为学
开始一个新的学习计划,涵盖:
| 主题 | 学习内容 |
|---|---|
| CUDA | Professional CUDA C Programming/NVIDIA CUDA初级教程视频(周斌) |
| C++ | C++Primer / The Cherno CPP |
| Unity Compute Shader | Udemy Learn to Write Unity Compute Shaders |
| Linear Algebra | MIT 18.06 Prof.Gilbert Strang Linear Algebra |
本系列博客用以记录学习过程中的知识要点!!!
为学
—彭端淑
天下事有难易乎?为之,则难者亦易矣;不为,则易者亦难矣。人之为学有难易乎?学之,则难者亦易矣;不学,则易者亦难矣。
2023/4/28
〇、CUDA
1.使用nvfrof时,报错
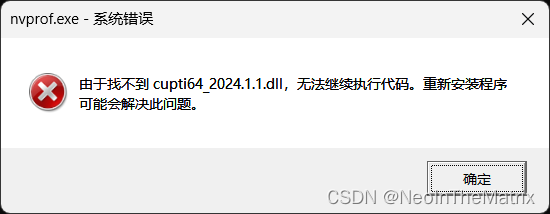
解决方法:
将路径
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\extras\CUPTI\lib64
下的文件
cupti64_2024.1.1.dll
复制到路径
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\bin
下即可。
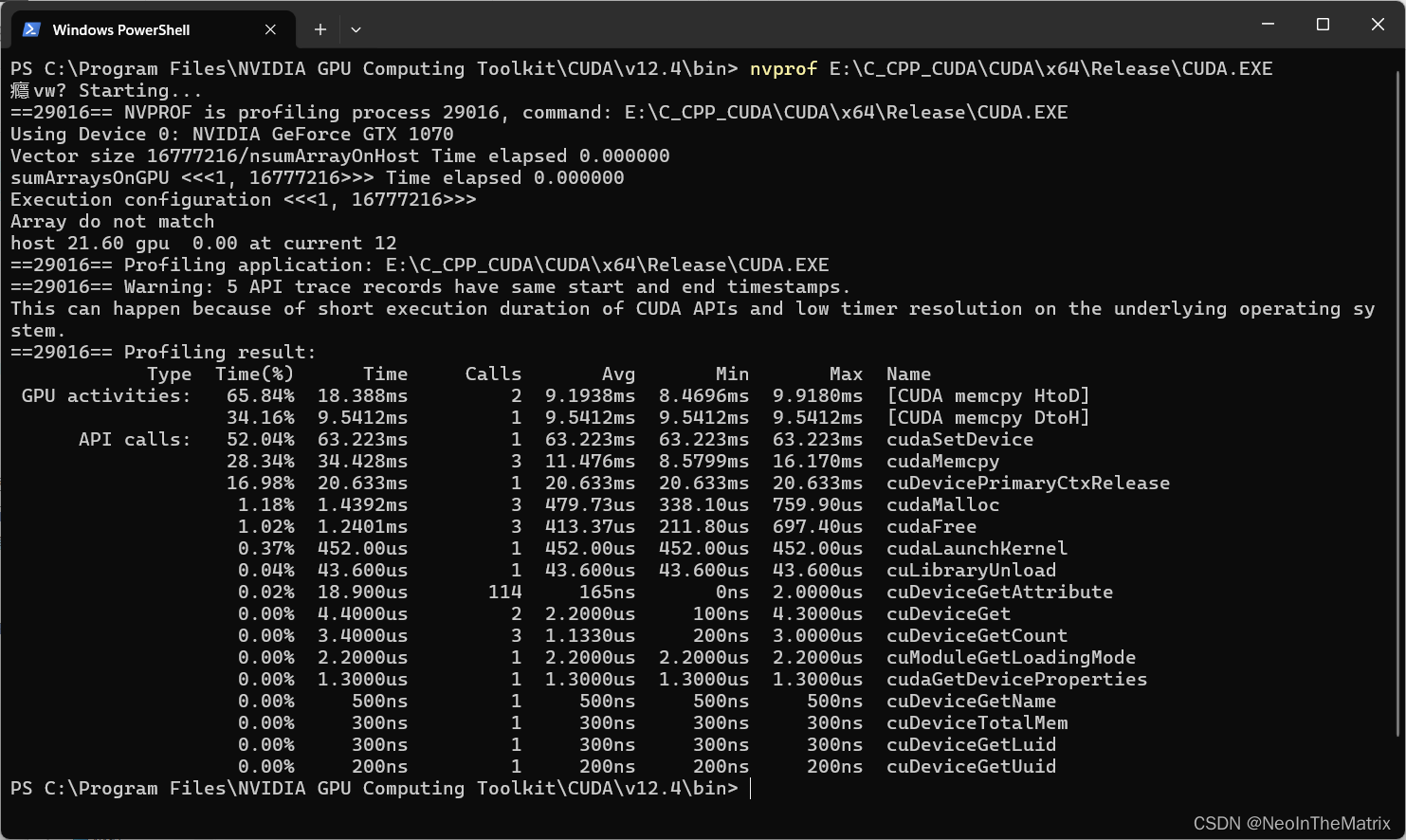
2.nvprof的使用
Shift+鼠标右键->在此处打开PowerShell窗口(S)
在控制台中输入
nvprof E:\C_CPP_CUDA\CUDA\x64\Release\CUDATest.exe
3.Win10/Win11查看CUDA Capability Major
在路径
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\extras\demo_suite
中使用Shift+鼠标右键->在此处打开PowerShell窗口(S)
然后将deviceQuery.exe拖入到PowerShell窗口中,即可查看;
注:应该可以deviceQuery.exe直接查看,可是这个控制台程序不暂停,一闪而退。
4.未解决问题
在PowerShell中使用nvcc命令编译
PS E:\C_CPP_CUDA\CUDA\CUDA> nvcc sumArrayOnHost.cu -o sum
sumArrayOnHost.cu
nvcc error : 'cudafe++' died with status 0xC0000005 (ACCESS_VIOLATION)
网上找的解决方法都不行呢,有知道如何解决的望告知呢;
因可在Visual Studio中直接通过调试器直接进行编译,所以命令行编译不行就不行吧。
5.CUDA 2.2 给核函数计时
a>#include <sys/time.h>
该文件应为linux系统下的头文件,在windows中可使用time.h头文件;
#include <time.h>int main(){clock_t start=clock();//do somethingclock_t elaps=clock()-start;printf("do something spent %.10f ms",elaps);}
6.CHECK方法中的call显示未定义
严重性 代码 说明 项目 文件 行 禁止显示状态 详细信息
错误(活动)
E0020 未定义标识符 "call" CUDA E:\C_CPP_CUDA\CUDA\CUDA\sumArrayOnHost.cu 10
//后面这个反斜杠必须有啊啊啊
#define CHECK(call){ \ const cudaError_t error = call; \if (error != cudaSuccess) { \printf("Error: %s:%d ", __FILE__, __LINE__); \printf("code:%d, reason: %s\n", error, cudaGetErrorString(error)); \exit(1); \} \
}
一、CPP
1.break语句会跳出整个循环,而非内层循环;
2.C++的编译
编译包含外部代码的项目,
