原文:安全验证 - 知乎
来源
题目:LLM Inference Performance Engineering: Best Practices
地址:https://www.databricks.com/blog/llm-inference-performance-engineering-best-practices
在这篇博文中,MosaicML工程团队分析了利用当下的开源大语言模型(LLM)进行生产部署的最佳实践。作者也基于这些模型提供了构建推理服务的指南,以帮助用户选择模型以及部署硬件。作者在生成环境中针对多种基于Pytorch的后端(比如FasterTransformers, vLLM, NVIDIA即将发布的TensorRT-LLM)进行了测试,这个指南也是基于此基础完成。
了解LLM文本生成
大型语言模型(LLM)通过两个步骤生成文本:
- 预填充(prefill):输入提示中的token被并行处理。
- 解码(decoding):文本采用自回归方式一次生成一个"token"。
每个生成的token都会附加到输入中,并反馈到模型中生成下一个token。当LLM输出一个特殊的停止token或满足用户定义的条件(如超过生成token的最大数量)时,生成就会停止。
Tokens可以是单词或分词;将文本分割成token的具体规则因模型而异。例如,您可以比较Llama模型和OpenAI模型如何将文本分割成token。虽然LLM推理提供商经常用基于token的指标(如tokens/秒)来衡量性能,但由于存在不同差异,这些衡量指标在不同模型类型之间常常不具备可比性。举个具体的例子,Anyscale团队发现Llama 2分词要比ChatGPT分词长19%(但总体成本仍然要低得多)。HuggingFace的研究人员还发现,在相同数量的文本中,Llama 2需要比GPT-4多花20%左右的token来进行训练。
LLM服务的重要指标
那么,应该如何考虑推理速度呢?
我们的团队使用四个关键指标来衡量LLM服务:
- 生成第一个token的时间(TTFT):用户输入查询后多久开始看到模型输出。在实时交互中,等待响应的时间越短越重要,但在离线工作负载中,等待响应的时间就没那么重要了。这一指标取决于处理提示和生成第一个输出token所需的时间。
- 生成每个输出token所需的时间(TPOT):为每个查询我们系统的用户生成一个输出token所需的时间。这一指标与每个用户如何感知模型的"速度"相对应。例如,TPOT为100ms/token,即为每个用户每秒生成10个token,或每分钟生成450个左右单词,这比一般人的阅读速度还要快。
- 延迟:模型为用户生成完整响应所需的总时间。整体响应延迟可通过前两个指标计算得出:延迟= (TTFT) + (TPOT)*(要生成的token数量)。
- 吞吐量:推理服务器每秒可为所有用户和请求生成的输出token数量。
我们的目标是什么?尽可能快地生成第一个token、最高的吞吐量以及输出每个token的时间尽可能短。换句话说,我们希望我们的模型能以最快的速度为尽可能多的用户生成文本。
值得注意的是,吞吐量和每个输出token所需的时间之间存在权衡:如果我们同时处理16个用户的查询,相比于按顺序进行查询,吞吐量会更高,但为每个用户生成输出token所需的时间会更长。
如果对整体的推理延迟有要求,以下是一些评估模型的有用建议:
- 输出长度主导整体响应延迟:对于平均延迟,通常只需将预期或者最大输出token长度乘以模型每个输出token的整体平均时间。
- 输入长度对性能影响不大,但对硬件要求很重要:在MPT模型中,增加512个输入token所增加的延迟比增加8个输出token所增加的延迟要少。但是,支持长输入的需求可能会增加模型的服务难度。例如,我们建议使用A100-80GB(或更新版本)为最大上下文长度为2048个token的MPT-7B提供服务。
