文章目录
- 背景
- gdb调试Go程序
- 为什么不用dlv
- gdb调试Go可执行程序
- gdb打印地址内容
- go汇编快速入门
- 常用的寄存器和用法
- AMD64
- ARM64
- loong64
- riscv64
- Go汇编常用命令及含义
- Go汇编和x86的区别
- 找到map的赋值指令
- Go中map的内存布局
- gdb中查看map结构
- map的存储结构
- map的内存布局
- 计算bmap偏移量
- 根据map的地址获取key和value
- 测试代码
- 获取key和value的值
- 操作指令介绍
- 根据map地址获取buckets地址
- 根据buckets地址获取keys的值
- 根据keys地址获取values的值
- 总结
背景
在逆向一个无符号可执行Go程序的时候,有个需求是获取map里面存储的值。但是只能拿到map的地址,以及知道key是string类型,其他的就不知道了。
那要怎么实现我们的需求呢?上GDB,读汇编,取地址。
下面是介绍一些前置知识,以及实操。实操部分的代码是写的测试代码,方便观看。
gdb调试Go程序
参考:
11.2. 使用 GDB 调试 | 第十一章. 错误处理,调试和测试 |《Go Web 编程》| Go 技术论坛
查看Golang程序的汇编的话,参考:Golang调试之GDB高级功能_go 实现的高级功能-CSDN博客
gdb调试Go程序的详细文档:GDB
GBD的多窗口管理和切换窗口: GDB调试之多窗口管理 (十二) - TechNomad - 博客园
Go的内存机制:一文彻底理解Go语言栈内存/堆内存 - 掘金
为什么不用dlv
不得不说,dlv要调试汇编的话,相比gdb来说还差点。特别是可视化还有取地址打印地址这块。
比如我想直接获取某个地址的值,或者打印寄存器的值之类的,确实不太方便,因此还是选择gdb来作为调试工具了。
当然,gdb调试Go程序有一个致命缺陷,那就是无法控制goroutine。这个问题目前博主还没找到解决方案,有类似经验的同学可以指点下博主,不胜感谢。
关于dlv可以参考: https://zhuanlan.zhihu.com/p/655096453
gdb调试Go可执行程序
这块网上文章比较多,大概介绍下怎么用gdb,以及使用到的命令。
开始调试
gdb demo # 开始调试可执行程序b main.main # 给main加断点run # 执行到断点处
源码和汇编窗口
layout src # 查看源码
layout asm # 查看汇编指令info win # 查看当前打开的窗口
focus cmd # 焦点回到cmd窗口,同样也可以回到源码或者汇编窗口
layout split # 分割窗口,同时打开cmd,源码,汇编框# 关闭窗口
tui disable
效果如下: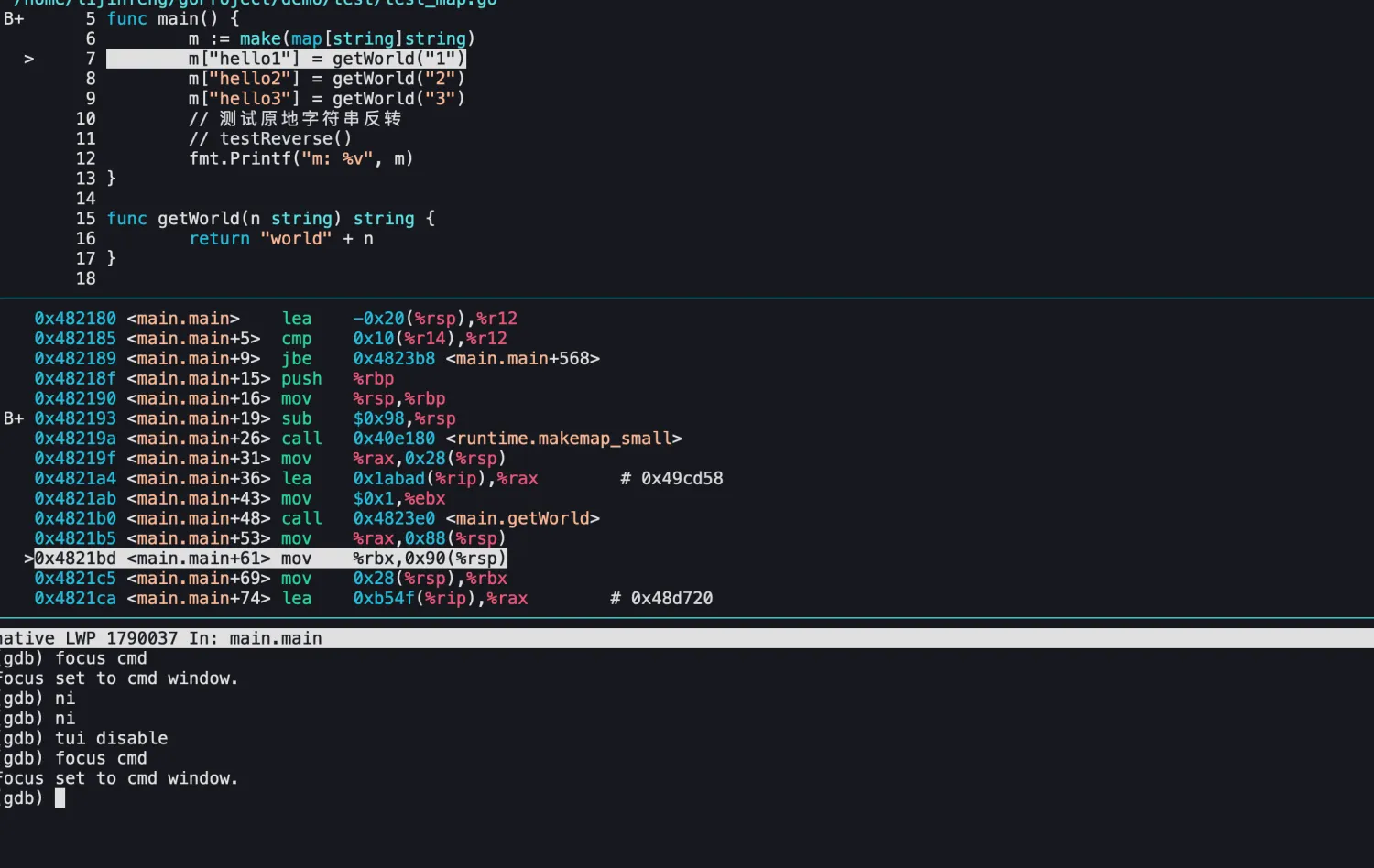
