随着数据体量的日益增长,人们对 Hudi 的查询性能也提出更多要求,除了 Parquet 存储格式本来的性能优势之外,还希望 Hudi 能够提供更多的性能优化的技术途径,尤其当对 Hudi 表进行高并发的写入,产生了大量的小文件之后,又需要使用 Presto/Trino 对 Hudi 表进行高吞吐的即席查询的场景里。怎样处理这些小文件,即把原本是写优化的Hudi 表,让它也能支持读优化,就成了使用 Hudi 的用户需要解决的问题。
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |
本文将通过一个实际的例子,使用 Clustering 技术,对Hudi表的数据文件进行重组和重写,从而提升Hudi表的SQL查询性能。
1.Hudi
Hudi将数据仓库和数据库的核心功能直接引入数据湖。Hudi 提供了表、事务、高效的升级/删除、高级索引、流式摄取服务、数据集群(Clustering)、压缩优化和并发,同时将数据保持为开源文件格式,即可以把 Hudi 表的数据,保存在 HDFS,Amazon S3 等文件系统。
Hudi 之所以能快速流行起来,为多数开发用户接受,除了它可以轻松地在任何云平台上使用,并且可以通过任何流行的查询引擎(包括 Apache Spark、Flink、Presto、Trino、Hive 等)来访问Hudi的数据,更为难能可贵的,是Hudi的设计者考虑了尽可能多的业务场景和实际需求。
从实际的业务场景出发,对数据湖平台对需求,首先可以先分为两大类:读偏好和写偏好,所以 Apache Hudi 提供了两种类型的表:
- Copy On Write 表:简称 COW,这类Hudi表使用列文件格式(例如Parquet)存储数据,如果有数据写入,则会对整个 Parquet 文件进行复制,适合读偏好的操作
- Merge On Read 表:简称 MOR,这类 Hudi 表使用列文件格式(例如Parquet)和行文件格式(例如 Avro)共同存储数据。数据更新时,写到行文件中,然后进行压缩,以同步或异步方式生成列文件,适合写偏好的操作
再细分下来,Hudi 对两种类型的表,提供了不同的查询类型:
- Snapshot Queries:快照查询,查询数据的最新快照,即全部的数据
- Incremental Queries:增量查询,可以查询指定时间范围内的新增或修改的数据
- Read Optimized Queries:读取优化查询,对MOR表来说,仅查询Parquet 文件中的数据
以上三种查询类型,读优化查询只能用于MOR表(其实用于 COW 也没什么意义,本来COW就只有 Parquet 文件保存数据),另外两种查询模式,可以用于 COW 表和 MOR 表。
不仅于此, Hudi 还在索引、事务管理、并发、压缩等方面,使用到了很多先进的理念和技术,这也给那些想对 Hudi 表进行性能调优的用户,提供了广阔的空间和更多的手段,例如 Index,Metadata Table,Clustering 等,本文将介绍 Clustering 这一技术。
2.Hudi Clustering
在数据湖/数据仓库中,关键的权衡之一是写入速度和查询性能之间的权衡。数据写入通常倾向于使用小文件来提高并行性,并使数据尽快可用于查询。但是,如果有很多小文件,查询性能会很差。此外,在写入过程中,数据通常根据到达时间写入同一位置的文件。然而,当频繁查询的数据位于同一位置时,查询引擎的性能会更好。
这就对 Hudi 的数据重组提出了要求,即数据写入时使用小文件,数据查询时使用大文件。
2.1 设定 Hudi 表的 Clustering 参数
在文档 [RFC-19] 中, 作者创建了一个Hudi表,并设定了 Clustering的参数,然后启动了异步 Clustering Job,并对结果进行了对比。请注意,该文档创建 Hudi 表的时候,调用 getQuickstartWriteConfigs 方法来设定参数hoodie.upsert.shuffle.parallelism 为 2,对数据量较大的测试,这显然是不够的。
我们来看一个不同的例子,首先生成一套 TPC-DS 测试数据,它具体包括24个表,以及用于性能测试的99个 SQL 查询语句,生成数据的具体步骤请参考:
通过使用 Amazon Graviton2 提升 EMR 的性价比 | 亚马逊AWS官方博客
创建一个 Amazon EMR 集群,版本6.5.0,硬件配置如下:

使用该集群生成一套100G的TPC-DS数据,大概需要30分钟。
Amazon EMR 提供了 Hudi 组件,接下来用生成的 TPC-DS 数据,来生成一个 Hudi 表,我们选取表 store_sales,脚本如下:
spark-shell --master yarn \
--deploy-mode client \
--conf "spark.serializer=org.apache.spark.serializer.KryoSerializer" \
--conf "spark.sql.hive.convertMetastoreParquet=false" \
