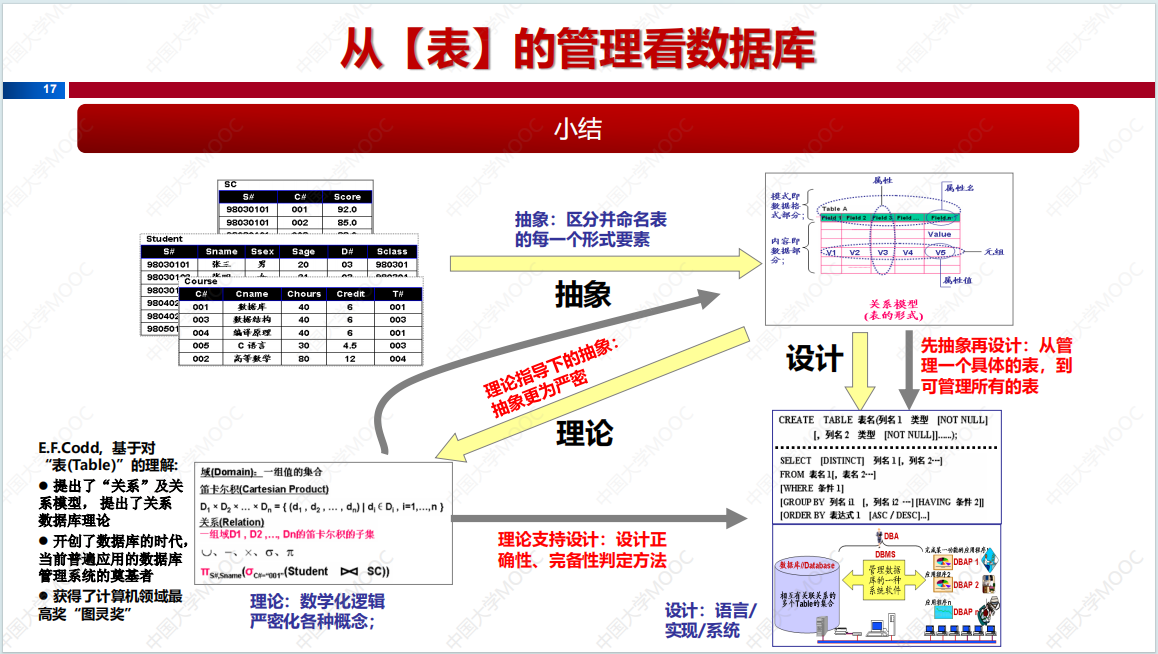
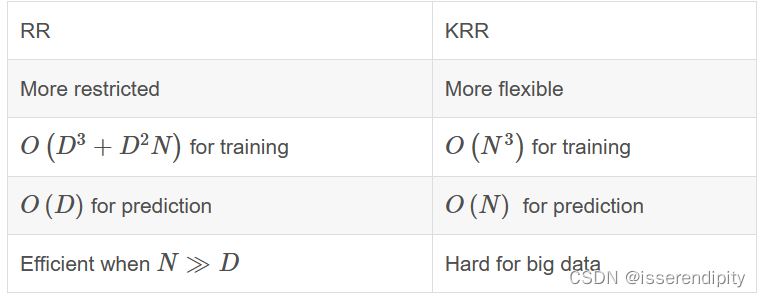
数据集划分是跟着up主魔傀面具做的,很好用很方便,推荐给大家,顺便做个例子讲一下怎么使用
把自己的图片数据集放在dataset/VOCdevkit/JPEGImages里面,看看自己的数据集格式,是JPEG还是png格式的还是其他。
然后就是把标注的文件放在dataset/VOCdevkit/Annotations,如果你的格式是xml格式
如果是txt格式的话,放在dataset/VOCdevkit/txt
标注文件的格式看的方法

