动手学深度学习12 Dropout丢弃法
- 1. 丢弃法
- 2. 代码实现
- 源码实现
- 简洁实现
- torch.rand() 和 torch.randn() 两个函数的区别
- 3. QA
1. 丢弃法
在层之间加入噪音,不对输入层做处理。不是在输入数据上加噪音。

核心:为什么除以1-p

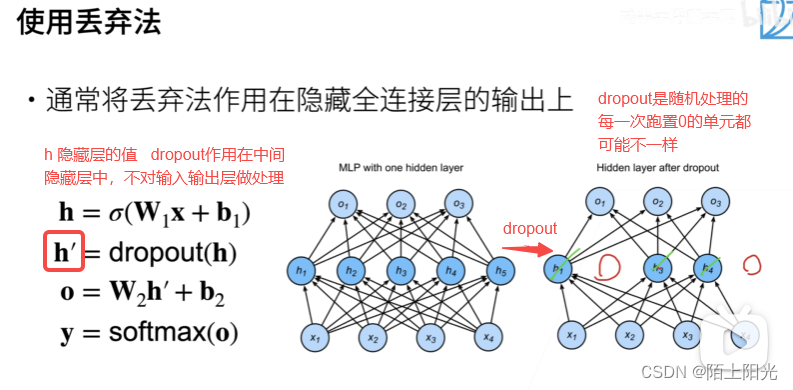
以上是训练过程使用的。正则项只在训练中使用,是对权重做的影响。在推理【inference 预测过程 权重不需要发生变化】的时候是不对h做处理的,dropout输出的是数据本身。

常用语全连接层–多层感知机的隐藏层上,很少用于cnn等网络上。常用丢弃概率(0.1, 0.9 ,0.5),效果比L2正则化好一点点。

2. 代码实现
学看封装思路和d2l源码
torch.rand是产生0-1之间的均匀分布,randn是产生均值为0,方差为1的高斯分布。
mask可以理解成一个布尔型的张量,每一个值表示X对应下标的值是否要dropout。
核心: 每一次调用dropout_layer
源码实现
import torch
from torch import nn
from d2l import torch as d2l# 以dropout的概率丢弃张量输入X中的元素
def dropout_layer(X, dropout):assert 0<= dropout <=1# dropout=1 所有元素都会被丢弃,全部置为0if dropout == 1:return torch.zeros_like(X) # 返回一个和X shape一致的全部为0的变量# dropout=0 所有元素都会被保留,返回的是X 即不做任何处理if dropout == 0:return X# 随机生成和X shape相同的数,和dropout对应位置值做比较,大于为真-True,值为1,小于为假FALSE值为0# mask1 = torch.randn(X.shape)# mask = (mask1 > dropout).float()# print("mask1", mask1)# print("mask", mask)# mask是元素为0或者1的矩阵,0元素表示该对应位置数据被丢弃,1元素表示对应位置,gpu做乘法的速度会比较快,比从结构化里面选一个数据要计算的快。mask = (torch.randn(X.shape) > dropout).float()return mask * X / (1.0 - dropout)X = torch.arange(16, dtype=torch.float32).reshape((2,8))
print(X)
# print(dropout_layer(X, 0.0))
print(dropout_layer(X, 0.7))
# print(dropout_layer(X, 1.0))def evaluate_accuracy(net, data_iter):"""计算在指定数据集上模型的精度"""if isinstance(net, torch.nn.Module):net.eval() # 将模型设置为评估模式# net.eval() 作用1. 网络结构如果有Batch Normalization 和 Dropout 层的,做模型评测必须加上这个命令以防止报错# 作用2: 关闭梯度计算# Accumulator 累加器 不断迭代数据X y 不断累加评测结果# Accumulator 初始化传入数值2 表示有数组有两个变量,第一个位置存正确测试数,第二个位置存样本总数,根据批次遍历依次累加metric = d2l.Accumulator(2) # 正确预测数、预测总数with torch.no_grad():for X, y in data_iter: # 迭代一次 一次批量# metric.add(该批次的预测类别正确的样本数,批次的总样本数)# y.numel() pytorch中用于返回张量的元素总个数metric.add(d2l.accuracy(net(X), y), y.numel())# 返回值=分类正确样本数/样本总数=精度return metric[0] / metric[1]def trian_epoch_ch3(net, train_iter, loss, updater):"""训练模型一个迭代周期(定义见第三章)"""# 如果模型是用nn模组定义的if isinstance(net, torch.nn.Module):net.train() # 将模型设置为训练模式 告诉pytorch要计算梯度# 训练损失总和、训练准确度总和、样本数metric = d2l.Accumulator(3) # 三个参数需要累加的迭代器for X, y in train_iter:# 计算梯度并更新参数y_hat = net(X)l = loss(y_hat, y) # 计算损失函数# 如果优化器是pytorch内置的优化器# 下面两个加的结果有什么区别# print(float(l)*len(y), accuracy(y_hat,y), y.size().numel(),# float(l.sum()), accuracy(y_hat, y), y.numel())if isinstance(updater, torch.optim.Optimizer):# 使用pytorch内置的优化器和损失函数updater.zero_grad() # 1.梯度先置零l.mean().backward() # 2.计算梯度updater.step() # 3.