一、RNN快速入门
1.学习单步的RNN:RNNCell
# -*- coding: utf-8 -*-
import tensorflow as tf# 参数 a 是 BasicRNNCell所含的神经元数, 参数 b 是 batch_size, 参数 c 是单个 input 的维数,shape = [ b , c ]
def creatRNNCell(a,b,c):# 请在此添加代码 完成本关任务# ********** Begin *********#x1=tf.placeholder(tf.float32,[b,c])cell=tf.nn.rnn_cell.BasicRNNCell(num_units=a)h0=cell.zero_state(batch_size=b,dtype=tf.float32)output,h1=cell.__call__(x1,h0)print(cell.state_size)print(h1)# ********** End **********#2.探幽入微LSTM
# -*- coding: utf-8 -*-
import tensorflow as tf# 参数 a 是 BasicLSTMCell所含的神经元数, 参数 b 是 batch_size, 参数 c 是单个 input 的维数,shape = [ b , c ]
def creatLSTMCell(a,b,c):# 请在此添加代码 完成本关任务# ********** Begin *********#x1=tf.placeholder(tf.float32,[b,c])cell=tf.nn.rnn_cell.BasicLSTMCell(num_units=a)h0=cell.zero_state(batch_size=b,dtype=tf.float32)output,h1=cell.__call__(x1,h0)print(h1.h)print(h1.c)# ********** End **********#3.进阶RNN:学习一次执行多步以及堆叠RNN
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np# 参数 a 是RNN的层数, 参数 b 是每个BasicRNNCell包含的神经元数即state_size
# 参数 c 是输入序列的批量大小即batch_size,参数 d 是时间序列的步长即time_steps,参数 e 是单个输入input的维数即input_size
def MultiRNNCell_dynamic_call(a,b,c,d,e):# 用tf.nn.rnn_cell MultiRNNCell创建a层RNN,并调用tf.nn.dynamic_rnn# 请在此添加代码 完成本关任务# ********** Begin *********#cell = tf.nn.rnn_cell.MultiRNNCell([tf.nn.rnn_cell.BasicRNNCell(num_units=b) for _ in range(a)]) # a层RNNinputs = tf.placeholder(np.float32, shape=(c, d, e)) # a 是 batch_size,d 是time_steps, e 是input_sizeh0=cell.zero_state(batch_size=c,dtype=tf.float32)output, h1 = tf.nn.dynamic_rnn(cell, inputs, initial_state=h0)print(output)# ********** End **********#二、RNN循环神经网络
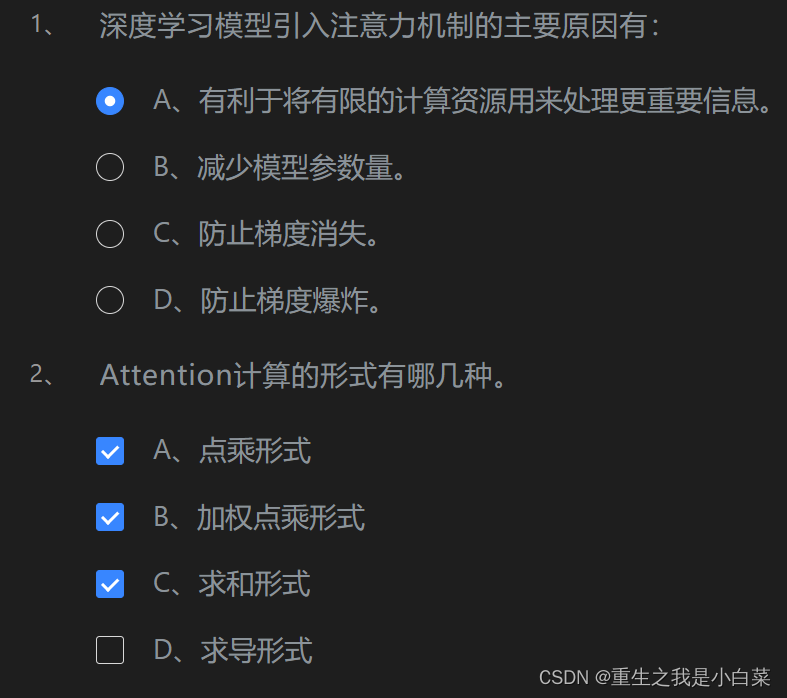
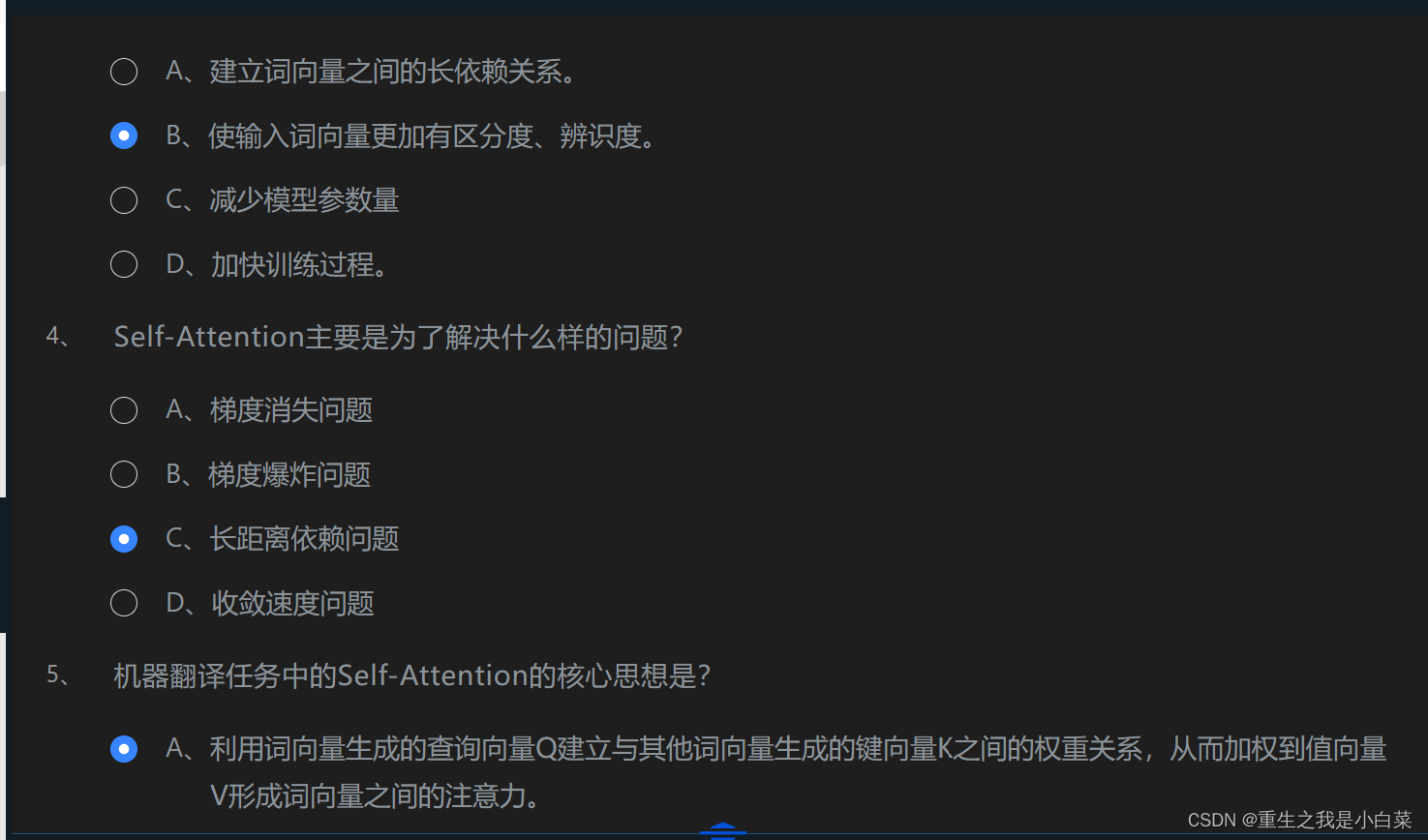
1.Attention注意力机制(A ABC B C A)
2.Seq2Seq
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variabledtype = torch.FloatTensor
char_list = [c for c in 'SEPabcdefghijklmnopqrstuvwxyz']
char_dic = {n: i for i, n in enumerate(char_list)}