- 总体延迟与模型大小呈亚线性关系:在相同硬件条件下,模型越大速度越慢,但速度比率并不一定与参数量比率相匹配。MPT-30B的延迟是MPT-7B的2.5倍。Llama2-70B的延迟是Llama2-13B的2倍。
经常有潜在客户要求我们提供平均推理延迟。我们建议您在确定具体的延迟目标之前(类似于“我们需要每个token的延迟时间小于20毫秒"),先花一些时间确定您的预期输入和预期输出长度。
LLM推理面临的挑战
优化LLM推理的常见手段有如下这些:
- 算子融合:将不同的相邻算子组合在一起,可以很好的降低延迟。
- 量化:对激活和模型权重进行压缩,以使用更少的bit数。
- 压缩:稀疏化或模型蒸馏。
- 并行:跨多个设备的张量并行或针对大模型的流水线并行。
除了这些方法,还有许多针对Transformer的重要优化。
一个典型的例子就是KV(key-value)缓存。在仅基于解码器的Transformer模型中,Attention机制的计算效率很低。每个token都会依赖之前的所有token,因此在生成每个新的token时都存在大量的重复计算。例如,在生成第N个token时,(N-1)个token会关注第(N-2)、第(N-3)一直到第1个token。同样地,在生成第(N+1)个token时,第N个token也需要关注第(N-1)、第(N-2)、第(N-3)一直到第1个token。KV缓存,即为注意力层保存中间的K/V值方便后续复用,避免重复计算。
内存带宽是关键
LLM中的计算主要由矩阵乘运算主导。在大多数硬件上,这些小维度运算通常受内存带宽限制。当以自回归方式生成token时,激活矩阵的维度(由batch size和序列中的token数量定义)在batch size小的情况下很小。因此,速度取决于我们将模型参数从GPU内存加载到本地缓存或寄存器的速度,而不是加载数据后的计算速度。推理硬件内存带宽的利用率比其峰值算力更能预测token生成的速度。
就服务成本而言,推理硬件的利用率非常重要。GPU价格昂贵,因此我们需其做尽可能多的工作。通过共享推理服务,合并来自多用户的工作负载、填补单个计算流中的气泡和batching多个请求提高吞吐来降低成本。对于像Llama2-70B这样的大模型,只有在batch size较大时才能获得更好的性价比。拥有一个能在大的batch size下运行的推理服务系统对于成本效益至关重要。然而,大batch意味着更大的KV缓存,这反过来又增加了为模型提供服务所需的GPU数量。这就是一场拉锯战,共享服务运营商需要对成本进行权衡,并进行系统优化。
模型带宽利用率(MBU)
LLM推理服务器的优化程度如何?
如前文所述,在较小的batch size,LLM推理(尤其是在解码时)受限于我们如何将模型参数从设备内存加载到计算单元的速度。内存带宽决定了数据移动的速度。为了衡量底层硬件的利用率,我们引入了一个新指标,称为模型带宽利用率(MBU)。MBU的定义是(实际的内存带宽)/(峰值内存带宽),其中实际的内存带宽为((模型参数总大小+KV缓存大小)/TPOT)。
例如,如果以16 bit精度运行的7B参数的TPOT等于14毫秒,也就是在14毫秒内要移动 14GB的参数,相当于每秒使用1TB的带宽。如果机器的峰值带宽为2TB/秒,那么对应的MBU为50%。为简单起见,本示例忽略了KV缓存大小,因为对于较小的batch size和较短的序列长度来说,KV缓存较小。MBU值接近100%,意味着推理系统有效利用了可用的内存带宽。MBU还有助于以标准化方式比较不同的推理系统(硬件+软件)。MBU是对模型浮点计算利用率(MFU,在PaLM论文中介绍)指标的补充,其中MFU在compute bound的环境中非常重要。
图1为MBU示例图,与roofline model类似。橙色区域的斜线表示在内存带宽100%完全饱和的情况下可能达到的最大吞吐量。然而,在实际情况中,对于小batch size(白点),观察到的性能会低于最大值--低多少是MBU的衡量标准。对于大batch size(黄色区域),系统是compute bound,所实现的吞吐量占峰值吞吐量的比例可以通过MFU来衡量。