--packages org.apache.hudi:hudi-spark3-bundle_2.12:0.10.0import org.apache.hudi.QuickstartUtils._import org.apache.spark.sql.SaveMode._import org.apache.hudi.DataSourceReadOptions._import org.apache.hudi.DataSourceWriteOptions._import org.apache.hudi.config.HoodieWriteConfig._import java.util.Dateval tableName = "store_sales"val basePath = "s3://dalei-demo/hudi/tpcds_hudi_cluster/store_sales"val partitionKey = "ss_sold_date_sk"val df = spark.read.format("parquet").load(s"s3://dalei-demo/tpcds/data10g/store_sales").filter("ss_sold_time_sk is not null and ss_item_sk is not null and ss_sold_date_sk is not null and ss_customer_sk is not null").withColumn("ts", lit((new Date()).getTime)).repartition(1000)df.write.format("org.apache.hudi").option(TABLE_NAME, tableName).option("hoodie.datasource.write.precombine.field", "ts").option("hoodie.datasource.write.recordkey.field", "ss_sold_time_sk, ss_item_sk").option("hoodie.datasource.write.partitionpath.field", partitionKey).option("hoodie.upsert.shuffle.parallelism", "1000").option("hoodie.datasource.write.table.type", "MERGE_ON_READ").option("hoodie.datasource.write.operation", "upsert").option("hoodie.parquet.max.file.size", "10485760").option("hoodie.datasource.write.hive_style_partitioning", "true").option("hoodie.datasource.write.keygenerator.class", "org.apache.hudi.keygen.ComplexKeyGenerator").option("hoodie.datasource.hive_sync.enable", "true").option("hoodie.datasource.hive_sync.mode", "hms").option("hoodie.datasource.hive_sync.database", "tpcds_hudi_cluster").option("hoodie.datasource.hive_sync.table", tableName).option("hoodie.datasource.hive_sync.partition_fields", partitionKey).option("hoodie.parquet.small.file.limit", "0").option("hoodie.clustering.inline", "true").option("hoodie.clustering.inline.max.commits", "2").option("hoodie.clustering.plan.strategy.max.num.groups", "10000").option("hoodie.clustering.plan.strategy.target.file.max.bytes", "1073741824").option("hoodie.clustering.plan.strategy.small.file.limit", "629145600").option("hoodie.clustering.plan.strategy.sort.columns", "ss_customer_sk").mode(Append).save(basePath);解释一下上面代码中用到的主要参数:
- hoodie.upsert.shuffle.parallelism: upsert 时 shuffle 的并发数
- hoodie.parquet.max.file.size: 指定 Parquet 文件大小,为了对比 Clustering 前后的效果,我们希望能生成大量的小文件,所以这里限制了文件不能过大
- hoodie.datasource.write.keygenerator.class: 如果是复合主键,需要指定该参数的值为 org.apache.hudi.keygen.ComplexKeyGenerator
- hoodie.datasource.hive_sync.*: 这些参数是为了将 Hudi 表的 Schema 信息同步到 Hive MetaStore
- hoodie.parquet.small.file.limit: 如果小于指定的值,将被看作是小文件,Upsert 时会将小文件替换成大文件(所谓的“扩展”),而不是新生成一个文件,将该值设为 0,即关闭了小文件限制,这样每次写入数据都会生成新的文件
- hoodie.clustering.inline: 启用同步的 Clustering, 即 Commit 数量一旦达到,马上执行 Clustering
- hoodie.clustering.inline.max.commits: 多少次 Commit 之后,就开始执行Clustering
