达梦DM SQL日期操作及分析函数
- 日期操作
- SYSDATE
- EXTRACT
- 判断一年是否为闰年
- 周的计算
- 确定某月内第一个和最后一个周末某天的日期
- 确定指定年份季度的开始日期和结束日期
- 补充范围内丢失的值
- 按照给定的时间单位查找
- 使用日期的特殊部分比较记录
- 范围处理
- 分析函数
- 定位连续值的范围
- 查找同一分区中行之间的差
- 定位连续范围的起始点
本文主要讲述DM 数据库中如何实现各种日期相关的运算以及如何利用分析函数 lead() over() 进行范围问题的处理。
日期操作
SYSDATE
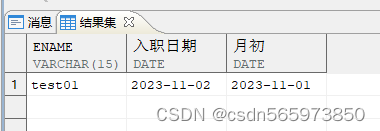
使用 trunc() 函数获得某个日期对应的月初时间
SELECT ename,hiredate AS 入职日期,TRUNC (hiredate, 'mm') AS 月初 FROM employee WHERE ROWNUM <= 1;
获取具体时间的时分秒、年月日、月初、周初、年初等
SELECT hiredate,TO_NUMBER (TO_CHAR (hiredate, 'hh24')) 时,TO_NUMBER (TO_CHAR (hiredate, 'mi')) 分,TO_NUMBER (TO_CHAR (hiredate, 'ss')) 秒,TO_NUMBER (TO_CHAR (hiredate, 'dd')) 日,TO_NUMBER (TO_CHAR (hiredate, 'mm')) 月,TO_NUMBER (TO_CHAR (hiredate, 'yyyy')) 年,TO_NUMBER (TO_CHAR (hiredate, 'ddd')) 年内第几天,TRUNC (hiredate, 'dd') 一天之始,TRUNC (hiredate, 'day') 周初,TRUNC (hiredate, 'mm') 月初,LAST_DAY (hiredate) 月末,ADD_MONTHS (TRUNC (hiredate, 'mm'), 1) 下月初,TRUNC (hiredate, 'yy') 年初,TO_CHAR (hiredate, 'day') 周几,TO_CHAR (hiredate, 'month') 月份FROM (SELECT hiredate FROM employeeWHERE ROWNUM <= 1);

EXTRACT
EXTRACT 函数可以提取时间字段中的年、月、日、时、分、秒,返回的值为 NUMBER 类型
SELECT EXTRACT (YEAR FROM SYSTIMESTAMP) AS 年,EXTRACT (MONTH FROM SYSTIMESTAMP) AS 月,EXTRACT (DAY FROM SYSTIMESTAMP) AS 日,EXTRACT (HOUR FROM SYSTIMESTAMP) AS 时,EXTRACT (MINUTE FROM SYSTIMESTAMP) AS 分,EXTRACT (SECOND FROM SYSTIMESTAMP) AS 秒FROM DUAL;

to_char 函数可以用来取日期时间类型字段中的时、分、秒
SELECT hiredate, TO_CHAR (hiredate, 'dd') AS 天, TO_CHAR (hiredate, 'hh24') AS 时 FROM employee WHERE ROWNUM <= 1;

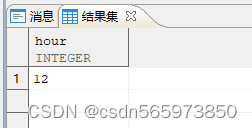
EXTRACT 函数可以用来取 INTERVAL 中的信息,to_char 函数不支持
