一、配置环境
安装下面的顺序以及自己的文件路径配置环境
conda create -n opencompass python=3.10 -y安装下面的包
absl-py
accelerate>=0.19.0
boto3
cn2an
cpm_kernels
datasets>=2.12.0
einops==0.5.0
evaluate>=0.3.0
fairscale
func_timeout
fuzzywuzzy
immutabledict
jieba
langdetect
ltp
mmengine-lite
nltk==3.8
numpy>=1.23.4
openai
OpenCC
opencompass
opencv-python-headless
pandas<2.0.0
prettytable
pyext
pypinyin
python-Levenshtein
rank_bm25==0.2.2
rapidfuzz
requests==2.31.0
rich
rouge
-e git+https://github.com/Isaac-JL-Chen/rouge_chinese.git@master#egg=rouge_chinese
rouge_score
sacrebleu
scikit_learn==1.2.1
seaborn
sentence_transformers==2.2.2
tabulate
tiktoken
timeout_decorator
tokenizers>=0.13.3
torch>=1.13.1
tqdm==4.64.1
transformers>=4.29.1
typer
二、源码下载
# 下载源码
git clone -b 0.2.4 https://github.com/open-compass/opencompass# 配置环境依赖库
pip install -r /root/autodl-tmp/opencompass/requirements.txt# 解压评测数据集到 data/ 处
cp /share/temp/datasets/OpenCompassData-core-20231110.zip /root/autodl-tmp/opencompass/opencompass
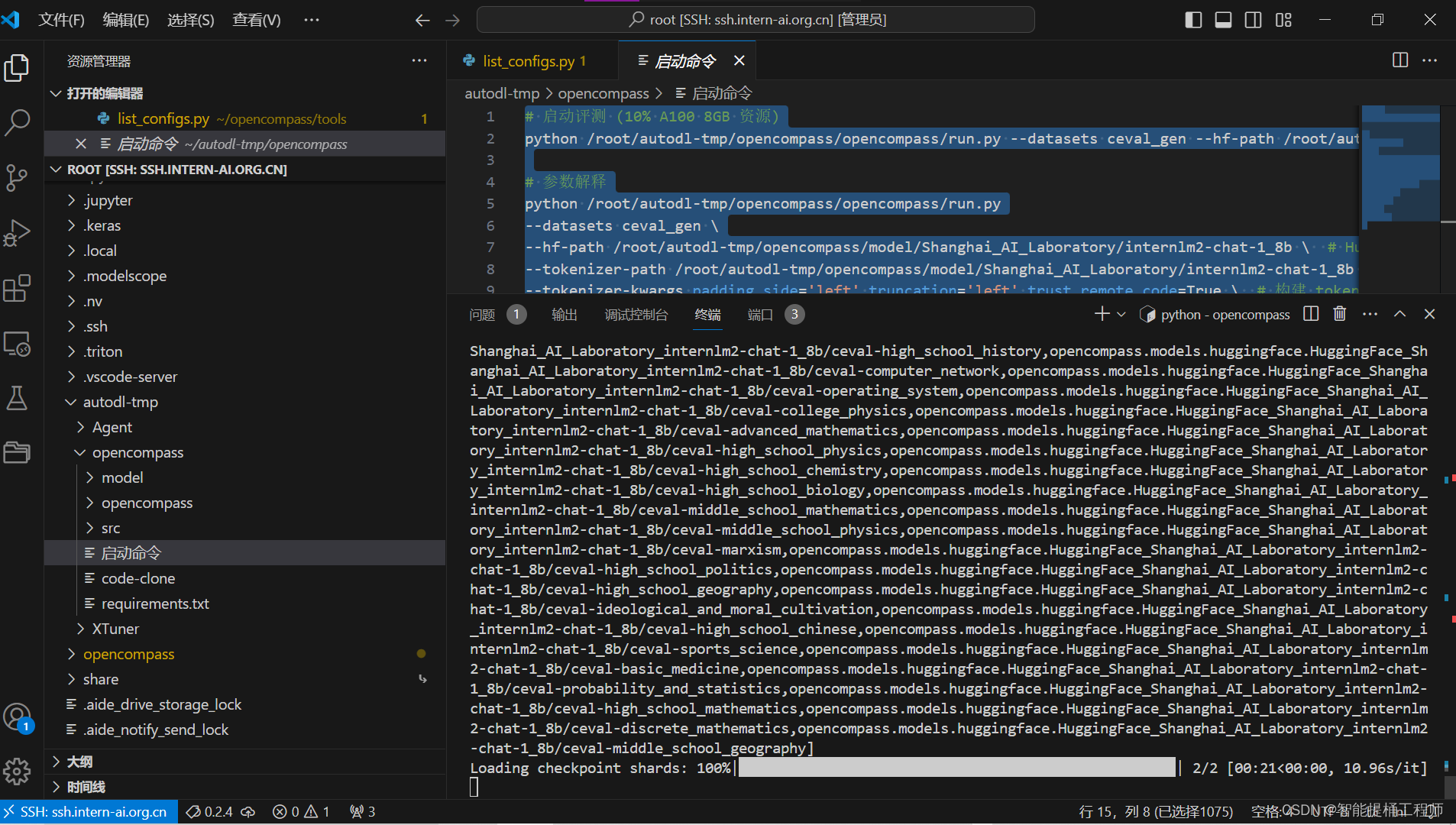
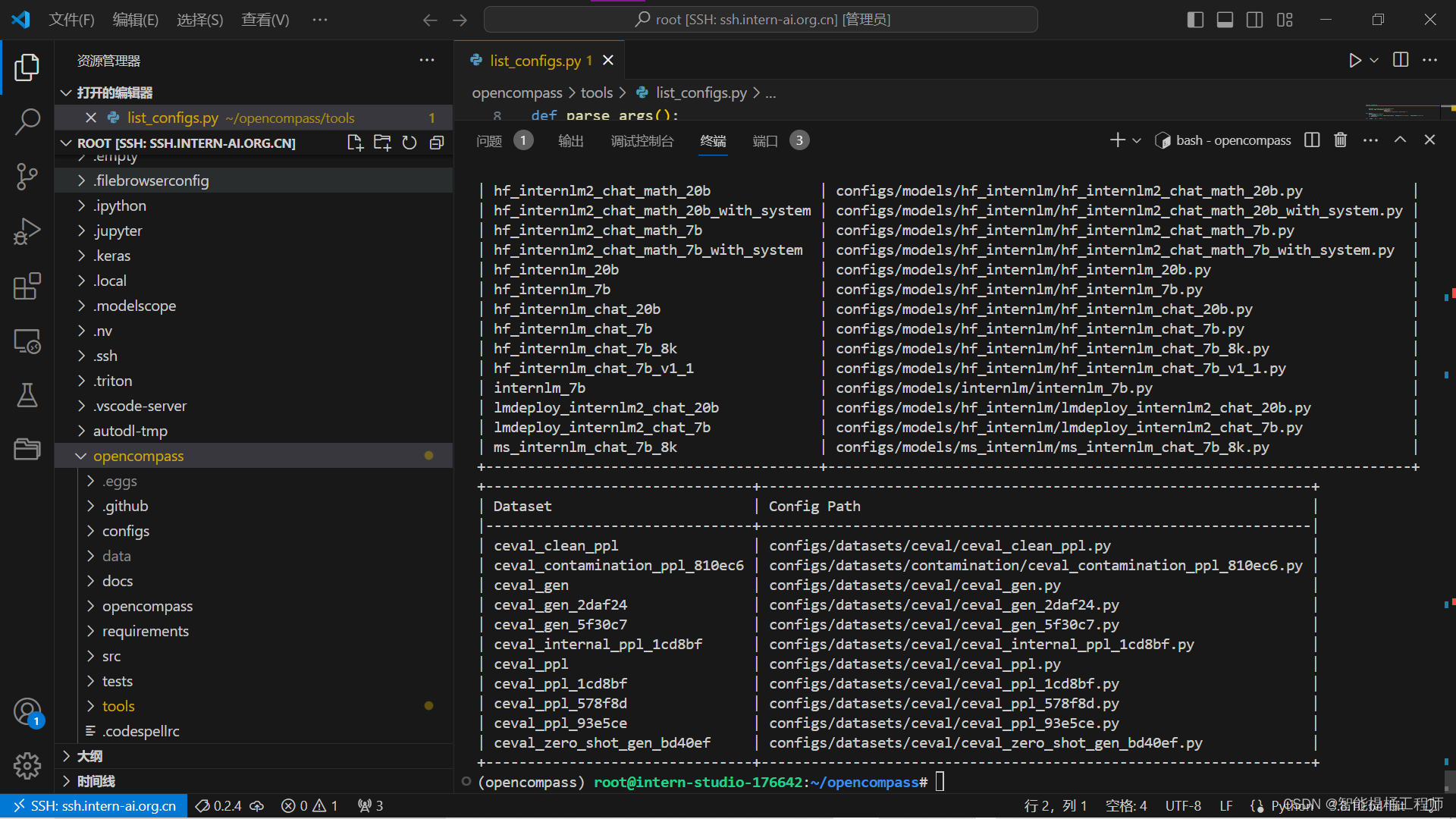
unzip /share/temp/datasets/OpenCompassData-core-20231110.zip# 列出所有跟 internlm 及 ceval 相关的配置