- hoodie.clustering.plan.strategy.max.num.groups: Clustering 将产生多少个File Group,默认30个
- hoodie.clustering.plan.strategy.target.file.max.bytes: Clustering 后文件大小的限制
- hoodie.clustering.plan.strategy.small.file.limit: 小于该值的文件,会被 Clustering
- hoodie.clustering.plan.strategy.sort.columns: Clustering 时,使用该字段排序
参数可以使用定义在 org.apache.hudi.DataSourceWriteOptions 里的常量(例如TABLE_NAME),也可以直接使用字符串(例如” hoodie.datasource.write.table.name”),效果都是一样的。
2.2 触发 Clustering
之前的操作只是创建了Hudi表和配置了 Clustering,由于 Commit 次数不到2次(请注意看配置参数,之前的 Upsert 是1次 Commit),所以还没有触发 Clustering. 大家可以先把Commit理解为一次 Upsert操作。
我们再模拟一次 Commit 操作,对 store_sales 表的一个分区的某个字段做修改,然后再Upsert到表里,代码如下:
val df1 = spark.read.format("hudi").option("hoodie.datasource.query.type", "read_optimized").load("s3://dalei-demo/hudi/tpcds_hudi_cluster/store_sales").filter("ss_sold_date_sk=2450816").drop(col("_hoodie_commit_seqno")).drop(col("_hoodie_commit_time")).drop(col("_hoodie_record_key")).drop(col("_hoodie_partition_path")).drop(col("_hoodie_file_name"))val df2 = df1.withColumn("ss_ext_tax", col("ss_ext_tax") + lit(1.0))df2.write.format("org.apache.hudi").option(TABLE_NAME, tableName).option("hoodie.datasource.write.precombine.field", "ts").option("hoodie.datasource.write.recordkey.field", "ss_sold_time_sk, ss_item_sk").option("hoodie.datasource.write.partitionpath.field", partitionKey).option("hoodie.upsert.shuffle.parallelism", "1000").option("hoodie.datasource.write.table.type", "MERGE_ON_READ").option("hoodie.datasource.write.operation", "upsert").option("hoodie.parquet.max.file.size", "10485760").option("hoodie.datasource.write.hive_style_partitioning", "true").option("hoodie.datasource.write.keygenerator.class", "org.apache.hudi.keygen.ComplexKeyGenerator").option("hoodie.datasource.hive_sync.enable", "true").option("hoodie.datasource.hive_sync.mode", "hms").option("hoodie.datasource.hive_sync.database", "tpcds_hudi_cluster").option("hoodie.datasource.hive_sync.table", tableName).option("hoodie.datasource.hive_sync.partition_fields", partitionKey).option("hoodie.parquet.small.file.limit", "0").option("hoodie.clustering.inline", "true").option("hoodie.clustering.inline.max.commits", "2").option("hoodie.clustering.plan.strategy.max.num.groups", "10000").option("hoodie.clustering.plan.strategy.target.file.max.bytes", "1073741824").option("hoodie.clustering.plan.strategy.small.file.limit", "629145600").option("hoodie.clustering.plan.strategy.sort.columns", "ss_customer_sk").mode(Append).save(basePath);代码执行完后,Commit 次数达到2次,Clustering 已经做后台执行了。
