专栏规划: https://qibin.blog.csdn.net/article/details/137728228
首先说明一下,跟其他文章不太一样,在本篇文章中不会对Transformer架构中的自注意力机制进行讲解,而是后面单独1~2篇文章详细讲解自注意力机制,我认为由浅入深的先了解Transformer整体架构和其中比较简单的部分,后面再详细讲解自注意力更容易理解Transformer架构。
Transformer架构是Google在2017的著名的论文Attention Is All You Need中提出,Transformer的整体架构可以用以下这张著名的架构图来说明
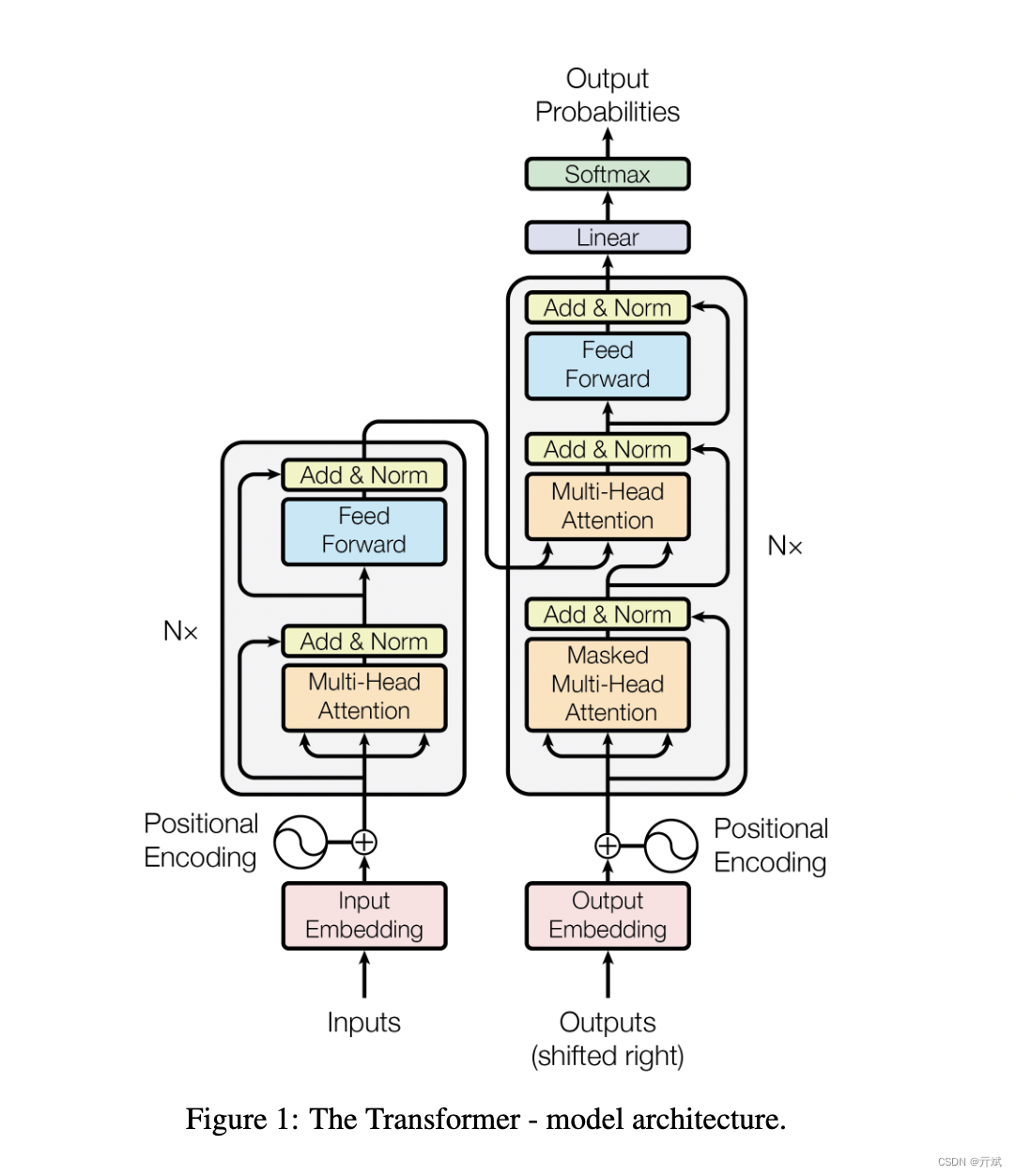
从架构图可以看出,Transformer由左右两部分组成,左边的叫encoder,右边的叫decoder,每一部分都有两个核心组件Multi-Head Attention和Feed Forward组成,所以encoder和deocoder在实现上其实区别不大,在现在比较流行的架构中,自然语言模型主要用到了Transformer右边的部分,也就是只用deocoder(例如GPT);而在视觉方向主要用到了encode