gdb打印地址内容
需要使用gdb中的x指令,通过help x来查看怎么使用。
格式: x /nuf
x 是 examine 的缩写
n 表示要显示的内存单元的个数
u 表示一个地址单元的长度:
- b 表示单字节
- h 表示双字节
- w 表示四字节
- g 表示八字节
f 表示显示方式, 可取如下值:
- x 按十六进制格式显示变量w
- d 按十进制格式显示变量
- u 按十进制格式显示无符号整型
- o 按八进制格式显示变量
- t 按二进制格式显示变量
- a 按十六进制格式显示变量
- si 指令地址格式
- c 按字符格式显示变量
- f 按浮点数格式显示变量
举例
x/3uh buf:表示从内存地址buf读取内容,h 表示以双字节为一个单位,3 表示三个单位,u 表示按十六进制显示
x/3gx addr: 从内存addr中,输出3个,g代表8个字节(int指针是8字节), x是十六进制的
x/144bx addr中 : 从内存,输出144个单字节的16进制数据
x/3cb addr: 从内存中,输出3个单字节,并且转换成字符的数据。一般是ascii
go汇编快速入门
参考:
go汇编学习: 初识Golang汇编
go文档的汇编解释:https://tip.golang.org/doc/asm
go文档的ABI定义: https://tip.golang.org/src/cmd/compile/abi-internal
通过上面的截图,我们看到了Go的汇编代码。大家基本在学习计算机的时候或多或少都会接触到汇编,不过Go的汇编会稍微有点区别,语法是基于Plan9的,Go 汇编器所用的指令,一部分与目标机器的指令一一对应,而另外一部分则不是,略有有点差异。
下面简单介绍一下汇编相关的知识,以及Go汇编的一些特性,顺带帮大家复习一波汇编知识。
常用的寄存器和用法
AMD64
amd64 架构使用以下 9 个寄存器序列来存储整数参数和结果:
RAX, RBX, RCX, RDI, RSI, R8, R9, R10, R11它使用 X0 – X14 来表示浮点参数和结果。
ARM64
arm64 架构使用 R0 – R15 来表示整数参数和结果。它使用 F0 – F15 来表示浮点参数和结果。
loong64
loong64 架构使用 R4 – R19 来表示整数参数和整数结果。它使用 F0 – F15 来表示浮点参数和结果。
riscv64
riscv64 架构使用 X10 – X17、X8、X9、X18 – X23 作为整数参数和结果。它使用 F10 – F17、F8、F9、F18 – F23 来表示浮点参数和结果。
Go汇编常用命令及含义
| 助记符 | 指令种类 | 用途 | 示例 |
|---|---|---|---|
| MOVQ | 传送 | 数据传送 | MOVQ 48, AX // 把 48 传送到 AX |