2.3 解释 Clustering 操作过程
在解释 Clustering 之前,先介绍一下 Hudi 表的操作文件的构成。
2.3.1 Hudi 表的操作文件
以前面生成的 store_sales 表为例,在.hoodie 目录下,包含了该表的操作记录,如下图:
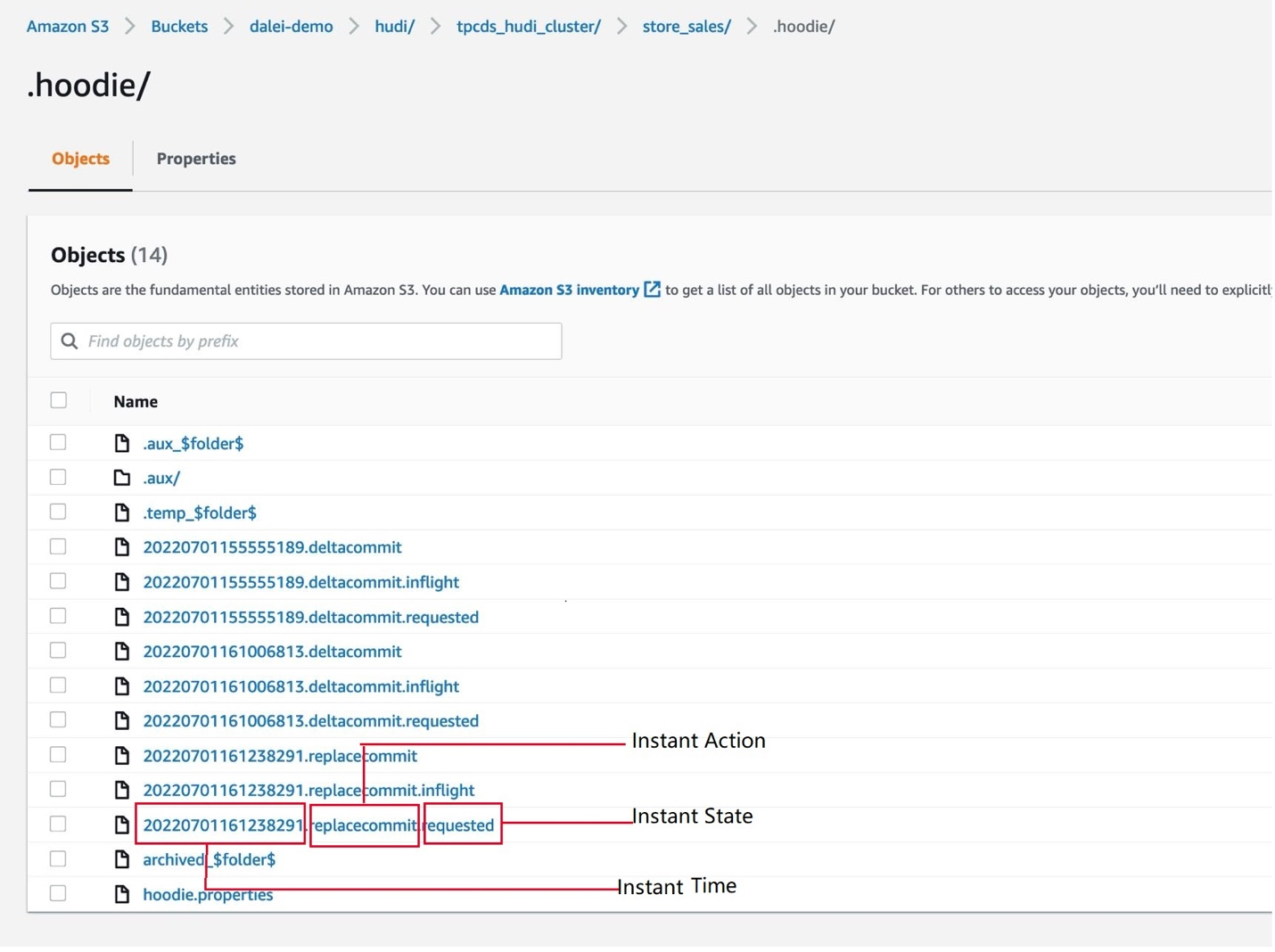
图1: Hudi 表的操作文件
Hudi 操作的文件名,通常有三个部分组成:
- Instant Time: 操作的时间,一个17位的时间戳(8位日期 + 9位时间,精确到毫秒)
- Instant Action: 操作的类型,前端执行 Upsert 时,会产生的操作类型是deltacommit; Clustering会产生的操作类型是 replacecommit
- Instant State: 操作的状态,requested 表示请求,inflight 表示正在进行,状态为空表示已经执行完成
可以把 Clustering 请求文件20220701161238291.replacecommit.requested 文件下载下来,因为它是 Avro 格式的,使用 avro-tools 来查看一下它的内容:
[ec2-user@cm ~]$ aws s3 cp s3://dalei-demo/hudi/tpcds_hudi_cluster/store_sales/.hoodie/20220701161238291.replacecommit.requested ./[ec2-user@cm ~]$ wget http://archive.apache.org/dist/avro/avro-1.9.2/java/avro-tools-1.9.2.jar[ec2-user@cm ~]$ java -jar avro-tools-1.9.2.jar tojson 20220701161238291.replacecommit.requested >> 20220701161238291.replacecommit.requested.json可以使用浏览器将文件打开,如下图:
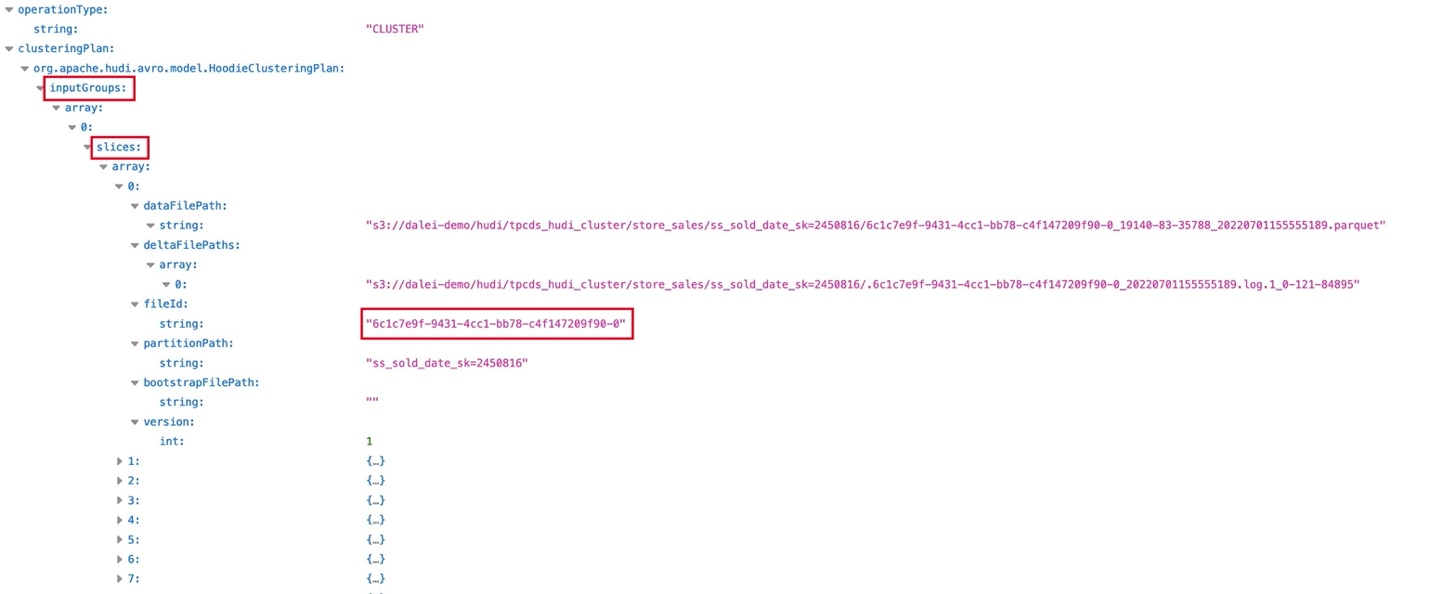
图2: Clustering 请求文件
上图中的inputGroups就是File Group,slices就是File Slice,还有File ID, 这三个概念在2.3.2里会介绍,这个文件就是发起了一个Clustering操作的请求,要把这些文件作为输入,生成更大的文件来替换它们,生成的文件也会在2.3.2里介绍。
20220701161238291.replacecommit.inflight 文件的大小为0,说明 Clustering 已经立即完成了,再来看20220701161238291.replacecommit 文件,它是 json 格式的文件,可以直接打开,内容如下:
{"partitionToWriteStats" : {"ss_sold_date_sk=2451080" : [ {"fileId" : "91377ca5-48a9-491a-9c82-56a1ba4ba2e3-0","path" : "ss_sold_date_sk=2451080/91377ca5-48a9-491a-9c82-56a1ba4ba2e3-0_263-1967-116065_20220701161238291.parquet","prevCommit" : "null","numWrites" : 191119,"numDeletes" : 0,"numUpdateWrites" : 0,"numInserts" : 191119,"totalWriteBytes" : 11033199,"totalWriteErrors" : 0,"tempPath" : null,"partitionPath" : "ss_sold_date_sk=2451080","totalLogRecords" : 0,"totalLogFilesCompacted" : 0,"totalLogSizeCompacted" : 0,"totalUpdatedRecordsCompacted" : 0,"totalLogBlocks" : 0,"totalCorruptLogBlock" : 0,"totalRollbackBlocks" : 0,"fileSizeInBytes" : 11033199,"minEventTime" : null,"maxEventTime" : null} ],......},"compacted" : false,"extraMetadata" : {"schema" : "{\"type\":\"record\",\"name\":\"store_sales_record\",\"namespace\":\"hoodie.store_sales\",\"fields\":[{\"name\":\"ss_sold_time_sk\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"ss_item_sk\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"ss_customer_sk\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"ss_cdemo_sk\