调用step参数进行一次更新# metric.add(float(l)*len(y), accuracy(y_hat,y), y.size().numel())# 报错 ValueError: only one element tensors can be converted to Python scalarselse:# 使用定制的优化器和损失函数# 自己实现的l是一个向量l.sum().backward()updater(X.shape[0])# metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())metric.add(float(l.sum()), d2l.accuracy(y_hat, y), y.numel())# 返回训练损失和训练精度# 损失累加/总样本数 训练正确的/总样本数return metric[0] / metric[2], metric[1] / metric[2]# 开启训练
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):"""训练模型"""animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3,0.9],legend=['train-loss', 'train-acc', 'test-acc'])for epoch in range(num_epochs):train_metrics = trian_epoch_ch3(net, train_iter, loss, updater)test_acc = evaluate_accuracy(net, test_iter)animator.add(epoch+1, train_metrics+(test_acc,))train_loss, train_acc = train_metricsassert train_loss < 0.5, train_lossassert train_acc <= 1 and train_acc > 0.7, train_accassert test_acc <= 1 and test_acc > 0.7, test_acc# 定义模型参数
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256# 定义模型
dropout1, dropout2 = 0.2, 0.5class Net(nn.Module):def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2, is_training=True):super(Net, self).__init__()self.num_inputs = num_inputsself.is_training = is_trainingself.lin1 = nn.Linear(num_inputs, num_hiddens1)self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)self.lin3 = nn.Linear(num_hiddens2, num_outputs)self.relu = nn.ReLU()def forward(self, X):H1 = self.relu(self.lin1(X.reshape(-1, self.num_inputs)))# 只有在训练状态才会使用dropoutif self.is_training == True:H1 = dropout_layer(H1, dropout1)H2 = self.relu(self.lin2(H1))if self.is_training == True:H2 = dropout_layer(H2, dropout2)out = self.lin3(H2)return outnet = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
简洁实现
import torch
from torch import nn
from d2l import torch as d2l# def dropout_layer(X, dropout):
# assert 0<= dropout <=1
# # dropout=1 所有元素都会被丢弃,全部置为0
# if dropout == 1:
# return torch.zeros_like(X) # 返回一个和X shape一致的全部为0的变量
# # dropout=0 所有元素都会被保留,返回的是X 即不做任何处理
# if dropout == 0:
# return X
# # 随机生成和X shape相同的数,和dropout对应位置值做比较,大于为真-True,值为1,小于为假FALSE值为0
# mask1 = torch.randn(X.shape)
# mask = (mask1 > dropout).float()
# # print("mask1", mask1)
# # print("mask", mask)
# # mask = (torch.rand(X.shape) > dropout).float()
# return mask * X / (1.0 - dropout)# X = torch.arange(16, dtype=torch.float32).reshape((2,8))
# print(X)
# # print(dropout_layer(X, 0.0))
# print(dropout_layer(X, 0.7))
# # print(dropout_layer(X, 1.0))def evaluate_accuracy(net, data_iter):"""计算在指定数据集上模型的精度"""if isinstance(net, torch.nn.Module):net.eval() # 将模型设置为评估模式# net.eval() 作用1. 