SELECT EXTRACT (HOUR FROM it) AS "hour" FROM (SELECT INTERVAL '2 12:30:59' DAY TO SECOND AS it FROM DUAL);
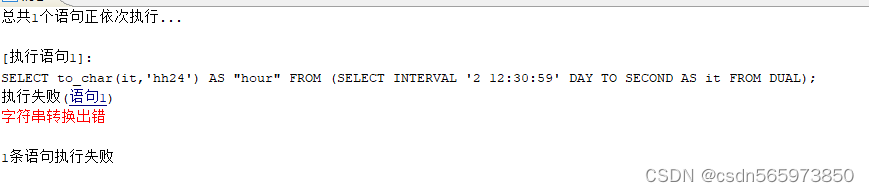
换成to_char函数
SELECT to_char(it,'hh24') AS "hour" FROM (SELECT INTERVAL '2 12:30:59' DAY TO SECOND AS it FROM DUAL);
判断一年是否为闰年
判断一年是否为闰年,可以看二月的月末具体是哪一天。使用 TO_CHAR、 LAST_DAY、 ADD_MONTHS、 TRUNC 函数共同实现
--计算年初 2023-01-01SELECT TRUNC (hiredate, 'y') 年初 FROM employee WHERE ROWNUM <= 1;--计算二月初 2023-02-01SELECT ADD_MONTHS (TRUNC (hiredate, 'y'), 1) 二月初 FROM employee WHERE ROWNUM <= 1;--计算二月底 2023-02-28SELECT LAST_DAY (ADD_MONTHS (TRUNC (hiredate, 'y'), 1)) AS 二月底 FROM employee WHERE ROWNUM <= 1;--计算二月底对应的日期SELECT TO_CHAR (LAST_DAY (ADD_MONTHS (TRUNC (hiredate, 'y'), 1)), 'DD') AS 日 FROM employee WHERE ROWNUM <= 1;
周的计算
使用 TO_CHAR、 NEXT_DAY、TRUNC 函数共同实现周的计算
WITH xAS (SELECT TRUNC (SYSDATE, 'yy') + (LEVEL - 1) AS 日期 FROM DUAL CONNECT BY LEVEL <= 8)SELECT 日期,TO_CHAR (日期, 'd') AS d,TO_CHAR (日期, 'day') AS day,NEXT_DAY (日期, 1) AS 下个周日,TO_CHAR (日期, 'ww') AS ww,TO_CHAR (日期, 'iw') AS iwFROM x;
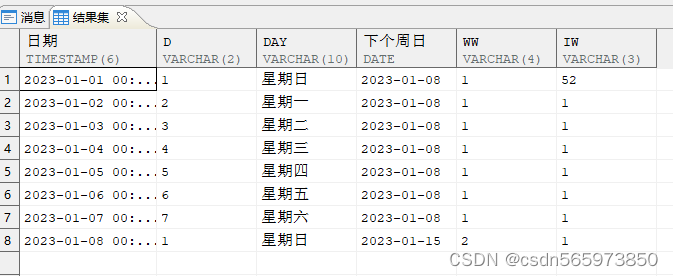
参数 “day” 与字符集无关,所以建议使用 “d”, WW 与 IW 都是取 “第几周”,只是两个参数的初始值不一样。
确定某月内第一个和最后一个周末某天的日期
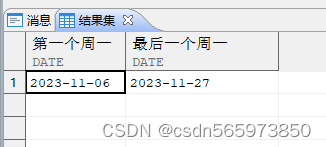
返回当月内第一个星期一与最后一个星期一,我们分别找上月末及当月末之前七天的下一周的周一即可
SELECT NEXT_DAY (TRUNC (hiredate, 'mm') - 1, 2) 第一个周一,NEXT_DAY (LAST_DAY (TRUNC (hiredate, 'mm')) - 7, 2) 最后一个周一FROM employeeWHERE ROWNUM <= 1;
确定指定年份季度的开始日期和结束日期
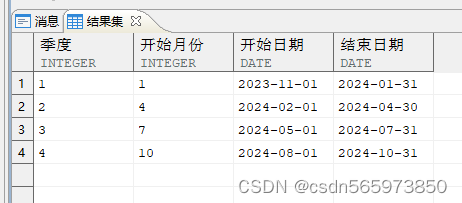
在写报表查询语句时需要按季度分类汇总,提取对应的季度开始日期和结束日期。可以通过 add_months、to_date 函数实现