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"ss_hdemo_sk\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"ss_addr_sk\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"ss_store_sk\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"ss_promo_sk\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"ss_ticket_number\",\"type\":[\"null\",\"long\"],\"default\":null},{\"name\":\"ss_quantity\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"ss_wholesale_cost\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ss_list_price\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ss_sales_price\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ss_ext_discount_amt\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ss_ext_sales_price\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ss_ext_wholesale_cost\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ss_ext_list_price\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ss_ext_tax\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ss_coupon_amt\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ss_net_paid\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ss_net_paid_inc_tax\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ss_net_profit\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ts\",\"type\":\"long\"},{\"name\":\"ss_sold_date_sk\",\"type\":[\"null\",\"int\"],\"default\":null}]}"},"operationType" : "CLUSTER","partitionToReplaceFileIds" : {"ss_sold_date_sk=2451080" : [ "2e2bec06-78fb-4059-ad89-2914f63dd1c0-0", "63fc2a2d-73e6-4261-ab30-ff44912e1696-0", "fc5fd42e-0f3f-434c-aa56-ca43c36c659d-0", "41299b3d-0be9-4338-bbad-6feeb41d4975-0", "c23873a1-03a3-424a-aa9c-044b40f1659f-0", "8af23590-4b8c-4b44-946e-0fdd73747e19-0", "7d740b43-83ca-48ca-a9dc-6b8e19fce6f0-0", "bc90dfd5-7323-4786-832c-4a6516332adf-0", "67abd081-dfcc-45d9-8f29-50a4fb71108c-0", "80bffa2b-df05-4c9f-9766-84a700403a89-0", "cbba9f2a-32cd-4c73-a38b-570cbb5501e4-0", "ea59e1a4-1f97-40e8-baae-3bedc5752095-0", "55cffcb6-5410-4c2a-a61d-01300be50171-0", "601b74b3-663d-4ef8-bf5e-158f135f81ea-0", "c46e8539-418e-482d-936e-a79464d869ac-0", "3dbe1997-bfc2-41a7-ac12-f302d3013c87-0", "acf9be44-71a3-436f-b595-c0f322f34172-0", "d7bbe517-87c7-482c-b885-a16164062b81-0", "f1060ef7-ba7c-4b8e-abc3-c409cd6af7d4-0" ],......},"writePartitionPaths" : [ "ss_sold_date_sk=2451080", ......],"fileIdAndRelativePaths" : {"742c6044-4f76-4d04-993c-d4255235d484-0" : "ss_sold_date_sk=2451329/742c6044-4f76-4d04-993c-d4255235d484-0_511-1967-116236_20220701161238291.parquet","20dafb58-8ae7-41d6-a02d-2b529bcdcc83-0" : "ss_sold_date_sk=2452226/20dafb58-8ae7-41d6-a02d-2b529bcdcc83-0_1407-1967-116870_20220701161238291.parquet",......