OK了发布
OK了发布
你说的对,但是釜山行里逃过了六节车厢的丧尸,却逃不过一节车厢的人心,这说明了什么?说明一节更比六节强,王中王,火腿肠,果冻我要喜之郎,上课要听鹏哥讲!
目录
你说的对,但是釜山行里逃过了六节车厢的丧尸,却逃不过一节车厢的人心,这说明了什么?说明一节更比六节强,王中王,火腿肠,果冻我要喜之郎,上课要听鹏哥讲!
第1个补充一下:
用矩形法求编辑 。(,说明,矩形的长的计算方法不一样,会造成运算结果有误差)
变量定义:
输入分成的份数:
计算每份的宽度:
初始化x的值:
循环计算近似积分:
输出近似积分:
第2个才是最炸裂的,当时看错掉了:
深感体悟。
:)我直接把它给记下来。那天直接给我在那看懵逼了。
用二分法求下面方程在(-10,10)之间的根:(
2x3-4x2+3x-6=0
程序运行结果:x= 2.00
包含头文件
主函数
变量定义
检查函数在初始区间内的符号
二分法循环
输出结果
如果没有根
总结
第3个:回来补充第3个
编程实现:给定一个一维数组,计算并输出此数组(长度为9)中每相邻两个元素之平均值的平方根之和。
输入测试数据:12.0 34.0 4.0 23.0 34.0 45.0 18.0 3.0 11.0
程序输出结果:s=35.951014.
数组定义与初始化:
变量定义:
循环处理:
a. 计算相邻元素的平均值:
b. 计算平均值的平方根:
c. 累加平方根:
d.输出结果:
第四个:
编程实现:在一组数中,顺序查找n是否在此数组中,若存在则输出“the number is found!”,若不存在则输出“the number is not found!”。要求数组长度定义为10,用给定的测试数据对数组初始化。
找到数字后立即输出了位置信息,但是输出位置信息的代码块被放在了 if 语句中,这意味着它只会在找到数字时执行一次。如果没找到数字,这个位置信息将不会被输出。应该在循环外部检查 flag 变量,并只在找到数字后输出位置信息。
主要我们加了一个查找位数:编辑
详细解释:
第五个:
程序填空:把a数组中的奇数按原顺序依次存放到a[0]、a[1]、a[2]、……中,把偶数从数组中删除后输出a数组。请填空,填空时不得增行或删行,也不得更改程序的结构,一条横线上只能填写一条语句!
#define N 9 什么意思
我来看看他这个到底是弄什么的,
这里看一下:
编辑OK了,可以看一下补充的;
第1个补充一下:
用矩形法求 。(,说明,矩形的长的计算方法不一样,会造成运算结果有误差)
。(,说明,矩形的长的计算方法不一样,会造成运算结果有误差)
输入测试数据:3000 (区间的等份数)
程序运行结果:18.000000
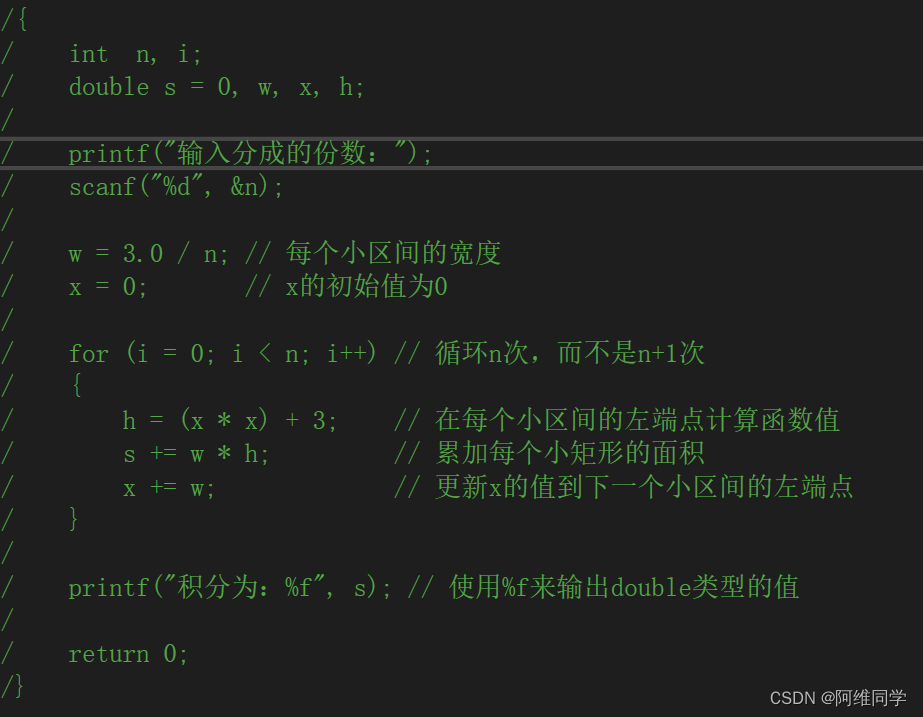
#include<stdio.h>
int main()
{int n,i;double s = 0, w, x, h;printf("输入分成的份数:");scanf("%d", &n);w = 3.0/ n;x = 0;for ( i = 0; i <n; i++){h = (x * x) + 3;s += w*h;x += w;}printf("积分为:%f", s);return 0;
}
具体在下面:
变量定义:
int n,i;double s = 0, w, x, h;
* `n`:表示将区间`[0, 3]`分成多少份。* `i`:循环变量。* `s`:用于存储近似积分的和,初始化为0。* `w`:每份的宽度。* `x`:当前计算的x值,初始为0。* `h`:函数`h(x) = x^2 + 3`在`x`处的值。输入分成的份数:
printf("输入分成的份数:");scanf("%d", &n);程序首先打印提示,然后等待用户输入一个整数
n,表示将区间[0, 3]分成n份。计算每份的宽度:
w = 3.0/ n;由于区间是
[0, 3],所以每份的宽度是3/n。初始化x的值:
x = 0;因为我们要从区间的左端点开始计算。
循环计算近似积分:
for ( i = 0; i <n; i++){h = (x * x) + 3;s += w*h;x += w;}
* 对于`n`份中的每一份:+ 计算`h(x)`的值。+ 将`w * h`加到`s`上(即计算矩形的面积并累加到总和中)。+ 更新`x`的值,为下一份做准备。输出近似积分:
printf("积分为:%f", s);将计算得到的近似积分
s输出到屏幕上
第2个才是最炸裂的,当时看错掉了:
深感体悟。
:)我直接把它给记下来。那天直接给我在那看懵逼了。

用二分法求下面方程在(-10,10)之间的根:(
2x3-4x2+3x-6=0
程序运行结果:x= 2.00
请看:
#include<stdio.h>
#include<math.h>
int main()
{float eps = 1e-5, x;float x1 = -10.00, x2 = 10.0;float y1 = 2 * x1 * x1 * x1 - 4 * x1 * x1 + 3 * x1 - 6;float y2 = 2 * x2 * x2 * x2 - 4 * x2 * x2 + 3 * x2 - 6;if (y1*y2<0){while (fabs(x2-x1)>eps){ x = (x1 + x2) / 2;float y0 = 2 * x * x * x - 4 * x * x + 3 * x - 6;if (y1 * y0 < 0){x2 = x;y2 = y0;}else if (y2 * y0 < 0){x1 = x;y1 = y0;}}printf("函数的根为:%.2f", x);return 0;}else{printf("没有根");}return 0;
}我不再去解释一遍。
直接输出
这段代码是一个用C语言编写的程序,用于求解一个三次方程的根。使用了二分法(Bisection method)来逼近方程的根。
首先,逐步解释代码中的每个部分。
包含头文件
#include<stdio.h>#include<math.h>这里包含了
stdio.h(用于标准输入输出)和math.h(用于数学函数,如fabs,用于计算浮点数的绝对值)。主函数
int main()程序的入口点。
变量定义
float eps = 1e-5, x;float x1 = -10.00, x2 = 10.0;float y1 = 2 * x1 * x1 * x1 - 4 * x1 * x1 + 3 * x1 - 6;float y2 = 2 * x2 * x2 * x2 - 4 * x2 * x2 + 3 * x2 - 6;
eps:用于定义逼近的精度,即当x1和x2的差小于eps时,认为找到了根。x1和x2:用于二分法的初始区间,这里选择的是[-10, 10]。y1和y2:分别是x1和x2处函数的值。检查函数在初始区间内的符号
if (y1*y2<0)这行代码检查函数在
x1和x2处的值的符号是否相反。如果符号相反,那么根据介值定理,函数在[x1, x2]区间内至少有一个根。二分法循环
while (fabs(x2-x1)>eps)当
x1和x2的差的绝对值大于eps时,继续循环。在循环内部:
- 计算中间点
x和其对应的函数值y0。- 检查
