Python编程精粹:深入常用库与高效开发实践

1 引言:
在数字世界中,Python已然成为一种杰出的工具,它的优雅、简洁和强大功能吸引了无数的开发者和研究者。Python之所以在多个领域内占据主导地位,一个重要的原因在于其强大的多功能性。从数据分析到人工智能,从网络爬虫到科学计算,Python几乎无所不能。这背后的功臣是数不胜数的模块和包,它们像乐高积木一样,可以拼接组合,创造出无限的可能性。
在Python的编程实践中,模块扮演着至关重要的角色。一个模块可以被看作是一个包含所有你定义的函数和变量的文件,后缀名为.py。模块可以被别的程序引入,以使用该模块中的函数等功能。这种机制极大地促进了代码的重用性和程序的模块化。Python拥有一个庞大的标准库,它包含了许多内置模块,以支持不同的任务。例如,数学运算相关的任务,可以使用内置的math模块,它提供了一组标准的数学运算,比如:
cos ( θ ) = 1 2 ( e i θ + e − i θ ) \cos(\theta) = \frac{1}{2} \left(e^{i\theta} + e^{-i\theta}\right) cos(θ)=21(eiθ+e−iθ)
这是一个用于计算余弦的公式,其中 θ \theta θ是角度, e e e是自然对数的底数, i i i是虚数单位。在math模块中,我们可以直接通过调用math.cos()来计算一个角度的余弦值,而不需要关心背后的计算细节。
除了标准库之外,Python的第三方库生态同样繁荣。社区贡献的模块和包极大地扩展了Python的能力,让Python几乎能够触及每一个计算领域。例如,在数据科学领域,广受欢迎的pandas库为数据处理提供了强大而高效的工具,使得处理复杂数据变得简单。
模块化编程不仅仅是Python的一种编程范式,更是一种编程艺术。合理利用模块和包,可以使代码变得更加清晰、优雅,同时也方便了团队之间的协作和代码的维护。在本文中,我们将详细介绍Python中模块和包的使用,探讨如何通过这些强大的工具,提升我们的开发效率和程序的可读性。
让我们在接下来的章节中,一起探索Python编程的精粹,深入了解那些常用库的魔法,以及那些不为人知的高效开发实践。通过这篇文章,你将能够深刻理解模块的重要性,并且学会如何在你自己的编程实践中,运用这些模块来打造功能强大、易于维护的Python应用。

2 Python模块与包的基础
Python是一种极具表达力的编程语言,它的模块化特性使得代码易于组织和复用。在这部分,我们将详细解释模块和包的概念,展示如何创建和使用它们,并通过具体示例加深理解。
2.1 模块和包的定义与区别
在Python中,一个模块是一个包含Python定义和声明的文件,文件名就是模块名加上.py后缀。模块可以包含函数、类和变量,也可以包含可执行的代码。
一个包是一个含有模块的文件夹,它定义了一个Python应用程序的执行环境。包是一种管理Python模块命名空间的形式,通过使用“点模块名称”。例如,在模块名称 A.B 中,A 是一个包,B 是A包中的一个子模块。
简单来说,模块就是文件,包就是文件夹。但这个文件夹中包含一个特殊的文件__init__.py,该文件可以为空,它的存在就表明这个文件夹是一个Python包,不是一个普通文件夹。
2.2 创建自己的模块和包
创建一个模块非常简单,您只需要在一个文本编辑器中写下一些Python代码,然后保存为.py文件即可。例如,我们创建一个名为mymodule.py的文件,内容如下:
# mymodule.py
def say_hello(name):return f"Hello {name}!"
接着,我们可以创建一个包,首先需要创建一个文件夹,例如mypackage,然后在该文件夹内创建一个__init__.py文件。我们可以在__init__.py中导入包中的模块,使得包的使用更加简洁:
# mypackage/__init__.py
from .mymodule import say_hello
2.3 使用import语句加载模块
加载模块时,Python会在sys.path中列出的目录中查找模块。import语句允许我们在当前命名空间中获取模块。例如,要使用前面创建的mymodule模块,可以这样做:
import mymodulegreeting = mymodule.say_hello("Alice")
print(greeting) # 输出:Hello Alice!
与此同时,我们也可以使用from关键字进行选择性导入:
from mymodule import say_hellogreeting = say_hello("Bob")
print(greeting) # 输出:Hello Bob!
2.4 包的结构和__init__.py的作用
正如我们提到的,__init__.py的存在将一个文件夹转变为一个Python包。该文件可以用于执行包级别的初始化代码,例如设置全局变量或者导入包内必要的模块。
一个典型的包结构可能如下所示:
mypackage/
|-- __init__.py
|-- submodule1.py
|-- submodule2.py
`-- subpackage/|-- __init__.py|-- submodule3.py`-- submodule4.py
在这个结构中,mypackage是顶层包,submodule1.py和submodule2.py是它的子模块,而subpackage是一个子包,它自己也有__init__.py和属于它的子模块。
2.5 实例代码:组织和使用模块和包
让我们通过一个更具体的例子来理解如何组织模块和包。假设我们在开发一个网络应用程序,我们可能会有以下的包结构:
networkapp/
|-- __init__.py
|-- http.py
|-- utils.py
`-- tests/|-- __init__.py|-- test_http.py`-- test_utils.py
在这个结构中,http.py模块可能包含处理HTTP请求的函数和类,utils.py可能包含一些通用的工具函数。在tests包中,我们有针对以上模块的单元测试。
2.6 可视化:模块导入和包结构图
理解模块和包的结构对于高效编程至关重要。一个清晰的可视化结构图可以帮助我们理解包的组织。例如,我们可以使用图表软件绘制上述networkapp的结构,其中每个节点代表一个模块或包,箭头表示导入关系。
2.7 进一步阅读:模块搜索路径和命名空间
当Python尝试加载模块时,它会在sys.path指定的目录列表中查找。这个列表通常包含当前目录、Python安装的库目录和环境变量PYTHONPATH指定的目录。您可以通过打印sys.path来查看这个列表:
import sys
print(sys.path)
理解Python的命名空间可以帮助您避免名字冲突。模块的命名空间是一个从名字到对象的映射。不同的命名空间可以包含相同名字的不同对象,这允许模块独立地使用变量名,不会与其他模块的相同名字的变量冲突。
在本节中,我们已经探索了模块和包的基本概念,以及如何在Python中有效地使用它们。通过合理的模块化设计,您可以提高代码的可读性、可维护性和复用性,从而成为一个更高效的Python程序员。在下一节中,我们将深入探讨Python中处理时间和日期的模块——datetime。

