更多大厂面试内容可见 -> http://11come.cn
携程 Java 暑期实习一面:HashMap 的 key 可以设置为 null 吗?那 ConcurrentHashMap 呢?
Java 基础
1、Java 中有哪些常见的数据结构?
图片来源于:JavaGuide
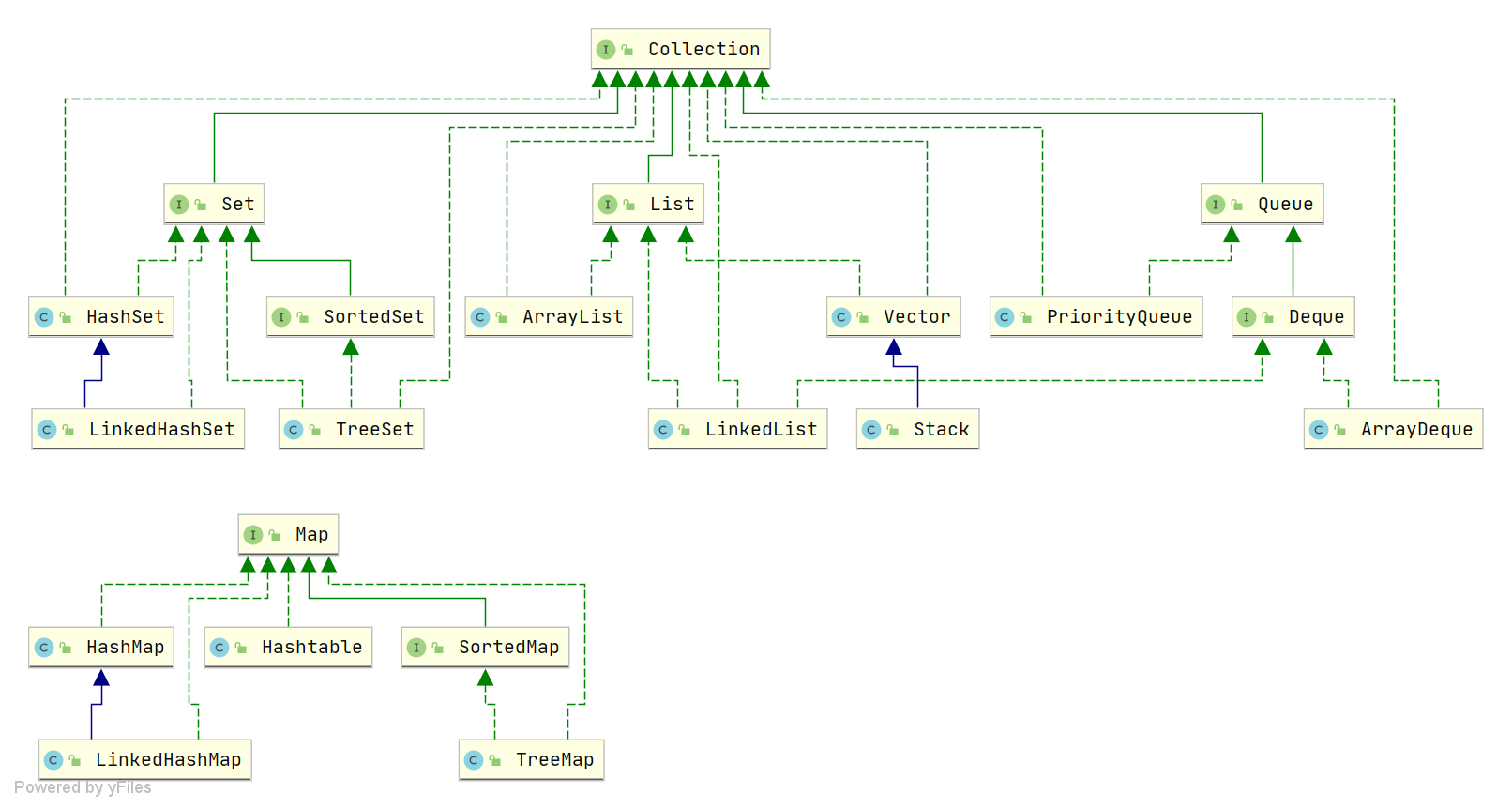
Java 中常见的数据结构包含了 List、Set、Map、Queue,在回答的时候,只要把经常使用的数据结构给说出来即可,不需要全部记住
如下:
List 列表: 有 ArrayList、LinkedList
1、ArrayList 是动态数组
2、LinkedList 是双向链表
Set 集合: 有 HashSet、LinkedHashSet、TreeSet
1、HashSet 基于 HashMap 实现,不保证元素的顺序,利用 Map 的 key 不能重复保证元素的唯一性
2、LinkedHashSet 继承自 HashSet,基于 LinkedHashMap 实现,通过链表维护元素的插入顺序
3、TreeSet 基于红黑树实现,元素自然排序或指定排序器排序
Map 哈希映射: 有 HashMap、LinkedHashMap、TreeMap、ConcurrentHashMap
1、HashMap 基于数组+链表+红黑树实现
2、LinkedHashMap 继承自 HashMap,通过链表维护元素插入顺序
3、TreeMap 基于红黑树实现,会对元素的 key 进行自然排序或指定排序器排序
4、ConcurrentHashMap 并发安全的 HashMap,在 JDK1.8 及以后通过 CAS + synchronized 实现线程安全
Queue 队列: 有 PriorityQueue、ArrayDeque
1、PriorityQueue 基于优先级堆的优先队列实现,元素自然排序或指定排序器排序
2、ArrayDeque 基于数组的双端队列
2、HashMap 介绍一下,key 可以设置为 null 吗?
HashMap 是哈希结构,存储 k-v 键值对,底层实现的话由数组+链表+红黑树进行实现
HashMap 中是可以存储 null 的 key 或 value 的,在 HashMap 中,为 null 的 key 只有一个,当传入 key 为 null 的时候,就会返回数组中索引为 0 的位置