图1:MBU(模型带宽利用率)和MFU(模型浮点计算利用率)。MBU和MFU分别是memory bound和compute bound时所占峰值的比例。MBU和MFU确定了在给定的硬件配置下,还有多少空间可以用于进一步提高推理速度。图2显示了基于TensorRT-LLM的推理服务器在不同张量并行度下测量的MBU。在传输大的连续内存块时,内存带宽利用率达到峰值。类似MPT-7B等较小的模型被分布在多个GPU上时,当每个GPU中移动的内存块较小,相应MBU会更低。

图2:在A100-40G GPU使用TensorRT-LLM时,观察不同张量并行度的MBU。请求:512个输入token的序列,batch size:1。如图3所示,使用NVIDIA H100 GPU观察不同张量并行度和batch size情况下的MBU。MBU随着batch size的增加而减少。然而,随着GPU规模的扩大,MBU的相对下降幅度并没那么明显。另外值得注意的是,选择内存带宽更大的硬件可以使用更少的GPU来提高性能。当batch size为1时,4xA100-40GB GPU对应的MBU为55%,而2xH100- 80GB GPU上可以实现更高的MBU,达到60%(如图2所示)。
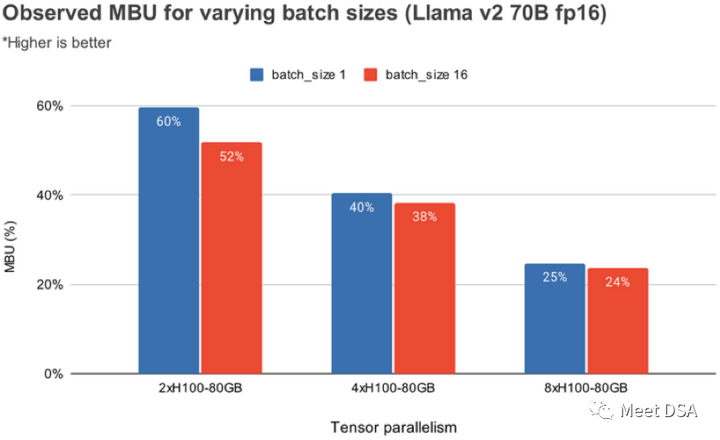
图3:在H100-80G GPU上,观察不同batch size和张量并行模式下的MBU。请求:512个输入token的序列。
基准测试结果
延迟
我们测量了MPT-7B和Llama2-70B模型在不同张量并行度下的第一个token生成时间(TTFT)和每个token的生成时间(TPOT)。随着输入提示时间的延长,生成第一个token的时间在总时延中的占比也增加。在多个GPU上实现张量并行有助于减少这种延迟。与模型训练不同的是,扩展到更多GPU对推理延迟的影响是明显递减的。例如,对于Llama2-70B,将GPU从4倍增加到8倍,在batch size较小的情况下,延迟只减少了0.7倍。其中一个原因是并行度越高,MBU越低(如前所述)。另一个原因是张量并行会带来GPU节点间的通信开销。

表1:当输入请求长度为512个token,batch size为1时,生成第一个token的时间。类似Llama2 70B较大的模型,至少需要4xA100-40B GPU才能装入内存。
batch size越大时,张量并行度越高,token延迟相对减少的幅度也就越大。图4显示了MPT-7B每个token输出的时间变化情况。在batch size为1时,GPU从两倍扩展到四倍,token延迟时间减少了约12%。在batch size为16时,4 GPU的延迟比2 GPU低33%。这与我们之前的观察结果一致,即与batch size为1相比,batch size为16时,张量并行度越高,MBU的相对减少幅度越小。

图4:在A100-40GB GPU上扩展MPT-7B时,对每个用户输出每个token所需的时间。延迟并不随着GPU数量的增加而线性增加。请求:128个输入token和64个输出token序列。
图5显示了Llama2-70B的类似结果,只是4 GPU和8 GPU之间的相对提升不太明显。我们还比较了两种不同硬件的GPU缩放情况。由于H100-80GB的GPU内存带宽是A100-40GB的2.15倍,对于4x系统,batch size为1时,延迟降低了36%;batch size为16时,延迟降低了52%。

图5:在多个GPU上扩展Llama-v2-70B时,对每个用户输出每个token所需的时间(输入请求:512个token长度)。注意,这里缺少1x40GB GPU、2x40GB和1x80GB GPU对应的数据,因为Llama-v2-70B(float16)不适合这些系统。
吞吐量