y0与y1或y2的符号。
- 如果
y0与y1的符号相反,更新x2和y2。- 如果
y0与y2的符号相反,更新x1和y1。输出结果
printf("函数的根为:%.2f", x);当找到根时(即
x1和x2的差小于eps),输出找到的根。如果没有根
else{printf("没有根");}如果在初始区间
[-10, 10]内函数值的符号相同,则输出“没有根”。总结
这个程序通过二分法在一个给定的区间内寻找三次方程的根。它首先检查函数在区间端点的值的符号,然后使用二分法逐步缩小区间,直到找到满足精度要求的根或确定区间内没有根为止。
okll
第3个:回来补充第3个
编程实现:给定一个一维数组,计算并输出此数组(长度为9)中每相邻两个元素之平均值的平方根之和。
输入测试数据:12.0 34.0 4.0 23.0 34.0 45.0 18.0 3.0 11.0
程序输出结果:s=35.951014.
#include<stdio.h>
#include<math.h>
void main()
{double arr1[9] = { 12.0,34.0,4.0,23.0,34.0,45.0,18.0,3.0,11.0 };double sum = 0;for (int i = 0; i < 8; i++){double avg = (arr1[i] + arr1[i + 1]) / 2;double sqrt_avg = sqrt(avg);sum += sqrt_avg;}printf("平均值的平方根之和:%lf\n", sum);return 0;
}用AI辅助一下:
数组定义与初始化:
double arr1[9] = { 12.0,34.0,4.0,23.0,34.0,45.0,18.0,3.0,11.0 };定义了一个包含9个双精度浮点数的数组
arr1,并进行了初始化。变量定义:
double sum = 0;定义了一个双精度浮点数变量
sum,并初始化为0。这个变量用于存储平均值的平方根之和。循环处理:
for (int i = 0; i < 8; i++)这是一个循环,从
i = 0开始,直到i = 7(因为数组有9个元素,但我们只需要处理前8个元素以形成8对相邻的元素)。在循环内:
a. 计算相邻元素的平均值:
double avg = (arr1[i] + arr1[i + 1]) / 2;这里计算了
arr1[i]和arr1[i + 1]的平均值,并存储在变量avg中。注意,当i = 7时,arr1[i + 1]是访问数组的第9个元素,这是安全的,因为数组索引是从0开始的。b. 计算平均值的平方根:
double sqrt_avg = sqrt(avg);使用
sqrt函数计算avg的平方根,并将结果存储在sqrt_avg中。c. 累加平方根:
sum += sqrt_avg;将
sqrt_avg加到sum上。d.输出结果:
printf("平均值的平方根之和:%lf\n", sum);使用
printf函数输出sum的值,即所有相邻元素平均值的平方根之和。
第四个:
编程实现:在一组数中,顺序查找n是否在此数组中,若存在则输出“the number is found!”,若不存在则输出“the number is not found!”。要求数组长度定义为10,用给定的测试数据对数组初始化。
测试数据:3 4 7 12 24 78 9 15 80 45
第一次运行程序
输入测试数据 12
程序输出结果:the number is found!
第二次运行程序
输入测试数据:11
程序输出结果:the number is not found!
