对数据库而言,合适的字符集和 collation 规则能够大大提升使用者运维和分析的效率。TiDB 从 v4.0 开始支持新 collation 规则,并于 TiDB 6.0 版本进行了更新。本文将深入解读 Collation 规则在 TiDB 6.0 中的变更和应用。
引
这里的“引”,有两层含义,这第一层是“ 引言”,从 TiDB v6.0 发版说明 中可以了解到,TiDB 6.0 引入了很多新特性,同时也引入了新的 发版模型 ,本文将对 TiDB 6.0 新特性一睹为快。
第二层含义是“抛砖 引玉”,开源社区的力量是无穷尽的,希望有更多人可以参与到开源中来,那么如何参与开源,其实途径远不止提交代码一种,比如,在 AskTUG 社区提问、回答、互动,再如,发现 TiDB 官方文档 有 Bug 或信息不完整,提出 Issue 和解决方案,又如,参与 TiDB 6.0 Book Rush! 活动,做版本评测、案例文章等等。
默认启用新 Collation 规则
| 1 | TiDB 从 v4.0 开始支持新 collation 规则,在大小写不敏感、口音不敏感、padding 规则上与 MySQL 行为保持一致。
|
TiDB 6.0 默认采用新的 Collation 规则。新 Collation 规则虽已在 TiDB 4.0 引入,但一直都是默认关闭项,只有集群初始化时才能变更。可通过系统表看到该变量值的设定。
| 1 2 3 4 5 6 7 | TiDB [(none)] 18:45:27> select * from mysql.tidb where variable_name = 'new_collation_enabled';
+-----------------------+----------------+----------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE | COMMENT |
+-----------------------+----------------+----------------------------------------------------+
| new_collation_enabled | True | If the new collations are enabled. Do not edit it. |
+-----------------------+----------------+----------------------------------------------------+
1 row in set (0.003 sec)
|
查看 I_S.collations 表,可以知道 TiDB 6.0 已支持 11 种规则,较之前未启用新 collation 框架的版本新增了 5 种规则,分别是 gbk_bin, gbk_chinese_ci, utf8_general_ci, utf8_unicode_ci, utf8mb4_unicode_ci。
由于很多旧系统使用的是 GBK 字符集,所以在做系统重构的项目,尤其涉及到数据迁移的情况时,对于 GBK 字符集的支持就显得尤为重要和实用。当然,对于新项目,建议使用 UTF8mb4。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | TiDB [(none)] 18:45:51> select version()\G
*************************** 1. row ***************************
version(): 5.7.25-TiDB-v6.0.0
1 row in set (0.001 sec)
TiDB [(none)] 18:46:00> SELECT * FROM information_schema.collations;
+--------------------+--------------------+------+------------+-------------+---------+