3 时间和日期处理的艺术:datetime模块
在我们的日常编程中,对时间和日期的处理是绕不开的一环。不论是记录日志、处理时间序列数据还是简单地显示当前日期,时间和日期无处不在。在Python中,datetime模块提供了一系列强大的内置类型和方法,用于简化时间日期的处理。本节将带你深入了解这一模块的艺术。
3.1 datetime对象简介
datetime模块中的核心是datetime类,它封装了日期和时间的信息。创建datetime对象可以通过构造函数直接指定年、月、日、时、分、秒等信息。
3.2 常用datetime类方法和属性
datetime类提供了多种方法和属性,以下是一些最常用的:
today()/now():获取当前本地日期和时间。utcnow():获取当前的UTC时间。strftime(format):将datetime对象格式化为字符串。strptime(date_string, format):将格式化的字符串解析为datetime对象。
每个datetime对象都包含多个属性,如year、month、day、hour、minute、second和microsecond,允许我们轻松访问日期和时间的各个组成部分。
3.3 实例代码:构建和格式化日期时间
让我们通过实际的代码示例来看看如何使用datetime模块:
from datetime import datetime# 获取当前时间
now = datetime.now()
print(f"当前时间: {now}")# 构造一个特定的日期时间
new_year = datetime(2023, 1, 1, 0, 0)
print(f"新年时间: {new_year}")# 格式化日期时间
formatted_now = now.strftime("%Y-%m-%d %H:%M:%S")
print(f"格式化当前时间: {formatted_now}")# 解析字符串为日期时间
date_time_str = '2023-01-01 00:00:00'
date_time_obj = datetime.strptime(date_time_str, "%Y-%m-%d %H:%M:%S")
print(f"解析字符串为datetime对象: {date_time_obj}")
3.4 可视化:时间线和日历图表
考虑到时间的连续性,时间线是展示时间流逝的理想可视化工具。而日历图表则可以很好地展示日期和星期的对应关系。以下内容将展示如何用时间线和日历进行可视化。
在Python中,绘制时间线和日历图表通常涉及到使用绘图库,比如matplotlib。以下是一些简单的示例,展示如何使用matplotlib来进行这两种可视化。
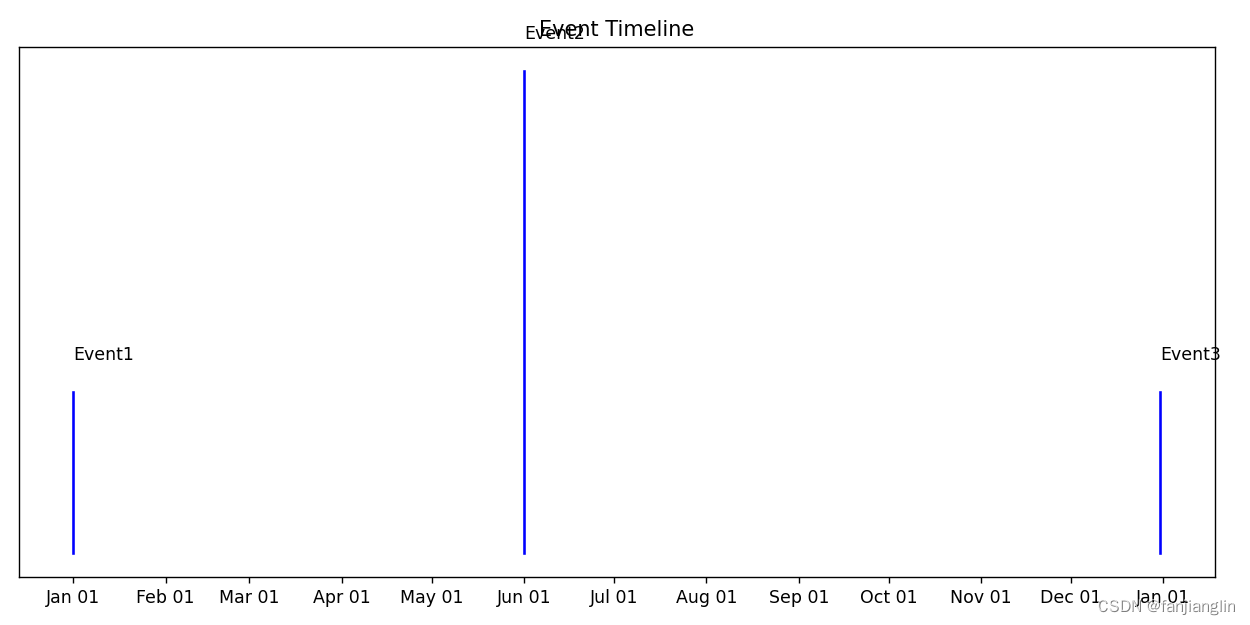
绘制时间线
绘制时间线通常意味着将一系列事件按照时间顺序展示在一条直线上。下面是一个简单的时间线示例:
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from datetime import datetime# 时间线上的事件和日期
events = ['Event1', 'Event2', 'Event3']
dates = [datetime(2023, 1, 1), datetime(2023, 6, 1), datetime(2023, 12, 31)]# 创建图和轴
fig, ax = plt.subplots(figsize=(10, 5))# 时间线和事件标签
for i, (date, event) in enumerate(zip(dates, events)):ax.plot([date, date], [0, i % 2 + 0.5], color='blue') # 时间线ax.text(date, i % 2 + 0.6, event) # 事件文本# 设置日期格式
ax.xaxis.set_major_locator(mdates.MonthLocator())
ax.xaxis.set_major_formatter(mdates.DateFormatter('%b %d'))# 美化图表
plt.title('Event Timeline')
plt.yticks([]) # 隐藏y轴标签
plt.subplots_adjust(bottom=0.2)
plt.tight_layout()# 展示图表
plt.show()
绘制日历图表
日历图表的绘制可能会稍微复杂一些。matplotlib并没有直接支持日历图表的功能,但我们可以通过一些创造性的方法来实现。以下是一个模拟日历图表的简单例子:
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import pandas as pd
from datetime import datetime, timedelta# 生成一个月的日期
start_date = datetime(2023, 1, 1)
end_date = datetime(2023, 1, 31)
dates_in_month = pd.date_range(start_date, end_date, freq='D')# 创建图和轴
fig, ax = plt.subplots(figsize=(12, 8))# 计算开始日期是星期几 (0=Monday, 6=Sunday)
start_day = start_date.weekday()# 生成日历格子
for i, date in enumerate(dates_in_month):ax.add_patch(plt.Rectangle(((i + start_day) % 7, (i + start_day) // 7), 1, 1, fill=False))# 设置日期标签
day_of_week_labels = ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun']
day_of_month_labels = [date.day for date in dates_in_month]for i, day in enumerate(day_of_week_labels):ax.text(i + 0.5, -0.5, day, ha='center', va='center')for i, day in enumerate(day_of_month_labels):ax.text((i + start_day) % 7 + 0.5, (i + start_day) // 7 + 0.5, str(day), ha='center', va='center')# 美化图表
ax.set_aspect('equal') # 设置宽高比
ax.set_xlim(0, 7) # 设置x轴的范围
ax.set_ylim(-1, (len(dates_in_month) + start_day) // 7 + 1) # 设置y轴的范围
plt.axis('off') # 隐藏坐标轴
plt.title('January 2023 Calendar')# 展示图表
plt.show()
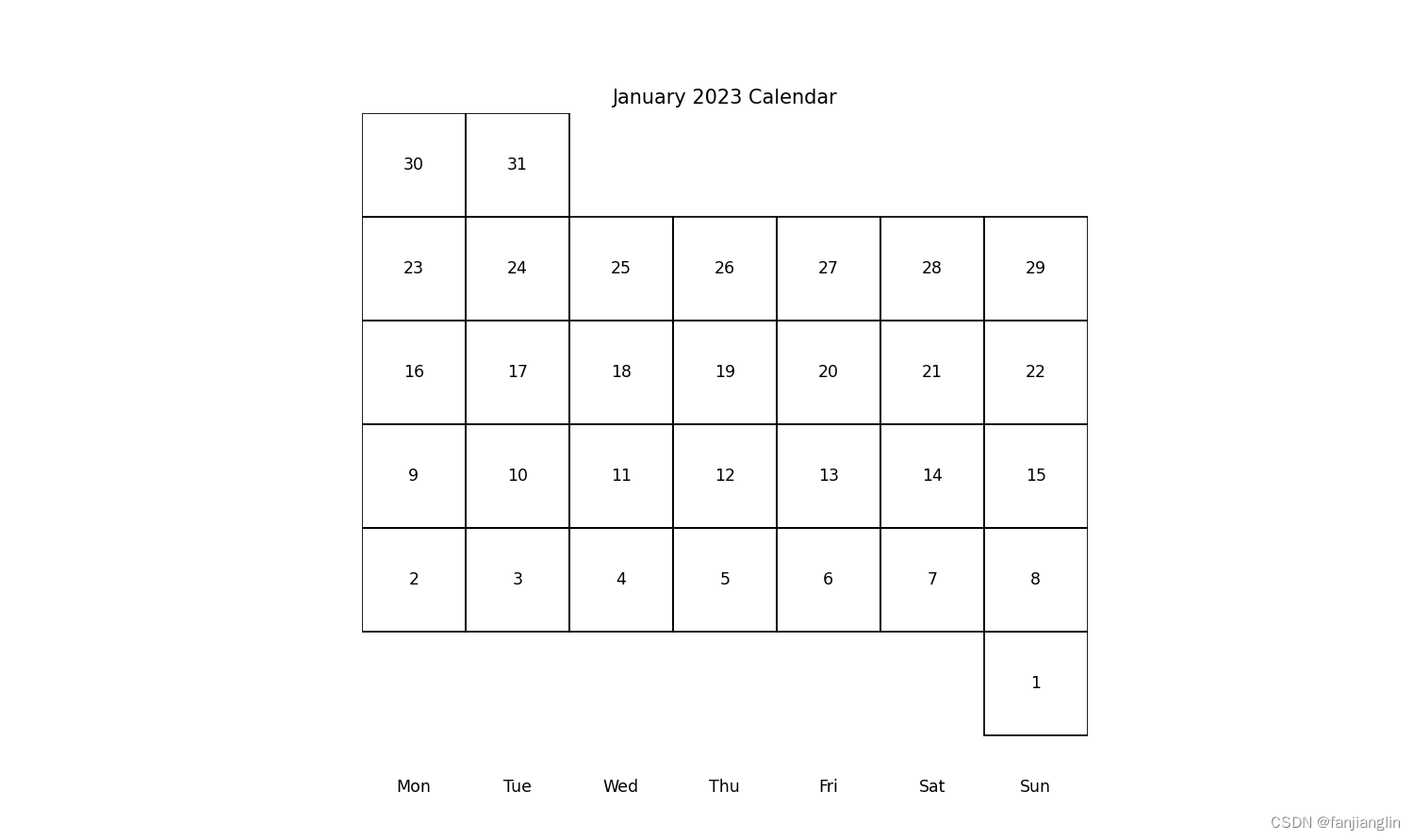
请注意,上述代码只是用来演示概念的,真实的日历图表可能需要考虑更多的边界情况(例如,月初不一定从星期天开始)。对于复杂的日历图表,可能需要更高级的绘图技巧或使用专门的库。
3.5 进一步阅读:时区处理和日期计算高级话题
时区处理在datetime模块中也得到了支持,通过pytz库可以更好地处理时区转换。日期计算,例如计算两个日期之间的时间差或者添加/减去一段时间,可以通过timedelta对象来实现。
对于时间和日期的计算来说,最简单的数学模型就是线性时间概念,它可以用如下公式表示:
T n e w = T o l d + Δ T T_{new} = T_{old} + \Delta T Tnew=Told+ΔT
其中, ( T n e w ) ( T_{new} ) (Tnew) 和 ( T o l d ) ( T_{old} ) (Told) 分别代表新旧时间,而 ( Δ T ) ( \Delta T ) (ΔT) 是一个timedelta对象,代表时间差。这个模型假设时间是线性流动的,没有考虑闰秒等复杂情况。不过,对于绝大多数应用场景来说,这样的简化是足够的。
在处理时间和日期时,我们不仅要考虑其数学模型,还需要考虑其在计算机系统中的表示。一个常见的表示是Unix时间戳,它定义为自1970年1月1日00:00:00 UTC以来经过的秒数。它可以用以下公式表示:
U n i x 时间戳 = ( 日期 − U n i x 纪元 ) / 时间单位 Unix时间戳 = (日期 - Unix纪元) / 时间单位 Unix时间戳=(日期−Unix纪元)/时间单位
其中,Unix纪元是1970年1月1日00:00:00 UTC,时间单位通常是秒。
通过datetime模块中的timestamp()方法,我们可以轻松地将一个datetime对象转换为其对应的Unix时间戳:
# Unix时间戳
timestamp = now.timestamp()
print(f"当前时间的Unix时间戳: {timestamp}")
掌握了datetime模块,你就能够在Python中灵活处理各种时间和日期相关的任务了。学会了这门艺术,你将在编程中获得极大的便利和效率。
在接下来的章节中,我们将继续探索Python中的其他核心模块,提高你的编程能力和效率。