干干干
然后我开始在这里敲。第4个。
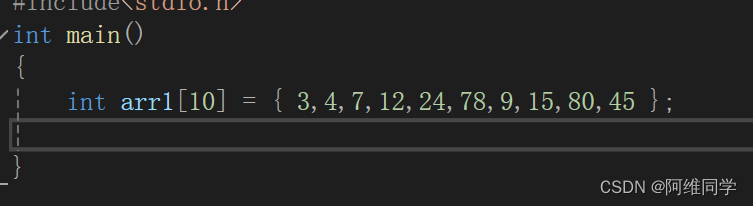
先搞一个出来。找一下他的元素个数。
int n = sizeof(arr1) / arr1[0];
给他来一个循环;
搞了半天忘记了输入:
给他来一个flag:

一下子就敲到头:
那还是重新给他点补充,等会给他修正一波,哈哈哈:
要改的还挺多的:
找到数字后立即输出了位置信息,但是输出位置信息的代码块被放在了 if 语句中,这意味着它只会在找到数字时执行一次。如果没找到数字,这个位置信息将不会被输出。应该在循环外部检查 flag 变量,并只在找到数字后输出位置信息。
改
主要我们加了一个查找位数:

爆改了一遍。
下面给了一段解释。、
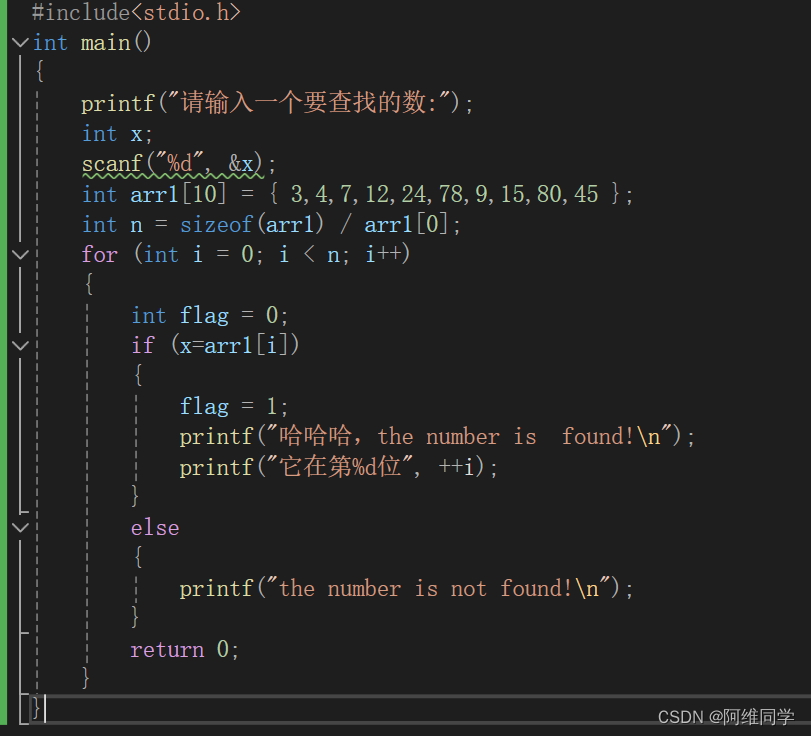
#include<stdio.h>
int main()
{printf("请输入一个要查找的数:");int x;scanf("%d", &x);int arr1[10] = { 3,4,7,12,24,78,9,15,80,45 };int n = sizeof(arr1) / sizeof(arr1[0]);int flag = 0;int position = 0;for (int i = 0; i < n; i++){if (x==arr1[i]){flag = 1;position = i+1 ;break;}}if (flag){printf("哈哈哈,the number is found!\n");printf("它在第%d位", position);}else{printf("the number is not found!\n");}return 0;
}详细解释:
#include<stdio.h> // 引入标准输入输出库,用于printf和scanf等函数int main() // 定义主函数,程序从这里开始执行{printf("请输入一个要查找的数:"); // 使用printf函数输出提示信息,要求用户输入一个数字int x; // 声明一个整型变量x,用于存储用户输入的数字scanf("%d", &x); // 使用scanf函数读取用户输入的数字,并存储到变量x中int arr1[10] = { 3,4,7,12,24,78,9,15,80,45 }; // 声明并初始化一个包含10个整数的数组arr1int n = sizeof(arr1) / sizeof(arr1[0]); // 计算数组的长度,通过数组总大小除以单个元素的大小得到int flag = 0; // 声明一个整型变量flag,并初始化为0,用于标记是否找到了数字int position = 0; // 声明一个整型变量position,并初始化为0,用于存储找到的数字的位置(从1开始计数)for (int i = 0; i < n; i++) // 使用for循环遍历数组中的每一个元素{if (x == arr1[i]) // 如果当前元素的值等于用户输入的数字x{flag = 1; // 设置flag为1,表示找到了数字position = i + 1; // 更新position为当前位置i加1,因为位置从1开始计数break; // 跳出循环,因为已经找到了数字,不需要继续检查}}if (flag) // 如果flag为1,表示找到了数字{printf("哈哈哈,the number is found!\n"); // 输出找到数字的消息printf("它在第%d位", position); // 输出找到的数字的位置}else // 否则,表示没有找到数字{printf("the number is not found!\n"); // 输出未找到数字的消息}return 0; // 主函数返回0,表示程序正常结束}