| COLLATION_NAME | CHARACTER_SET_NAME | ID | IS_DEFAULT | IS_COMPILED | SORTLEN |
+--------------------+--------------------+------+------------+-------------+---------+
| ascii_bin | ascii | 65 | Yes | Yes | 1 |
| binary | binary | 63 | Yes | Yes | 1 |
| gbk_bin | gbk | 87 | | Yes | 1 | (#28645)
| gbk_chinese_ci | gbk | 28 | Yes | Yes | 1 | (#28645)
| latin1_bin | latin1 | 47 | Yes | Yes | 1 |
| utf8_bin | utf8 | 83 | Yes | Yes | 1 |
| utf8_general_ci | utf8 | 33 | | Yes | 1 |
| utf8_unicode_ci | utf8 | 192 | | Yes | 1 | (#18678)
| utf8mb4_bin | utf8mb4 | 46 | Yes | Yes | 1 |
| utf8mb4_general_ci | utf8mb4 | 45 | | Yes | 1 |
| utf8mb4_unicode_ci | utf8mb4 | 224 | | Yes | 1 | (#18678)
+--------------------+--------------------+------+------------+-------------+---------+
11 rows in set (0.001 sec)
TiDB [test] 19:05:14> SHOW CHARACTER SET;
+---------+-------------------------------------+-------------------+--------+
| Charset | Description | Default collation | Maxlen |
+---------+-------------------------------------+-------------------+--------+
| ascii | US ASCII | ascii_bin | 1 |
| binary | binary | binary | 1 |
| gbk | Chinese Internal Code Specification | gbk_chinese_ci | 2 |
| latin1 | Latin1 | latin1_bin | 1 |
| utf8 | UTF-8 Unicode | utf8_bin | 3 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_bin | 4 |
+---------+-------------------------------------+-------------------+--------+
6 rows in set (0.001 sec)
|
而在 TiDB v5.4 未启用新 Collation 的结果为:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | TiDB-v5.4 [test] 10:17:22> select version()\G
*************************** 1. row ***************************
version(): 5.7.25-TiDB-v5.4.0
1 row in set (0.001 sec)
