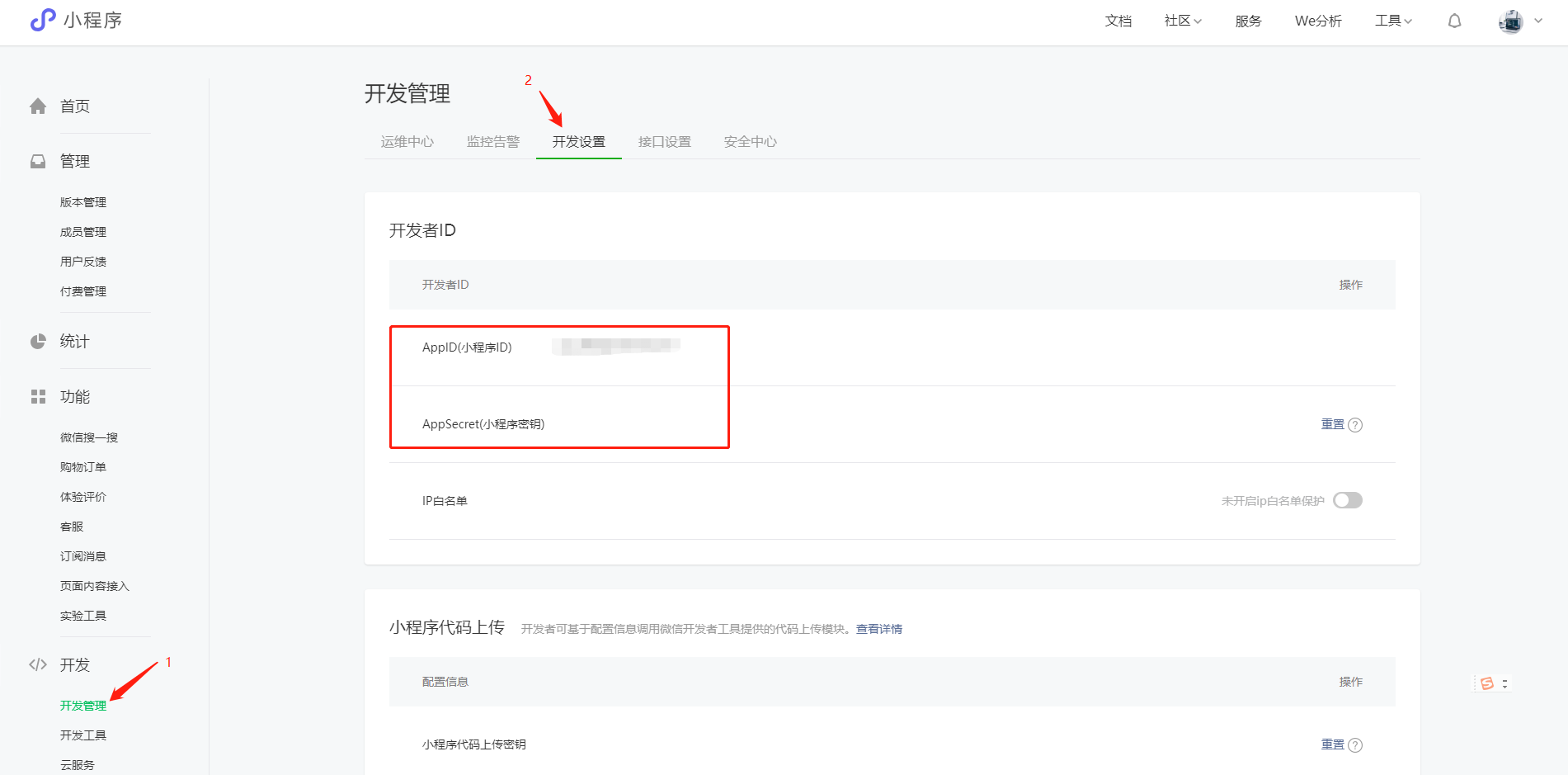
背景
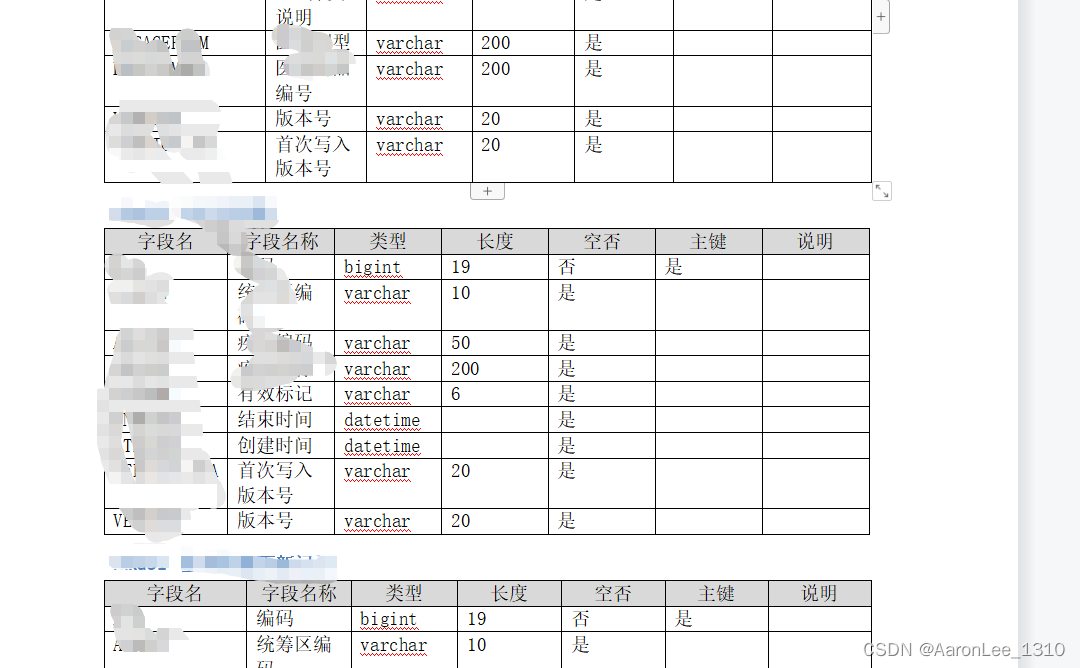
将项目中用到的表的结构写入到word文档,格式如下:

解决思路 -- 注意这次最初的思路,操作简单但是重复的操作很多最后选择了python
使用sql将这些字段查出来,然后导出到excel或者excel xml,然后粘贴到word
SELECT UPPER(COLUMN_NAME) 字段名,COLUMN_COMMENT 字段名称,DATA_TYPE 类型,(CASEWHEN DATA_TYPE = 'float' OR DATA_TYPE = 'double' OR DATA_TYPE = 'TINYINT' OR DATA_TYPE = 'SMALLINT' OR DATA_TYPE = 'MEDIUMINT' OR DATA_TYPE = 'INT' OR DATA_TYPE = 'INTEGER' OR DATA_TYPE = 'decimal' OR DATA_TYPE = 'bigint' THEN NUMERIC_PRECISION ELSE CHARACTER_MAXIMUM_LENGTH