| LEAQ | 传送 | 地址传送 | LEAQ AX, BX // 把 AX 有效地址传送到 BX |
| PUSHQ | 传送 | 栈压入 | PUSHQ AX // 将 AX 内容送入栈顶位置 |
| POPQ | 传送 | 栈弹出 | POPQ AX // 弹出栈顶数据后修改栈顶指针 |
| ADDQ | 运算 | 相加并赋值 | ADDQ BX, AX // 等价于 AX+=BX |
| SUBQ | 运算 | 相减并赋值 | SUBQ BX, AX // 等价于 AX-=BX |
| CMPQ | 运算 | 比较大小 | CMPQ SI CX // 比较 SI 和 CX 的大小 |
| CALL | 转移 | 调用函数 | CALL runtime.printnl(SB) // 发起调用 |
| JMP | 转移 | 无条件转移指令 | JMP 0x0185 //无条件转至 0x0185 地址处 |
| JLS | 转移 | 条件转移指令 | JLS 0x0185 //左边小于右边,则跳到 0x0185 |
Go汇编和x86的区别
go tool compile -S -N -l test_map.go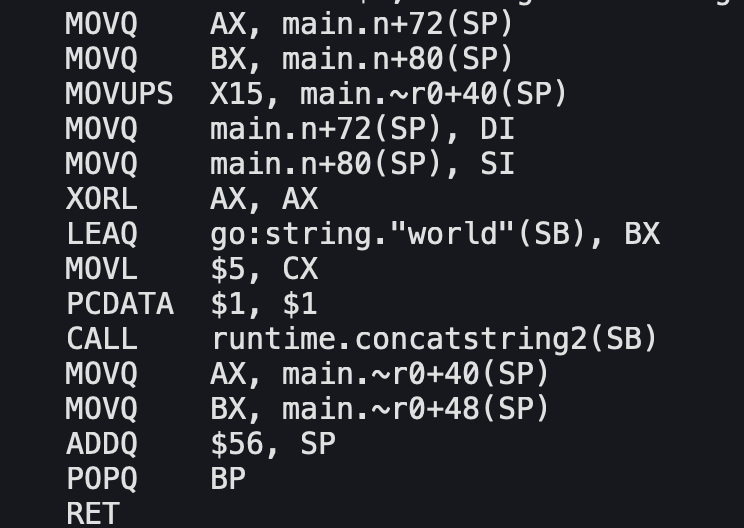
gdb调试中的汇编
TEXT runtime·profileloop(SB),NOSPLIT,$8MOVQ $runtime·profileloop1(SB), CXMOVQ CX, 0(SP)CALL runtime·externalthreadhandler(SB)RET
主要区别如下:
- go的汇编里面有Q后缀,例如MOVQ,含义等同于MOV,Q的意思是64位的汇编指令
- 汇编读取的顺序和x86的汇编是反的
- 例如:MOVQ $5,CX = mov rcx,5 # 移动5到CX寄存器,go的汇编是从左到右。x86是从右向左
- go源码中也有用汇编实现的功能,有兴趣可以看看:/usr/lib/go/src/math/big
找到map的赋值指令
一开始是打算直接看汇编找到map的赋值操作,然后取寄存器里面的value。可惜失败了,简单测试了以下几种map的赋值:
- 直接赋值常量,类似于m[“hello”] = “world”
- 调用函数赋值,类似于m[“hello”] = getWrold()
- 变量赋值,类似于m[“hello”] = test
# 直接赋值常量
mov rdx, (rax)# 调用函数获取world
mov rax 0x88(rsp)# 通过变量的方式
mov rcx, (rax)
然后分别查看这几种赋值的汇编,发现跟逆向的那个程序都不一样,从寄存器里面取不到,也没找到类似的赋值指令。
那可咋办呢?是否可以根据map的内存布局来找到value呢?理论上来说map存储的时候key和value都是连续的,我们只要找到存储的buckets,然后就可以通过偏移量找到值了才对。