- 提示用户输入一个数字。
- 读取用户输入的数字。
- 定义一个数组并初始化它。
- 计算数组的长度。
- 使用循环遍历数组,查找用户输入的数字。
- 如果找到数字,则设置flag为1,并更新position为找到的位置(从1开始计数)。
- 检查flag的值,如果为1,则输出找到数字的消息和位置;否则输出未找到数字的消息。
注意:代码中
printf("它在第%d位", position);这一行没有换行符\n,所以在输出位置后,终端可能不会立即跳到下一行,而是等待用户的进一步输入。如果希望输出后自动换行,可以改为printf("它在第%d位\n", position);。
第五个:
程序填空:把a数组中的奇数按原顺序依次存放到a[0]、a[1]、a[2]、……中,把偶数从数组中删除后输出a数组。请填空,填空时不得增行或删行,也不得更改程序的结构,一条横线上只能填写一条语句!
程序运行结果:The original data :
9 1 4 2 3 6 5 8 7
The odd number :
9 1 3 5 7
#include <stdio.h>
#define N 9
void main()
{ int a[N]={9,1,4,2,3,6,5,8,7}, i,j=0;
printf("\nThe original data :\n");
for (i=0; i<N; i++) printf("%4d ", a[i]);
printf("\n");
for (i=0; i<N; i++)
if (___【1】___) /*判断是否为奇数*/
{
a[j] = a[i];
___【2】___;
}
printf("\nThe odd number :\n");
for (i=0;____【3】___; i++)
printf("%4d ", a[i]);
printf("\n");
}
再给付一张完整的图。嘿嘿

相信才看见这个肯定有点懵逼。
#define N 9 什么意思
在C语言中,
#define N 9是一个预处理指令,它定义了一个名为N的宏,并将其值设置为9。这意味着在编译程序之前,预处理器会在整个源代码中查找N,并将其替换为9。这样做有几个好处:
代码可读性:使用
N而不是直接写数字9可以使代码更容易理解。如果以后需要改变这个值,只需要在#define指令中修改一次,而不是在整个代码中搜索和替换。易于维护:如果
N的值在程序的多个地方被使用,并且你需要改变这个值,那么只修改#define指令会比逐个修改代码中的每个数字更快捷、更不容易出错。代码灵活性:通过使用宏定义,你可以使代码更加灵活。例如,你可以在不同的编译配置或平台中使用不同的值。
在你提供的代码中,
N被用作数组a的大小。通过使用宏定义,如果以后需要改变数组的大小,你只需要修改#define N 9这一行,而不是整个数组的定义和相关的循环。此外,由于宏定义在预处理阶段就已经完成替换,所以它们不会占用运行时内存,也不会增加运行时开销。但需要注意的是,过度使用宏定义可能会使代码难以调试和理解,因为它们只是简单的文本替换,不会进行类型检查或其他编译时检查。
我来看看他这个到底是弄什么的,

这里看一下:
在这个代码段中:
for (i = 0; ____【3】___; i++)printf("%4d ", a[i]);
____【3】___应该填写的是循环的条件。根据上下文,这个循环的目的是输出数组中所有的奇数,而这些奇数已经被重新排列在数组a的前面了。由于我们不知道数组中具体有多少个奇数,所以不能简单地使用固定的数字作为循环的条件。但是,我们知道j变量记录了已经处理(即存储)的奇数的数量。因此,循环条件应该是
i < j,这意味着循环将执行j次,输出数组a中的前j个元素,这些元素就是原数组中的所有奇数,按原顺序排列。所以,
