系列文章目录

文章目录
- 系列文章目录
- 前言
- 一、本文要点
- 二、开发环境
- 三、原项目
- 四、修改项目
- 五、测试一下
- 五、小结
前言
本插件稳定运行上百个kafka项目,每天处理上亿级的数据的精简小插件,快速上手。
<dependency><groupId>io.github.vipjoey</groupId><artifactId>multi-kafka-consumer-starter</artifactId><version>最新版本号</version>
</dependency>
例如下面这样简单的配置就完成SpringBoot和kafka的整合,我们只需要关心com.mmc.multi.kafka.starter.OneProcessor和com.mmc.multi.kafka.starter.TwoProcessor 这两个Service的代码开发。
## topic1的kafka配置
spring.kafka.one.enabled=true
spring.kafka.one.consumer.bootstrapServers=${spring.embedded.kafka.brokers}
spring.kafka.one.topic=mmc-topic-one
spring.kafka.one.group-id=group-consumer-one
spring.kafka.one.processor=com.mmc.multi.kafka.starter.OneProcessor // 业务处理类名称
spring.kafka.one.consumer.auto-offset-reset=latest
spring.kafka.one.consumer.max-poll-records=10
spring.kafka.one.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.one.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer## topic2的kafka配置
spring.kafka.two.enabled=true
spring.kafka.two.consumer.bootstrapServers=${spring.embedded.kafka.brokers}
spring.kafka.two.topic=mmc-topic-two
spring.kafka.two.group-id=group-consumer-two
spring.kafka.two.processor=com.mmc.multi.kafka.starter.TwoProcessor // 业务处理类名称
spring.kafka.two.consumer.auto-offset-reset=latest
spring.kafka.two.consumer.max-poll-records=10
spring.kafka.two.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.two.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer国籍惯例,先上源码:Github源码
一、本文要点
本文将介绍通过封装一个starter,来实现多kafka数据源的配置,通过通过源码,可以学习以下特性。系列文章完整目录
- SpringBoot 整合多个kafka数据源
- SpringBoot 批量消费kafka消息
- SpringBoot 优雅地启动或停止消费kafka
- SpringBoot kafka本地单元测试(免集群)
- SpringBoot 利用map注入多份配置
- SpringBoot BeanPostProcessor 后置处理器使用方式
- SpringBoot 将自定义类注册到IOC容器
- SpringBoot 注入bean到自定义类成员变量
- Springboot 取消限定符
二、开发环境
- jdk 1.8
- maven 3.6.2
- springboot 2.4.3
- kafka-client 2.6.6
- idea 2020
三、原项目
1、接前文,我们开发了一个kafka插件,但在使用过程中发现有些不方便的地方,例如我们所有processor需要继承MmcKafkaKafkaAbastrctProcessor<T extends MmcKafkaMsg> ,其中的T为反序列化的实体类类型。
@Slf4j
@Service
public class OneProcessor extends MmcKafkaKafkaAbastrctProcessor<DemoMsg> {@Resourceprivate DemoService demoService;@Overrideprotected Class<DemoMsg> getEntityClass() {return DemoMsg.class;}@Overrideprotected void dealMessage(List<DemoMsg> datas) {demoService.dealMessage("one", datas.stream().map(x -> (MmcKafkaMsg) x).collect(Collectors.toList()));}}@Slf4j
@Service
public class TwoProcessor extends MmcKafkaKafkaAbastrctProcessor<DemoMsg> {@Resourceprivate DemoService demoService;public TwoProcessor() {}@Overrideprotected Class<DemoMsg> getEntityClass() {return DemoMsg.class;}@Overrideprotected void dealMessage(List<DemoMsg> datas) {demoService.dealMessage("two", datas.stream().map(x -> (MmcKafkaMsg) x).collect(Collectors.toList()));}}2、可以看到这里有两个体验不太好的地方。
- 自定义实体类DemoMsg 必须要继承 MmcKafkaMsg,很多同学会忘记这个步骤;
- 需要覆盖
getEntityClass()父类方法,用于反序列化指定实体类的类型,这里太冗余;
因此、所以我们要升级和优化。
四、修改项目
1、取消限定符,消息实体类不再强制要求实现MmcKafkaMsg接口,改为可选项,作为候选插件化的能力增强(后文介绍);
@Data