TiDB-v5.4 [test] 10:19:39> SELECT * FROM information_schema.collations;
+----------------+--------------------+------+------------+-------------+---------+
| COLLATION_NAME | CHARACTER_SET_NAME | ID | IS_DEFAULT | IS_COMPILED | SORTLEN |
+----------------+--------------------+------+------------+-------------+---------+
| utf8mb4_bin | utf8mb4 | 46 | Yes | Yes | 1 |
| latin1_bin | latin1 | 47 | Yes | Yes | 1 |
| binary | binary | 63 | Yes | Yes | 1 |
| ascii_bin | ascii | 65 | Yes | Yes | 1 |
| utf8_bin | utf8 | 83 | Yes | Yes | 1 |
| gbk_bin | gbk | 87 | Yes | Yes | 1 |
+----------------+--------------------+------+------------+-------------+---------+
6 rows in set (0.001 sec)
|
新 Collation 注意事项
对于 TiDB 6.0 之前的版本,该配置项的默认值一直为 false ,但可以在集群初始化之前就改变其设定,如此就可以在集群初始化之后使用新的 collation 框架。
| 1 2 3 | service_configs:
tidb:
new_collations_enabled_on_first_bootstrap: true
|
不过,这里要强调注意的是,当 TiDB 集群跨大版本升级时,需要检查配置项。以免出现上下游集群字符校验规则不一致而导致数据不同步或查询结果不一致的情况。另外,当使用 BR 进行数据备份、恢复时,也需要注意 Collation 的设置,保证备份前、恢复后的集群设置相同,防止出现因配置项 new_collations_enabled_on_first_bootstrap 设定不同而报错。
Collation Bug 修复
TiDB 6.0 中修复了2个关于 Collation 的 Bug,分别与比较函数和 JSON 相关,下面举两个小案例对其进行测试。
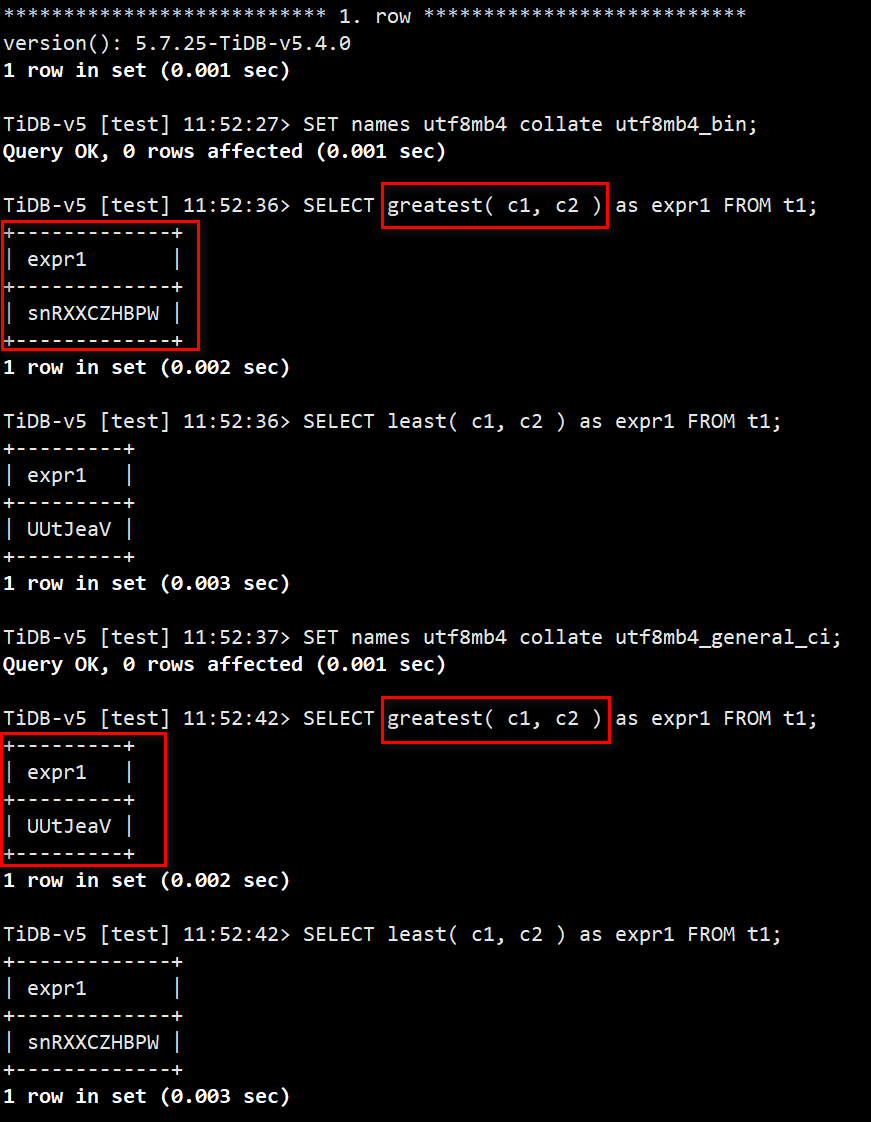
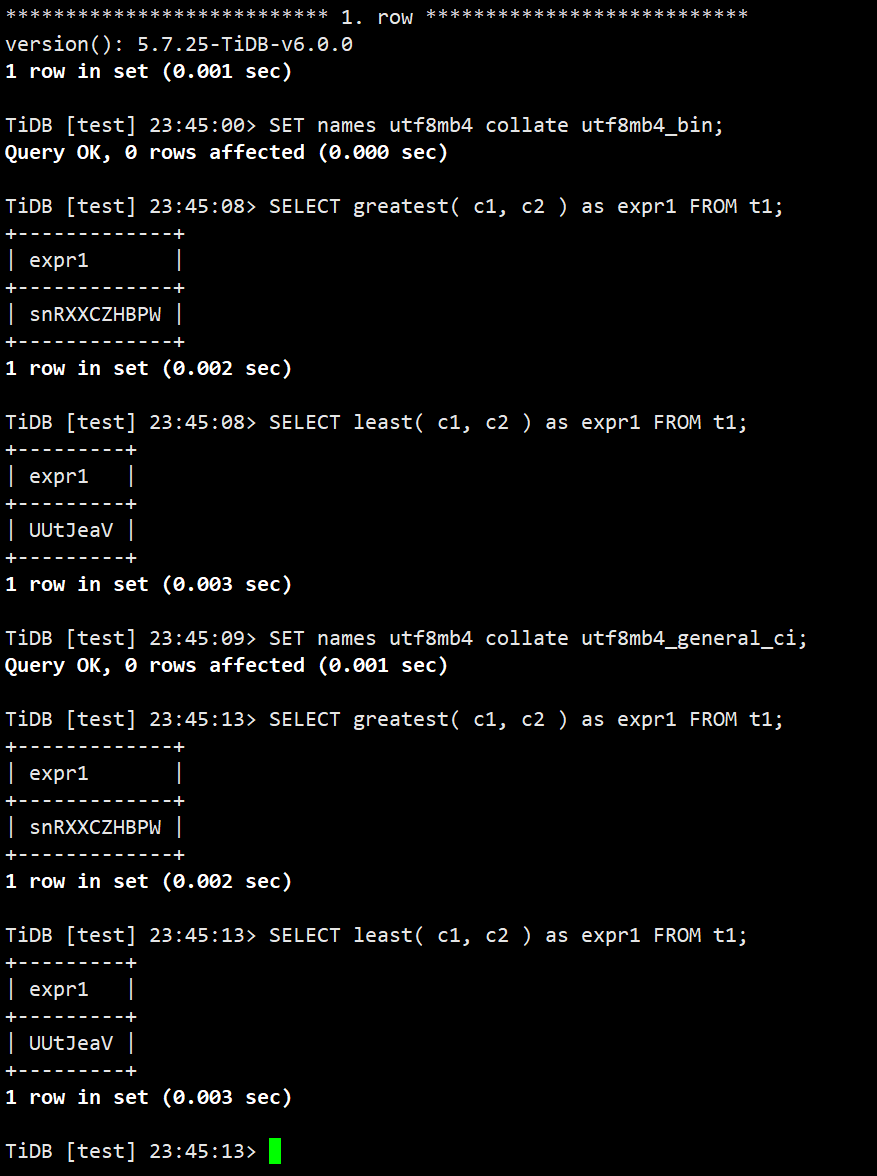
- 修复带有 collation 的 greatest 或 least 函数结果出错的问题 #31789
测试用例:
| 1 2 3 4 5 6 7 8 9 10 11 | DROP TABLE IF EXISTS t1;
CREATE TABLE t1 (
c1 char(20) CHARACTER SET utf8 COLLATE utf8_bin,
c2 char(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin);
INSERT INTO t1 VALUES ('UUtJeaV','snRXXCZHBPW');
SET names utf8mb4 collate utf8mb4_bin;
SELECT greatest( c1, c2 ) as expr1 FROM t1;
SELECT least( c1, c2 ) as expr1 FROM t1;
SET names utf8mb4 collate utf8mb4_general_ci;
SELECT greatest( c1, c2 ) as expr1 FROM t1;
SELECT least( c1, c2 ) as expr1 FROM t1;