4 文件操作精髓:读取、写入与管理
在编程世界中,文件是数据永久存储的根基。而在Python中,处理文件是一个简单却极其强大的过程。本节将深入探讨如何通过Python以高效且安全的方式执行文件操作。
4.1 文件对象和模式
每当我们在Python中打开一个文件时,我们实际上是在创建一个文件对象。这个对象为我们提供了执行各种操作的方法,如读取、写入以及关闭文件。这些文件对象可以在不同的模式下打开,如:
- ‘r’:只读模式,默认模式。如果文件不存在,会抛出一个错误。
- ‘w’:写入模式。会覆盖已存在的文件,如果文件不存在则创建新文件。
- ‘a’:追加模式。文件指针会放在文件的结尾,如果文件不存在则创建新文件。
- ‘b’:以二进制模式打开文件,用于非文本文件。
这些模式可以组合使用,例如 ‘rb’ 或 ‘w+’(读写模式,覆盖已存在的文件,如果文件不存在则创建新文件)。
打开文件后,一个常见的操作是文件读取。考虑以下公式,它表示我们如何计算文件中字符的平均数量:
平均字符数 = 总字符数 行数 \text{平均字符数} = \frac{\text{总字符数}}{\text{行数}} 平均字符数=行数总字符数
这个简单的公式可以帮助我们理解文件大小和内容的关系。
4.2 实例代码:创建、读取、写入和关闭文件
让我们以一个具体的例子来展示如何在Python中创建和操作文件。以下是打开一个文件、读取内容并写入新内容的步骤:
# 创建和写入文件
with open('example.txt', 'w') as file:file.write("This is the first line.\n")file.write("This is the second line.\n")# 读取文件
with open('example.txt', 'r') as file:content = file.readlines()# 处理内容
content = [line.strip() for line in content]
average_length = sum(len(line) for line in content) / len(content)# 追加内容
with open('example.txt', 'a') as file:file.write(f"\nAverage line length: {average_length}")# 读取并打印文件内容
with open('example.txt', 'r') as file:print(file.read())
注意我们在这里使用了with语句,它是一个上下文管理器,它能够自动管理资源。在本例中,它会在代码块执行完毕后自动关闭文件,这是一种安全的文件操作方式。
4.3 可视化:文件系统结构图
在理解文件操作的时候,可视化文件系统的结构是有帮助的。考虑一个文件系统,其中包含多个文件夹和文件,它们可以用树状图来表示。每个节点代表一个文件夹或文件,这有助于我们理解路径和目录结构。
4.4 进一步阅读:上下文管理器和安全的文件操作
在进行文件操作时,尤其是在复杂的应用程序中,确保文件在正确的时间被关闭是很重要的,这样可以避免数据丢失和文件损坏。Python的上下文管理器提供了一种在完成工作后自动清理资源(如文件)的简单方法。学习上下文管理器和with语句的更深层次用法将是你Python文件操作技能的重要组成部分。
随着你对文件操作的细节和可能性的探索,你将发现Python为这些常见任务提供的强大而优雅的解决方案。是否需要安全地读取大型文件?或者是以原子方式写入数据?这些都是Python可以处理的高级文件操作话题。通过实践和探索,你将能够精通Python中的文件操作,成为真正的文件处理专家。

5 系统编程基础:os和sys模块
在Python的世界里,系统编程是一项至关重要的技能,它允许我们与操作系统进行交互,执行文件操作、处理进程和环境变量等。在本节中,我们将深入探讨os和sys两个强大的内置模块,了解它们在系统级编程中的应用。
5.1 系统路径和目录操作
在os模块中,路径操作是其核心功能之一。它提供了许多与文件系统交互的函数。例如,os.path.join用于跨平台地拼接路径,它会根据你的操作系统选择合适的路径分隔符:
import os
path = os.path.join('user', 'documents', 'example.txt') # 'user\\documents\\example.txt' on Windows
而os.mkdir和os.makedirs则用于创建新目录。假设我们想创建一个新的项目目录结构:
os.makedirs('my_project/src')
此命令将在my_project下创建一个src文件夹,如果my_project不存在,也会被创建。如果我们仅想基于当前存在的目录创建一个新目录,使用os.mkdir会更合适。
在处理路径时,数学公式并不常用,但对于文件的大小和目录的层次结构等可以进行计量和表达,如目录树的深度可以通过计算路径分隔符的数量来近似:
d e p t h = l e n ( p a t h . s p l i t ( o s . s e p ) ) − 1 depth = len(path.split(os.sep)) - 1 depth=len(path.split(os.sep))−1
其中,os.sep是操作系统特定的路径分隔符,如在UNIX中为'/',而在Windows中为'\\'。
5.2 进程环境和参数传递
系统编程的另一个重要方面是与进程环境的交互。os模块允许我们访问环境变量,如通过os.environ获取一个包含所有环境变量的字典。例如,我们可以这样获取PATH环境变量:
import os
path_env = os.environ.get('PATH')
sys模块的argv属性则用于处理命令行参数。当Python脚本被执行时,sys.argv是一个列表,它包含了命令行中传递给脚本的所有参数。以一个简单的脚本为例:
import sysif len(sys.argv) > 1:filename = sys.argv[1]with open(filename, 'r') as f:content = f.read()print(content)
else:print("No filename provided.")
这个脚本检查是否提供了一个参数(除了脚本名称本身),如果提供了,它就尝试打开并打印文件的内容。在这里,sys.argv[0]是脚本名称,sys.argv[1]是传递给脚本的第一个参数。
5.3 实例代码:使用os和sys模块进行系统管理任务
让我们通过一个更实际的例子来演示os和sys模块的使用。假设我们想编写一个脚本,用于备份我们的文档目录到另一个位置:
import os
import sys
import shutildef backup_docs(source_dir, backup_dir):if not os.path.exists(backup_dir):os.makedirs(backup_dir)for filename in os.listdir(source_dir):full_file_name = os.path.join(source_dir, filename)if os.path.isfile(full_file_name):shutil.copy(full_file_name, backup_dir)if __name__ == "__main__":if len(sys.argv) == 3:source = sys.argv[1]backup = sys.argv[2]backup_docs(source, backup)print(f"Backup of {source} completed to {backup}")else:print("Usage: python backup_script.py <source_dir> <backup_dir>")
在上面的脚本中,我们首先检查备份目录是否存在,如果不存在则创建它。然后我们遍历文档目录中的所有文件,并使用shutil.copy将它们复制到备份目录。
5.4 可视化:系统调用流程图
在系统编程中,理解各种系统调用如何工作及其相互关系非常重要。一个系统调用流程图可以帮助我们可视化这一点。例如,使用os模块进行文件操作时,流程可能如下所示:
Python script -> os module function -> System call -> File system
通过流程图,我们可以直观地看到从Python代码到操作系统服务的调用链路。
5.5 进一步阅读:环境变量和系统配置
深入了解系统编程,我们还可以探讨更高级的话题,如如何利用环境变量来配置应用程序的行为,或者如何使用Python脚本来自动化系统配置任务。为此,可以深入阅读os.environ的使用方法,或者研究操作系统提供的脚本工具和服务。
在本节中,我们对Python的os和sys模块进行了一个简洁而深入的探讨,希望这能帮助你在进行系统编程时更加得心应手。无论是管理文件和目录,处理环境变量,还是接收命令行参数,这些工具都是每个Python开发者工具箱中不可或缺的一部分。