外部include文件添加
项目->(鼠标右键)属性->C/C++->Addtional Include Directories->"include files path"
外部lib添加
项目->(鼠标右键)属性->链接器->Addtional Library Directories->"lib path"
- 编译出错时,应首先聚焦第一个错误;
- 查看CPP文件的汇编代码
在需要查看汇编代码的地方打断点,当代码运行至该位置时,鼠标右键->转到反汇编
2024/04/29
第一课 CPU体系架构概述
桌面应用
真正用于数值计算的指令很少
CPU程序为串行程序优化
流水线
分支预测
超标量
乱序执行
存储器层次
矢量操作
多核处理
缓慢的内存带宽(存储器带宽)是大问题
并行处理是方向
第二课 并行程序设计概述
为什么
Power Wall
Memory Wall
怎么做
数据并行处理
并行计算模式
同时应用多个计算资源解决一个计算问题
基本概念
Flynn矩阵
S single I instruction M multiple D data
SISD SIMD
MISD MIMD
常见名词
Task
Paralllel Task
Serial Execution(串行执行)
Parallel Exection
Shared Memory
Distributed Memory
Communications
Synchronizations(同步)
Granularity(粒度)
Observed Speedup
Parrallel Overhead(并行开销)
Scalability
并行编程模型
共享存储模型
线程模型
消息传递模型
数据并行模式
数据和任务分割
Amdahl’s Law
speedup=-1/1-P
没有可并行化的 P=0
全部都可以并行化 P=1
speedup=1/(P/N+S)
P=并行部分
N=处理器数
S=串行部分
并行化的可扩展性有极限
| speedup | |||
|---|---|---|---|
| N | P=.50 | P=.90 | P=.99 |
| 10 | 1.82 | 5.26 | 9.17 |
| 100 | 1.98 | 9.17 | 50.25 |
| 1000 | 1.99 | 9.91 | 90.99 |
| 10000 | 1.99 | 9.91 | 99.02 |
第三课 CUDA开发环境搭建和工具配置
没啥好讲的,直接装NVIDIA CUDA TOOLKIT,装Visual Studio
第四课 GPU体系架构概述
带宽是非常宝贵的资源
Bandwidth is critical resource!
带宽受限!!!
Bandwidth limited!!!
减少带宽需求
GPU是异构 众核 处理器
针对吞吐优化
第五课 GPU编程模型
CPU和GPU的交互模型
DRAM GDRAM| |CPU GPU| PCIe | ---------------------- |I/O I/O
交互开销较大
GPU线程组织模型
访存速度
GPU存储模型
GPU线程组织模型
Grid
Block
Thread
线程组织架构说明
一个Kernel具有大量线程
线程被划分成线程块“blocks”
- 一个block内部的线程共享“Shared Memory”
- 可以同步“_syncthreads()”
Kernel启动一个“grid”,包含若干线程块
- 用户设定
- 线程和线程块具有唯一的标识
有很多通俗易懂的图,后续补充
SIMT
Single Instruction Mutilple Threads
CUDA Extended C
CUDA函数声明
第五课 CUDA编程
CUDA
层次化线程集合
Grid 一维或多维线程块(block)
- 1D/2D/3D
Block 一组线程
- 1D/2D/3D
- 一个Grid里面的每个Block的线程数是一样的
- block内部的每个线程可以
- 同步 synchronic
- 访问共享存储器
- 块索引 blockIdx
- 维度 blockDim
- 1D/2D/3D
线程
ThreadID threadIdx
- 1D/2D/3D
共享存储
同步
术语
Host 主机
Device 设备
Kernel 数据并行处理函数
通过调用kernel函数在设备端创建轻量级线程
线程由硬件创建并调度