},"totalRecordsDeleted" : 0,"totalLogRecordsCompacted" : 0,"totalLogFilesCompacted" : 0,"totalCompactedRecordsUpdated" : 0,"totalLogFilesSize" : 0,"totalScanTime" : 0,"totalCreateTime" : 151847,"totalUpsertTime" : 0,"minAndMaxEventTime" : {"Optional.empty" : {"val" : null,"present" : false}}
}上面省略了大量重复的内容,主要的信息如下:
- partitionToWriteStats: 列出将要被 Clustering 的分区,以及将要被 Clustering 的文件的信息
- extraMetadata: Hudi 表的 Schema
- operationType: 表示操作类型是 Clustering
- partitionToReplaceFileIds: 列出将要被 Clustering 的分区和文件ID
- fileIdAndRelativePaths: Clustering 产生的新的文件,请注意,文件名的时间戳
2.3.2 Hudi 表的数据文件
接下来介绍一下 Hudi 表的数据文件的构成,以MOR类型的表为例,如下图:
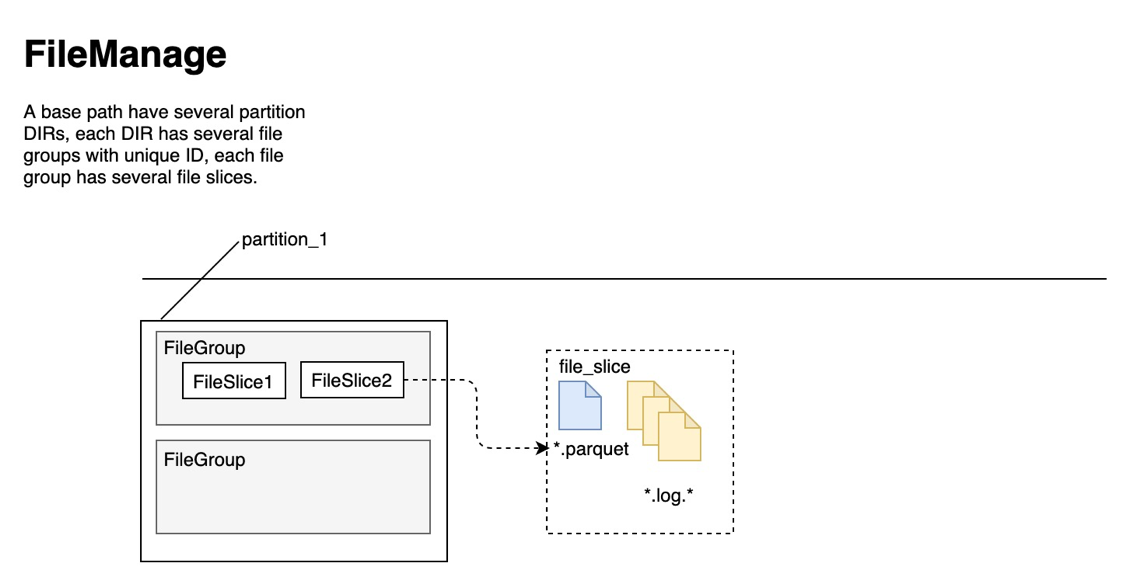
图3: MOR 表的文件结构
可以看出,文件的层级和包含关系是:Partition -> File Group -> File Slice -> Parquet + Log, 其中:
- Partition: 分区,大家都比较熟悉了,有的表也可以没有Partition
- File Group: 用于控制文件版本,同一个 File Group 里有唯一的File ID
- File Slice: 用于组织文件数据,同一个 File Slice 里,不但File ID要相同,Instant Time 也要相同
- Parquet文件是列存格式文件,Log 文件是行存文件格式,缺省值为Apache Avro, 它记录的是对同一个 File Slice 里的 Parquet 文件的修改。
来看一个 File Group 的例子:

图4: FileGroup的例子
在图4中,第一个文件和第二个文件的 File ID 相同,说明是同一个File Group,但是 Instant Time 不同,说明不是同一个 File Slice, 使用读优化的方式查询数据的时候,会读取 Instant Time更大的Parquet文件。
来看 store_sales 表的数据文件,如下图:
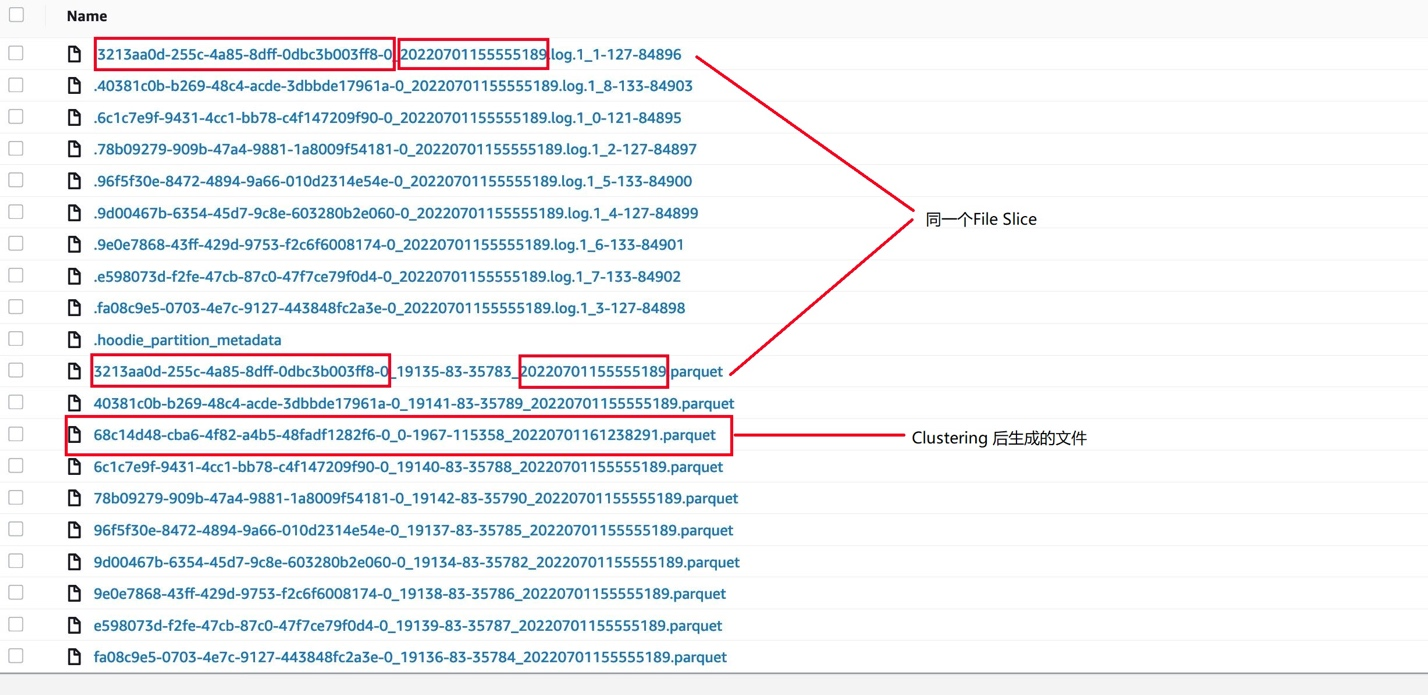
图5: store_sales表的数据文件
在图5中,标记的Log文件和Parquet文件,具有相同的 File ID 和Instant Time,表示这个 Log 文件是在 Parquet 文件基础上做的Upsert 后产生的,它们属于同一个File Slice,如果是Snapshot查询,需要把同一个 File Slice 的 Log 文件和 Parquet 的数据一起读出来。
在图5中,“68c14d48-cba6-4f82-a4b5-48fadf1282f6-0_0-1967-115358_20220701161238291.parquet”文件就是 clustering 生成的文件,可以把它下载下来,使用 parquet-tool 看看它的数据,如下:
[ec2-user@cm ~]$ wget http://logservice-resource.oss-cn-shanghai.aliyuncs.com/tools/parquet-tools-1.6.0rc3-SNAPSHOT.jar[ec2-user@cm ~]$ aws s3 cp s3://dalei-demo/hudi/tpcds_hudi_cluster/store_sales/ss_sold_date_sk=2450816/68c14d48-cba6-4f82-a4b5-48fadf1282f6-0_0-1967-115358_20220701161238291.parquet ./[ec2-user@cm ~]$ java -jar ./parquet-tools-1.6.0rc3-SNAPSHOT.jar head -n 10 68c14d48-cba6-4f82-a4b5-48fadf1282f6-0_0-1967-115358_20220701161238291.parquet上面的命令显示了10条 Clustering 后的 Parquet 文件的数据,注意观察Sort Column (ss_customer_sk) 的值,已经是排序的了。
对比Clustering前后的文件,可以看出,原来用10个1M左右的Parquet文件保存的数据,Clustering 后只有1个5.1M的 Parquet 文件。至于保存相同条数的数据,文件的总容量为什么会下降这么多,请参考Parquet的相关知识:Apache Parquet .