6 数学运算和随机数:math与random模块
在Python的世界里,数学运算是基础中的基础,而随机性则是许多算法不可或缺的香料。无论是在科学计算中对某个复杂函数求值,还是在游戏设计中生成随意的事件,math和random模块总是扮演着重要的角色。
6.1 常见数学函数和常量
首先,让我们来看一看math模块中的一些基础。这个模块提供了许多对浮点数进行数学运算的函数。比如,我们有math.sqrt(x)来计算 x \sqrt{x} x,以及math.sin(x)、math.cos(x)和math.tan(x)来计算角度x(以弧度为单位)的正弦、余弦和正切值。
举个例子,假设我们想计算直角三角形的斜边长度,其中两个直角边的长度分别为3和4。我们可以使用勾股定理 c = a 2 + b 2 c = \sqrt{a^2 + b^2} c=a2+b2来计算斜边长:
import matha = 3
b = 4
c = math.sqrt(math.pow(a, 2) + math.pow(b, 2))
print("斜边的长度是:", c)
输出将会是5,因为 3 2 + 4 2 = 9 + 16 = 25 = 5 \sqrt{3^2 + 4^2} = \sqrt{9 + 16} = \sqrt{25} = 5 32+42=9+16=25=5。
此外,math模块还提供了许多常用的数学常量,如圆周率math.pi和自然对数的底math.e。这些常量可以用于更多复杂的数学表达式中。
6.2 随机数生成技巧
转向随机性,random模块允许我们在程序中引入不可预测的元素。它可以生成随机数、随机挑选元素,甚至对序列进行随机排序。例如,random.randint(a, b)会生成一个介于a和b之间(包括a和b)的随机整数,而random.random()则会生成一个在0和1之间的随机浮点数。
如果我们想在一个列表中随机挑选一个元素,可以使用random.choice()。让我们来看一下如何实现:
import randomitems = ['苹果', '香蕉', '樱桃', '枣']
picked_item = random.choice(items)
print("随机挑选的水果是:", picked_item)
每次运行这个程序,输出都可能会有所不同,因为picked_item是随机选择的。
6.3 实例代码:数学问题求解和数据随机化
让我们更实际地看一个结合使用math和random模块来解决问题的例子。假设我们想模拟一个简单的抛硬币实验,我们希望计算正面朝上的概率。我们可以使用random模块来模拟抛硬币,然后使用math模块来计算概率:
import random
import mathdef simulate_coin_tosses(tosses):heads_count = 0for _ in range(tosses):if random.random() > 0.5: # 假定大于0.5表示正面heads_count += 1return heads_counttosses = 10000
heads = simulate_coin_tosses(tosses)
probability_of_heads = heads / tosses
print("正面朝上的概率约为:", probability_of_heads)
在这个模拟中,我们期望probability_of_heads接近0.5,因为硬币的两面是等可能的。
6.4 可视化:函数图像和概率分布图
为了更好地理解math模块中的函数,我们经常需要将它们可视化。Python中的matplotlib库可以帮助我们绘制函数图像。例如,如果我们想绘制正弦函数的图像,我们可以这样做:
import matplotlib.pyplot as plt
import mathx_values = [x * 0.1 for x in range(-70, 70)]
y_values = [math.sin(x) for x in x_values]plt.plot(x_values, y_values)
plt.title('正弦函数')
plt.xlabel('弧度')
plt.ylabel('正弦值')
plt.grid(True)
plt.show()
这段代码将会产生一个美观的正弦波函数图。
在使用random模块时,了解随机变量的概率分布也是很有帮助的。比如,我们可以绘制前面抛硬币实验结果的直方图,来观察实际结果与理论分布的接近程度。
6.5 进一步阅读:随机数生成算法和应用
要深入了解随机数的生成,我们可以探究random模块背后的随机数生成算法,如线性同余生成器或梅森旋转算法(Mersenne Twister)。这些算法如何保证数字的随机性,以及它们在不同应用中表现如何,是一个非常丰富的研究领域。
同时,数学函数的应用远不止我们讨论的这些用例。在数据科学、机器学习、工程设计等领域,math模块提供的函数都有着广泛的用途,了解它们的数学背景和计算复杂性对于专业人士来说至关重要。
通过本文,我们简要介绍了如何在Python中利用math和random模块进行数学运算和随机数的生成。这些模块的理解和熟练应用,对于任何希望提升编程效率和解决实际问题的Python程序员来说,都是宝贵的技能。正如我们所展示的,结合实例代码和可视化手段,可以使这些概念更加易于理解和应用。希望读者能够在实践中进一步探索和精炼这些工具,解锁Python编程的更多可能性。

7 文本处理高手:re模块
在编程的世界里,文本处理是一项基本而强大的技能。Python通过其内置的re模块,提供了一个完整的正则表达式(Regular Expression)引擎,使得复杂的字符串处理变得触手可及。在本节中,我们将探讨正则表达式的强大之处,学习如何使用re模块来执行高效的文本处理。
7.1 正则表达式语法要点
正则表达式是用于描述字符序列模式的一种语法。它们被广泛用于字符串的搜索、替换、检验等操作中。在Python的re模块中,正则表达式的使用涉及到以下几个关键概念:
- 字面量(Literals):最简单的匹配,直接匹配字符序列,例如
'python'。 - 字符类(Character Classes):匹配一组字符中的任何一个,例如
'[a-zA-Z]'匹配任何一个字母。 - 预定义字符集:如
\d匹配任何数字,\w匹配任何字母数字字符,\s匹配任何空白字符。 - 量词(Quantifiers):指定前面的字符或组合出现的频次,如
*表示0次或多次,+表示1次或多次,{n,m}表示至少n次,最多m次。 - 锚点(Anchors):匹配字符串的开始
^和结束$位置。 - 分组(Grouping)与引用(Backreferences):通过
()进行分组,可以通过\1等引用前面的分组。 - 非贪婪模式:通过
?使量词变为非贪婪模式,匹配尽可能少的字符。
举个例子,假设我们想匹配一个标准的电子邮件地址,其正则表达式可以写为:'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$'。其中,^和$是锚点,确保整个字符串匹配;[a-zA-Z0-9_.+-]+匹配邮箱用户名,[a-zA-Z0-9-]+匹配邮件服务商名称,\.匹配点字符,[a-zA-Z0-9-.]+ 匹配域名后缀。
7.2 实例代码:字符串搜索、替换和分割
通过re模块,可以实现复杂的文本处理操作。以下是一些常见操作的示例代码:
- 搜索(Search):
match = re.search(pattern, string),如果字符串中存在模式pattern,则返回一个匹配对象,否则返回None。 - 匹配(Match):
match = re.match(pattern, string),如果字符串开头的字符满足模式pattern,则返回一个匹配对象。 - 分割(Split):
split_list = re.split(pattern, string),使用模式pattern作为分隔符,将字符串分割成一个列表。 - 替换(Substitute):
new_string = re.sub(pattern, repl, string),将字符串中所有的模式pattern实例替换成repl。 - 查找所有(Findall):
matches = re.findall(pattern, string),返回字符串中所有满足模式pattern的子串列表。
例如,对于将文本中的日期格式从"dd-mm-yyyy"转换为"yyyy-mm-dd",可以使用sub函数和分组:
text = "Today's date is 15-04-2023."
pattern = r'(\d{2})-(\d{2})-(\d{4})'
replaced_text = re.sub(pattern, r'\3-\2-\1', text)
print(replaced_text) # "Today's date is 2023-04-15."
在这个例子中,(\d{2})-(\d{2})-(\d{4})是用来匹配日期格式的正则表达式,其中\d{2}匹配两位数字,\d{4}匹配四位数字,括号用于分组,而在替换字符串r'\3-\2-\1'中,\3、\2、\1分别引用了第三、第二、第一个分组。
7.3 可视化:正则表达式匹配模式图
理解正则表达式的一个挑战是如何将这些抽象的符号映射到实际的匹配过程中。通过可视化工具,比如正则表达式匹配模式图,我们可以更直观地理解这些模式是如何工作的。这些图通常将正则表达式中的每个符号转换为状态机中的状态和转移。
例如,正则表达式'^a(b|c)*d$'的匹配模式图将展示从字符串的起始状态,经过匹配字母a,然后是一个循环状态,匹配b或c零次或多次,最后匹配字母d并在字符串末端结束。
7.4 进一步阅读:复杂模式和优化技巧
当你掌握了基础后,可以进一步研究如何编写更复杂的正则表达式及其优化。复杂的正则表达式可能包含多个分组,嵌套结构,查找断言(look-ahead and look-behind assertions)等。同时,优化正则表达式的执行速度和效率是一个高级话题,包括避免回溯(backtracking)、使用非捕获组(non-capturing groups)等技术。
在编写正则表达式时,为了确保模式的效率,你可以使用正则表达式的编译功能:
pattern = re.compile(r'\d{2}-\d{2}-\d{4}')
这样,当你需要多次使用同一个模式时,可以提高匹配的执行速度。而\d{2}-\d{2}-\d{4}这个模式本身,就是一个使用量词和字符类的简单日期匹配例子。
7.5 小结
掌握re模块和正则表达式是成为Python文本处理高手的关键一步。通过本节的学习,你应该能够编写有效的正则表达式来解决实际的文本处理问题,并对如何进一步提高你的技能有所了解。
那么,不妨将这些知识应用到你的下一个Python项目中,解锁文本处理的无限可能!