SELECT sn AS 季度, (sn - 1) * 3 + 1 AS 开始月份, ADD_MONTHS (TO_DATE (年, 'yyyy'), (sn - 1) * 3) AS 开始日期, ADD_MONTHS (TO_DATE (年, 'yyyy'), sn * 3)-1 AS 结束日期FROM (SELECT '2023' AS 年, LEVEL AS sn FROM DUAL CONNECT BY LEVEL <= 4);
补充范围内丢失的值
统计每一年份入职员工数,若表中没有的年份,则展示的统计人数为 0
WITH xAS (SELECT 开始年份 + (LEVEL - 1) AS 年份FROM (SELECT EXTRACT (YEAR FROM MIN (hiredate)) AS 开始年份,EXTRACT (YEAR FROM MAX (hiredate)) AS 结束年份FROM employee)CONNECT BY LEVEL <= 结束年份 - 开始年份 + 1)SELECT * FROM x;
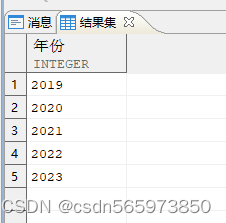
关联查询得到结果集
WITH xAS (SELECT 开始年份 + (LEVEL - 1) AS 年份FROM (SELECT EXTRACT (YEAR FROM MIN (hiredate)) AS 开始年份,EXTRACT (YEAR FROM MAX (hiredate)) AS 结束年份FROM employee)CONNECT BY LEVEL <= 结束年份 - 开始年份 + 1)SELECT x.年份, COUNT (e.empno) 入职人数FROM xLEFT JOIN employee eON (EXTRACT (YEAR FROM e.hiredate) = x.年份)GROUP BY x.年份ORDER BY 1;
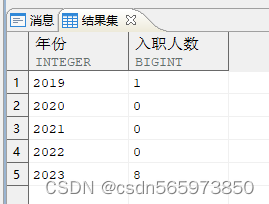
按照给定的时间单位查找
使用 to_char 函数查询给定时间单位的时间,比如查询如入职日期在 1 月或者 11 月且非星期三的员工信息
SELECT ename 姓名,hiredate 入职日期,TO_CHAR (hiredate, 'day') AS 星期FROM employeeWHERE TO_CHAR (hiredate, 'mm') IN ('01', '11')AND TO_CHAR (hiredate, 'd') != '4';

使用日期的特殊部分比较记录
使用 to_char 函数统计相同月份与周内日期入职的员工
SELECT ename 姓名,hiredate 入职日期,TO_CHAR (hiredate, 'MON day') AS 月周FROM (SELECT ename, hiredate, COUNT (*) OVER (PARTITION BY TO_CHAR (hiredate, 'MON day')) AS ctFROM employee)WHERE hiredate LIKE '2023%';
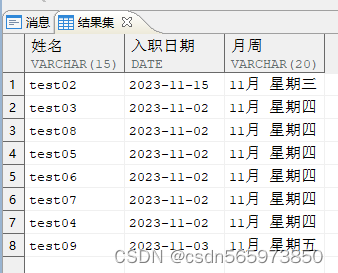
范围处理
分析函数
lead(列名,n,m) over(partition by … order by …),不带参数 n,m,则查找当前记录后面第一行的记录列名的值,参数说明
lead() 只能用于取后面第 n 行记录说明,不能取前面的。如果要取前面第 n 行记录说明,使用 lag()函数。over() 在什么条件之上,使用语法 over(partition by...order by...)。partition by 按某个字段划分组。order by 按某个字段排序。