2.3.3 多分区表的Clustering
默认情况下, Hudi出于对工作负载的考虑,使用 hoodie.clustering.plan.strategy.max.num.groups 这个参数 (默认值是30),规定了Clustering只会创建30个File Group. (根据文件大小的设定,目前每个分区只需创建1个File Group)
如果分区比较多的话,可以通过hoodie.clustering.plan.partition.filter.mode 参数,来规划Clustering的分区范围,具体可以参考:[All Configurations | Apache Hudi .](All Configurations | Apache Hudi .)
3.使用 Trino 来查询数据
3.1 准备其它的表
store_sales 表的数据就准备好了,类似的,我们也可以生成customer_address,customer,date_dim,item 这4个表,它们都是测试查询要用到的表。这4个表都是维度表,变化不会很频繁,所以都生成 COW 表,生成 customer_address 表的代码如下:
val tableName = "customer_address"val basePath = "s3://dalei-demo/hudi/tpcds_hudi_cluster/customer_address"val df = spark.read.format("parquet").load(s"s3://dalei-demo/tpcds/data10g/customer_address").filter("ca_address_sk is not null")df.write.format("org.apache.hudi").option(TABLE_NAME, tableName).option("hoodie.datasource.write.precombine.field", "ca_address_id").option("hoodie.datasource.write.recordkey.field", "ca_address_sk").option("hoodie.upsert.shuffle.parallelism", "100").option("hoodie.datasource.write.table.type", "COPY_ON_WRITE").option("hoodie.datasource.write.operation", "upsert").option("hoodie.parquet.max.file.size", "10485760").option("hoodie.datasource.hive_sync.enable", "true").option("hoodie.datasource.hive_sync.mode", "hms").option("hoodie.datasource.hive_sync.database", "tpcds_hudi_cluster").option("hoodie.datasource.hive_sync.table", tableName).option("hoodie.parquet.small.file.limit", "0").option("hoodie.clustering.inline", "true").option("hoodie.clustering.inline.max.commits", "2").option("hoodie.clustering.plan.strategy.target.file.max.bytes", "1073741824").option("hoodie.clustering.plan.strategy.small.file.limit", "629145600").option("hoodie.clustering.plan.strategy.sort.columns", "").mode(Append).save(basePath);触发 Clustering 的代码如下:
val df1 = spark.read.format("hudi").option("hoodie.datasource.query.type", "read_optimized").load("s3://dalei-demo/hudi/tpcds_hudi_cluster/customer_address")val df2 = df1.withColumn("ca_gmt_offset", col("ca_gmt_offset") + lit(1.1))df2.write.format("org.apache.hudi").option(TABLE_NAME, tableName).option("hoodie.datasource.write.precombine.field", "ca_address_id").option("hoodie.datasource.write.recordkey.field", "ca_address_sk").option("hoodie.upsert.shuffle.parallelism", "100").option("hoodie.datasource.write.table.type", "COPY_ON_WRITE").option("hoodie.datasource.write.operation", "upsert").option("hoodie.parquet.max.file.size", "10485760").option("hoodie.datasource.hive_sync.enable", "true").option("hoodie.datasource.hive_sync.mode", "hms").option("hoodie.datasource.hive_sync.database", "tpcds_hudi_cluster").option("hoodie.datasource.hive_sync.table", tableName).option("hoodie.parquet.small.file.limit", "0").option("hoodie.clustering.inline", "true").option("hoodie.clustering.inline.max.commits", "2").option("hoodie.clustering.plan.strategy.target.file.max.bytes", "1073741824").option("hoodie.clustering.plan.strategy.small.file.limit", "629145600").option("hoodie.clustering.plan.strategy.sort.columns", "").mode(Append).save(basePath);其余三个表的生成语句,跟 customer_address 表类似,大家可以试着生成一下。