8 数据交换格式处理:json与xml模块
在现代编程实践中,数据交换格式的标准化对于系统间的通信至关重要。JSON(JavaScript Object Notation)和XML(eXtensible Markup Language)是最常见的两种数据序列化格式。它们的普及源于其易读性、跨语言兼容性和网络传输的高效率。
8.1 json和xml概念和结构
JSON是一种轻量级的数据交换格式,其数据结构是一个键值对集合,可以非常直观地表示为一个嵌套的字典和列表。一个基本的JSON对象可能看起来像这样:
{"name": "John","age": 30,"cars": ["Ford", "BMW", "Fiat"]
}
而XML是一种标记语言,它定义了一组规则来编码文档,使其既可被机器读取也能被人读取。XML文档是标签的集合,每个标签可以有属性,并且可以包含其他标签或文本内容。下面是一个简单的XML例子:
<person><name>John</name><age>30</age><cars><car>Ford</car><car>BMW</car><car>Fiat</car></cars>
</person>
8.2 实例代码:解析和生成json/xml数据
现在让我们通过Python的json和xml模块来查看如何处理这些格式的数据。
8.2.1 JSON的处理
对于JSON数据,Python提供了json模块,该模块提供了一些函数,例如json.load()和json.loads()用于解析JSON数据,以及json.dump()和json.dumps()用于生成JSON数据。
import json# 解析JSON字符串
json_str = '{"name": "John", "age": 30, "cars": ["Ford", "BMW", "Fiat"]}'
person = json.loads(json_str)
print(person['name']) # 输出: John# 生成JSON字符串
new_person = {"name": "Alice", "age": 25, "cars": ["VW"]}
json_str = json.dumps(new_person)
print(json_str) # 输出: {"name": "Alice", "age": 25, "cars": ["VW"]}
8.2.2 XML的处理
Python的xml.etree.ElementTree模块则允许我们方便地解析和创建XML数据。以下是使用该模块进行基本操作的示例:
import xml.etree.ElementTree as ET# 解析XML字符串
xml_str = '''
<person><name>John</name><age>30</age><cars><car>Ford</car><car>BMW</car><car>Fiat</car></cars>
</person>
'''
tree = ET.ElementTree(ET.fromstring(xml_str))
root = tree.getroot()
print(root.find('name').text) # 输出: John# 创建XML数据
new_person = ET.Element("person")
name = ET.SubElement(new_person, "name")
name.text = "Alice"
ET.dump(new_person) # 打印出<new_person><name>Alice</name></new_person>
8.3 可视化:数据格式化结构图
为了更好地理解JSON和XML的结构,我们可以将它们想象成一个树状图,其中每个节点代表一个对象(在JSON中)或一个元素(在XML中)。JSON的树状结构图可能会是这样的:
root├── name: "John"├── age: 30└── cars├── [0]: "Ford"├── [1]: "BMW"└── [2]: "Fiat"
而XML的树状结构则可能如下:
root└── person├── name: "John"├── age: 30└── cars├── car: "Ford"├── car: "BMW"└── car: "Fiat"
8.4 进一步阅读:处理大型数据文件和性能优化
在处理大型JSON或XML文件时,性能成为一个关键考量点。此时,我们不能简单地将整个文件加载到内存中进行解析。JSON可以采用ijson这类库来进行增量解析,它允许我们一边读取一边解析大型JSON文件。类似地,对于XML,可以使用xml.etree.ElementTree的iterparse方法进行增量解析。
优化数据处理性能还涉及到一些数学上的考量,如时间复杂度和空间复杂度。对于JSON的解析,其时间复杂度通常是 O ( n ) O(n) O(n),其中 n n n 是文本长度。而对于XML,由于需要处理标签关系,复杂度可能会更高,尤其是在有嵌套关系的情况下。因此,理解和优化算法的性能是处理大型数据文件时的一个重要话题。
通过本节的内容,我们已经掌握了在Python中处理数据交换格式的初步知识和技能。探究更高效的数据处理方式和深入理解这些格式的内部结构将是任何希望提升数据处理能力的程序员的必经之路。