Go中map的内存布局
看到这个标题,我死去的八股文记忆开始攻击我。这里面的东西挺多的,不是本文的重点,因此下面借鉴源码和其他人的博客简单介绍下。
gdb中查看map结构

可以看到,默认的buckets有8个桶。跟八股文对上了,map的动态扩容,以及溢出检测。
map的存储结构
type hmap struct {count intflags uint8B uint8noverflow uint16hash0 uint32buckets unsafe.Pointeroldbuckets unsafe.Pointernevacuate uintptrextra *mapextra
}# hmap的简单描述count : map中存储了几个元素
flags: 状态标识正在被写、buckets和oldbuckets在被遍历、等量扩容(Map扩容相关字段)
B : 计算buckets的个数,2的B次方。比如B=2代表需要4个buckets
buckets: 指针,数组的类型为[]bmap,实际存储的数据在这里
hash0: hash因子
oldbuckets: 扩容时使用,存放扩容前的buckets
noverflow: 溢出桶里bmap大致的数量# 有数据时候的bmap
type bmap struct {tophash [8]uint8keys [8]keytypevalues [8]valuetypepad uintptroverflow uintptr
}# bmap的简单描述
tophash: 计算hash的,遍历时使用
keys,values: 存储键值对
pad: 内存对齐使用
overflow: 指向的 hmap.extra.overflow 溢出桶里的 bmapmap的内存布局
参考:https://www.edony.ink/deep-insight-of-golang-map-with-gdb-ebpf/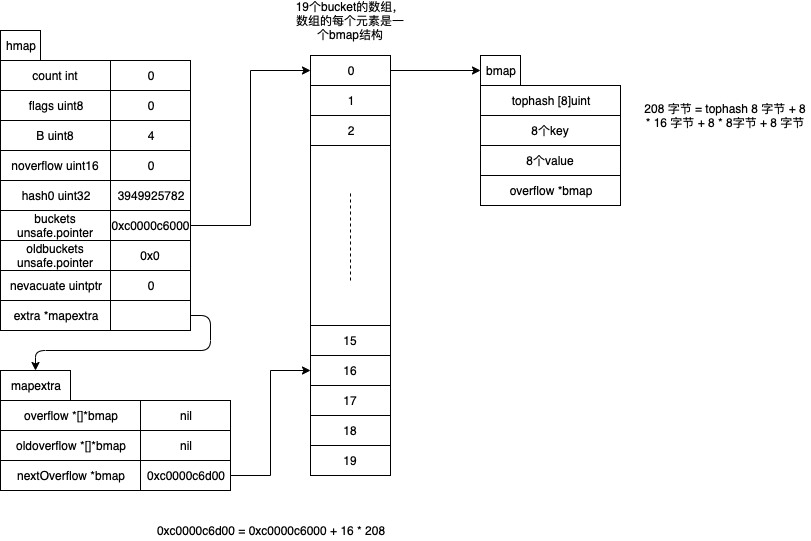
计算bmap偏移量
根据上面的截图,我们可以计算一个bmap占用多少字节。
# map定义: map[string]string
# string在go中是结构体,包含一个len和指向data的指针。
# 默认的指针和int都是8字节,因此一个string是16字节 8 + # tophash
16 * 8 + # key[8]
16 * 8 + # value[8]
8 # overflow bmap pointer
= 272
计算偏移量是为了方面找到bmap中的数据。比如有了第一个bmap的地址之后,可以通过+272的方式,找到第二个bmap的地址。
根据map的地址获取key和value
终于到重点了,有了前置知识之后,我们就可以使用gdb来操作map的地址,通过偏移量计算来获取到实际的值。
