一、背景介绍
- 题目来源:2023全国大学生计算机系统能力大赛操作系统设计赛-功能挑战赛
- 题目地址:proj225-document-question-answering-bot
- 题目描述:https://wiki.deepin.org 上有900多条deepin系统相关的中文教程和词条,请编写能根据这些内容回答问题的中文聊天机器人。使用者通过命令行界面输入问题,机器人输出回答和参考的wiki文档的链接。
- 参考文档:
- deepin wiki 仓库
- 问答系统用例
- 问答系统 wiki
- 题目要求:
- (必须)完成一个聊天机器人,能根据 deepin wiki 内容回答问题
- (必须)通过训练模型,使回答和问题要有80%以上概率的相关性。
- (必须)编写博客,记录开发过程的心得与体会,并将博客投递至 planet.deepin.org
- (可选)添加玲珑使用手册内容,支持回答玲珑使用的问题。
- (可选)使用web或qt为机器人添加可视化界面支持,能在deepin系统上使用。
二、题目分析
该题目要求做一个基于文档建立的问答系统,结合如今的深度学习技术,我们无需梳理意图、词槽,无需进行问题和答案的整理,只需准备文本格式的教程和词条文档,就可以得到一个问答系统,回答用户的各种问题。
通过结合大语言模型的推理能力和向量数据库的存储和检索能力,来实现通过向量检索到最相关的语义片段,然后让大语言模型结合相关片段上下文来进行正确的推理得到结论。在这个过程中主要有两个流程:后端数据处理和存储流程、前端问答流程,同时其底层主要依赖两个模块:基于大语言模型的推理模块、基于向量数据库的向量数据管理模块。
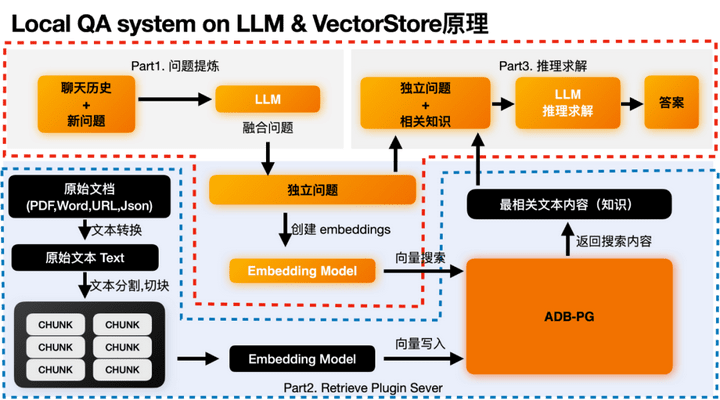
三、技术路线
ChatGLM-6B
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
时下主流的预训练框架有三种:autoregressive自回归模型(如GPT)、autoencoding自编码模型(如BERT)、encoder-decoder编码-解码模型(如T5、BigBird)。GLM模型基于autoregressive blank infilling方法,结合了上述三种预训练模型的思想。
使用ChatGLM做文档问答的大致思路如下:
- 将教程和词条整理为纯文本的格式,把每个文档切成若干个小的chunks。
- 调用文本转向量的接口,将每个chunk转为一个向量,并存入向量数据库。
- 当用户发来一个问题的时候,将问题同样转为向量,并检索向量数据库,得到相关性最高的一个chunk。
- 将问题和chunk合并重写为一个新的请求发给chatglm的api。
q-d匹配与q-q匹配
