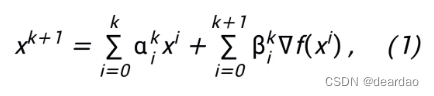23年4月,加州大学、Nvidia、Meta和Google联合发布了MCDiff模型。这是继DragNUWA之后,咱们介绍的第二篇Motion-guiding类视频生成模型。
Abstract
扩散模型的最新进展极大地提高了合成内容的质量和多样性。为了利用扩散模型的表达能力,研究人员探索了各种可控机制,允许用户直观地指导内容合成过程。尽管最新的努力主要集中在视频合成上,但缺乏有效的方法来控制和描述所需内容和动作。为了应对这一差距,我们引入了 MCDiff,这是一种条件扩散模型,它从一帧图像和一组笔画开始生成视频,允许用户指定用于合成的预期内容和动态。为了解决稀疏运动输入的模糊性,获得更好的合成质量,MCDiff首先利用流补全模型flow completion model根据视频帧的语义理解和稀疏运动控制来预测稠密视频运动。然后,扩散预测模型G合成高质量的未来帧,形成输出视频。我们定性和定量地证明了MCDiff在笔画引导的可控视频合成中实现了最先进的视觉质量。MPII人体姿势的其他实验进一步展示了我们的模型在不同内容和运动合成方面的能力。
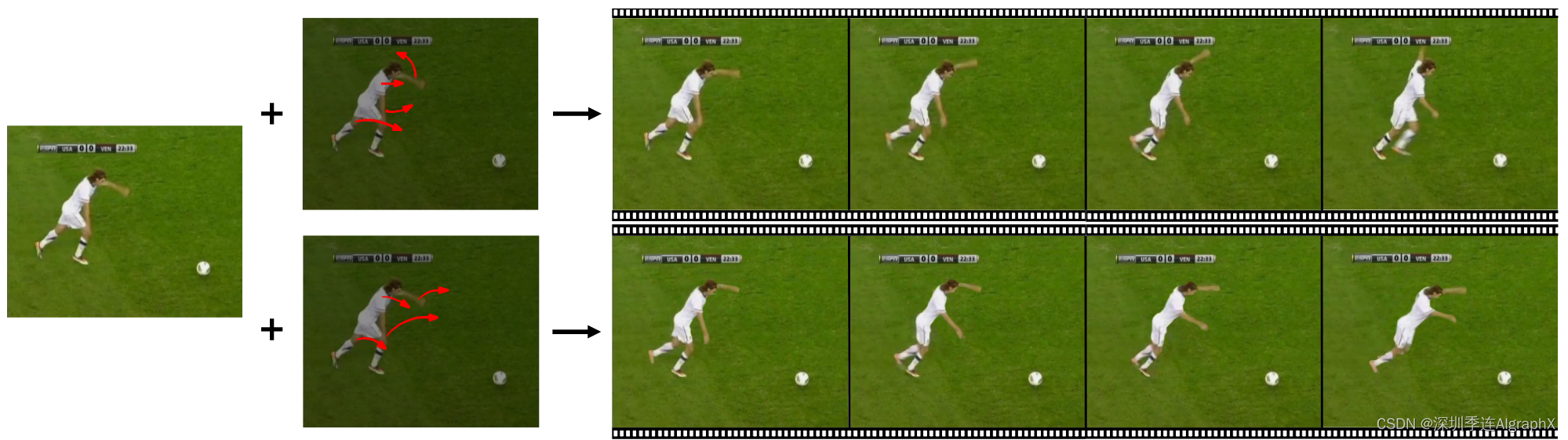
Figure 1: MCDiff enables flexible and accurate motion control in high-quality video synthesis with diffusion models.