|
测试结果:
2. 修复了 json 类型在 builtin-func 中推导 collation 错误的问题 #31320
修复这个问题的主要代码如下,期望表现是与 MySQL 一致,在使用 JSON 类型的内部方法时,应当始终使用 utf8mb4_bin 规则。
| 1 2 3 4 5 | // The collation of JSON is always utf8mb4_bin in builtin-func which is same as MySQL
// see details https://github.com/pingcap/tidb/issues/31320#issuecomment-1010599311
if isJSON {
dstCharset, dstCollation = charset.CharsetUTF8MB4, charset.CollationUTF8MB4
}
|
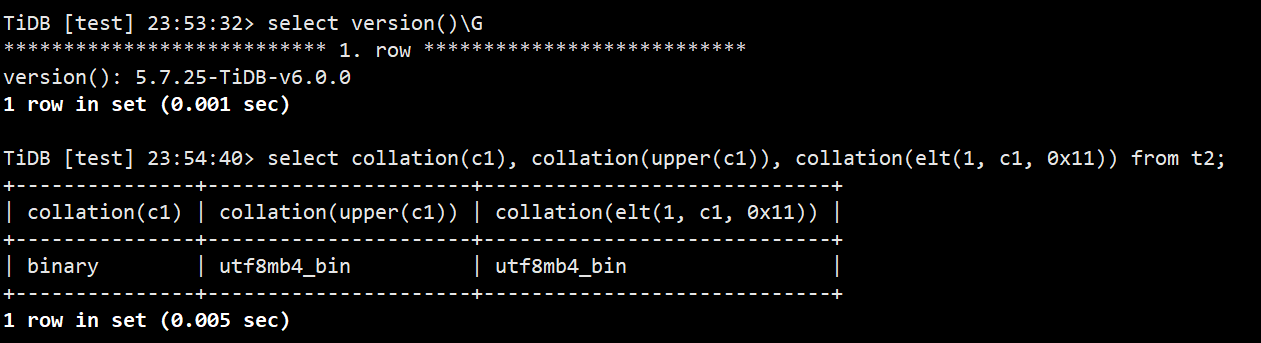
测试用例:
| 1 2 3 4 | DROP TABLE IF EXISTS t2;
CREATE TABLE t2 (c1 json);
INSERT INTO t2 VALUES ('{\"测试\": \"你好\"}');
SELECT collation(c1), collation(upper(c1)), collation(elt(1, c1, 0x12)) FROM t2;
|
测试结果:
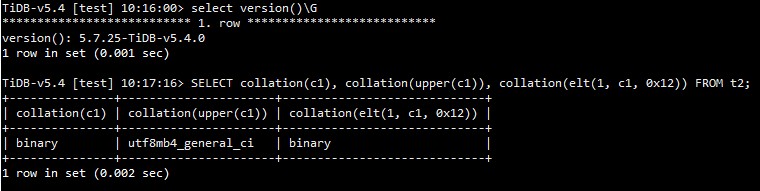
在 TiDB v5.4 中的测试结果为:
新增内置函数 CHARSET()
TiDB 6.0 新增了一个新内置函数,用来判定入参的字符集,这与 Collation 是相关联的,所以一并举例演示。注:从 Issue #3931 记录来看,这个需求早在 2017 年就提出来了,但是到 6.0 才合并到主干代码。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | TiDB [test] 23:54:42> select version()\G
*************************** 1. row ***************************
version(): 5.7.25-TiDB-v6.0.0
1 row in set (0.001 sec)
TiDB [test] 00:03:51> set names utf8mb4;
Query OK, 0 rows affected (0.000 sec)
TiDB [test] 00:03:58> select charset(1);
+------------+
| charset(1) |
+------------+
| binary |
+------------+
1 row in set (0.001 sec)
TiDB [test] 00:04:03> select charset('1');
+--------------+
| charset('1') |
+--------------+
| utf8mb4 |
+--------------+
1 row in set (0.001 sec)
|
文档拾遗
正如开篇所提到的,参与开源的途径有很多种,我们从开源中收益,自然也要回馈社区。
举一个实际例子,在写本文查阅文档时,就发现了 Collations 这节在 v6.0 (DMR) 版本下的查询结果集与实际不符,于是便进行了反馈。
在 GitHub 上提交了 Issue,处理速度也很快,第二天就已经完成初步修改,现处 Merge 到 master。
末
本文对 Collation 特性在 TiDB 6.0 中的变更进行了汇总阐释及举例说明,当前 TiDB 所提供的几种 Collation 已经可以支撑大部分业务场景,和大部分系统迁移需求建议在项目设计之初,就选用普适类型的字符集和规则,毕竟效率是提升生产力的重要因素之一。