网络结构如果有Batch Normalization 和 Dropout 层的,做模型评测必须加上这个命令以防止报错# 作用2: 关闭梯度计算# Accumulator 累加器 不断迭代数据X y 不断累加评测结果# Accumulator 初始化传入数值2 表示有数组有两个变量,第一个位置存正确测试数,第二个位置存样本总数,根据批次遍历依次累加metric = d2l.Accumulator(2) # 正确预测数、预测总数with torch.no_grad():for X, y in data_iter: # 迭代一次 一次批量# metric.add(该批次的预测类别正确的样本数,批次的总样本数)# y.numel() pytorch中用于返回张量的元素总个数metric.add(d2l.accuracy(net(X), y), y.numel())# 返回值=分类正确样本数/样本总数=精度return metric[0] / metric[1]def trian_epoch_ch3(net, train_iter, loss, updater):"""训练模型一个迭代周期(定义见第三章)"""# 如果模型是用nn模组定义的if isinstance(net, torch.nn.Module):net.train() # 将模型设置为训练模式 告诉pytorch要计算梯度# 训练损失总和、训练准确度总和、样本数metric = d2l.Accumulator(3) # 三个参数需要累加的迭代器for X, y in train_iter:# 计算梯度并更新参数y_hat = net(X)l = loss(y_hat, y) # 计算损失函数# 如果优化器是pytorch内置的优化器# 下面两个加的结果有什么区别# print(float(l)*len(y), accuracy(y_hat,y), y.size().numel(),# float(l.sum()), accuracy(y_hat, y), y.numel())if isinstance(updater, torch.optim.Optimizer):# 使用pytorch内置的优化器和损失函数updater.zero_grad() # 1.梯度先置零l.mean().backward() # 2.计算梯度updater.step() # 3.调用step参数进行一次更新# metric.add(float(l)*len(y), accuracy(y_hat,y), y.size().numel())# 报错 ValueError: only one element tensors can be converted to Python scalarselse:# 使用定制的优化器和损失函数# 自己实现的l是一个向量l.sum().backward()updater(X.shape[0])# metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())metric.add(float(l.sum()), d2l.accuracy(y_hat, y), y.numel())# 返回训练损失和训练精度# 损失累加/总样本数 训练正确的/总样本数return metric[0] / metric[2], metric[1] / metric[2]# 开启训练
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):"""训练模型"""animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3,0.9],legend=['train-loss', 'train-acc', 'test-acc'])for epoch in range(num_epochs):train_metrics = trian_epoch_ch3(net, train_iter, loss, updater)test_acc = evaluate_accuracy(net, test_iter)animator.add(epoch+1, train_metrics+(test_acc,))train_loss, train_acc = train_metricsassert train_loss < 0.5, train_lossassert train_acc <= 1 and train_acc > 0.7, train_accassert test_acc <= 1 and test_acc > 0.7, test_acc# 定义模型参数
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256# 定义模型
dropout1, dropout2 = 0.2, 0.5# class Net(nn.Module):
# def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2, is_training=True):
# super(Net, self).__init__()
# self.num_inputs = num_inputs
# self.is_training = is_training
# self.lin1 = nn.Linear(num_inputs, num_hiddens1)
# self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
# self.lin3 = nn.Linear(num_hiddens2, num_outputs)
# self.relu = nn.ReLU()# def forward(self, X):
# H1 = self.relu(self.lin1(X.reshape(-1, self.num_inputs)))
# # 只有在训练状态才会使用dropout
# if self.is_training == True:
# H1 = dropout_layer(H1, dropout1)
# H2 = self.relu(self.lin2(H1))
# if self.is_training == True:
# H2 = dropout_layer(H2, dropout2)
# out = self.lin3(H2)
# return out# net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256),nn.ReLU(),# 这里不用区分测试是因为nn.dropout在测试的时候就会自动变成直接输出(参考文档),也就是需要在测试之前先调用net.eval()转换成评估模式nn.Dropout(dropout1), # 在第一个全连接层之后添加一个dropout层nn.Linear(256, 256),# dropout和relu调换顺序并不会导致计算减少,虽然有一些数据变成0,但是0也是会参与计算,不会跳过的。