看我的文件后缀就是.xml
或者打开属性

图片格式的查看也类似
我用一些数据来做个例子,我的数据集是100张,格式是JPG,标注文件是xml格式的
点击右键,不管是用pycharm还是vscode都可以

我用vscode为例子
如果是xml格式的标注文件,先运行xml2txt.py文件

在这之前,先配好自己的环境
vscode配置anaconda环境-CSDN博客
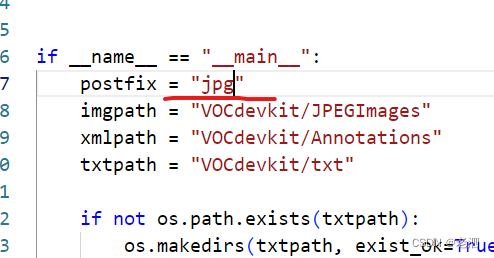
设置自己图片的格式,我的是jpg
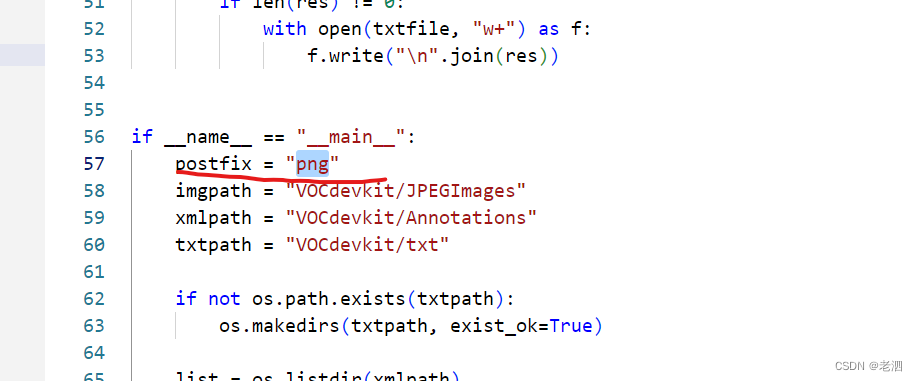
在vscode上方打开终端


先进入的dataset文件夹里
输入
cd dataset
最新一行的最后面是dataset,就说明进入dataset文件夹了
输入
python xml2txt.py
这就是转换好了,下面出现的的是类别的名字,把这个复制到data.yaml里面

接着是划分数据集,点开split_data.py
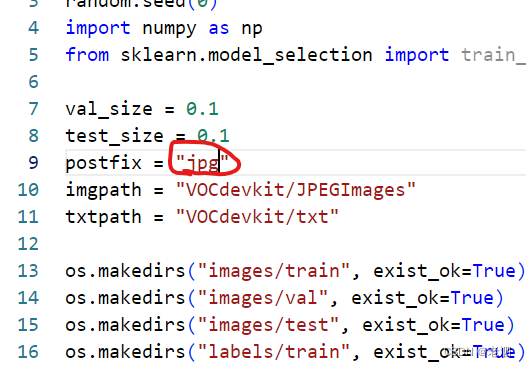
我的图片格式是jpg,自己看自己的格式是什么
这是划分的比例,一般来说都是8:1:1,这个就不用动了
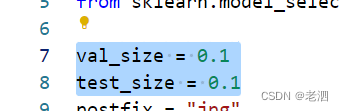
如果想划分成别的也可以,val_size是验证集占的比例,test_size是测试集占的比例,看你想设置多少,也可以设置为0
接着就是在终端输入
python split_data.py回车就可以了

这是我划分的结果,按照8:1:1分的,结果在dataset文件夹下又image和labels两个文件夹里放着,里面都是对应着放的

终端操作教程,前提是你的python文件都已经设置好了
按住shift加右键点击dataset文件
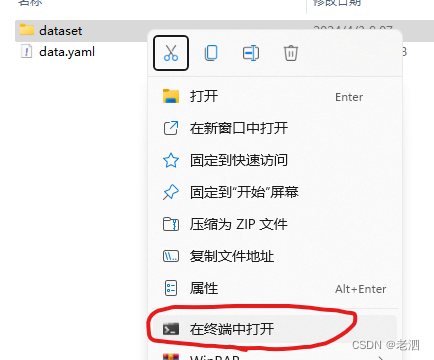

先选择自己的环境
这里不会的看我的其他文章,里面有介绍使用的
conda activate 自己环境的名字

如果自己的数据集格式是txt的直接运行
python split_data.py自己的数据集是xml格式的,先运行
python xml2txt.py然后再运行
python split_data.py这时候我的标注文件已经转换过txt了,这是我的运行结果

最后附上去代码链接
链接:https://pan.baidu.com/s/1wBYbKemcK67nVxmtSPundQ?pwd=0pdc
提取码:0pdc
--来自百度网盘超级会员V2的分享