seq_data = [['man', 'women'], ['black', 'white'], ['king', 'queen'], ['girl', 'boy'], ['up', 'down'], ['high', 'low']]
seq_len = 8
n_hidden = 128
n_class = len(char_list)
batch_size = len(seq_data)##########Begin##########
#对数据进行编码部分
##########End##########
def make_batch(seq_data):batch_size = len(seq_data)input_batch, output_batch, target_batch = [], [], []for seq in seq_data:for i in range(2):seq[i] += 'P' * (seq_len - len(seq[i]))input = [char_dic[n] for n in seq[0]]output = [char_dic[n] for n in ('S' + seq[1])]target = [char_dic[n] for n in (seq[1] + 'E')]input_batch.append(np.eye(n_class)[input])output_batch.append(np.eye(n_class)[output])target_batch.append(target)return Variable(torch.Tensor(input_batch)), Variable(torch.Tensor(output_batch)), Variable(torch.LongTensor(target_batch))##########Begin##########
#模型类定义
input_batch, output_batch, target_batch = make_batch(seq_data)
class Seq2Seq(nn.Module):def __init__(self):super(Seq2Seq, self).__init__()self.encoder = nn.RNN(input_size=n_class, hidden_size=n_hidden)self.decoder = nn.RNN(input_size=n_class, hidden_size=n_hidden)self.fc = nn.Linear(n_hidden, n_class)def forward(self, enc_input, enc_hidden, dec_input):enc_input = enc_input.transpose(0, 1)dec_input = dec_input.transpose(0, 1)_, h_states = self.encoder(enc_input, enc_hidden)outputs, _ = self.decoder(dec_input, h_states)outputs = self.fc(outputs)return outputs
##########End##########model = Seq2Seq()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)##########Begin##########
#模型训练过程
for epoch in range(5001):hidden = Variable(torch.zeros(1, batch_size, n_hidden))optimizer.zero_grad()outputs = model(input_batch, hidden, output_batch)outputs = outputs.transpose(0, 1)loss = 0for i in range(batch_size):loss += criterion(outputs[i], target_batch[i])loss.backward()optimizer.step()
##########End####################Begin##########
#模型验证过程函数