测试代码是随便写的一个map,实际逆向程序的时候也是类似的原理。
测试代码
package mainfunc main() {m := make(map[string]string)m["hello1"] = getWorld("1")m["hello2"] = getWorld("2")m["hello3"] = getWorld("3")
}func getWorld(n string) string {return "world" + n
}
获取key和value的值
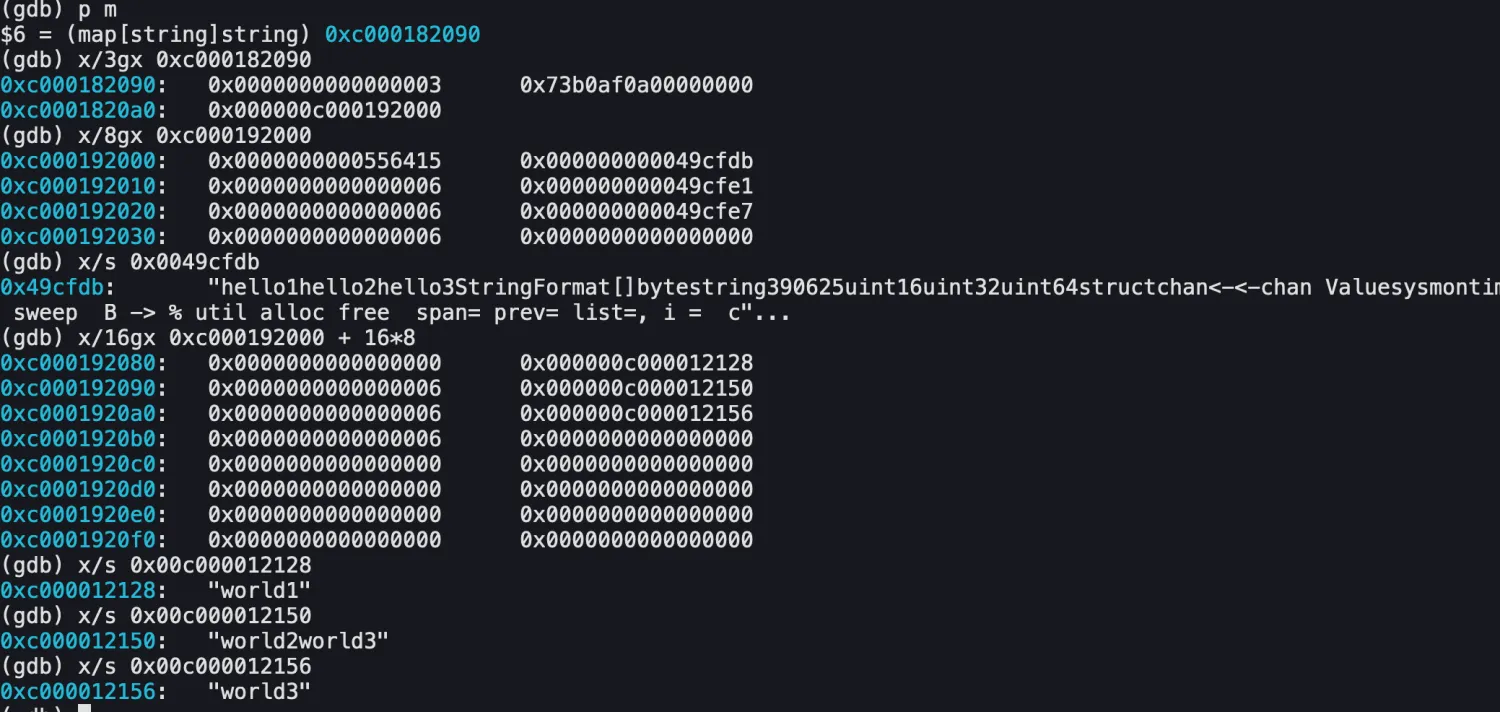
如图所示,我们根据map的地址就拿到了实际存储的key和value。
操作指令介绍
根据map地址获取buckets地址
x/3gx addr: 获取map中3个8字节的地址。第一个8字节: count(int=4字节) 第二个8字节:flags(uint8=1字节) + B(uint8=1字节) + noverflow + hash0(uint32=4字节)第三个8字节:buckets的入口地址
根据buckets地址获取keys的值
x/8gx addr: 获取buckets中8个8字节的数据,也就是8个int地址第一个8字节: tophash: 8个unit8 = 8字节第二个8字节: keys数组的入口x/s addr: 打印addr的字符串类型的值返回的是我们定义的hello1,hello2,hello3的值。# 为什么字符串这么多
内存中的字符串存储可能是连续的,除了我们存的24个字节之外,可能会有其他的数据在后面。
所以实际取字符串的值,应该是:地址+偏移量
根据keys地址获取values的值
x/16gx addr + 16*8: 偏移量是因为keys是string类型,且有8个,所以要计算偏移量第一个8字节: 字符串的len第二个8字节: values的第一个值x/s addr: 依次打印地址对应的字符串即可
总结
这篇博客主要也是对于八股文的一次实践吧,类似的八股文大家肯定也都看到过,但是实践可能会少一些。博主刚开始也没想到通过map的内存布局去找到value,中间走了不少弯路,也学到了很多,值得记录并分享给大家。
可能博主做这个事情的动机大家无法参考,但是中间的过程,工具的使用还是很有意义的。也越发明白了刚入行听到的那句话“源码面前,了无秘密”。
所有的高级语言最终都会编译成汇编,机器也只能识别二进制的数据。那么掌握这些知识,就像是手握锤子一样,看什么都像钉子,遇到什么疑难杂症都先敲两下,不至于束手无策了。
end




![【Hadoop】-HDFS的Shell操作[3]](https://img-blog.csdnimg.cn/direct/b7b40202df444d579b5d41c4e77eba55.png)