every blog every motto: You can do more than you think.
https://blog.csdn.net/weixin_39190382?type=blog
0. 前言
detr之encoder逐行梳理
1. 整体
encoder由encoder layer构成
输入进encoder的特征shape:(hw,b,c),后文将给出说明
class Transformer(nn.Module):def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,activation="relu", normalize_before=False,return_intermediate_dec=False):super().__init__()# encoder layerencoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,dropout, activation, normalize_before)encoder_norm = nn.LayerNorm(d_model) if normalize_before else None# encoder 部分self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)... # 略def forward(self, src, mask, query_embed, pos_embed):# flatten bxCxHxW to HWxbxCbs, c, h, w = src.shape# (b,c,h,w) ->(b,c,hw) -> (hw,b,c) src = src.flatten(2).permute(2, 0, 1)# (b,c,h,w) ->(b,c,hw) -> (hw,b,c) pos_embed = pos_embed.flatten(2).permute(2, 0, 1)# (b,h,w) -> (b,hw)mask = mask.flatten(1)memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)... # 略
2. 部分
2.1 get_clone
用于对指定的层进行复制
def _get_clones(module, N):return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
2.2 Encoder
串联多个layer,输出作为输入
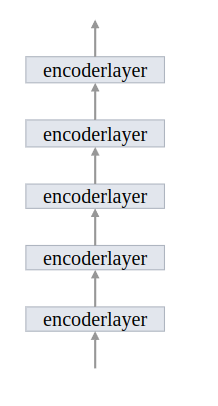
class TransformerEncoder(nn.Module):def __init__(self, encoder_layer, num_layers, norm=None):super().__init__()# 对指定的层进行复制self.layers = _get_clones(encoder_layer, num_layers)self.num_layers = num_layersself.norm = normdef forward(self, src,mask: Optional[Tensor] = None,src_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None):output = srcfor layer in self.layers:# 输出作为输入output = layer(output, src_mask=mask,src_key_padding_mask=src_key_padding_mask, pos=pos)if self.norm is not None:output = self.norm(output)return output
2.3 EncoderLayer
结构:
最开始的输入是backone的输出,即,src,后续的输入是上一层的输出
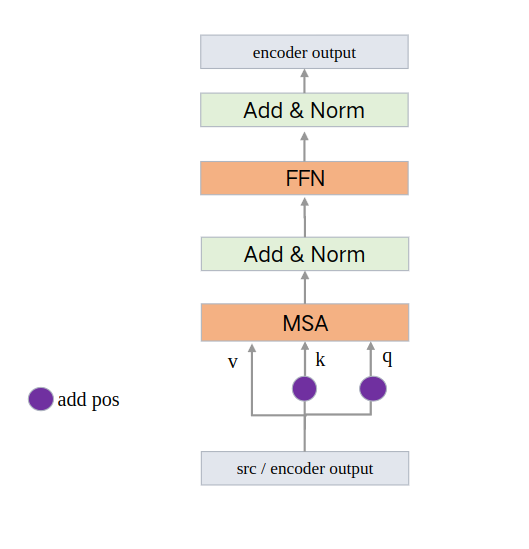
其中forward包含forward_post和forward_pre两个函数,主要区别是最开始进行标准化还是最后进行标准化。
由于self.normalize_before默认是False,所以默认是forward_post ,如下方的局部代码所示
q 和 k = backbone输出特征图 + 位置编码
这里对query和key增加位置编码 是因为需要在图像特征中各个位置之间计算相似度/相关性, 而value作为原图像的特征 和 相关性矩阵加权,
从而得到各个位置结合了全局相关性(增强后)的特征表示,所以q 和 k这种计算需要+位置编码 而v代表原图像不需要加位置编码
其中注意力计算主要涉及到两个参数:
-
key_padding_mask: 这部分就是我们在backbone中获取的mask,
记录backbone生成的特征图中哪些是原始图像pad的部分 这部分是没有意义的
计算注意力会被填充为-inf,这样最终生成注意力经过softmax时输出就趋向于0,相当于忽略不计。 -
attn_mask: 是在Transformer中用来“防作弊”的,即遮住当前预测位置之后的位置,忽略这些位置,不计算与其相关的注意力权重
在encoder中通常为None,不使用,因为要计算全局的相关性。 decoder中才使用
forward_post局部代码:
def with_pos_embed(self, tensor, pos: Optional[Tensor]):return tensor if pos is None else tensor + posdef forward_post(self,src,src_mask: Optional[Tensor] = None,src_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None):q = k = self.with_pos_embed(src, pos) # q,k都添加位置编码# 计算# key_padding_mask: 记录backbone生成的特征图中哪些是原始图像pad的部分 这部分是没有意义的# 计算注意力会被填充为-inf,这样最终生成注意力经过softmax时输出就趋向于0,相当于忽略不计# attn_mask: 是在Transformer中用来“防作弊”的,即遮住当前预测位置之后的位置,忽略这些位置,不计算与其相关的注意力权重# 而在encoder中通常为None 不适用 decoder中才使用src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,key_padding_mask=src_key_padding_mask)[0]# 残差连接src = src + self.dropout1(src2)# 标准化src = self.norm1(src)# FFNsrc2 = self.linear2(self.dropout(self.activation(self.linear1(src))))# 残差连接src = src + self.dropout2(src2)# 最后进行标准化src = self.norm2(src) return src
默认batch_first = False

所以输入的形式是(l,batch,d),即我们最开始看到的(hw,b,c)

输出两个值,第一个是计算结果,第二个是权重。只需要第一个所以上面用了[0]

EncoderLayer完整代码:
class TransformerEncoderLayer(nn.Module):def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,activation="relu", normalize_before=False):super().__init__()self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)# Implementation of Feedforward modelself.linear1 = nn.Linear(d_model, dim_feedforward)self.dropout = nn.Dropout(dropout)self.linear2 = nn.Linear(dim_feedforward, d_model)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)self.activation = _get_activation_fn(activation)self.normalize_before = normalize_beforedef with_pos_embed(self, tensor, pos: Optional[Tensor]):return tensor if pos is None else tensor + posdef forward_post(self,src,src_mask: Optional[Tensor] = None,src_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None):q = k = self.with_pos_embed(src, pos)src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,key_padding_mask=src_key_padding_mask)[0]src = src + self.dropout1(src2)src = self.norm1(src)src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))src = src + self.dropout2(src2)src = self.norm2(src) # 最后进行标准化return srcdef forward_pre(self, src,src_mask: Optional[Tensor] = None,src_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None):src2 = self.norm1(src) # 最开始进行标准化q = k = self.with_pos_embed(src2, pos)src2 = self.self_attn(q, k, value=src2, attn_mask=src_mask,key_padding_mask=src_key_padding_mask)[0]src = src + self.dropout1(src2)src2 = self.norm2(src)src2 = self.linear2(self.dropout(self.activation(self.linear1(src2))))src = src + self.dropout2(src2)return srcdef forward(self, src,src_mask: Optional[Tensor] = None,src_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None):# 默认是Falseif self.normalize_before:return self.forward_pre(src, src_mask, src_key_padding_mask, pos)return self.forward_post(src, src_mask, src_key_padding_mask, pos)
参考
- https://blog.csdn.net/weixin_39190382/article/details/137905915?spm=1001.2014.3001.5502
- https://hukai.blog.csdn.net/article/details/127616634