通过batching处理请求,可以权衡吞吐量和每个token所需的时间。与按顺序处理查询相比,在GPU评估期间对查询进行分组可提高吞吐量,但每个查询的完成时间会更长(忽略排队时间)。
以下是几种常见推理请求的批处理方式:
- 静态批处理(Static batching):客户端将多个提示打包到请求中,并在batching的所有序列完成后返回响应。我们的推理服务器支持这种方式,但并不要求这样处理。
- 动态批处理(Dynamic batching):在服务器内即时批处理提示。通常情况下,这种方法的性能比静态批处理差,但如果响应较短或长度一致,可以接近最佳性能。当请求具有不同参数时,这种方法效果不太好。
- 连续批处理(Continuous batching):有论文提出了在请求到达时将其batching在一起,目前是SOTA方法,即不是等待批次中的所有序列都完成,而是在请求到达时将序列以迭代分组在一起。与动态批处理相比,吞吐量可提高10-20倍。
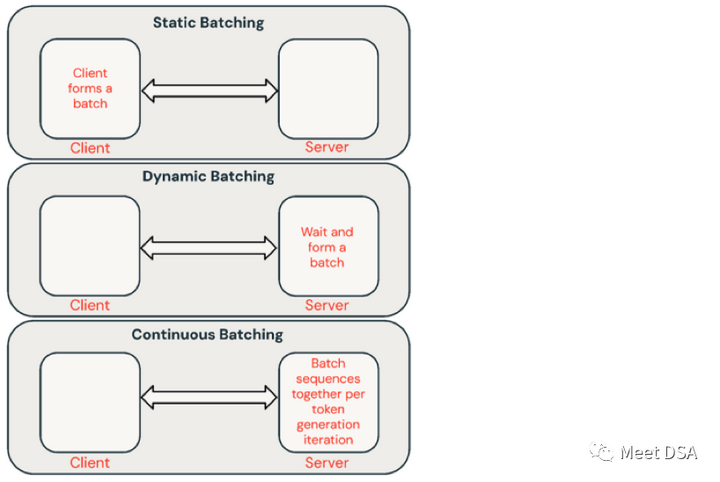
图6:LLM服务的不同批处理类型。批处理是一种提高推理效率的有效方法。
连续批处理通常是共享服务的最佳方法,但在某些情况下,其他两种方法可能更好。在低QPS环境中,动态批处理可能优于连续批处理。有时,在更简单的批处理框架中更容易实现底层GPU优化。对于离线批处理推理工作负载,静态批处理可以避免大量开销,并获得更高的吞吐量。
Batch Size
批处理的效果很大程度上取决于请求流。不过,我们可以通过对统一请求进行静态批处理的基准测试来确定其性能上限。

表2:使用静态批处理和基于FasterTransformers的后端时,MPT-7B的峰值吞吐量(req/sec)。请求:512个输入token和64个输出token。对于较大的输入,OOM边界将位于较小的batch size。
延迟的权衡
请求延迟随batch size的增加而增加。以NVIDIA A100 GPU为例,如果最大吞吐量对应的batch size为64,当batch从1增加到64时,吞吐量提升了14倍,而延时相应地增加了4倍。共享推理服务通常会选择均衡的batch size。自己部署模型的用户应根据自己的应用在延迟和吞吐量之间权衡。在某些应用(如聊天机器人)中,快速响应的低延迟是重中之重。而在其他应用中,比如批量处理非结构化PDF,可能希望牺牲处理单个文档的延迟来快速并行处理所有文档。
图7显示了7B模型的吞吐量与延迟曲线。曲线上的每一条线都是通过将batch size从1增加到256得到的,有助于确定在不同的延迟限制条件下,我们可以使用的batch size。回顾上面的roofline图,可以发现这些策略结果与预期一致。当batch size达到一定规模后,也就是进入compute bound状态,batch size每增加一倍,都只会增加延迟,而不会增加吞吐量。
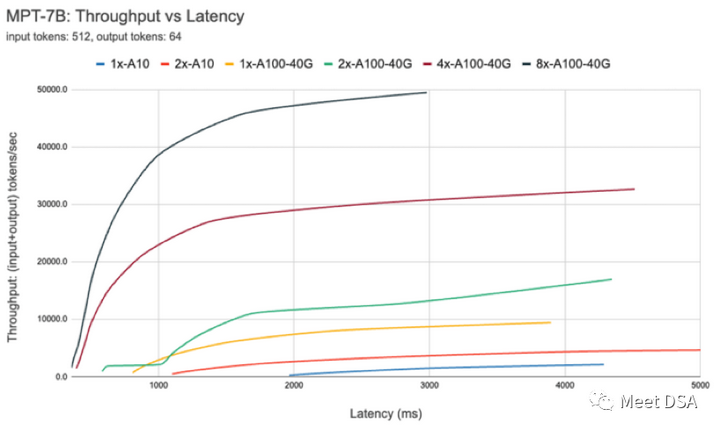
图7:MPT-7B模型的吞吐量延迟曲线。用户可以在延迟限制条件下选择满足吞吐量要求的硬件配置。使用并行时,了解底层硬件细节非常重要。比如,并非所有云服务商提供的8xA100实例都是相同的。有些服务器在所有GPU之间都是高带宽连接,而有些服务器的GPU是成对的,之间的通信带宽较低。这可能会出现瓶颈,导致实际性能与上述曲线出现明显偏差。
优化案例研究:量化
量化是降低LLM推理硬件要求的常用技术。在推理过程中,降低模型权重和激活的精度可以显著降低硬件要求。例如,在memory bound的环境中,将16 bit权重转换为8 bit权重可以将所需GPU的数量减半(如A100s上的Llama2-70B);将权重降至4 bit,则可以在消费级设备上运行推理(如在Macbook上运行Llama2-70B)。
根据我们的经验,应该谨慎使用量化。原始的量化技术会导致模型质量大幅下降。量化的影响会因模型架构(如MPT与Llama)、大小的不同而不同。