这里实际做的是将用户请求的query和document做匹配,也就是所谓的q-d匹配。q-d匹配的问题在于query和document在表达方式存在较大差异,通常query是以疑问句为主,而document则以称述说明为主,这种差异可能会影响最终匹配的效果。一种改进的方法是,不直接做q-d匹配,而是先通过document生成一批候选的question,当用户发来请求的时候,首先是把query和候选的question做匹配,进而找到相关的document片段,这种方法就是’q-q匹配’,具体思路如下:
- 将教程和词条整理为纯文本的格式,把每个文档切成若干个小的chunks
- 调用ChatGLM的API,根据每个chunk生成5个候选的question,使用的prompt格式为’请根据下面的文本生成5个问题: …'。
- 调用文本转向量的接口,将生成的question转为向量,并存入向量数据库,并记录question和原始chunk的对应关系。
- 当用户发来一个问题的时候,将问题同样转为向量,并检索向量数据库,得到相关性最高的一个question,进而找到对应的chunk。
- 将问题和chunk合并重写为一个新的请求发给chatglm的api。
总结来说,即让AI根据每段文本生成大量问题,再将用户问题跟AI生成问题匹配,找到问题所在的文本段落并生成prompt。
SimBERTv2
SimBERT是一个融生成和检索于一体的模型,可以用来作为句向量的一个比较高的baseline,也可以用来实现相似问句的自动生成,可以作为辅助数据扩增工具使用,它以Google开源的BERT模型为基础,基于微软的UniLM思想设计了融检索与生成于一体的任务,来进一步微调后得到的模型,所以它同时具备相似问生成和相似句检索能力。SimBERTv2是SimBERT的升级版,它们主要的区别在于训练的细节上,可以用两个公式进行对比:
S i m B E R T = B E R T + U n i L M + 对比学习 S i m B E R T v 2 = R o f o r m e r + U n i L M + 对比学习 + B A R T + 蒸馏 SimBERT=BERT+UniLM+对比学习 \\ SimBERTv2=Roformer+UniLM+对比学习+BART+蒸馏 SimBERT=BERT+UniLM+对比学习SimBERTv2=Roformer+UniLM+对比学习+BART+蒸馏
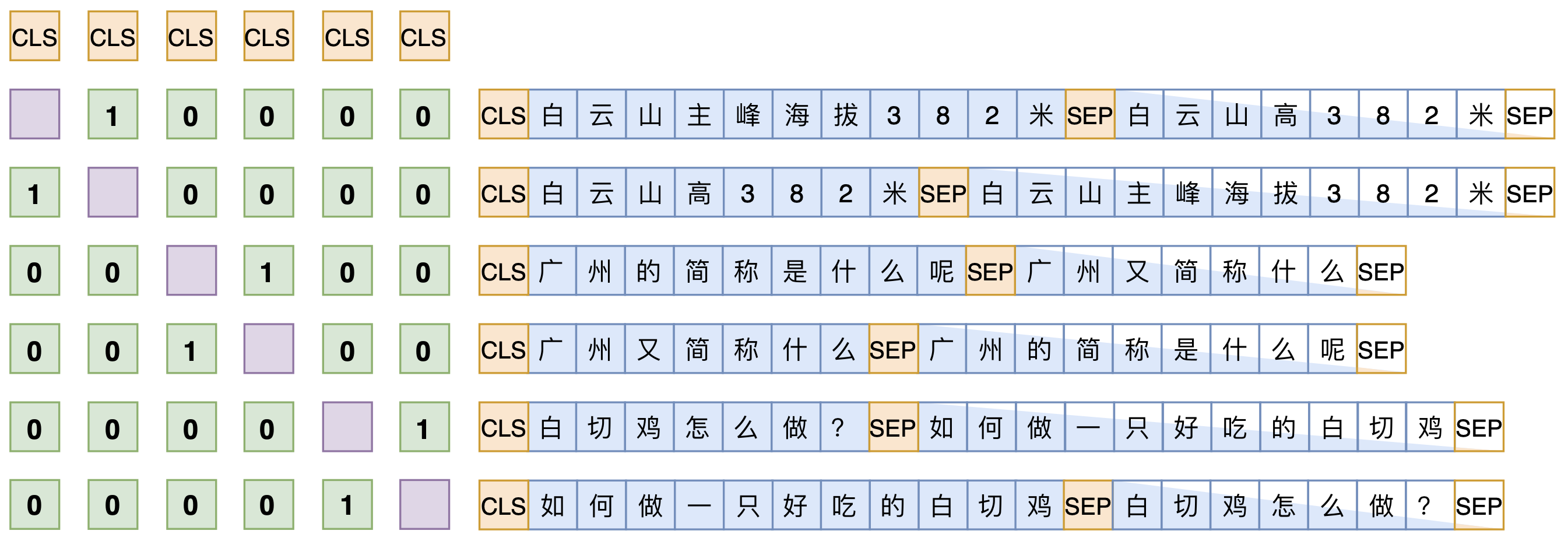
SimBERT属于有监督训练,训练语料是自行收集到的相似句对,通过一句来预测另一句的相似句生成任务来构建Seq2Seq部分,[CLS]的向量事实上就代表着输入的句向量,所以可以同时用它来训练一个检索任务,如下图:
、参考文献
[1]苏剑林. (Jun. 11, 2021). 《SimBERTv2来了!融合检索和生成的RoFormer-Sim模型 》[Blog post]. Retrieved from https://kexue.fm/archives/8454