class DemoMsg {private String routekey;private String name;private Long timestamp;}
2、修改MmcKafkaKafkaAbastrctProcessor类,取消限定符并增加类型推断方法。
a、如果实现了MmcKafkaMsg接口,就拥有了单次消费内的batch数据去重能力;
public void onMessage(List<ConsumerRecord<String, String>> records) {if (null == records || CollectionUtils.isEmpty(records)) {log.warn("{} records is null or records.value is empty.", name);return;}Assert.hasText(name, "You must pass the field `name` to the Constructor or invoke the setName() after the class was created.");Assert.notNull(properties, "You must pass the field `properties` to the Constructor or invoke the setProperties() after the class was created.");try {Stream<T> dataStream = records.stream().map(ConsumerRecord::value).flatMap(this::doParse).filter(Objects::nonNull).filter(this::isRightRecord);// 支持配置强制去重或实现了接口能力去重if (properties.isDuplicate() || isSubtypeOfInterface(MmcKafkaMsg.class)) {// 检查是否实现了去重接口if (!isSubtypeOfInterface(MmcKafkaMsg.class)) {throw new RuntimeException("The interface "+ MmcKafkaMsg.class.getName() + " is not implemented if you set the config `spring.kafka.xxx.duplicate=true` .");}dataStream = dataStream.collect(Collectors.groupingBy(this::buildRoutekey)).entrySet().stream().map(this::findLasted).filter(Objects::nonNull);}List<T> datas = dataStream.collect(Collectors.toList());if (CommonUtil.isNotEmpty(datas)) {this.dealMessage(datas);}} catch (Exception e) {log.error(name + "-dealMessage error ", e);}}
b、新增类型推断方法,目的是去掉子类必须实现getEntityClass()的约束;
protected boolean isSubtypeOfInterface(Class<?> interfaceClass) {if (null == type) {Type superClass = getClass().getGenericSuperclass();if (superClass instanceof ParameterizedType) {ParameterizedType parameterizedType = (ParameterizedType) superClass;Type[] typeArguments = parameterizedType.getActualTypeArguments();if (typeArguments.length > 0 && typeArguments[0] instanceof Class) {//noinspection uncheckedtype = (Class<T>) typeArguments[0];}}}return (null != type) && interfaceClass.isAssignableFrom(type);}protected Class<T> getEntityClass() {if (null == type) {synchronized(this) {Type superClass = getClass().getGenericSuperclass();if (superClass instanceof ParameterizedType) {ParameterizedType parameterizedType = (ParameterizedType) superClass;Type[] typeArguments = parameterizedType.getActualTypeArguments();if (typeArguments.length > 0 && typeArguments[0] instanceof Class) {//noinspection uncheckedtype = (Class<T>) typeArguments[0];}}}}return type;}
c、修改去重方法,也就是取批次内最新一条消息,不再使用限定符;
protected T findLasted(Map.Entry<String, List<T>> entry) {try {Optional<T> d = entry.getValue().stream().max(Comparator.comparing(x -> ((PandoKafkaMsg) x).getRoutekey()));if (d.isPresent()) {return d.get();}} catch (Exception e) {String content = JsonUtil.toJsonStr(entry.getValue());log.error("处理消息出错:{}", e.getMessage() + ": " + content, e);}return null;}protected String buildRoutekey(T t) {return ((MmcKafkaMsg) t).getRoutekey();}3、修改MmcKafkaBeanPostProcessor,取消限定符。