python /root/autodl-tmp/opencompass/opencompass/tools/list_configs.py打开配置之后可以看到如下结果
三、启动评测
执行下列命令
# 启动评测 (10% A100 8GB 资源)
python /root/autodl-tmp/opencompass/opencompass/run.py --datasets ceval_gen --hf-path /root/autodl-tmp/opencompass/model/Shanghai_AI_Laboratory/internlm2-chat-1_8b --tokenizer-path /root/autodl-tmp/opencompass/model/Shanghai_AI_Laboratory/internlm2-chat-1_8b --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True --max-seq-len 1024 --max-out-len 16 --batch-size 2 --num-gpus 1 # 参数解释
python /root/autodl-tmp/opencompass/opencompass/run.py
--datasets ceval_gen \
--hf-path /root/autodl-tmp/opencompass/model/Shanghai_AI_Laboratory/internlm2-chat-1_8b \ # HuggingFace 模型路径
--tokenizer-path /root/autodl-tmp/opencompass/model/Shanghai_AI_Laboratory/internlm2-chat-1_8b \ # HuggingFace tokenizer 路径(如果与模型路径相同,可以省略)
--tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True \ # 构建 tokenizer 的参数
--model-kwargs device_map='auto' trust_remote_code=True \ # 构建模型的参数
--max-seq-len 1024 \ # 模型可以接受的最大序列长度
--max-out-len 16 \ # 生成的最大 token 数
--batch-size 2 \ # 批量大小
--num-gpus 1 # 运行模型所需的 GPU 数量
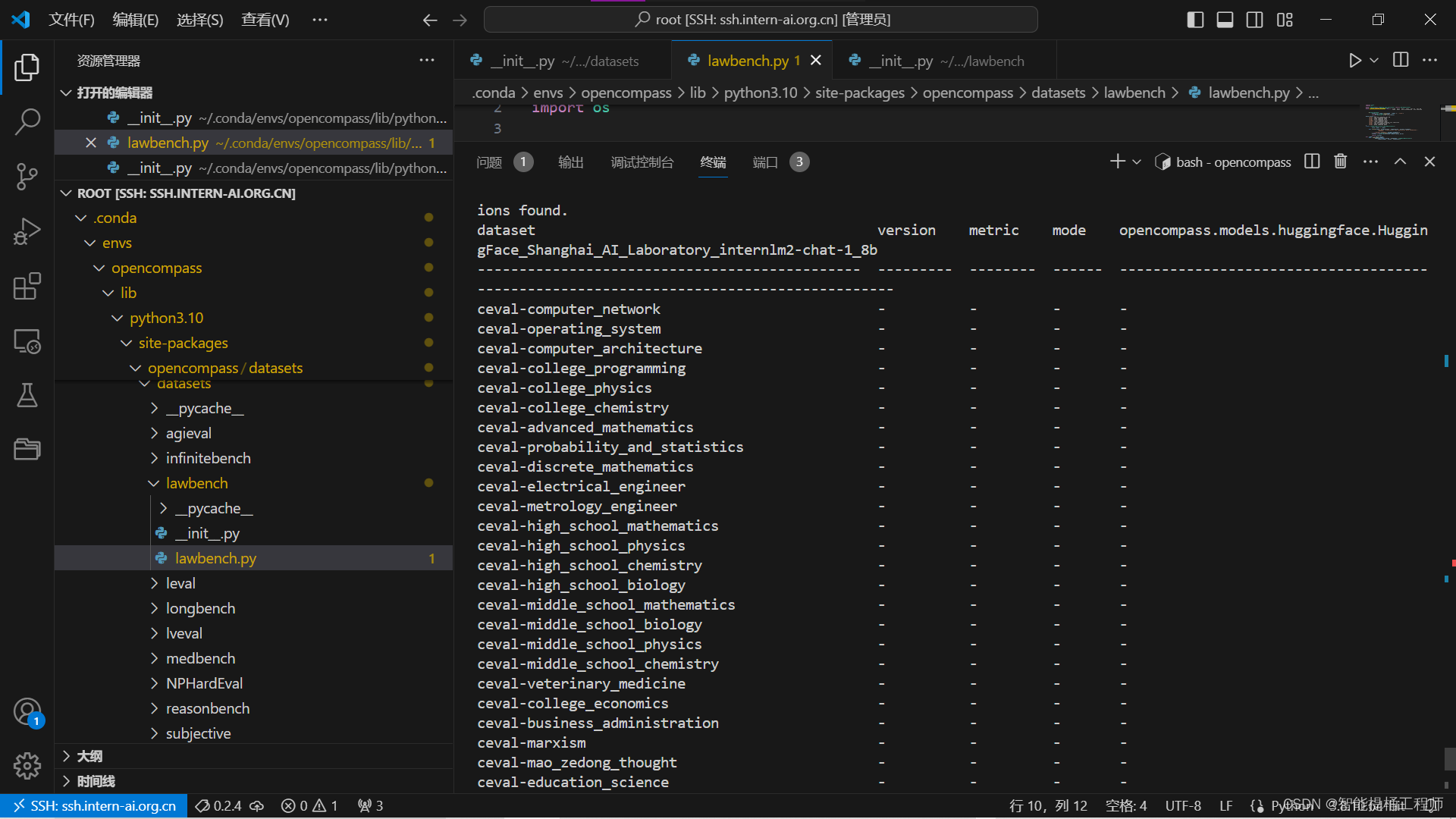
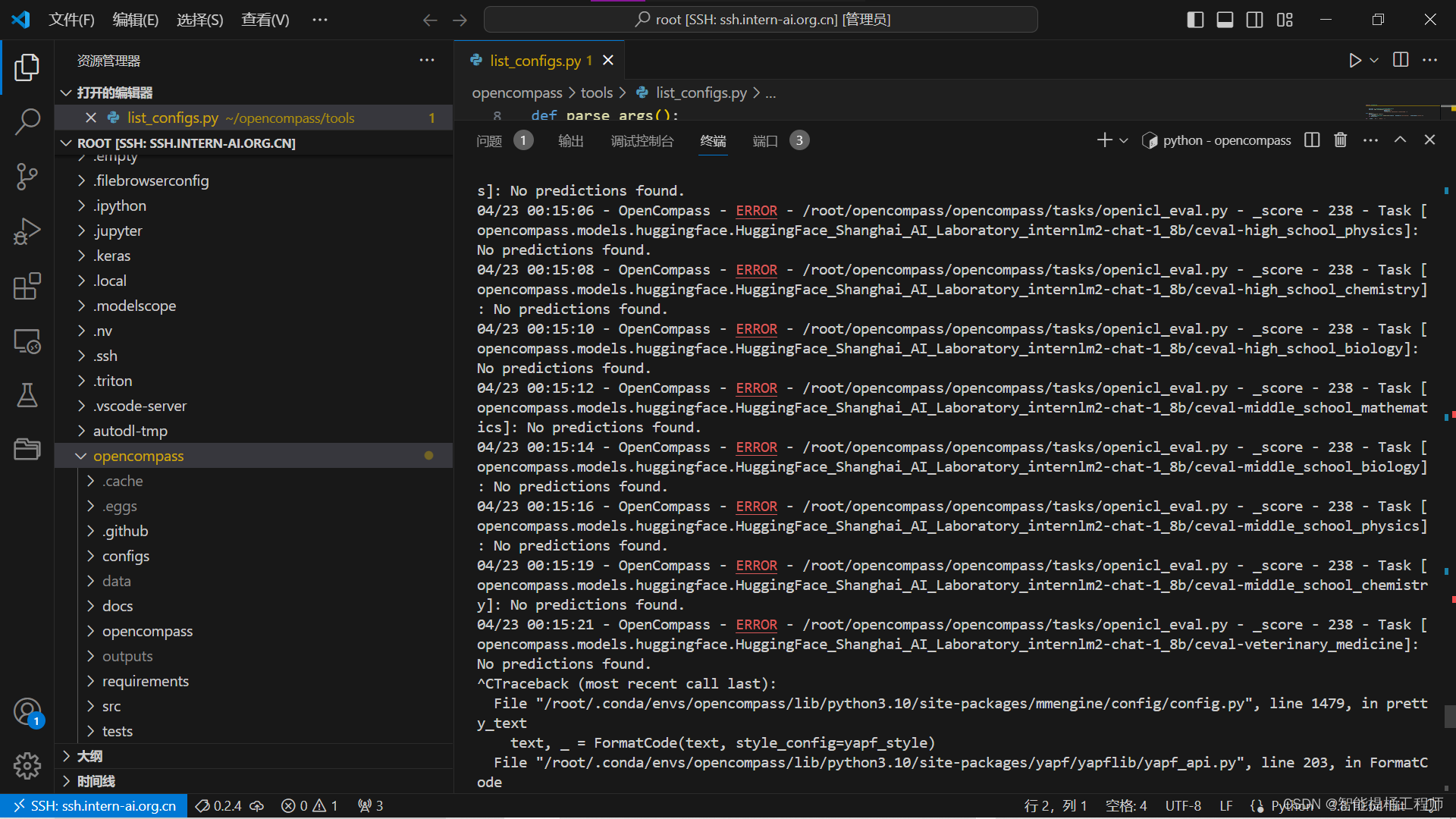
--debug结果如下:
模型加载