一、接着上文
上文已说到totalIds在or查询条件中,所以不会匹配到索引。
本文我们试着调整下查询条件,观察调整后,特别是totalIds字段,将匹配哪个索引。(观察的依据仍是查询计划的executionStats)
- 把totalIds从or查询条件中提取出来
// 调整前
"$or": [{ "auth": 1 },{ "totalIds": { "$in": [10001] } }
]// 调整后
{ "totalIds": { "$in": [10001] } }实际业务调整,让请求客户端,选择两者中的任意一个条件。这样,就需要写or条件了。
至于auth查询条件,想要查询变快,可以创建索引auth_1_createdOn_0,另外缩短查询的时间范围。(我们近一年auth=1的数据量不过2000条)
本文的主要内容是针对totalIds字段如何匹配索引,以及使用哪个组合索引。
二、新的执行计划
执行的步骤是(由内往外):IXSCAN -> FETCH -> OR -> FETCH -> SORT_KEY_GENERATOR -> SORT -> PROJECTION
可以看到,查询耗时提高了至少百倍,只需要37毫秒,检索的索引数量由十几万减少到几百。
'executionStats': {'nReturned': 4,'executionTimeMillis': 37,'totalKeysExamined': 486,'totalDocsExamined': 486,'executionStages': {'stage': "SINGLE_SHARD",'nReturned': 4,'executionTimeMillis': 37,'totalKeysExamined': 486,'totalDocsExamined': 486,'totalChildMillis': NumberLong("37"),'shards': [{'shardName': "d-bp1cef3c8241a8a4",'executionSuccess': true,'executionStages': {'stage': "PROJECTION",'nReturned': 4,'executionTimeMillisEstimate': 1,'works': 495,'advanced': 4,'needTime': 489,'needYield': 0,'saveState': 34,'restoreState': 34,'isEOF': 1,'invalidates': 0,'transformBy': {'$sortKey': {'$meta': "sortKey"}},'inputStage': {'stage': "SORT",'nReturned': 4,'executionTimeMillisEstimate': 1,// 略'inputStage': {'stage': "SORT_KEY_GENERATOR",'nReturned': 4,'executionTimeMillisEstimate': 1,// 略'inputStage': {'stage': "FETCH",'filter': {// 略},'nReturned': 4,'executionTimeMillisEstimate': 1,// 略'inputStage': {'stage': "OR",'nReturned': 486,'executionTimeMillisEstimate': 0,// 略'inputStages': [{'stage': "FETCH",'filter': {'recycle': {'$eq': null}},'nReturned': 0,'executionTimeMillisEstimate': 0,// 略'inputStage': {'stage': "IXSCAN",'nReturned': 0,'executionTimeMillisEstimate': 0,// 略}},{'stage': "IXSCAN",'nReturned': 486,'executionTimeMillisEstimate': 0,// 略}]}}}}}}]}
},
- IXSCAN
查询语句匹配到了索引totalIds_1_isDelete_1_recycle_1_creatorName_1,其中 ‘isMultiKey’: true, 因为totalIds是一个数组。
'stage': "IXSCAN",
'nReturned': 486,
'executionTimeMillisEstimate': 0,
'works': 487,
'advanced': 486,
'needTime': 0,
'needYield': 0,
'saveState': 34,
'restoreState': 34,
'isEOF': 1,
'invalidates': 0,
'keyPattern': {'totalIds': 1.0,'isDelete': 1.0,'recycle': 1.0,'creatorName': 1.0
},
'indexName': "totalIds_1_isDelete_1_recycle_1_creatorName_1",
'isMultiKey': true,
'multiKeyPaths': {'totalIds': ["totalIds"],'isDelete': [],'recycle': [],'creatorName': []