nn.ReLU(),nn.Dropout(dropout2), # 在第二个全连接层之后添加一个dropout层nn.Linear(256, 10))
def init_weights(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
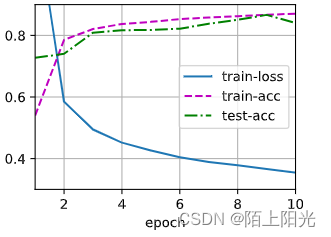
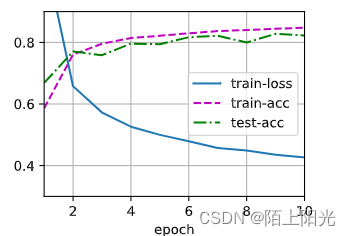
dropout1 2都设置为0,模型拟合的更好,测试精度上升,损失下降。
一般来说,隐藏层设置大一些+大一点的dropout会比不设置dropout,隐藏层比较小,训练出来的模型效果要好一些。
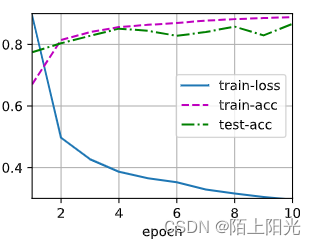
hidden1 2 =512

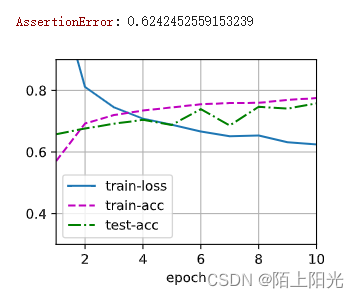
hidden1 2 =512 dropout1 2=0.9, 0.6
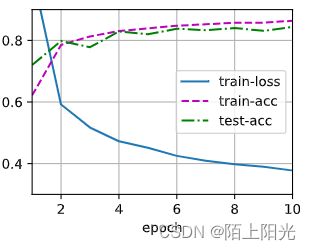
hidden1 2 =512 dropout1 2=0.1, 0.4
torch.rand() 和 torch.randn() 两个函数的区别
torch.rand() 和 torch.randn() 是 PyTorch 中用于生成随机数的函数,它们之间的区别主要在于生成的随机数的分布不同:
-
torch.rand():- 函数原型:
torch.rand(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) -> Tensor - 功能:生成指定形状的张量,其中的元素值是在区间 [0, 1) 内均匀分布的随机数。
- 示例:
import torch# 生成形状为(2, 3)的随机张量,元素值在区间 [0, 1) 内均匀分布 rand_tensor = torch.rand(2, 3)
- 函数原型:
-
torch.randn():- 函数原型:
torch.randn(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) -> Tensor - 功能:生成指定形状的张量,其中的元素值是从标准正态分布(均值为0,标准差为1)中抽取的随机数。
- 示例:
import torch# 生成形状为(2, 3)的随机张量,元素值从标准正态分布中抽取 randn_tensor = torch.randn(2, 3)
- 函数原型:
因此,torch.rand() 生成的随机数是均匀分布的,而 torch.randn() 生成的随机数是从标准正态分布中抽取的。你可以根据需要选择使用哪种分布的随机数。
3. QA
- dropout随机置0, 梯度也会变成0,置1的部分梯度也会跟着增大。dropout对求梯度是乘了一个对称函数,dropout掉的一些输出当前轮训练就不会更新权重参数【也是为什么前期理论理解dropout是随机采样一些小网络去更新参数】
- 丢弃法的丢弃依据,正则项,自己调丢弃率–大小合适,太小对模型正则效果不大还是overfitting,太大导致模型underfitting。
- dropout随机丢弃,如何保证可重复性:固定好随机种子,每次dropout的值保证是一样的。又因为参数本身就是随机初始化的,所以很难保证可重复。cudnn加速矩阵运算。cudnn每次计算的乘法结果是不一样的,n个数相加,加的顺序不一样得到的结果也会不一样,因为精度不够,cudnn计算因为要做好的并行,每次计算顺序可能会不一样,随机性很大,计算结果几乎不能重复【浮点数计算】。也没必要重复,训练很多轮之后精度达到就可以。随机性能让模型更稳定,随机能让模型变得更平滑。
- 丢弃法是在训练中把神经元丢弃后【本轮不参与训练不参与参数更新】训练,在预测时网络中的神经元没有丢弃。每迭代一次,就随机丢弃一次。
- 在全连接层用dropout,卷积层不会用到。BN是给卷积层用的。
- 训练曲线loss是否平滑不关心,训练到后期都会平滑的,否则收敛会困难。
- dropout是正则项,让模型的训练更新权重的时候让模型复杂度变低一点,在预测的时候,不对权重更新不更新模型,dropout是不做处理的。做预测的时候肯定不会再去修改模型。训练要跑很多次,次数够大dropout随机丢弃的对整体来说影响不大。
- dropout不为0的值要除以1-p,保证数据的期望是不变的,避免输出的结果是训练翻倍的结果【方差没有发生变化】。更改的隐藏层的输出,并不是更改标签的值。【随机改标签的正则化是别的算法】改label应该和改隐藏层一样,一次epoch随机改一部分,本质为添加随机噪声,还可以改输入。比如bert、MAE这种,让模型做完形填空,同样的文章每次进来都挖掉不同的单词。
- dropout每次随机选几个子网络,最后做平均做法类似于随机森林多决策树做投票的思想,但是后面证明dropout更类似于正则项。【hinton胶囊网络】
- dropout是一种避免过拟合的正则化方法,和regularization没有区别,可以一起用。
- dropout丢掉的是一层,上一层的输出和下一层的输入都被丢掉,丢掉的是一个东西。丢掉的是节点,连接节点的边也会同时被丢掉。
- 为什么都是正则,dropout比权重衰退效果好?