def translated(word):input_batch, output_batch, _ = make_batch([[word, 'P' * len(word)]])hidden = Variable(torch.zeros(1, 1, n_hidden))outputs = model(input_batch, hidden, output_batch)predict = outputs.data.max(2, keepdim=True)[1]decode = [char_list[i] for i in predict]end = decode.index('P')translated = ''.join(decode[:end])print(translated)
##########End##########translated('highh')
translated('kingh')三、RNN和LSTM
1.循环神经网络简介
import torchdef rnn(input,state,params):"""循环神经网络的前向传播:param input: 输入,形状为 [ batch_size,num_inputs ]:param state: 上一时刻循环神经网络的状态,形状为 [ batch_size,num_hiddens ]:param params: 循环神经网络的所使用的权重以及偏置:return: 输出结果和此时刻网络的状态"""W_xh,W_hh,b_h,W_hq,b_q = params"""W_xh : 输入层到隐藏层的权重W_hh : 上一时刻状态隐藏层到当前时刻的权重b_h : 隐藏层偏置W_hq : 隐藏层到输出层的权重b_q : 输出层偏置"""H = state# 输入层到隐藏层H = torch.matmul(input, W_xh) + torch.matmul(H, W_hh) + b_hH = torch.tanh(H)# 隐藏层到输出层Y = torch.matmul(H, W_hq) + b_qreturn Y,Hdef init_rnn_state(num_inputs,num_hiddens):"""循环神经网络的初始状态的初始化:param num_inputs: 输入层中神经元的个数:param num_hiddens: 隐藏层中神经元的个数:return: 循环神经网络初始状态"""init_state = torch.zeros((num_inputs,num_hiddens),dtype=torch.float32)return init_state2.长短时记忆网络
import torchdef lstm(X,state,params):"""LSTM:param X: 输入:param state: 上一时刻的单元状态和输出:param params: LSTM 中所有的权值矩阵以及偏置:return: 当前时刻的单元状态和输出"""W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q = params"""W_xi,W_hi,b_i : 输入门中计算i的权值矩阵和偏置W_xf,W_hf,b_f : 遗忘门的权值矩阵和偏置W_xo,W_ho,b_o : 输出门的权值矩阵和偏置W_xc,W_hc,b_c : 输入门中计算c_tilde的权值矩阵和偏置W_hq,b_q : 输出层的权值矩阵和偏置"""#上一时刻的输出 H 和 单元状态 C。(H,C) = state# 遗忘门F = torch.matmul(X, W_xf) + torch.matmul(H, W_hf) + b_fF = torch.sigmoid(F)# 输入门I = torch.sigmoid(torch.matmul(X,W_xi)+torch.matmul(H,W_hi) + b_i)C_tilde = torch.tanh(torch.matmul(X, W_xc) + torch.matmul(H, W_hc) + b_c)C = F * C + I * C_tilde# 输出门O = torch.sigmoid(torch.matmul(X,W_xo)+torch.matmul(H,W_ho) + b_o)H = O * C.tanh()# 输出层Y = torch.matmul(H,W_hq) + b_qreturn Y,(H,C)