3、ConcurrentHashMap 的 key 可以为 null 吗?
在 ConcurrentHashMap 中的 key 和 value 是不可以为 null 的
大家可以思考一下,为什么 HashMap 中 key 可以为 null,ConcurrentHashMap 中不可以呢?
ConcurrentHashMap 是并发安全的,因此是在多线程环境中使用的,如果 key 或者 value 可以为 null 的话,那么就会存在 二义性
因为一个线程在操作 ConcurrentHashMap 的时候,其他线程也有可能同时来进行修改,因此会存在 二义性 的问题:
如果 key 为 null,就无法区分这个 key 是否存在于 ConcurrentHashMap 中;如果 value 为 null,就无法区分这个 value 是不存在 ConcurrentHashMap 中还是该 value 被置为了 null
HashMap 中的 key 和 value 为什么可以为 null?
而 HashMap 中的 key 和 value 可以为 null 就是因为 HashMap 是并发不安全的,因此使用 HashMap 的话,都是在单线程环境下使用,一个线程操作的时候,其他的线程不会同时操作,因此不会存在二义性问题
那么为什么 ConcurrentHashMap 源码不设计成可以判断是否存在 null 值的 key?
如果 key 为 null,那么就会带来很多不必要的麻烦和开销。比如,你需要用额外的数据结构或者标志位来记录哪些 key 是 null 的,而且在多线程环境下,还要保证对这些额外的数据结构或者标志位的操作也是线程安全的。而且,key 为 null 的意义也不大,因为它并不能表示任何有用的信息。
4、如果多线程同时操作一个数据,会有什么问题,怎么解决?
会存在线程安全的问题,只需要控制多个线程之间的操作同步,并且对该变量添加 volatile 关键字,保证该变量对多个线程的可见性即可
控制多个线程之间操作同步的话,通过 synchronized 或者 ReentrantLock 进行控制即可
5、线程池介绍一下,线程池的参数中最大线程数可以设得比核心线程数小吗?