为了对比,我们还要生成一组同命名的没有使用 Clustering 的表,可以把这两组表,分别放到不同的Hive Database里,例如tpcds_hudi_cluster 和 pcds_hudi_nocluster. 生成没有Clustering 表的脚本,跟生成 Clustering 表的脚本类似,只要把Clustering 相关的参数拿掉就可以了。
3.2 查询
Amazon EMR 6.5.0里提供了 Trino360, 我们使用它来测试Hudi表的SQL查询性能。启动命令如下: /usr/lib/trino/bin/trino-cli-360-executable –server localhost:8889 –catalog hive –schema tpcds_hudi_cluster
如果按照2.1中生成了 TPC-DS 测试数据,就会看到一起生成的用于测试的查询语句,我们用 q6.sql 来测试,脚本如下:
--q6.sql--SELECT state, cnt FROM (SELECT a.ca_state state, count(*) cntFROMcustomer_address a, customer c, store_sales_ro s, date_dim d, item iWHERE a.ca_address_sk = c.c_current_addr_skAND c.c_customer_sk = s.ss_customer_skAND s.ss_sold_date_sk = d.d_date_skAND s.ss_item_sk = i.i_item_skAND d.d_month_seq =(SELECT distinct (d_month_seq) FROM date_dimWHERE d_year = 2001 AND d_moy = 1)AND i.i_current_price > 1.2 *(SELECT avg(j.i_current_price) FROM item jWHERE j.i_category = i.i_category)GROUP BY a.ca_state
) x
WHERE cnt >= 10
ORDER BY cnt LIMIT 100对没有使用Clustering的Hudi表的查询如下:
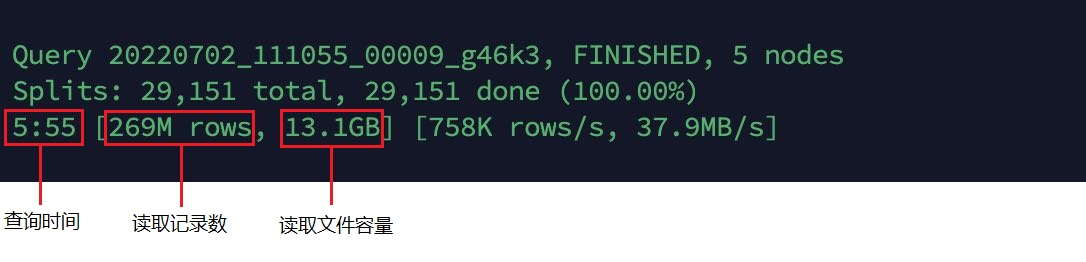
图6: 没有Clustering的Hudi表的查询
对使用Clustering的Hudi表的查询如下:
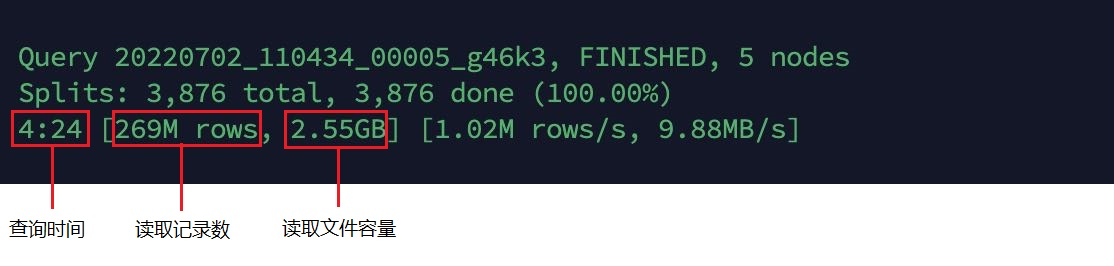
图7: 使用Clustering的Hudi表查询
可以看出:使用了 Clustering 的 Hudi 表,对比没有使用Clustering 的 Hudi 表,查询性能提升了35.4% , 读取记录数相同,读取文件容量大幅下降了。
4.对于使用Clustering的一些建议
4.1 对Upsert的影响
当执行 Clustering 的时候,对 File Group 实现的是 Snapshot Isolation 级别的隔离,所以对他们的修改是不允许对,也就是说,如果有 Upsert 和 Compaction 操作(MOR表),都要等 Clustering 结束之后
4.2 对负载的考虑
如果需要 Clustering 的表数据量比较大,分区比较多的话,做一次Clustering 也会产生大量的负载,所以对 Clustering 的范围,Hudi提供了多种选择。对既要高并发写,又要高吞吐读对表,可以在高并发写的波谷时段,例如夜间进行 Clustering
4.3 同步 or 异步
udi提供了两种 Clustering 方式,同步和异步。在对Hudi表高并发写的时候,不建议使用同步 Clustering,可以参考 [RFC-19] 中的方法,使用命令进行异步 Clustering.
4.4 要不要选择Sort Column
如果有些字段经常要用来做 Join,而且该字段的值又可以保证非空的情况下,是可以放到 Sort Column 里的,如果 Clustering 之后还有多个文件,Sort Column 有助于确认每个文件里该字段的范围,可以避免过多的文件读取,提升 Join 操作的性能。原理上有点类似Hive Clustering,请参考:Bucketing in Hive: Create Bucketed Table in Hive | upGrad blog .
有兴趣的朋友可以对比一下,选不选择Sort Column在Join查询性能上的差别。
4.5 Clustering 等同于大文件吗?
有人会说,Clustering 就是把小文件合并成大文件,那创建Hudi表的时候,我直接选择大文件不就可以了吗?如果只是考虑读性能,这么做确实可以。但 Clustering 提供了更多的选择,对于那种有时候高并发写(适合小文件),有时候高吞吐读(适合大文件)的表,就很适合用Clustering 了。
4.6 增量查询
目前 Hudi 版本0.10下,Clustering 对增量查询的支持不是很好,Clustering 后的数据,都会被认为是“新”数据,也会出现在增量查询的结果中,然后这并不是我们期望的,因为本来没有对数据做任何改变,只是从小文件重写到大文件中,就被认为是增量数据了。所以依赖增量查询的表,不推荐使用 Clustering.
4.7 什么时间指定Clustering?
可以在任何需要 Clustering 的时候,指定 Clustering 的相关配置,不是只能在创建 Hudi 表的时候指定 Clustering. 也就是说,对于任意的 Hudi 表,如果发现产生了大量的小文件,如果其他条件符合(没有高并发写、不依赖增量查询等),可以随时指定 Clustering.
参考文档
通过使用 Amazon Graviton2 提升 EMR 的性价比 | 亚马逊AWS官方博客
Clustering | Apache Hudi
RFC - 19 Clustering data for freshness and query performance - HUDI - Apache Software Foundation
Apache Parquet
Hudi -Amazon EMR
Presto and Trino - Amazon EMR
Bucketing in Hive: Create Bucketed Table in Hive | upGrad blog
本篇作者

Dalei Xu
Amazon 数据分析产品技术专家,负责 Amazon 数据分析的解决方案的咨询和架构设计。多年从事一线开发,在数据开发、架构设计、性能优化和组件管理方面积累了丰富的经验,希望能将 Amazon 优秀的服务组件,推广给更多的企业用户,实现与客户的双赢和共同成长。
文章来源:https://dev.amazoncloud.cn/column/article/6309c8e20c9a20404da79150?sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN




![人工智能能够通过所有[创造力测试]](https://img-blog.csdnimg.cn/img_convert/1bb27851d2d44cd0920278caef1464d4.png)