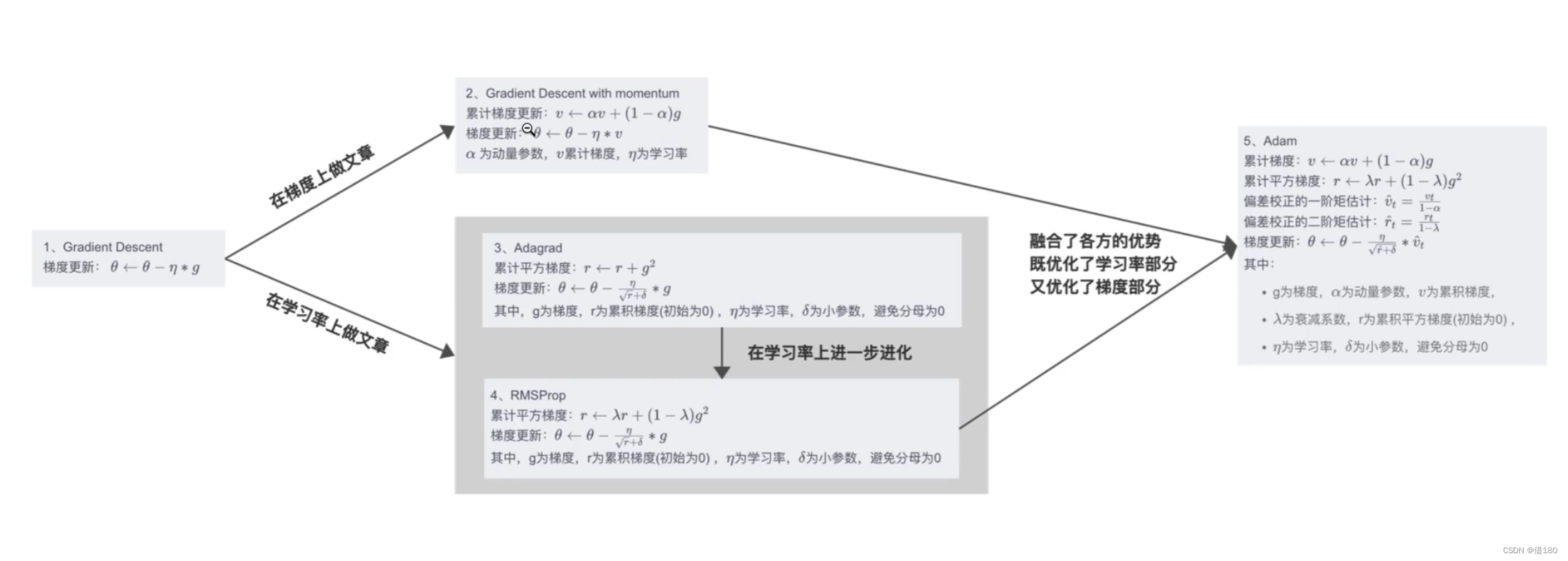
1.使用众所周知的梯度下降法。
(1).批量梯度下降法:每次参数更新使用所有的样本(2).随机梯度下降法:每次参数更新只使用一次样本(3).小批量梯度下降法:每次参数更新使用小部分数据样本
优点:算法简洁,当学习率值恰当时,可以收敛到全局最优点或局部最优点。
缺点:对于超参数比较敏感:过小导致收敛速度过慢,过大容易越过极值点;无法实时修改学习率,容易出现在鞍点上,处于局部最大值;且求导时要对整个数据集进行求导,计算量很大;且容易达到局部最优点,无法继续优化。
2.随机梯度下降法,在梯度下降上做了优化,优点是:计算量小,因为只需要对一个训练数据进行求导。缺点:无法调整学习率,容易发生震荡,收敛慢,容易出现在鞍点上,处于局部最大值。
3.动量法momentum,优点:加上了原始动量(梯度累积)且对于变量给了参数,给了一种惯性,使得其在正确的方向上,下降更快,而且容易跳出局部最小点。更具有鲁棒性,使得训练过程更加平稳。缺点:容易出现在鞍点上,处于局部最大值。
更新的时候用的不再是梯度,而是参数的动量值。
以上是对梯度做文章,
4.adagrad(自适应学习率优化器)
对于不同的参数设置不同的学习率,
使用累计平方梯度来计算新的学习率(让其作为平方根,且为分母)这样就能在梯度与学习率相乘的时候能够自适应。
优点:可以自适应的调整学习率,不同量级的参数能更好的收敛(使得梯度大的学习率变小,使得梯度乘以学习率后为一个可以接受的值,能够减少震荡)。
5.RMSProp
优点:给累计梯度增加了参数,学习率进一步优化,给累计梯度和和当前梯度增加参数,计算公式不变。
以上是对学习率做文章
6.adam
缝合怪,集中了以上所有的优点,在梯度方面增加了momentum,使用累计梯度。同时在学习率上能够自适应使用RMSProp的优点。其中的参数均为超参数,需要自己去调整。最后使用了偏差纠正,起初的时候累计梯度和累计平方梯度都是属于0,而参数会接近于一,那么当t较小时,可能会偏向于0。那么就需要做偏差矫正。