____【3】___应该填写为i < j。完整的循环将如下所示:
for (i = 0; i < j; i++)printf("%4d ", a[i]);这个循环的作用是输出数组中重新排列后的前
j个元素,即所有的奇数,每个数前面有4个空格用于对齐输出。这样,程序的输出将只包含原数组中的奇数,且按原顺序排列。
 OK了,可以看一下补充的;
OK了,可以看一下补充的;
#include<stdio.h>
#define N 9
void main()
{int a[N] = { 9,1,4,2,3,6,5,8,7 }, i, j = 0;printf("\nThe original data :\n");for (i = 0; i < N; i++) printf("%4d ", a[i]);printf("\n");for (i = 0; i < N; i++)if (a[i]%2==1) /*判断是否为奇数*/{a[j] = a[i];j++;}printf("\nThe odd number :\n");for (i = 0; i<j; i++)printf("%4d ", a[i]);printf("\n");
}以下是这段代码的详细解释:
首先,程序引入了标准输入输出头文件
<stdio.h>,并定义了一个宏N,其值为9。
#include<stdio.h>#define N 9然后,
main函数开始执行。在函数内部,定义了一个整数数组a,它的大小为N(即9),并初始化为9个整数。同时,定义了两个整数变量i和j,其中j被初始化为0。
int a[N] = { 9,1,4,2,3,6,5,8,7 }, i, j = 0;接下来,程序输出原始数据:
printf("\nThe original data :\n");for (i = 0; i < N; i++) printf("%4d ", a[i]);printf("\n");这里使用了一个
for循环来遍历数组a,并使用printf函数以宽度为4的格式输出每个元素,每个元素后面跟一个空格。输出结束后,还输出了一个换行符,使输出更加清晰。然后,程序开始处理数组,将奇数移动到数组的前面,并删除偶数:
for (i = 0; i < N; i++)if (a[i]%2==1) /*判断是否为奇数*/{a[j] = a[i];j++;}这个循环再次遍历数组
a。对于数组中的每个元素,它检查该元素是否为奇数(通过取模运算a[i]%2,如果结果为1,则是奇数)。如果是奇数,就将它复制到数组a的当前j位置,并将j增加1。这样,所有的奇数都将被依次存放到数组a的前面,而偶数则不再保留在数组中(它们的值会被后续的奇数覆盖)。最后,程序输出处理后的数组,即只包含奇数的数组:
printf("\nThe odd number :\n");for (i = 0; i<j; i++)printf("%4d ", a[i]);printf("\n");这个循环从数组的开头开始,输出到第
j个元素(不包含第j个元素),因为j现在包含了数组中奇数的数量。每个元素仍然以宽度为4的格式输出,并在每个元素后面跟一个空格。输出结束后,再次输出一个换行符。所以,程序的输出将是:
The original data :9 1 4 2 3 6 5 8 7The odd number :9 1 3 5 7注意:在C语言中,
main函数的返回类型应该是int,而不是void。因此,正确的main函数定义应该是:
int main() {// ... 程序内容 ...return 0;}在程序的最后返回0表示程序正常结束。
OK准备发布。