public class MmcKafkaBeanPostProcessor implements BeanPostProcessor {@Getterprivate final Map<String, MmcKafkaKafkaAbastrctProcessor<?>> suitableClass = new ConcurrentHashMap<>();@Overridepublic Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {if (bean instanceof MmcKafkaKafkaAbastrctProcessor) {MmcKafkaKafkaAbastrctProcessor<?> target = (MmcKafkaKafkaAbastrctProcessor<?>) bean;suitableClass.putIfAbsent(beanName, target);suitableClass.putIfAbsent(bean.getClass().getName(), target);}return bean;}
}
4、修改MmcKafkaProcessorFactory,取消限定符。
五、测试一下
1、引入kafka测试需要的jar。参考文章:kafka单元测试
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka-test</artifactId><scope>test</scope></dependency>2、定义一个消息实体和业务处理类。
@Data
class DemoMsg {private String routekey;private String name;private Long timestamp;}
@Slf4j
@Service
public class OneProcessor extends MmcKafkaKafkaAbastrctProcessor<DemoMsg> {@Resourceprivate DemoService demoService;@Overrideprotected void dealMessage(List<DemoMsg> datas) {datas.forEach(x -> {log.info("dealMessage one: {}", x);});}}
3、配置kafka地址和指定业务处理类。
spring.kafka.one.enabled=true
spring.kafka.one.consumer.bootstrapServers=${spring.embedded.kafka.brokers}
spring.kafka.one.topic=mmc-topic-one
spring.kafka.one.group-id=group-consumer-one
spring.kafka.one.processor=com.mmc.multi.kafka.starter.OneProcessor // 业务处理类名称
spring.kafka.one.consumer.auto-offset-reset=latest
spring.kafka.one.consumer.max-poll-records=10
spring.kafka.one.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.one.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer4、编写测试类。
@Slf4j
@ActiveProfiles("dev")
@ExtendWith(SpringExtension.class)
@SpringBootTest(classes = {MmcMultiConsumerAutoConfiguration.class, DemoService.class, OneProcessor.class})
@TestPropertySource(value = "classpath:application.properties")
@DirtiesContext
@EmbeddedKafka(topics = {"${spring.kafka.one.topic}"})
class AppTest {@Resourceprivate EmbeddedKafkaBroker embeddedKafkaBroker;@Value("${spring.kafka.one.topic}")private String topicOne;@Value("${spring.kafka.two.topic}")private String topicTwo;@Testvoid testDealMessage() throws Exception {// 模拟生产数据produceMessage();Thread.sleep(10 * 1000);}void produceMessage() {Map<String, Object> configs = new HashMap<>(KafkaTestUtils.producerProps(embeddedKafkaBroker));Producer<String, String> producer = new DefaultKafkaProducerFactory<>(configs, new StringSerializer(), new StringSerializer()).createProducer();for (int i = 0; i < 10; i++) {DemoMsg msg = new DemoMsg();msg.setRoutekey("routekey" + i);msg.setName("name" + i);msg.setTimestamp(System.currentTimeMillis());String json = JsonUtil.toJsonStr(msg);producer.send(new ProducerRecord<>(topicOne, "my-aggregate-id", json));producer.send(new ProducerRecord<>(topicTwo, "my-aggregate-id", json));producer.flush();}}
}5、运行一下,测试通过。
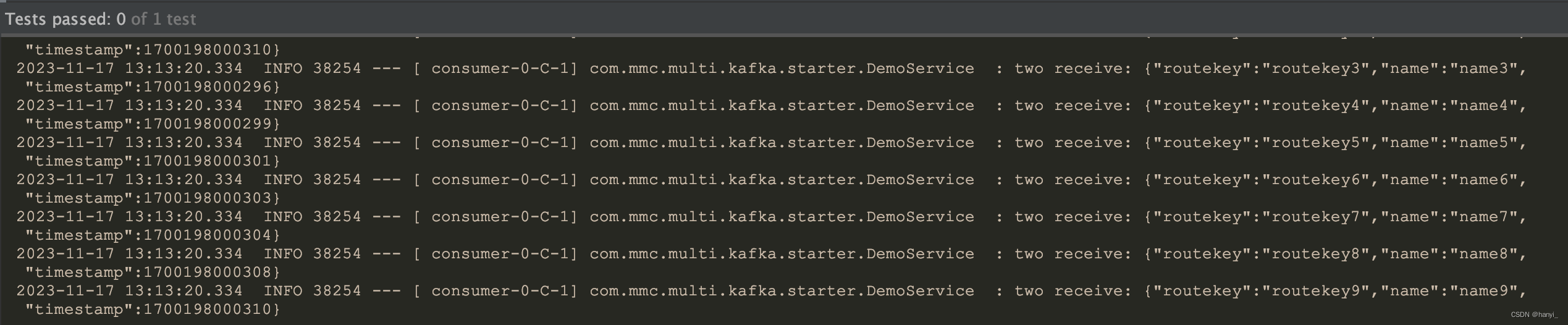
五、小结
将本项目代码构建成starter,就可以大大提升我们开发效率,我们只需要关心业务代码的开发,github项目源码:轻触这里。如果对你有用可以打个星星哦。下一篇,升级本starter,在kafka单分区下实现十万级消费处理速度。
加我加群一起交流学习!更多干货下载、项目源码和大厂内推等着你
 |  |