泰坦尼克号乘客生存情况预测分析1
泰坦尼克号乘客生存情况预测分析2
泰坦尼克号乘客生存情况预测分析3
泰坦尼克号乘客生存情况预测分析总

背景描述
Titanic数据集在数据分析领域是十分经典的数据集,非常适合刚入门的小伙伴进行学习!
泰坦尼克号轮船的沉没是历史上最为人熟知的海难事件之一。1912年4月15日,在她的处女航中,泰坦尼克号在与冰山相撞后沉没,在船上的 2224 名乘客和机组人员中,共造成 1502 人死亡。这场耸人听闻的悲剧震惊了国际社会,从而促进了船舶安全规定的完善。造成海难失事的原因之一是乘客和机组人员没有足够的救生艇。尽管在沉船事件中幸存者有一些运气因素,但有些人比其他人更容易存活下来,究竟有哪些因素影响着最终乘客的生存与否呢?
数据说明
在该数据集中,共包括三个文件,分别代表训练集、测试集以及测试集的答案;
数据描述:
| 变量名称 | PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 变量解释 | 乘客编号 | 是否存活 | 船舱等级 | 姓名 | 性别 | 年龄 | 兄弟姐妹和配偶数量 | 父母与子女数量 | 票的编号 | 票价 | 座位号 | 登船码头 |
| 数据类型 | numeric | categorical | categorical | String | categorical | categorical | numeric | numeric | string | numeric | string | categorical |
注:以上数据类型均为经过预处理后的数据类型!
数据来源
Titanic Competition : How top LB got their score
目录
- 背景描述
- 数据说明
- 数据来源
- 二 特征工程
- 1. 合并训练集与测试集
- 2. 缺失值处理
- 2.1 填充Embarked字段
- 2.2 填充船票Fare字段
- 2.3 填充年龄Age字段
- 3 不同特征字段的数据处理
- 3.1 先对Embarked、Sex以及Pclass等用dummy处理
- 3.2 票价分级处理
- 3.3 名字处理
- 3.4 Cabin处理
- 3.5 Ticket处理
- 4. 利用随机森林预测Age缺失值
- 5. 各特征与Survived的相关系数排序
- 6. 保存特征处理后的数据
- 7. 小结
二 特征工程
1. 合并训练集与测试集
在进行特征工程的时候,我们不仅需要对训练数据进行处理,还需要同时将测试数据同训练数据一起处理,使得二者具有相同的数据类型和数据分布。
import pandas as pdtrain = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
train_and_test = train.append(test, sort=False) # 合并训练集与测试集
PassengerId = test['PassengerId']
train_and_test.shape

2. 缺失值处理
对Embarked直接用众数填充;
对Fare用均值填充;
对Age,建立模型预测;
2.1 填充Embarked字段
mode = train_and_test['Embarked'].mode().iloc[0] # 找到众数
train_and_test['Embarked'].fillna(mode, inplace=True)
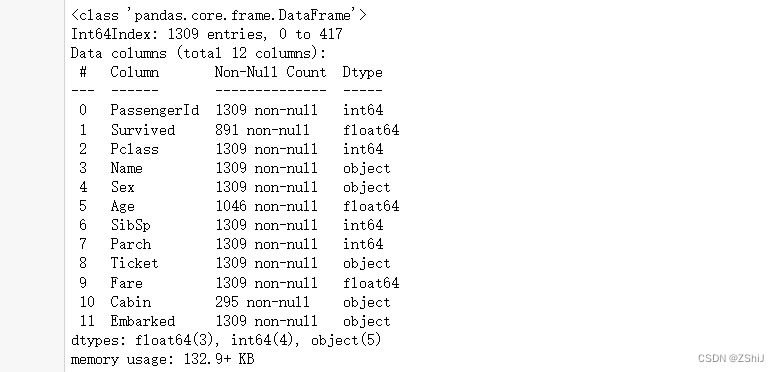
train_and_test.info()

2.2 填充船票Fare字段
train_and_test['Fare'].mean()

Fare_mean = train_and_test['Fare'].mean()
train_and_test['Fare'].fillna(Fare_mean, inplace=True)
train_and_test.info()
2.3 填充年龄Age字段
为尽可能用多的特征去预测Age的值,先对Cabin、Embarked、Name、Sex、Ticket、Pclass等特征进行处理,模型预测见后;
3 不同特征字段的数据处理
3.1 先对Embarked、Sex以及Pclass等用dummy处理
对分类特征进行编码
cols = ['Embarked', 'Sex', 'Pclass']
train_and_test = pd.get_dummies(train_and_test, columns=cols, prefix_sep='__')
train_and_test.info()