试着使用量化等技术时,我们建议使用像Mosaic Eval Gauntlet这样的LLM质量基准来评估推理系统的质量,而不是评估模型的某个单一指标。此外,探索更深层次的系统优化也很重要。特别是,量化可以使KV缓存更加高效。
如前所述,在token自回归生成过程中,注意力层之前的KV值会被缓存起来,而不用在每一步都重新计算。KV缓存的大小根据每次处理的序列数量和序列长度而变化。此外,在下一次token生成的迭代过程中,新的KV项会被添加到现有的缓存中,使缓存随着新token的生成而增大。
因此,在添加这些新值时,有效的KV缓存内存管理对于良好的推理性能至关重要。Llama2模型使用一类称为分组查询注意力(GQA)的注意变体。注意,当KV头数为1时,GQA与多查询注意力(MQA)相同。GQA通过共享KV值,有助于减少KV缓存。
计算KV缓存大小的公式:batch_size * seqLen * (d_modeL/n_heads) * n_Layers * 2 (K and V) * 2 (bytes per FLoat16) * n_kv_heads
表3显示了在序列长度为1024个token时,按不同batch size计算的GQA KV缓存大小。与70B模型相比,Llama2模型的参数大小是140 GB(Float16)。除了GQA/MQA,量化KV缓存是另一种减少KV缓存大小的方法,我们正在积极评估其对生成质量的影响。

表3:序列长度为1024时Llama-2-70B的KV缓存大小。如前所述,在batch size较小的情况下,LLM生成token是GPU内存带宽受限问题,即生成速度取决于模型参数从GPU内存移动到片上缓存的速度。将模型权重从FP16(2字节)转换为INT8(1字节)或INT4(0.5字节)所需的移动数据更少,因此可以加快token生成速度。但是,量化可能会对模型生成质量产生负面影响。我们目前正在使用Model Gauntlet评估其对模型质量的影响,并计划很快发布相关的后续博文。
结论和主要成果
上述每个因素都会影响构建和部署模型的方式,可以基于硬件类型、软件栈、模型架构以及典型的使用方式,并结合上面的结果来做出数据驱动的决策。以下是根据我们的经验提出的一些建议。
- 确定优化目标:是关心交互性能吗?最大化吞吐量?还是成本最小化?需要在这些方面进行权衡。
- 注意延迟的组成部分:对于交互式应用而言,第一个token生成的时间决定了服务的响应速度,而每个输出token的时间则决定了服务的速度。
- 内存带宽是关键:生成第一个token通常是compute bound,而随后的解码则是memory bound。由于LLM推理经常在memory bound的环境中运行,因此MBU是一个有用的优化指标,可用于比较推理系统的效率。
- 批处理至关重要:同时处理多个请求对于实现高吞吐量和有效利用昂贵的GPU至关重要。对于共享在线服务来说,连续批处理是必不可少的,而离线批处理推理工作负载可以通过更简单的批处理技术实现高吞吐量。
- 深度优化:标准的推理优化技术(如算子融合、权重量化)对LLM非常重要,但探索更深层次的系统优化也很重要,尤其是那些能提高内存利用率的优化。KV缓存量化就是一个例子。
- 硬件配置:应根据模型类型和预期工作量来决定部署的硬件。例如,当扩展到多个GPU时,较小模型(例如MPT-7B)的MBU下降速度比较大模型(LLaMA2-70B)快得多。随着张量并行化程度的提高,性能也会呈亚线性缩放。也就是说,如果流量很高,或者用户愿意为超低的延迟支付溢价,那么对于较小的模型来说,高度的张量并行性仍然是有意义的。
- 数据驱动决策:虽然理解理论很重要,但我们建议始终测量端到端的服务性能。实现推理部署的性能可能会比预期的差,原因有很多。由于软件效率低下,MBU可能出乎意料地低。或者云提供商之间的硬件差异也可能导致意外(我们观察到两个云提供商的8xA100服务器之间的延迟有2倍的差异)。