介绍线程池的时候,说一下线程池的几个核心参数,以及线程池的工作流程
线程池中重要的参数如下:
corePoolSize:核心线程数量maximumPoolSize:线程池最大线程数量 = 核心线程数+非核心线程数keepAliveTime:非核心线程存活时间unit:空闲线程存活时间单位(keepAliveTime单位)workQueue:工作队列(任务队列),存放等待执行的任务- LinkedBlockingQueue:无界的阻塞队列,最大长度为 Integer.MAX_VALUE
- ArrayBlockingQueue:基于数组的有界阻塞队列,按FIFO排序
- SynchronousQueue:同步队列,不存储元素,对于提交的任务,如果有空闲线程,则使用空闲线程来处理;否则新建一个线程来处理任务
- PriorityBlockingQueue:具有优先级的无界阻塞队列,优先级通过参数Comparator实现。
threadFactory:线程工厂,创建一个新线程时使用的工厂,可以用来设定线程名、是否为daemon线程等等。handler: 拒绝策略 ,有4种- AbortPolicy :直接抛出异常,默认策略
- CallerRunsPolicy:用调用者所在的线程来执行任务
- DiscardOldestPolicy:丢弃阻塞队列里最老的任务,也就是队列里靠前的任务
- DiscardPolicy :当前任务直接丢弃
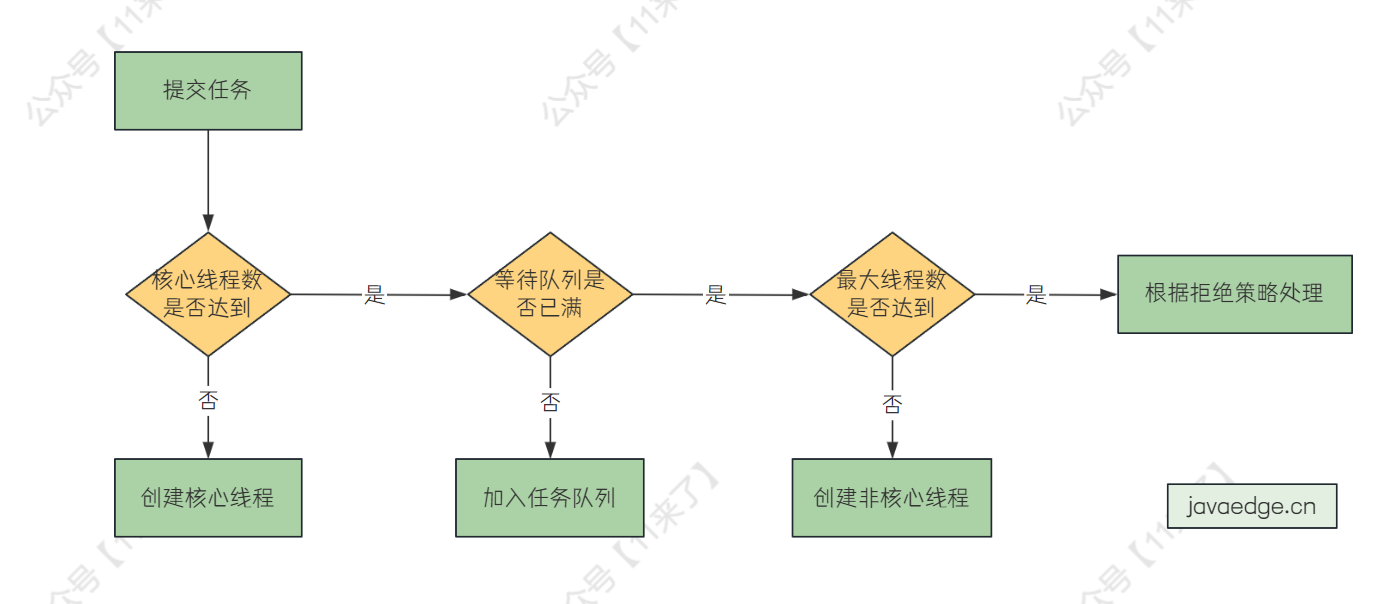
新加入一个任务,线程池处理流程如下:
- 如果核心线程数量未达到,创建核心线程执行
- 如果当前运行线程数量已经达到核心线程数量,查看任务队列是否已满
- 如果任务队列未满,将任务放到任务队列
- 如果任务队列已满,看最大线程数是否达到,如果未达到,就新建非核心线程处理
- 如果当前运行线程数量未达到最大线程数,则创建非核心线程执行
- 如果当前运行线程数量达到最大线程数,根据拒绝策略处理
线程池的参数中最大线程数可以设得比核心线程数小吗?
这个一般对于线程池有了解的都不会这么设置,最大线程数 = 核心线程数 +非核心线程数,所以最大线程数不可能比核心线程数还要小,这是错误的使用方式