1. Introduction
允许用户指定所需内容和动作的可控视频合成在视觉效果合成、视频编辑和动画等领域有许多应用。尽管新兴的扩散模型在视频合成方面取得了重大进展,但可控性程度仍然局限于粗粒度类或文本提示。这一观察激起了我们对视频合成过程中更细粒度用户控制的兴趣,特别是如何让用户准确地指定合成视频中的预期主题和动作。考虑到视频可以被视为内容和运动组件的组合,如图1所示,我们设计了一个界面,使用户能够使用参考图像指定内容作为视频的开始帧,并使用一组笔画输入控制运动。这些笔画可以描述整个视频中前景对象和相机调整(例如,缩放或移动视点)的期望运动。我们的目标是合成一个视频序列,忠实地反映指定的内容和运动信息。
虽然之前的研究用简单的数据集(如TaiChiHD和Human3.6M)对类似问题进行了探索性研究,但这些数据集仍然很简单(单一主体,单调背景下的动作),合成质量仍然是初步的,如章节 4.3 所示。为了利用扩散模型的表达能力试图来解决视觉质量问题,我们实现了一个单阶段条件扩散模型,该模型直接基于起始图像帧和笔画输入合成视频。然而,如第 4.4 节所述,这种原始的方法会导致不满意的结果。我们假设这挑战性任务失败是从两个方面引起的:
- 稀疏笔画所表现出的歧义;
- 真实视频合成对语义理解的要求。
例如,考虑这样一种情况,输入笔画表示向上移动的手。笔画只附加到单个像素上,但动作应该通过与手对应的所有像素传播。同时,手臂应该有一个连贯的运动。随着数据集中对象、场景和活动多样性的增加,这样的问题变得更加困难。从而否定了扩散模型在高质量下收敛和生产合理视频的能力。
为了减少单阶段端到端学习任务中表现出的模糊性和难度,我们提出了运动条件扩散模型,简称MCDiff,这是一个两阶段框架,将任务分解为两个子问题:稀疏到稠密流补全和未来帧预测。
流补全任务旨在基于输入视频帧的语义理解将输入笔画(相当于稀疏流)转换为更稠密的流,从而表示视频内的运动。接下来,未来帧预测模型基于当前帧和预测的稠密流,通过条件扩散过程生成下一个视频帧。最后,这两个网络被端到端地微调为一个连贯和协同的模型。我们观察到,两阶段模型稳定了训练,并成功地利用了扩散模型的优点,在忠实遵循输入笔画指示的同时,实现了卓越的视觉质量。
我们在三个大型视频数据集上评估了MCDiff。在标准基准Human3.6M、Image animation上的定量和定性实验表明,与以前的笔画引导可控视频合成方法相比,MCDiff实现了最先进的视觉质量。然后,我们在MPII人类姿势数据集上进一步检查了我们方法的局限性,该数据集是一组在各种条件和相机设置下拍摄的400多个人类活动的视频。实验证明了所提出的模型在合成具有不同上下文和运动视频方面的能力。MCDiff发现前景主题上的笔画表示对象移动,而背景场景上的笔画代表相机调整。这样的行为能够实现更灵活的控制和逼真的摄像机轨迹,用于视频合成和编辑。
2. Related Works
Controllable Diffusion Models for Content Synthesis.
最近的许多工作提出了为图像或 3D 形状扩散模型量身定制的新型控制机制。这些方法旨在为用户提供控制合成新内容的过程,通常是合成目标的外观或形状。对于图像扩散模型,这些控制机制包括文本、图像参考、分割图草图、轮廓或场景图。类似的控制机制也可以在 3D 形状扩散模型中找到,例如文本、图像参考和分割图。
- Magic3D: High-Resolution Text-to-3D Content Creation
- DREAMFUSION: TEXT-TO-3D USING 2D DIFFUSION
- RealFusion: 360{deg} Reconstruction of Any Object from a Single lmage
- 3D-aware Conditional lmage Synthesis
在本文中,我们提出了另一种扩散模型控制机制,实现了更细粒度的视频合成控制。
Video Diffusion Models
最近,已经开发了几种基于扩散模型的方法来合成时间一致的视频。这些探索性工作中的大多数要么专注于无条件视频合成或粗粒度控制,而不是文本提示的合成过程。