9 网络请求与数据抓取:urllib模块
在当今互联网时代,网络资源的获取与数据的交互成为了编程中不可或缺的一部分。Python提供了强大的库来处理网络请求,其中urllib模块是最基础也是最常用的HTTP客户端模块之一。在这一部分,我们将深入探讨如何使用urllib模块发送HTTP请求、处理响应,以及如何通过编程实现网页内容的下载和API的交互。
9.1 发送HTTP请求和处理响应
HTTP(HyperText Transfer Protocol)是互联网上应用最为广泛的协议之一,用于传输超文本数据。urllib模块提供了一系列用于操作HTTP请求和响应的功能。其中,urllib.request子模块可以帮助我们创建请求并发送到服务器,接收并读取服务器的响应内容。
发送一个简单的GET请求,可以使用urlopen方法:
from urllib.request import urlopenurl = 'http://example.com'
response = urlopen(url)
html = response.read()
上面的代码片段发出了一个基本的GET请求到example.com,并获得了响应对象。通过调用响应对象的.read()方法,我们可以读取到网页的HTML内容。
如果需要发送POST请求,可以使用urllib.parse子模块来编码参数,并通过urlopen方法的data参数传递:
from urllib.request import urlopen
from urllib.parse import urlencodedata = {'key1': 'value1', 'key2': 'value2'}
encoded_data = urlencode(data).encode('utf-8')
url = 'http://example.com/post'
response = urlopen(url, data=encoded_data)
result = response.read()
在上述代码中,我们首先通过urlencode方法将字典格式的参数编码成适合在HTTP请求中使用的格式,然后通过encode方法将其转换为字节码,这是urlopen方法发送POST请求时所需要的格式。
9.2 实例代码:网页内容下载和API交互
现在让我们来看一个实例,假设我们要下载一个网页,并对其内容进行处理。以获取GitHub API中的公共仓库信息为例:
import json
from urllib.request import Request, urlopenapi_url = 'https://api.github.com/repositories'# 构建请求对象
request = Request(api_url)
# 发送请求,并获取响应对象
response = urlopen(request)
# 读取响应内容
data = response.read()# 将响应内容转换为JSON
repositories = json.loads(data.decode('utf-8'))# 输出获取的数据
for repo in repositories:print(repo['name'])
在这个例子中,我们请求GitHub的公共仓库API,并将响应内容解析为JSON格式。这个过程中,Request类被用来构造请求,它允许我们在发送请求前设置headers等信息,以便满足一些API接口的要求。
9.3 可视化:HTTP请求流程图
现在,让我们用数学的形式来描述一个HTTP请求的生命周期。从客户端发送请求到服务器响应请求,这个过程可以用以下的状态转换图(State Transition Diagram)表示:
Client → open connection Server → request line, headers Server → body (optional) Server → response line Client → response headers Client → response body Client \text{Client} \xrightarrow{\text{open connection}} \text{Server} \xrightarrow{\text{request line, headers}} \text{Server} \xrightarrow{\text{body (optional)}} \text{Server} \xrightarrow{\text{response line}} \text{Client} \xrightarrow{\text{response headers}} \text{Client} \xrightarrow{\text{response body}} \text{Client} Clientopen connectionServerrequest line, headersServerbody (optional)Serverresponse lineClientresponse headersClientresponse bodyClient
这个图表体现了一个HTTP请求从开始到结束所经历的状态变化。客户端首先与服务器建立连接,然后发送包含请求行、请求头以及可选的请求体的HTTP请求。服务器处理这个请求后,会返回响应行、响应头和响应体。这个过程就构成了一次完整的HTTP交互周期。
9.4 进一步阅读:网络爬虫和网页解析
urllib模块虽然功能强大,但在实践中,我们通常会遇到更为复杂的情形。例如,某些网站可能需要登录后才能访问特定内容,或者网页中的数据是通过JavaScript动态加载的。在这些情况下,我们可能需要使用到urllib模块的高级功能,或者结合其他模块如http.cookiejar来处理cookies,甚至是使用第三方库如requests和BeautifulSoup,lxml等来简化任务。
网络爬虫的开发通常需要对HTTP协议有着深刻的理解,并且对目标网站的结构和行为有充分的分析。这涉及到许多技术点,如请求头的设置、登录认证、数据提取、动态内容加载、反爬虫策略的应对等。
总之,urllib模块是Python网络编程的基石之一,它的学习和理解是进一步掌握网络应用开发的关键步骤。通过本章节的学习,希望读者能够对urllib模块有更加深入的认识,并在实际项目中灵活运用。

10 进程与线程管理:subprocess与threading模块
在现代操作系统中,多任务并发执行是一项基本功能,Python提供了多种机制来实现这一任务,包括进程和线程。虽然Python的全局解释器锁(GIL)限制了线程的并行执行,但通过合理设计,我们仍然可以在多核CPU上实现有效的并发。
10.1 启动和管理外部进程
subprocess模块允许我们从Python程序中启动和管理外部进程。这个功能非常强大,因为它使我们能够运行那些不是用Python编写的程序,并能与之交互。
例如,假设我们需要从Python脚本中运行一个外部命令ls -l,来列出当前目录下的文件和目录。这可以通过以下代码实现:
import subprocessresult = subprocess.run(['ls', '-l'], stdout=subprocess.PIPE, text=True)
print(result.stdout)
这个例子中,我们使用subprocess.run()函数,传入命令的参数作为列表。stdout=subprocess.PIPE的设置是为了捕获命令的输出。text=True参数表明输出以文本形式返回。
当我们需要更复杂的进程管理,比如不仅要启动进程还要与之通信,则可以使用subprocess.Popen类。以下是一个使用Python脚本来启动一个Python交互式解释器,并执行一些简单命令的示例:
import subprocess# 启动一个子进程并获取输入/输出/错误管道
proc = subprocess.Popen(['python'], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE,text=True)
# 向Python解释器传递一个简单的打印命令
out, err = proc.communicate('print("Hello from subprocess")\n')
print(out) # 输出: Hello from subprocess
在这个示例中,我们通过Popen对象的communicate方法向Python解释器发送了一行代码,并打印了其输出结果。
10.2 线程创建、同步与通信
Python的threading模块允许我们在单独的线程中运行任务,这有助于执行I/O密集型或可以并行化的任务。当我们需要保持主程序的响应性,同时执行一些后台任务时,线程就显得尤为重要。
下面是一个创建新线程并与主线程同步的例子:
import threading# 定义一个线程执行的函数
def worker():"""线程工作函数"""print('Worker thread is running')# 创建一个线程实例
t = threading.Thread(target=worker)# 启动线程
t.start()# 等待线程结束
t.join()print('Main thread continues after worker thread')
在这个例子中,worker函数是每个线程执行的任务。我们通过threading.Thread类创建了一个线程实例,并将worker函数传递给它作为目标函数。调用该线程的start()方法会在一个单独的控制流中启动该函数的执行。join()方法是用来告诉主线程等待子线程结束。
对于线程间的数据共享和同步,可以使用threading模块提供的锁(Locks)、事件(Events)、条件(Conditions)和信号量(Semaphores)。例如,如果两个线程需要交替打印数字和字母,我们可以使用threading.Condition来同步它们的动作:
import threading# 创建条件变量
cond = threading.Condition()
turn = 'number'def print_number():global turnfor i in range(1, 11):with cond:while turn != 'number':cond.wait()print(i)turn = 'letter'cond.notify()def print_letter():global turnfor i in range(65, 75):with cond:while turn != 'letter':cond.wait()print(chr(i))turn = 'number'cond.notify()t1 = threading.Thread(target=print_number)
t2 = threading.Thread(target=print_letter)t1.start()
t2.start()t1.join()
t2.join()
在这个例子中,我们定义了两个函数print_number和print_letter,分别在两个线程中运行。它们通过全局变量turn和一个条件变量cond来协调打印顺序。with cond语句块保证了在此区块内部的代码会在获得锁的情况下执行,从而保证了线程间对全局变量的互斥访问。
10.3 可视化:进程和线程生命周期图
为了更好地理解进程和线程的管理,我们可以将其生命周期进行可视化。这通常涉及到以下几个阶段:
- 创建:一个新的进程或线程被初始化。
- 就绪:进程或线程准备好执行,并等待CPU的分配。
- 执行:进程或线程获得CPU时间,并开始执行任务。
- 等待:进程或线程进入等待状态,可能是因为I/O操作或其他资源不可用。
- 终止:进程或线程完成其任务并停止执行。
将这些阶段绘制成图表,可以帮助我们理解并发执行的复杂性以及必要的同步和通信操作。
10.4 进一步阅读:多核处理和进程间通信
为了深入学习进程与线程管理,我们需要了解更多有关多核处理和进程间通信(IPC)的知识。利用多核处理可以显著提高程序的执行效率,尤其是在对于计算密集型任务时。而进程间通信则允许不同的进程共享数据和状态信息,常见的IPC机制包括管道、消息队列、共享内存和套接字等。
让我们以探究和实践的精神,继续深化对Python并发编程的理解,从而编写出更高效、响应更快的应用程序。在下一章节,我们会探讨迭代器与生成器,它们是Python高效处理数据的又一利器。

