等待执行任务的队列ThreadFactory threadFactory,//线程工厂,用来创建线程,一般默认即可RejectedExecutionHandler handler//拒绝策略,当提交的任务过多而不能及时处理时,我们可以定制策略来处理任务) {if (corePoolSize < 0 ||maximumPoolSize <= 0 ||maximumPoolSize < corePoolSize ||keepAliveTime < 0)throw new IllegalArgumentException();if (workQueue == null || threadFactory == null || handler == null)throw new NullPointerException();this.corePoolSize = corePoolSize;this.maximumPoolSize = maximumPoolSize;this.workQueue = workQueue;this.keepAliveTime = unit.toNanos(keepAliveTime);this.threadFactory = threadFactory;this.handler = handler;
}
ThreadPoolExecutor 3 个最重要的参数:
- corePoolSize : 任务队列未达到队列容量时,最大可以同时运行的线程数量。
- maximumPoolSize : 任务队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。
- workQueue: 新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
ThreadPoolExecutor其他常见参数 :
下面这张图可以加深你对线程池中各个参数的相互关系的理解(图片来源:《Java 性能调优实战》):
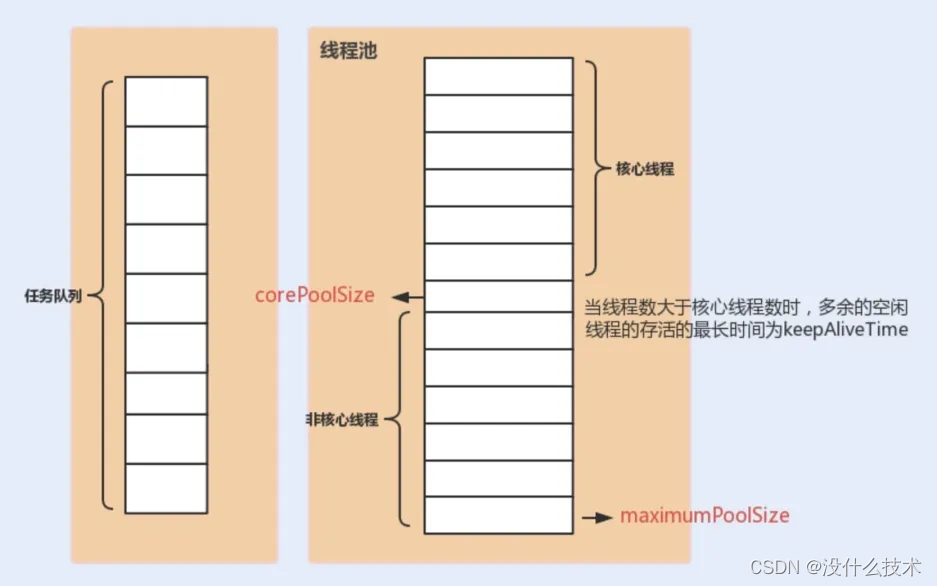
- keepAliveTime:线程池中的线程数量大于 corePoolSize 的时候,如果这时没有新的任务提交,多余的空闲线程不会立即销毁,而是会等待,直到等待的时间超过了 keepAliveTime才会被回收销毁,线程池回收线程时,会对核心线程和非核心线程一视同仁,直到线程池中线程的数量等于 corePoolSize ,回收过程才会停止。
- unit : keepAliveTime 参数的时间单位。
- threadFactory :executor 创建新线程的时候会用到。
- handler :饱和策略。关于饱和策略下面单独介绍一下。
sleep()、wait()、 join()、 yield()的区别
1.锁池.
所有需要竞争同步锁的线程都会放在锁池当中,比如当前对象的锁已经被其中一个线程得到,则其他线程需要在这
个锁池进行等待,当前面的线程释放同步锁后锁池中的线程去竞争同步锁,当某个线程得到后会进入就绪队列进行
等待cpu资源分配。
2.等待池
当我们调用wait () 方法后,线程会放到等待池当中,等待池的线程是不会去竞争同步锁。只有调用了notify ()
或notifyAll)后等待池的线程才会开始去竞争锁,notify ()是随机从等待池选出一个线程放到锁池,而notifAl()
是将等待池的所有线程放到锁池当中
1、sleep 是Thread类的静态本地方法,wait 则是Object类的本地方法。
2. sleep方法不会释放lock,但是wait会释放,而且会加入到等待队列中。
yield ()执行后线程直接进入就绪状态,马上释放了cpu的执行权,但是依然保留了cpu的执行资格,所以有可能
cpy下次进行线程调度还会让这个线程获取到执行权继续执行
join ()执行后线程进入阻塞状态,例如在线程B中调用线程A的join () , 那线程B会进入到阻塞队列,直到线程
A结束或中断线程