3.2 票价分级处理
我们可以尝试将Fare分桶处理,使用qcut函数。qcut是根据这些值的频率来选择箱子的均匀间隔,每个箱子中含有的数的数量是相同的;
# 临时列
train_and_test['Fare_bin'] = pd.qcut(train_and_test['Fare'], 5)#编码
train_and_test['Fare_bin_id'] = pd.factorize(train_and_test['Fare_bin'])[0]
fare_bin_dummies_df = pd.get_dummies(train_and_test['Fare_bin_id']).rename(columns=lambda x : 'Fare_' + str(x))
train_and_test = pd.concat([train_and_test, fare_bin_dummies_df], axis=1)
train_and_test.drop(['Fare_bin'], axis=1, inplace=True)
3.3 名字处理
对名字Name进行处理,提取其特征;
提取称呼
train_and_test['Title'] = train_and_test['Name'].apply(lambda x : x.split(',')[1].split('.')[0].strip())
train_and_test['Title']

# 将各式称呼进行统一化处理
# 头衔映射表
titleDict = {"Capt" : "Officer", "Col" : "Officer","Major": "Officer","Jonkheer": "Royalty","Don": "Royalty","Sir" : "Royalty","Dr": "Officer","Rev": "Officer","the Countess":"Royalty","Dona": "Royalty","Mme": "Mrs","Mlle": "Miss","Ms": "Mrs","Mr" : "Mr","Mrs" : "Mrs","Miss" : "Miss","Master" : "Master","Lady" : "Royalty"
}
train_and_test['Title'] = train_and_test['Title'].map(titleDict)
train_and_test['Title'].value_counts()

one_hot编码
train_and_test['Title'] = pd.factorize(train_and_test['Title'])[0]
title_dummies_df = pd.get_dummies(train_and_test['Title'], prefix=train_and_test[['Title']].columns[0])
train_and_test = pd.concat([train_and_test, title_dummies_df], axis=1)
train_and_test.info()
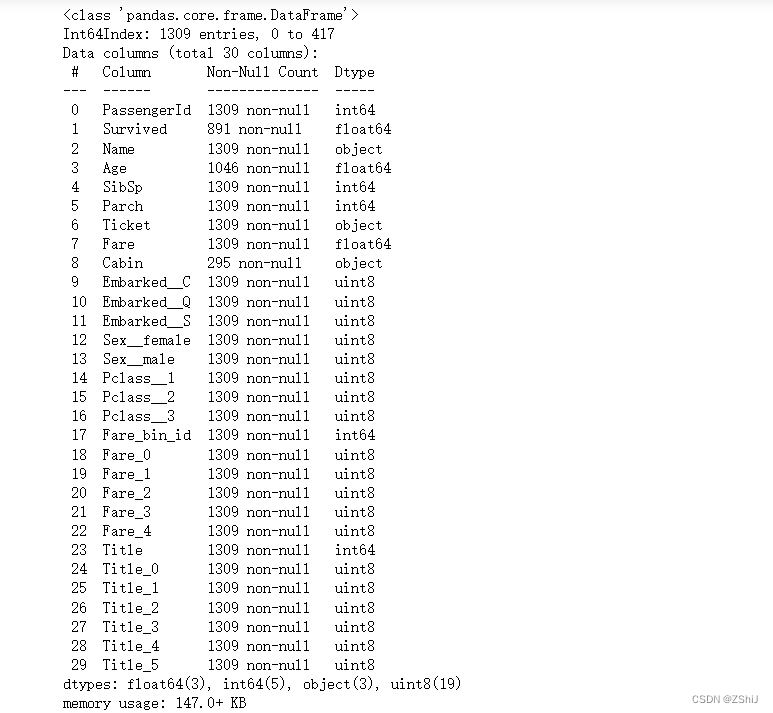
提取长度特征
train_and_test['Name_length'] = train_and_test['Name'].apply(len)
train_and_test['Name_length']

3.4 Cabin处理
Cabin缺失值过多,将其分为有无两类,进行编码,如果缺失,即为0,否则为1;
train_and_test.loc[train_and_test.Cabin.isnull(), 'Cabin'] = 'U0'
train_and_test['Cabin'] = train_and_test['Cabin'].apply(lambda x : 0 if x == 'U0' else 1)
train_and_test['Cabin']

3.5 Ticket处理
Ticket有字母和数字之分,对于不同的字母,可能在很大程度上就意味着船舱等级或者不同船舱的位置,也会对Survived产生一定的影响,所以我们将Ticket中的字母分开,为数字的部分则分为一类。
train_and_test['Ticket_Letter'] = train_and_test['Ticket'].str.split().str[0]
train_and_test['Ticket_Letter'] = train_and_test['Ticket_Letter'].apply(lambda x : 'U0' if x.isnumeric() else x)# 将Ticket_Letter factorize
train_and_test['Ticket_Letter'] = pd.factorize(train_and_test['Ticket_Letter'])[0]
train_and_test['Ticket_Letter']