- Video Diffusion Models
- IMAGEN VIDEO: HIGH DEFINITION VIDEO GENERATION WITH DIFFUSION MODELS
- Make-A-Video: Text-to-Video Generation without Text-Video Data
最近的一些研究探索了对不同方法的扩散过程的细粒度控制,例如通过将视频模拟到不同的艺术风格来编辑视频,用文本提示修改运动,改变视频中的主要主题,或从演示外推运动。
- Structure and Content-Guided Video Synthesis with Diffusion Models
- Video diffusion models are general video editors
- Tune-A-Video: One-Shot Tuning of lmage Diffusion Models for Text-to-Video Generation
- SinFusion: Training Diffusion Models on a Single lmage or Video
然而,这些方法需要一个输入视频来提供初始运动,这使得控制机制无法对所需的目标运动进行更精细的调整。
许多作品将视频合成视为未来帧预测任务,旨在基于输入图像合成视频。这样的问题需要根据图像中的内容线索合成适当的运动。之前的方法通常不需要额外的输入条件,因此缺乏指导目标视频运动的机制。因此,我们的控制机制可以看作是未来帧预测任务的扩展,因为许多现实世界设计师和编辑的工作流程需要准确和精确的控制来实现它们在最终产品中所需的运动。
Controllable Video Synthesis
许多视频合成方法利用不同类型的控制机制。动作转换或图像再现是一类从参考视频中提取运动并使用其驱动静止图像的方法。这些方法需要视频演示,因此更难实现细粒度和精确的控制。可播放视频合成学习一组输入指令,使得用户可以交互式地控制场景中某些主题的空间位置,并产生时间连贯的视频。然而,这些学习到的指令仍然是简单的粗粒度操作,并且仅控制在所有训练数据中共享的单个主题。
一些先前的方法也采用笔画输入作为其控制机制,这与我们的研究密切相关。
- Click To Move: Controlling Video Generation With Sparse Motion
- iPOKE: Poking a Still lmage for Controlled Stochastic Video Synthesis
- Understanding Object Dynamics for Interactive lmage-to-Video Synthesis
- Controllable Video Generation with Sparse Trajectories
C2M等明确地学习了通过预测未来帧的稠密光流图和扭曲特征来对视频运动进行建模。这种扭曲操作往往会造成不自然的扭曲,从而损害视觉质量。另一方面,II2V和iPOKE将视频压缩到稠密的潜在空间中,并学会用递归神经网络操纵这些潜在变量。然而,如图4所示,这些方法的质量仍然是初步的,生成的结果往往包含不自然的失真,导致视觉质量较差。
3. Method
MCDiff采用两种类型的输入,表示视频内容的开始图像帧 和控制运动的一组笔画。
这些笔画被解释为一组稀疏流 { },其中每个稀疏流
是受控像素从时间步长
到
+1的瞬时位移。基于这些输入,我们的目标是合成
帧视频
{
},其内容和运动遵循输入条件。
在实践中,我们发现以稀疏流作为输入直接驱动条件扩散模型会导致次优性能,如第 4.4 节所示。这样的观察启发了两阶段框架的开发,该框架具有额外的模块来解决稀疏流输入的模糊性和难度。具体来说,如图 2 所示,我们以自回归的方式合成视频,并通过两个模型完成视频帧合成:流补全 和未来帧预测
。为了生成视频帧
,我们首先利用流补全模型来预测稠密流映射
,基于当前视频帧
和稀疏流
。随后,我们设计了一个条件扩散模型,以在当前帧
和预测的稠密流
的基础上生成未来帧
。