dropout只用于全连接层,权重衰退【更常用 lambda不好调参】还可以用于卷积层等网络,dropout更好调参一些,所以效果比较好。尽量让模型容量变大【更强】,然后用正则项让模型不要太偏,可能会比模型容量比较小没有用正则项处理训练出来的模型效果要好。cnn是特别的MLP。 - 在同样的lr下,dropout的介入可能会造成参数收敛过慢,dropout不改变期望,lr对期望和方差敏感。
- transformer可以看做kernel machine
将 Transformer 模型描述为“kernel machine”通常指的是 Transformer 中的注意力机制与核方法之间的类比。这种类比主要是基于 Transformer 中的注意力机制与核方法在数学上的一些相似性和联系。以下是对这种理解的详细解释:
1 注意力机制的类比:
- 自注意力机制:Transformer 中的自注意力机制允许模型在不同位置之间建立关系,类似于核方法中的核函数,能够将输入数据映射到高维空间中,并计算不同数据之间的相似度。
- 多头注意力:Transformer 中的多头注意力机制允许模型同时关注输入的不同方面,类似于核方法中的多个核函数,可以捕获不同特征之间的关系。
2 核方法的应用:
- 特征映射:在核方法中,核函数将输入数据映射到高维空间,使得数据在高维空间中更容易分隔。在 Transformer 中,注意力机制也可以看作是一种特征映射,将输入序列映射到一个更加语义丰富的表示空间。
- 相似度计算:核方法中常用核函数来计算数据之间的相似度,而 Transformer 中的注意力权重可以看作是计算输入序列中不同位置之间的相似度。
3 性能和灵活性:
- 性能:类比 Transformer 为核机器也意味着 Transformer 在处理序列数据时具有一定的性能,特别是在语言建模和自然语言处理任务中,Transformer 已经证明了其在大规模数据集上的有效性和性能。
- 灵活性:类比 Transformer 为核机器也突出了 Transformer 模型在处理不同类型数据时的灵活性,它可以适用于不同的领域和任务,不仅限于自然语言处理。
总的来说,将 Transformer 描述为“kernel machine”是一种类比的说法,用来强调 Transformer 模型中注意力机制与核方法之间的一些数学和功能上的相似性,以及 Transformer 在处理序列数据时的性能和灵活性。
CuDNN(CUDA Deep Neural Network library)是由NVIDIA开发的用于深度学习的加速库。它是专门针对 NVIDIA GPU 架构设计的,旨在优化深度神经网络的训练和推理过程。以下是关于 CuDNN 的一些重要信息:
-
加速深度学习:
- CuDNN 提供了针对深度学习任务的高度优化的计算库,可以加速神经网络的训练和推理过程。
- 它实现了各种深度学习操作的高效实现,包括卷积、池化、归一化、循环神经网络等。
-
针对 NVIDIA GPU 的优化:
- CuDNN 是为 NVIDIA GPU 架构设计的,充分利用了 GPU 的并行计算能力和特定功能单元的优势。
- 它与 CUDA 并行计算平台紧密集成,可以实现与 CUDA 应用程序的无缝对接。
-
版本和功能:
- CuDNN 的版本通常与 NVIDIA CUDA Toolkit 的版本相对应,因为它们需要相互配合使用。
- 不同版本的 CuDNN 支持不同的深度学习功能和算法,同时也会针对新的 GPU 架构进行优化。
-
使用方式:
- 开发者可以通过在深度学习框架(如 TensorFlow、PyTorch)中调用 CuDNN 库来利用其提供的加速功能。
- CuDNN 提供了一系列 API,可以在 CUDA 编程中直接调用,或者在深度学习框架的底层中使用。
总体来说,CuDNN 是 NVIDIA 提供的一个关键工具,用于在 NVIDIA GPU 上加速深度学习任务的执行,提高深度神经网络模型训练和推理的效率和速度。