定位连续值的范围
可以使用分析函数 lead() over() 定位某一段连续值的范围
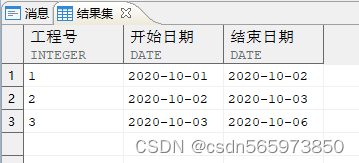
CREATE OR REPLACE VIEW v(pro_id,pro_start,pro_end) asSELECT 1,date '2020-10-01',date '2020-10-02' FROM dual UNION ALLSELECT 2,date '2020-10-02',date '2020-10-03' FROM dual UNION ALLSELECT 3,date '2020-10-03',date '2020-10-06' FROM dual UNION ALLSELECT 4,date '2020-10-06',date '2020-10-07' FROM dual UNION ALLSELECT 5,date '2020-10-09',date '2020-10-11' FROM dual UNION ALLSELECT 6,date '2020-10-13',date '2020-10-15' FROM dual;SELECT * FROM v;
查看创建的视图v
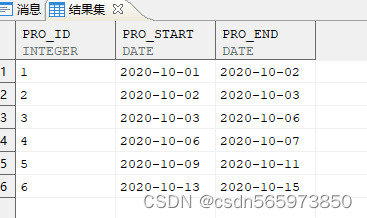
现在需要查询连续值记录,即下一行记录的开始时间与上一行记录的结束时间一致
SELECT 工程号, 开始日期, 结束日期FROM (SELECT pro_id AS 工程号,pro_start AS 开始日期,pro_end AS 结束日期,LEAD (pro_start) OVER (ORDER BY pro_id) 下一工程开始日期FROM v)WHERE 下一工程开始日期 = 结束日期;
查找同一分区中行之间的差
可以使用分析函数 lead() over() 查找同一分区中行之间的差
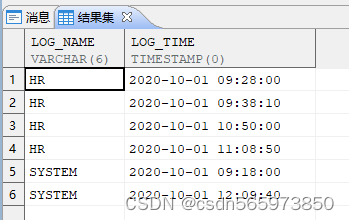
CREATE OR REPLACE VIEW v(log_name,log_time) asSELECT 'HR',datetime '2020-10-01 09:28:00' FROM dual UNION ALLSELECT 'HR',datetime '2020-10-01 09:38:10' FROM dual UNION ALLSELECT 'HR',datetime '2020-10-01 10:50:00' FROM dual UNION ALLSELECT 'HR',datetime '2020-10-01 11:08:50' FROM dual UNION ALLSELECT 'SYSTEM',datetime '2020-10-01 09:18:00' FROM dual UNION ALLSELECT 'SYSTEM',datetime '2020-10-01 12:09:40' FROM dual;SELECT * FROM v;
创建视图v
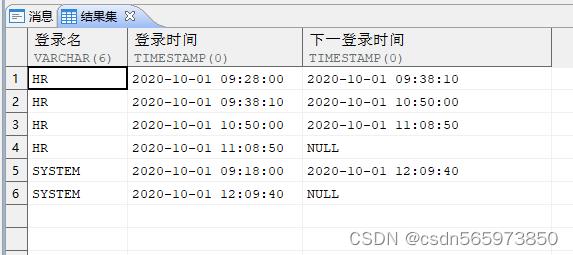
现在需要各用户两次登录的时间间隔,首先使用分析函数 lead() over() 取出下一行信息
SELECT log_name AS 登录名,log_time AS 登录时间,LEAD (log_time) OVER (PARTITION BY log_name ORDER BY log_time) 下一登录时间FROM v;
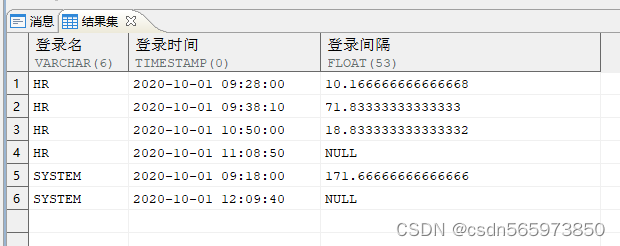
计算用户两次登录的时间间隔