图 2:MCDIff架构。MCDiff 是一个自回归视频合成模型。对于每个时间步长,模型由前一帧(即开始或先前预测的帧)和输入笔画的瞬间段(标记为彩色箭头,较亮的颜色表示更大的运动)引导。流补全模型F首先预测代表每像素瞬时运动的稠密流。然后,未来帧预测模型通过条件扩散过程基于前一帧和预测的密集流合成下一帧。最后,遵循起始帧提供的上下文和笔画指定的运动,所有预测帧的集合形成一视频序列。
3.1. Annotations of Video Dynamics
Flow是用于表达视频动态的直观表示。密集流标记了从一个视频帧到另一个的逐像素运动方向,描述了相应像素在经过的时间内产生的运动。
如图3所示,为了获得视频的稠密流,我们在图像帧上散布一组跟踪点 P,然后通过通用点和关键点跟踪算法检索整个视频中这些跟踪点的轨迹。
###跟踪算法如以下论文给出
Particle Videos Revisited: Tracking Through Occlusions Using Point Trajectories
Deep High-Resolution Representation Learning for Visual Recognition
我们用关键点的轨迹覆盖一般点的轨迹来聚合这两个结果,因为前者往往对人形先验更准确。最终,通过在整个视频中稠密标注的轨迹,我们可以很容易地在两个任意帧 之间生成稠密流图,表示为
。

图 3:视频动态的标注。我们通过跟踪关键点(红色,用身体骨架标记以获得更好的可视化)和一般点网格(灰色)来表达视频动态。通过在整个视频中跟踪点的轨迹,我们可以很容易地在两个任意帧 之间产生稠密流图
。
3.2. Flow Completion Model
给定当前帧 和瞬时稀疏流
,流补全模型 F 旨在预测稠密流图
。我们首先重新格式化稀疏流
为2D映射,其中每个像素表示从时间步长
到
+1 的用户指定的运动。由于流的稀疏性,该操作引入了大量的缺失值。我们用共享和可学习的嵌入填充缺失的值,以表示在这些像素值中不存在用户指定的运动。然后将 2D 映射与
级联,形成 F 的输入数据,实现为一个UNet网络。
我们以自监督方式训练 F。也就是说,对于作为训练数据的每一对帧 ,我们通过对提取到的稠密流
进行下采样,仿真用户指定的稀疏流
。为了更好地在稀疏流数据集中保持有意义的视频动态,我们优先对与关键点像素相对应的流进行采样,因为它们对表示视频中的主体运动更为关键。此外,考虑到幅度较大的流通常更具代表性,我们使用流幅度作为采样概率,对关键点流进行采样。另一方面,我们还随机采样一般跟踪点的流,以表示其他对象的运动和由于相机调整而导致的背景移动。
利用仿真的稀疏流 作为输入,然后我们监督 F,在
和预测的稠密流
之间计算MSE损失。然而,在使用静态相机的某些场景中,流幅度的分布可能由零值主导。这种不平衡的分布导致模型倾向于生成小的运动。为了缓解这个不令人满意的问题,对于每个跟踪点 p,我们基于流幅度应用额外的每像素加权因子Wp。总的来说,我们训练 F 的目标如下:
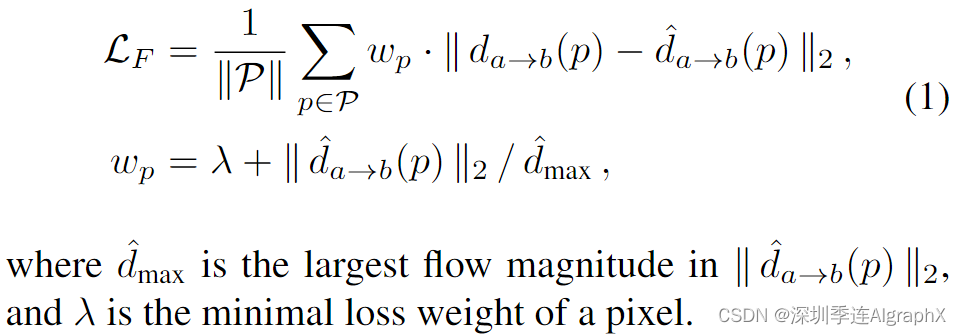
3.3. Future-Frame Prediction
接下来,我们基于当前帧 和预测的稠密流图
生成未来帧
。我们将视频帧合成问题公式化为一系列去噪扩散过程,以利用扩散模型的表现力。形式上,为了合成未来的帧
,我们首先从高斯分布中采样变量
,然后通过具有 t 个时间步长的UNet网络逐渐去噪噪声变量
(其中 t= T,…,1)。为了使去噪过程以当前帧
和稠密流图
为条件,我们遵循LDM,并将有噪声变量
与
和
这两个条件连接起来,以形成去噪UNet的输入数据。最后,我们将输出
作为预测的未来帧
。
为了用任意视频帧 对训练未来帧预测模块 G,我们取当前帧
和提取的稠密流图
作为输入,并通过预测
的损失来监督G

3.4. End-to-End Fine-Tuning
在分别训练 F 和 G 直到收敛后,我们对整个流程进行端到端微调,减少两个模型之间的域差距,以更好地协同它们的相互作用。具体来说,我们通过对当前帧 和来自F预测的稠密流图
进行G 条件处理来级联两个模型,形成端到端可微流程
。我们以端到端的方式对整个流程进行微调,目标如下:

4. Experiments
4.1. Datasets
三个数据集:TaiChi-HD、Human3.6M、MPII Human Pose。
4.2. Implementation Details
Model Architecture
对于流补全模型F和未来预测模型G中的 UNet 骨干网络,我们都使用了LDM-4。为了在有限的计算资源上实现高分辨率视频合成,我们遵循LDM,通过预训练的VQ-4自动编码器将空间大小为256×256的视频帧编码为大小为64×64的潜在变量。在推理过程中,经过去噪处理,我们将潜在变量解码为分辨率为256×256的输出视频。
Video Dynamics Annotations
为了跟踪人体关键点,我们首先应用HRNet对每个人的17个关键点的位置进行逐帧估计,在相邻的两帧之间连接人的身份。对于一般点的跟踪,我们执行PIP来跟踪MPII的64×64个均匀分散点和其他两个数据集的16×16个点的网格。
Model Training
给定一个视频,我们对一对间隔为 的帧
进行采样以进行训练。如第3.2 节所述,我们对提取的稠密流
进行下采样得到稀疏流
用于训练 F。具体而言,我们对两组跟踪点的流进行随机采样:
- 每个人采样30%的关键点
- MPII数据集采样8个通用点,另外两个采样4个
注意,关键点的采样概率与其流幅度相关,而一般点是均匀采样的。MCDiff训练包括两个步骤。
- 首先,我们分别训练F和G进行400k次迭代,批量大小为40,学习率为4.5e-6,G为7e-5,并将 λ 设置为0.2。
- 在第二阶段,我们通过额外的100k次迭代对整个pipeline进行微调,批量大小为20,学习率为7e-5。L的加权因子为 λF=0.05 和 λG=1。
我们在8个NVIDIA A100 GPU上训练该模型。
4.3. Comparisons with Prior Methods

4.4. Failure of Single-Stage Framework
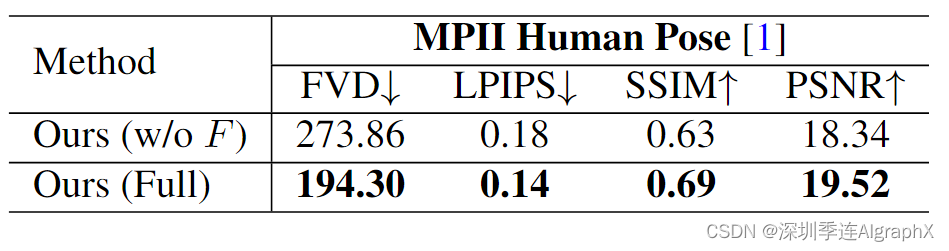
接下来,我们进行消融研究,以证明流补全模型 F 对 MPII 的必要性。对于没有 F 的模型,我们直接使用稀疏流图作为 G 的输入。我们在MPII上分别训练两个模型,其他实验设置与 4.3 节相同。结果如表 2 所示。这些结果表明,从稠密流图合成未来帧可以更好地解决稀疏动作输入的模糊性和难度问题,有利于视频帧合成过程。
4.5. Synthesis with Diverse Contents and Motions

5. Conclusion and Limitations
我们提出了MCDiff,这是一个用于可控视频合成的强大扩散模型框架,通过直观和细粒度的用户控制界面实现了高质量和高保真度的视频合成。该方法在三个具有广泛人类活动的大规模视频合成数据集上显示出有希望的结果。
尽管显示出了令人印象深刻的结果,但我们的框架仍然受到一些限制。
- 首先,由于流补全模型是以数据驱动的方式学习的,因此很难完成远远超出训练数据分布的编辑。学习一个可以处理新的对象组件的生成模型仍然具有挑战性,我们把构建这样一个通才模型作为未来重要的方向。
- 其次,针对常见的网络视频数据,采用基于模式识别的方法提取训练流,不包含实际运动场的特殊感知信息;由于这些方法旨在解决视频帧之间图像模式的关系,因此它们通常在具有无纹理表面或视觉错觉(例如barber-pole illusion)的视频中失败。
未来使用特殊传感器或仿真来构建物理真值运动场的视频数据集可以帮助解决这些困难和罕见情况。
本专题由深圳季连科技有限公司AIgraphX自动驾驶大模型团队编辑,旨在学习互助。内容来自网络,侵权即删。文中如有错误的地方,也请在留言区告知。
论文名称:Motion-Conditioned Diffusion Model for Controllable Video Synthesis。
MCDiff-https://arxiv.org/abs/2304.14404
Motion-Conditioned Diffusion Model for Controllable Video Synthesis