},
'isUnique': false,
'isSparse': false,
'isPartial': false,
'indexVersion': 2,
'direction': "forward",
'indexBounds': {'totalIds': ["[10001, 10001]"],'isDelete': ["[false, false]"],'recycle': ["[0, 0]"],'creatorName': ["[MinKey, MaxKey]"]
},
'keysExamined': 486,
'seeks': 1,
'dupsTested': 486,
'dupsDropped': 0,
'seenInvalidated': 0
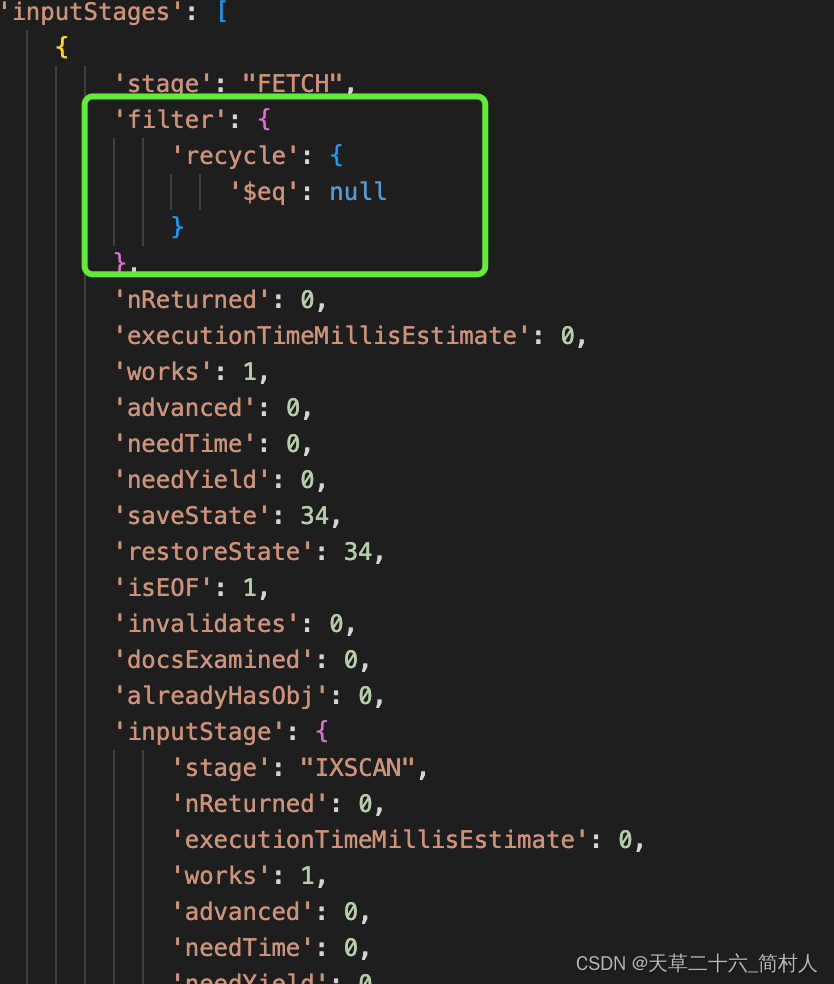
OR
“第一个”FETCH和IXSCAN两个stage之间是OR关系。这里的IXSCAN和上一个stage相同。
这里说它是“第一个”FETCH,因为外层还有一个FETCH。
本阶段主要是针对recycle查询条件,这也提醒我们在编程的时候,对字段不要赋空,要赋一个默认状态的值。
就拿本例的recycle字段为例:
- 保存记录的时候,recycle=0
- 放入回收站的时候,recycle=1
- 从回收站还原的时候,recycle=0
如此,recycle字段的值要么是0,要么是1。
而查询条件也就可以优化,不存在or查询了。
// 修改前
{"$or":[{"recycle":null},{"recycle":0}]}// 修改后
{"recycle":0}
“第二个”FETCH
和前文不同,根据创建时间区间检索,由IXSCAN阶段改为FETCH阶段了。
'stage': "FETCH",
'filter': {'$and': [{'createdOn': {'$lte': ISODate("2024-04-29T00:00:00.000Z")}},{'createdOn': {'$gte': ISODate("2023-04-28T00:00:00.000Z")}},{'classroomName': {'$regex': ".*大口加小口.*"}}]
},
SORT
SORT排序是在内存中进行排序,所以它的速度非常快。

三、组合索引的差异
前文,我们说了,包含totalIds字段的组合索引有两个:
- totalIds_1_isDelete_1_recycle_1_creatorName_1
- totalIds_1_createdOn_2
mongodb匹配的是前者,而非后者。(个人认为,Mongo应该是根据组合索引匹配的字段数量来,前者匹配了三个字段,而后者是两个字段)
这也给我们建组合索引提了个醒,不要像我们这样,一通下来,期望匹配的索引(totalIds_1_createdOn_2)反而落榜了。
如果你想要指定使用索引totalIds_1_createdOn_2,在末尾指定hint(“totalIds_1_createdOn_2”)
见下所示:

当然,对于本查询来说,只要查询条件totalIds匹配了索引,由于其区分度非常高,最后的查询效率都很高。(查询只需几十毫秒)
下面说一说,当指定使用索引totalIds_1_createdOn_2时,执行计划变成怎么样了。
执行步骤为(由内往外):IXSCAN --> FETCH --> SORT_KEY_GENERATOR --> SORT --> PROJECTION
"winningPlan" : {"stage" : "PROJECTION","transformBy" : {"$sortKey" : {"$meta" : "sortKey"}},"inputStage" : {"stage" : "SORT","sortPattern" : {"createdOn" : -1},"limitAmount" : 20,"inputStage" : {"stage" : "SORT_KEY_GENERATOR","inputStage" : {"stage" : "FETCH","filter" : {// 略},"inputStage" : {"stage" : "IXSCAN","keyPattern" : {"totalIds" : 1,"createdOn" : 1},"indexName" : "totalIds_1_createdOn_2","isMultiKey" : true,"multiKeyPaths" : {"totalIds" : ["totalIds"],"createdOn" : [ ]},"isUnique" : false,"isSparse" : false,"isPartial" : false,"indexVersion" : 2,"direction" : "forward","indexBounds" : {"totalIds" : ["[MinKey, MaxKey]"],"createdOn" : ["[MinKey, MaxKey]"]}}}}}}
最内层的索引数据检索,使用了我们指定的索引totalIds_1_createdOn_2。
四、总结
通过两篇文章,我们举例一个集合的多个组合索引,对比分析其执行计划。
因为只有执行计划,才是判定你的查询语句最后是否使用了索引,以及哪个索引。
最后,当一个字段被包含在多个组合索引的时候,更加要小心了,因为我们程序是不会指定使用哪个索引。