11 迭代器与生成器:itertools模块
在深入Python的迭代器与生成器之前,让我们先了解这两者的基本概念。迭代器(Iterator)是一个可以记住遍历的位置的对象,它只能往前不会后退。生成器(Generator)是一种特殊类型的迭代器,它可以动态地在循环过程中创建值,而不是一次性地创建并保存全部值。
11.1 迭代器的数学本质
迭代器可以被看作是一个映射: f : N → X f: \mathbb{N} \to X f:N→X,其中 N \mathbb{N} N是自然数集合, X X X是数据集合,迭代器 f f f按顺序为每个自然数 n n n(通常作为索引)提供一个值 x n ∈ X x_n \in X xn∈X。我们可以说,迭代器定义了一个序列 { x 0 , x 1 , x 2 , . . . } \{x_0, x_1, x_2, ...\} {x0,x1,x2,...}。
11.2 生成器的数学表示
生成器通常通过函数体中包含yield语句来定义,它定义了一个序列的生成规则。在数学上,生成器可以用递归序列来描述,例如斐波那契数列: F ( n ) = F ( n − 1 ) + F ( n − 2 ) F(n) = F(n-1) + F(n-2) F(n)=F(n−1)+F(n−2),对于 F ( 0 ) = 0 F(0) = 0 F(0)=0和 F ( 1 ) = 1 F(1) = 1 F(1)=1。
11.3 itertools中的工具函数
itertools模块是Python标准库中的一部分,提供了一系列用于构建迭代器的函数。这些函数分为三大类:
- 无限迭代器:如
count,cycle,repeat。 - 有限迭代器:如
accumulate,chain,zip_longest,islice。 - 组合生成器:如
product,permutations,combinations。
我们将通过具体例子来探索一些itertools模块中的函数。
11.4 实例代码:构建高效的迭代模式
让我们使用itertools来实现一些迭代任务:
1. 累积求和:
使用accumulate来实现累积求和,它接受一个可迭代对象并返回一个迭代器,每一步产生中间累积结果:
from itertools import accumulate# 累积求和
numbers = [1, 2, 3, 4, 5]
summed = accumulate(numbers)
for total in summed:print(total)
输出将是序列的累积和:1, 3, 6, 10, 15。
2. 笛卡尔积:
product函数用于计算多个可迭代对象的笛卡尔积,返回元组组成的迭代器:
from itertools import product# 计算两个集合的笛卡尔积
set1 = [1, 2, 3]
set2 = ['a', 'b']
for p in product(set1, set2):print(p)
输出将是所有可能的有序对组合:(1, ‘a’), (1, ‘b’), (2, ‘a’), (2, ‘b’), (3, ‘a’), (3, ‘b’)。
11.5 可视化:迭代过程示意图
为了直观展示迭代过程,我们可以画出生成器函数的状态转换图。例如,一个无限计数器count()函数会有一个状态,它不断地递增计数并返回。我们可以将这个过程表示为一个从状态S0到S1, S2, …, Sn的箭头序列,每个箭头对应一个输出值。
11.6 进一步阅读:创建自定义迭代器和生成器
深入学习迭代器和生成器,你可以探索如何创建自定义迭代器类,实现__iter__()和__next__()方法,或者使用生成器表达式来创建简洁而强大的生成器。此外,还可以研究生成器的底层实现机制,例如如何利用生成器来实现协程。
迭代器和生成器是Python高效编程的关键。通过itertools模块,我们可以构建出复杂而高效的迭代模式,这些模式可以用于数据处理、数学计算以及算法实现等各个领域。掌握了这些迭代工具,你就能以更加Pythonic的方式编写出简洁、高效且易于理解的代码。

12 数据结构精粹:collections模块
Python的collections模块包括了多种扩展的数据结构,我们将挑选一些最常用的进行讲解:deque、namedtuple、Counter等。
12.1 deque
deque(发音为"deck"),即"双端队列",是一种具有队列和栈的性质的对象。在deque中,可以从任一端进行快速的数据插入和删除。这种双端队列的数据结构可以高效地扩展数据,并且可以从两端进行访问。
考虑一个常见的数学模型:在一个滑动窗口内计算最大值。我们可以使用deque来有效地解决这个问题。例如,一个长度为n的滑动窗口在数组中移动,我们希望实时跟踪窗口内的最大值。deque可以让我们在 O ( 1 ) O(1) O(1)的时间复杂度内进行必要的操作,如下所示:
from collections import dequedef max_in_sliding_window(arr, n):q = deque()for i in range(n):while q and arr[i] >= arr[q[-1]]:q.pop()q.append(i)for i in range(n, len(arr)):print(arr[q[0]], end=' ')while q and q[0] <= i - n:q.popleft()while q and arr[i] >= arr[q[-1]]:q.pop()q.append(i)print(arr[q[0]])
在这段代码中,我们维护了一个deque,保证它从大到小排列,deque中存储的是数组索引,并保证窗口中的最大值总在deque的前端。每次移动窗口时,只需查看deque前端的值即可。
12.2 namedtuple
namedtuple是另一个非常有用的数据结构,它是一个函数,用于创建自定义的tuple对象。与普通的tuple只能通过索引访问数据不同,namedtuple让你能够给每个位置的数据命名,这样代码的可读性大大提高。
设想我们正在处理一个地理坐标系统,我们可以定义一个Point的namedtuple来表示坐标点,如下所示:
from collections import namedtuplePoint = namedtuple('Point', 'x y')
pt1 = Point(1.0, 5.0)
pt2 = Point(2.5, 1.5)def get_distance(p1, p2):return ((p1.x - p2.x)**2 + (p1.y - p2.y)**2)**0.5print(f"The distance is {get_distance(pt1, pt2)}")
在这个例子中,我们创建了一个Point的namedtuple来存储坐标点,并定义了一个函数来计算两点间的欧几里得距离, ( x 2 − x 1 ) 2 + ( y 2 − y 1 ) 2 \sqrt{(x_2 - x_1)^2 + (y_2 - y_1)^2} (x2−x1)2+(y2−y1)2。这使得代码既简洁又具有表达力。
12.3 Counter
Counter是一个简单的计数器,用于跟踪值出现的次数。它是一个字典的子类,每个元素作为键,元素计数作为值。这在很多场合都非常有用。例如,我们可以使用Counter来统计文本中单词出现的频率。
from collections import Countertext = "apple banana apple strawberry banana lemon"
words = text.split()
counter = Counter(words)for word, count in counter.items():print(f"The word '{word}' appears {count} times.")
在这段简单的代码中,我们使用Counter来统计一段文本中每个单词出现的次数。Counter对象可以非常方便地转换成列表或其他数据结构,提供了我们所需的统计信息。
12.4 可视化:数据结构内部工作原理图
我们可以通过可视化来更好地理解这些数据结构的内部工作原理。例如,一个deque可以被可视化为一个两端都可以插入和删除元素的队列。相比之下,一个Counter可以通过柱状图来展示各元素的计数,而namedtuple则可以通过一个有标签的点来表示其结构。
12.5 进一步阅读:collections模块源码解析
想要更深入地了解collections模块,一个很好的方式是阅读其源代码。Python是开源的,所以你可以直接访问collections模块的实现代码。通过阅读源代码,你不仅可以了解到这些数据结构的内部工作机制,还能学习到如何编写高质量的Python代码。
通过阅读本章节,希望你能对Python的collections模块有了更深刻的理解。这些工具都是为了提高你的编程效率和代码可读性。记住,掌握了这些强大的工具后,使得你能够更加自在地驾驭Python编程的海洋。下次编码时不妨试试这些结构,看看它们如何能够帮助你更好地解决问题。

13 高级函数用法:functools模块
在Python编程的世界里,我们常常聆听到一句箴言:“一切皆对象。”在这个前提下,函数也并不例外。函数作为一等公民,意味着它们可以像任何其他对象一样存储在数据结构中,作为参数传递,或作为函数的返回值。而functools模块,便是围绕这一理念,提供了一系列用于高阶函数编程的工具。这一章节,我们将专注于解读functools模块中的部分精华——partial函数和装饰器,并举例说明它们在编写可复用代码组件时的应用。
13.1 partial函数
partial函数的作用是:基于一个函数创建一个新的可调用对象,新函数固定了原函数的部分参数。数学上,这可以视作函数的部分评估,我们有:
f ( x , y , z ) → f ′ ( y , z ) f(x, y, z) \rightarrow f'(y, z) f(x,y,z)→f′(y,z)
其中,通过partial, f ′ f' f′是 f f f的一个特殊形式,其中一些参数 x x x已经被预先填充。那么在代码中,这是如何实现的呢?
假设我们有如下的函数:
def power(base, exponent):return base ** exponent
现在,我们想创建一个新的函数square,用于计算平方,我们可以使用partial:
from functools import partialsquare = partial(power, exponent=2)print(square(2)) # 输出: 4
print(square(5)) # 输出: 25
这里,square本质上是power的一个特例,其中exponent被固定为2。
13.2 装饰器
装饰器是Python中一种强大的函数修改工具,它们允许程序员在不修改函数源代码的情况下,增加函数功能。数学上,可以认为装饰器是一个函数,它接受函数作为输入,并返回一个新的函数:
decorator ( f ) → f ′ \text{decorator}(f) \rightarrow f' decorator(f)→f′
其中, f ′ f' f′代表被装饰后的函数。例如,让我们创建一个简单的装饰器,用于记录函数调用:
def logger(func):def wrapper(*args, **kwargs):print(f"Calling {func.__name__} with {args} and {kwargs}")result = func(*args, **kwargs)print(f"{func.__name__} returned {result}")return resultreturn wrapper@logger
def add(x, y):return x + yadd(5, 3)
此时,调用add(5, 3)将首先打印出函数名和传递的参数,然后执行函数本身,最后打印函数的返回值。
在functools模块内,有一个非常有用的装饰器叫做@lru_cache,它可以对函数的调用结果进行缓存,减少重复计算,特别是在处理递归函数时非常有效:
from functools import lru_cache@lru_cache(maxsize=None)
def fib(n):if n < 2:return nreturn fib(n-1) + fib(n-2)print(fib(30)) # 会快速返回结果,而不是逐个计算
13.3 可视化:函数装饰和组合流程图
若要可视化partial和装饰器的工作原理,我们可以画出函数的变换流程图。
对于partial,流程图可以表现为一个有向图,其中节点表示函数,边表示参数的固定。
对于装饰器,流程图将表现为层叠的结构,基础函数位于最内层,而装饰器则像洋葱一样一层层包裹在其外部,每一层代表一个装饰器所添加的功能。
13.4 进一步阅读:高阶函数和函数式编程
要更进一步理解高阶函数和函数式编程,我们需要深入研究functools模块,并探讨其它高阶函数如reduce、map和filter的使用。函数式编程的一个核心原则是不修改外部状态,而是通过函数之间的输入和输出进行数据流动。
在函数式编程中,一个常见的数学概念是函数复合,它可以表示为:
( f ∘ g ) ( x ) = f ( g ( x ) ) (f \circ g)(x) = f(g(x)) (f∘g)(x)=f(g(x))
这意味着你可以创建两个函数g和f,通过将g的输出作为f的输入,你得到了两个函数的复合。
通过充分利用functools模块,Python程序员可以编写出既简洁又强大的代码,从而提高开发效率和代码质量。掌握这些工具,无疑会让你在编程的道路上更加游刃有余。

