每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

近年来,计算机视觉技术由于像COCO这样的综合基准数据集的推动而取得了飞速发展。但是,自COCO面世近十年后,其作为现代AI模型基准的适用性正受到质疑。其标注可能包含早期计算机视觉研究中的偏见和细微差别。随着模型在COCO数据集上的表现逐渐趋于平稳,人们担心过度拟合数据集的特定特征,可能限制了其在现实世界中的应用性。
下载:
COCONut: Modernizing COCO Segmentation
为了使COCO分割现代化,研究人员在本文中提出了COCONut——一种全新的、大规模的通用分割数据集。与之前创建大型数据集时常常为了扩展而牺牲标签精度不同,COCONut提供了383K张由人工验证的掩码标记图像。想象一下手工标注数百万个图像中的物体,这将需要数年时间!COCONut通过一个创新的辅助人工标注流程解决了这一挑战,该流程利用神经网络来增强人工标注者的工作效率。
这一流程包括四个关键阶段:机器生成预测、人工检查和编辑、掩码生成/精细化以及专家质量验证。在每个阶段,不同的神经模型分别处理“物体”(可数对象)和“非物体”(无定形区域)类,以确保标注的高质量。
但这个辅助人工流程是如何实际运作的呢?在第一阶段,边界框检测器和掩码分割器分别为“物体”和“非物体”类生成初步提议。人工标注者随后检查这些提议,并根据需要编辑或新增提议。精细化后的框和点被送入不同的模块生成最终的分割掩码。最后,专家标注者验证这些掩码的随机样本,重新标记任何不符合严格质量标准的掩码。
为了扩大数据集规模的同时保持质量,研究人员构建了一个数据引擎。它使用标注数据反复训练神经网络,为标注流程生成更优的提议。这一正向反馈循环,加上来自其他数据集的额外图像,最终形成了包含358K张图像和475万个掩码的COCONut-L分割。
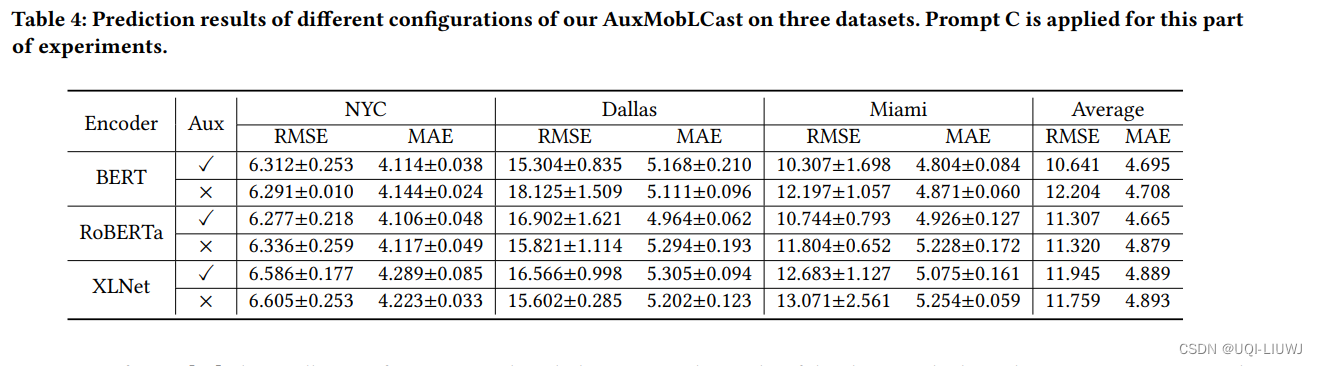
研究人员进行了全面分析,将COCONut的标注与纯人工标注进行了比较。他们的专家标注者在“物体”和“非物体”掩码上展现了高度一致性。与此同时,辅助人工流程显著加快了“物体”类的标注速度。COCONut分为三种规模——COCONut-S(118K张图像)、COCONut-B(242K张图像)和COCONut-L(358K张图像,带475万个掩码)。量化结果显示,随着训练集规模从COCONut-S扩展到COCONut-L,各种神经架构的表现都有所改善。
有趣的是,尽管较大的伪标签数据集带来的收益有限,但在完全由人工标注的COCONut-B上训练带来了最显著的性能提升。这强调了人工标注
数据对于训练强大的分割模型的重要性。
COCONut代表了COCO基准现代化的重大进步。凭借其精心人工验证的标注和严格策划的25K图像验证集(COCONut-val),它有望成为评估当代分割模型的更具挑战性的测试平台。COCONut的开源发布为开发更能力强大、更公正的计算机视觉系统铺平了道路,这些系统适用于现实世界的场景。




![[Linux][多线程][二][线程互斥][互斥量][可重入VS线程安全][常见锁概念]](https://img-blog.csdnimg.cn/direct/733562548c514e95bbf2acb6193d7aa4.png)
![[Algorithm][二分查找][山峰数组的峰顶索引][寻找峰值][寻找旋转排序数组中的最小值][0~n-1中缺失的数字]详细讲解](https://img-blog.csdnimg.cn/direct/9dcd330ba1a14067aa3d650756a76ec6.png)