4. 利用随机森林预测Age缺失值
from sklearn.ensemble import RandomForestRegressor # 随机森林回归missing_age = train_and_test.drop(['PassengerId', 'Survived', 'Name', 'Ticket'], axis=1) # 去除字符串类型的字段
missing_age_train = missing_age[missing_age['Age'].notnull()]
missing_age_test = missing_age[missing_age['Age'].isnull()]X_train = missing_age_train.iloc[:,1:]
y_train = missing_age_train.iloc[:,0]
X_test = missing_age_test.iloc[:,1:]rfr = RandomForestRegressor(n_estimators=1000, n_jobs=-1)
rfr.fit(X_train, y_train)
y_predict = rfr.predict(X_test)
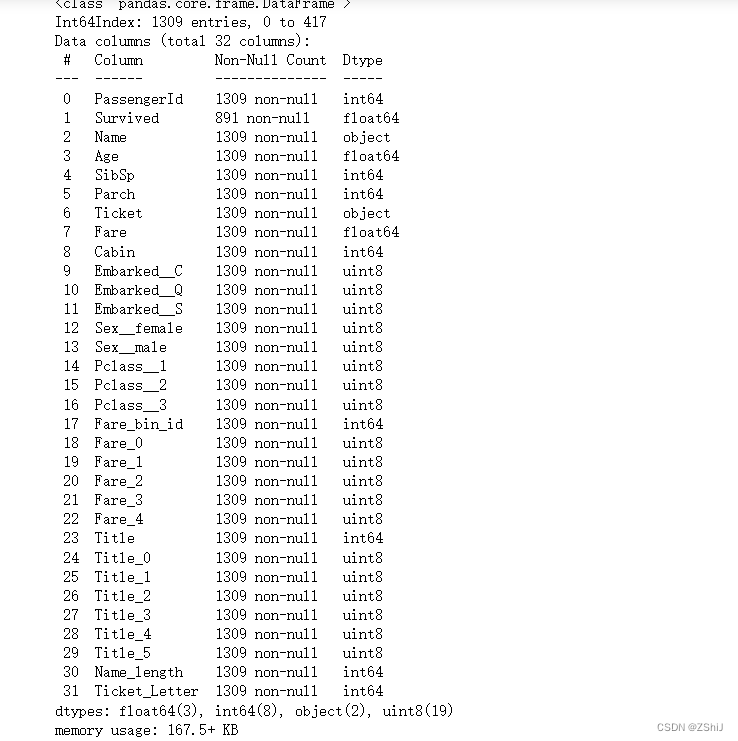
train_and_test.loc[train_and_test['Age'].isnull(), 'Age'] = y_predict
train_and_test.info()
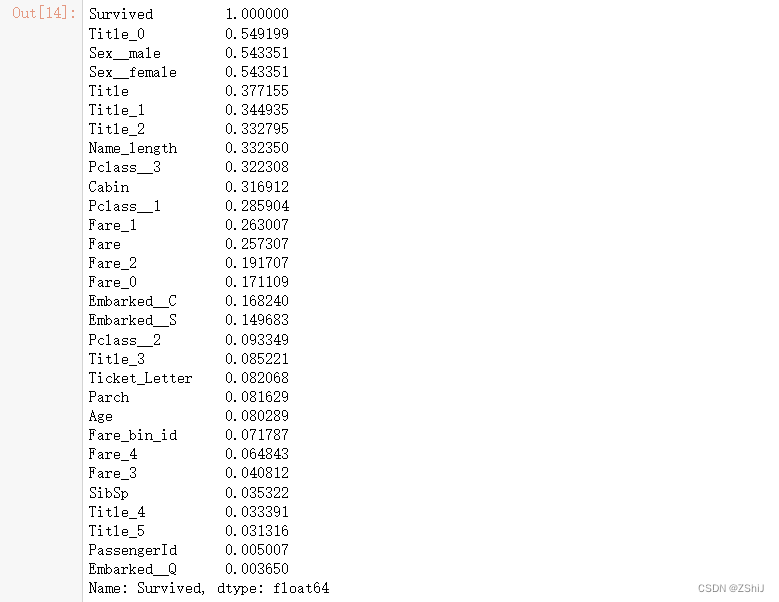
5. 各特征与Survived的相关系数排序
根据生存情况与其他各特征的相关系数,按系数倒序排序,筛选出重要特征 – 重要特征
train_and_test.corr()['Survived'].abs().sort_values(ascending=False)
6. 保存特征处理后的数据
train_and_test.to_csv('经过特征工程处理后的数据.csv', index=None)
7. 小结
特征工程这一章主要做了以下工作:
- 合并训练集和测试集
- 为了使二者具有相同的数据类型和数据分布;
- 缺失值处理:
- Embarked:众数填充;
- Fare:平均值填充;
- Age:随机森林预测填充;
- 各特征字段的数据处理:
- Embarked,Sex,Pclass: 直接dummy编码;
- Fare: 先分桶处理,再dummy编码;
- Name: 先提取称呼,再对称呼进行人群分类,最后dummy处理;
- cabin:缺失值较多,根据是否缺失划分类别,缺失为0,否则为1;
- Ticket:只保留其中字母,并对字母进行数字转换;
- 随机森林建模预测Age缺失值;
- 对各特征与生存与否进行了相关系数大小排序;
本章主要关于到泰坦尼克号数据的特征工程处理,后续就是建模预测部分了,建模预测打算分两部分,一部分只是简单涉及一些算法,参数全部默认;另一部分,会加些算法调参、优化以及复杂模型等,这几天就会安排上!
如果本文有存在不足的地方,欢迎大家在评论区留言