14 日志与调试:logging模块
14.1 配置日志记录器
在软件开发的世界里,日志记录是一项关键的任务,它使我们能够观察程序的执行情况并在问题发生时进行调试。Python的logging模块提供了一套灵活的日志系统,既可以轻松记录消息,也可以通过各种方式输出信息。
日志系统的核心是日志记录器(logger),它是一个日志接口,可以设置不同的日志级别和输出目标。日志级别从低到高包括DEBUG、INFO、WARNING、ERROR和CRITICAL,它们定义了记录信息的严重性。例如,使用 D E B U G DEBUG DEBUG级别可以记录详细的程序运行信息,而 E R R O R ERROR ERROR级别则用于记录运行错误。
配置记录器通常涉及设置日志级别和日志处理器(handlers),处理器决定了日志信息的去向,可以是控制台、文件或网络。以下是一个配置日志记录器的例子:
import logging# 创建一个配置器
logger = logging.getLogger('example_logger')
logger.setLevel(logging.DEBUG) # 设置日志级别为DEBUG# 创建一个处理器,将日志写入文件
file_handler = logging.FileHandler('example.log')
file_handler.setLevel(logging.ERROR) # 仅记录ERROR级别的信息# 创建一个格式化器,并设置格式
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
file_handler.setFormatter(formatter)# 将处理器添加到记录器
logger.addHandler(file_handler)# 记录一条信息
logger.debug('This is a debug message') # 因为级别太低,这条信息不会被记录到文件
logger.error('This is an error message') # 这条信息会被记录到文件
在这个例子中,我们首先创建了一个名为example_logger的日志记录器,并将其日志级别设置为 D E B U G DEBUG DEBUG,意味着所有 D E B U G DEBUG DEBUG及以上级别的日志都会被处理。然后,我们创建了一个文件处理器,它专门负责记录 E R R O R ERROR ERROR级别的日志,同时我们为这个处理器设置了一个格式化器,以定义日志的格式。最后,我们尝试记录两条信息,只有 E R R O R ERROR ERROR级别的信息被写入了文件。
14.2 实例代码:记录应用程序运行日志
让我们看一个实际的应用程序例子,该程序计算数列的平均值,并使用日志记录关键信息:
import logging
import random# 配置日志记录器
logging.basicConfig(filename='app.log', filemode='w', format='%(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger('average_calculator')def calculate_average(numbers):if not numbers:logger.error('No numbers to calculate average.')raise ValueError('List is empty.')average = sum(numbers) / len(numbers)logger.info('Calculated average: %s', average)return average# 模拟一些数据
data = [random.uniform(0, 100) for _ in range(10)]# 调用函数并记录日志
try:result = calculate_average(data)
except ValueError as e:logger.exception('Exception occurred: %s', e)
else:logger.debug('Successfully calculated average.')在这个例子中,我们首先使用basicConfig方法简化了日志配置过程,随后创建了一个名为average_calculator的记录器。在calculate_average函数中,我们使用日志记录了错误和信息级别的事件。此外,我们还演示了如何在出现异常时记录它。
14.3 可视化:日志级别和输出格式图
理解日志级别和它们如何影响日志记录是至关重要的。一个有效的可视化方式是使用日志级别金字塔图:
CRITICAL^|ERROR^|WARNING^|INFO^|DEBUG
金字塔顶部的级别最高,只有最严重的消息会使用CRITICAL级别。随着你向下移动,记录的信息会越来越详细。通常,在开发过程中使用DEBUG级别,而在生产环境中可能更多使用WARNING或ERROR级别。
格式化日志输出是日志配置的另一个关键部分。一个标准的日志格式可能包括时间戳、记录器名称、日志级别和消息:
2023-03-26 16:20:45,123 - example_logger - ERROR - Error occurred.
14.4 进一步阅读:日志系统的设计和维护
要深入了解和设计一个完整的日志系统,你需要考虑许多因素,像是日志的分割、压缩和归档、远程日志记录、线程和多进程环境中的日志记录等。此外,了解如何利用日志对系统进行监控和警报也是重要的。
探究logging模块的高级特性,比如添加过滤器、设置不同的日志处理流程、整合其他日志框架或服务,都是设计一个成熟日志系统不可或缺的部分。

15 结语
亲爱的读者,在这篇博客文章中,我们一起探索了Python世界中的一些最有用的模块。从处理时间日期的datetime模块,到执行文件I/O的内置函数,再到os和sys模块在系统编程中的应用,我们见证了这些工具如何简化我们的编程任务,使我们能够更加专注于解决实际问题。
在math模块的探讨中,我们重点了解了该模块提供的一系列数学函数和常量。例如,我们可以使用math.sqrt(x)计算一个数( x )的平方根,或者使用math.pi获得π的值。数学常量和函数在Python中的实现,是基于一系列复杂的数学公式和原理。所以,math模块不仅是一个工具箱,它也代表了数学与计算的完美结合。
当我们在讨论随机数生成时,random模块的使用让程序能够处理不确定性,这对于模拟、游戏开发和随机抽样至关重要。背后的数学不仅仅是随机性的体现,还涉及到概率论的深刻理解。伪随机数生成器(PRNG)的一般形式可以表示为:
X n + 1 = ( a X n + c ) m o d m X_{n+1} = (aX_n + c) \mod m Xn+1=(aXn+c)modm
这里( a )、( c )和( m )是常数,( X )是序列中的数,这个公式是产生一系列看似随机的数的基础。
我们的讨论还包括了re模块,它是处理文本的强大工具。通过编写正则表达式,我们能够执行复杂的字符串搜索、替换和分割操作。例如,表达式^a...s$可以匹配以’a’开始,以’s’结束的任何五个字符的字符串。这种模式匹配能力是通过对正则表达式引擎底层算法的深刻理解实现的。
在数据交换格式处理方面,json和xml模块使我们能够在网络编程中轻松地解析和生成数据。我们可以通过json.loads(s)解析JSON字符串,或者使用xml.etree.ElementTree解析XML文档。处理这些数据结构背后的数学模型,通常涉及到了树结构、递归算法和图论概念。
最后,我们也探讨了urllib模块如何帮助我们发送HTTP请求和处理响应。网络请求的过程可以通过状态机模型来描述,每个状态代表着请求/响应周期的不同阶段:
Idle → send request Sent → receive response Received → process data Processed \text{Idle} \xrightarrow{\text{send request}} \text{Sent} \xrightarrow{\text{receive response}} \text{Received} \xrightarrow{\text{process data}} \text{Processed} Idlesend requestSentreceive responseReceivedprocess dataProcessed
通过本篇文章,我们希望你能够对Python的常用模块有了更深入的理解,并且能够将这些知识应用到实践中。记住,每个模块都是Python这个强大生态系统中的一部分,它们各自承担着特定的角色。掌握它们,将是你成为一名高效、精通的Python程序员的重要一步。
我们鼓励你不仅仅停留在本文内容的学习上,更要动手实践和自我探索。只有通过实际使用这些模块去解决问题,你才能真正领会它们的威力。在这个过程中,无论遇到何种挑战,都不要忘记,每个问题往往都是新知识的开端。祝你在这条充满挑战与发现的编程之旅上,越走越远。