SELECT log_name AS 登录名, log_time AS 登录时间, (next_log_time - log_time) * 24 * 60 AS 登录间隔FROM (SELECT log_name, log_time, LEAD (log_time) OVER (PARTITION BY log_name ORDER BY log_time) next_log_time FROM v);
定位连续范围的起始点
创建视图v
CREATE OR REPLACE VIEW v(pro_id,pro_start,pro_end) asSELECT 1,date '2020-10-01',date '2020-10-02' FROM dual UNION ALLSELECT 2,date '2020-10-02',date '2020-10-03' FROM dual UNION ALLSELECT 3,date '2020-10-03',date '2020-10-06' FROM dual UNION ALLSELECT 4,date '2020-10-06',date '2020-10-07' FROM dual UNION ALLSELECT 5,date '2020-10-09',date '2020-10-11' FROM dual UNION ALLSELECT 6,date '2020-10-13',date '2020-10-15' FROM dual;SELECT * FROM v;
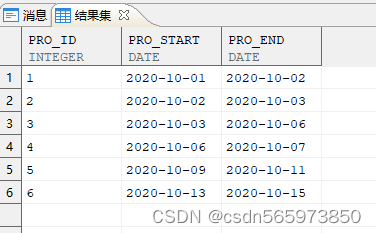
要求把连续的项目合并,返回合并后的起始时间,首先提取上一个工程结束时间
CREATE OR REPLACE VIEW x0ASSELECT pro_id AS 编号,pro_start AS 开始日期,pro_end AS 结束日期,LAG (pro_end) OVER (ORDER BY pro_id) AS 上一工程结束日期FROM v;SELECT * FROM x0;
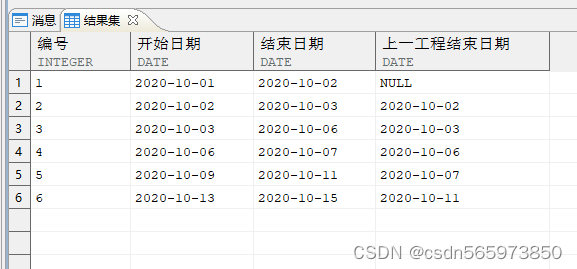
标定项目的连续状态
CREATE OR REPLACE VIEW x1ASSELECT 编号,开始日期,结束日期,上一工程结束日期,CASE WHEN 开始日期 = 上一工程结束日期 THEN 0 ELSE 1 END AS 连续状态 FROM x0;SELECT * FROM x1;
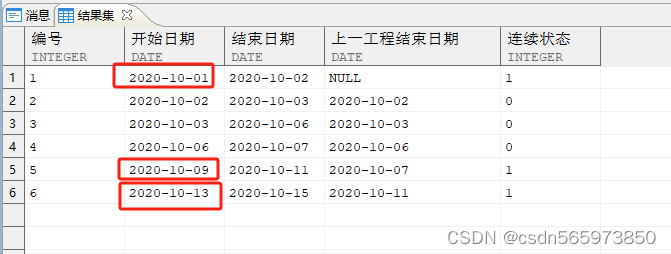
从结果图看出,每个连续分组的开始,都生成了一个“1”的标识,对位置状态进行累加,得到分组依据
CREATE OR REPLACE VIEW x2ASSELECT 编号,开始日期,结束日期,上一工程结束日期,连续状态,SUM(连续状态) over(ORDER BY 编号) AS 分组依据FROM x1;SELECT * FROM x2;
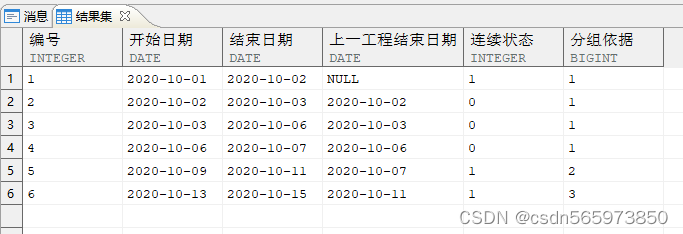
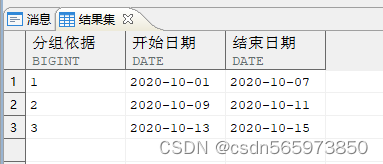
通过提取数据、生成标识、累加标识这些操作后,得到了需要的 3 个连续分组
SELECT 分组依据,MIN (开始日期) AS 开始日期,MAX (结束日期) AS 结束日期FROM x2GROUP BY 分组依据ORDER BY 1;
到这里基于DM 数据库中如何实现各种日期相关的运算以及如何利用分析函数 lead() over() 进行范围问题的处理也就算说完了,下面继续进行后续的操作。