END) + '' 长度,CASEWHEN IS_NULLABLE = 'YES' THEN '是' ELSE '否' END 空否,CASEWHEN column_key = 'PRI' THEN '是' ELSE '' END 主键,'' 说明
FROMINFORMATION_SCHEMA.COLUMNS
WHERE table_schema = '你的库名' AND table_name = '你的表名' 【备注】:改成你自己的库名,表名
用可视化sql APP允许此sql之后,导出到excel 然后粘贴,以下使用sqlyog演示
生成结果后 右键 -> 导出表中所有的数据行/结果
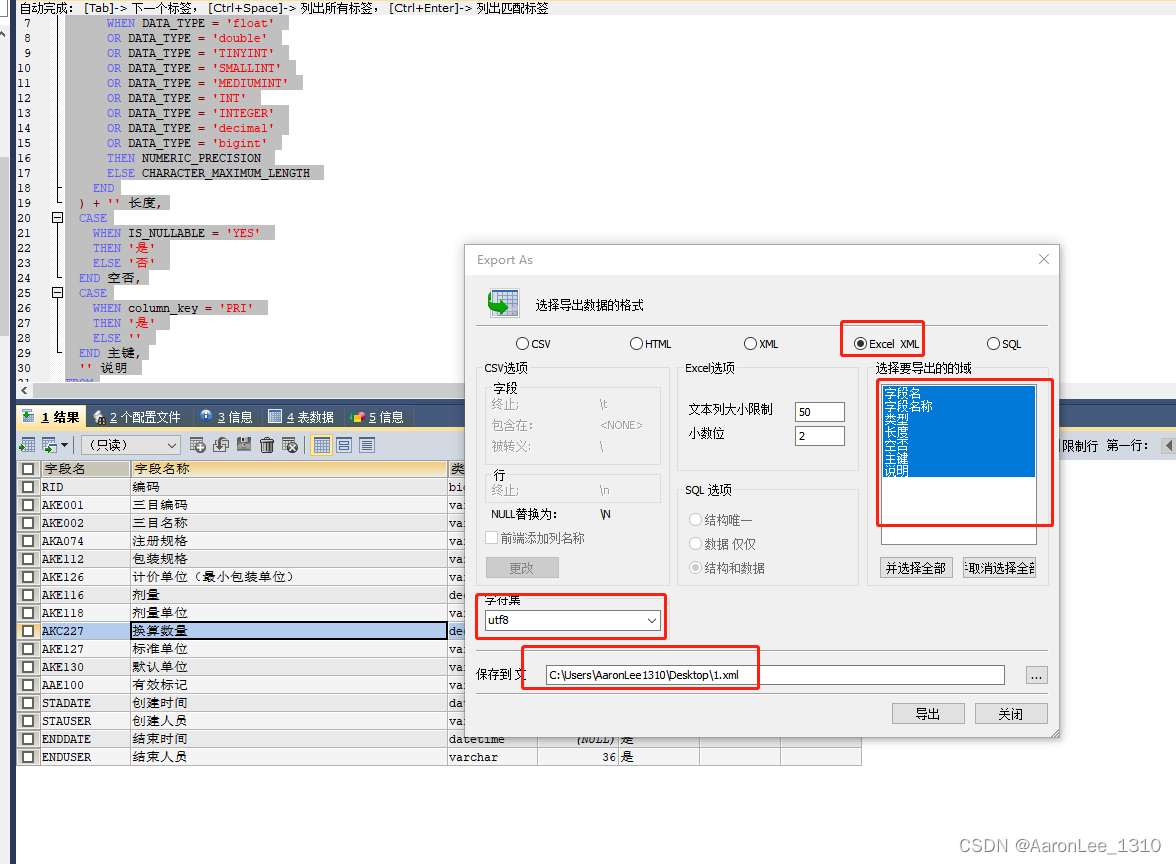
【注意】:我自己的使用过程中导出excel之后没有格式不方便复制,因此我选择的excel xml,可以自行去试一试
总结
按道理讲这里就结束了,但是我这里需要处理的表非常多,然后我自己的电脑有点垃圾,每次关闭生成的excel xml 再次重新打开需要浪费很多的时间,加上几十上百的表,重复操作及时上百次让我觉得非常恶心,因此就想着用python实现自动化办公
python 的实现
【说明】 下载依赖啥的自己努力吧!我在使用的过程中也遇到很多报错,但是解决错误本身是一个愉快的事情不是么
直接放代码
# 导包
import pymysql
from docx import Document
from docx.enum.table import WD_CELL_VERTICAL_ALIGNMENT
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml import parse_xml
from docx.shared import Pt, RGBColor
from docx.oxml.ns import qn, nsdecls# 读取或者创建文件
document = Document() # 新建文档
# document = Document('test.docx') # 读取现有文档,建立文档对象def load_data_from_mysql(table_name):conn = pymysql.connect(host="你的ip",port=3306,user="你的用户名",password="你的密码",db="你的库名",charset="utf8")cursor = conn.cursor()sql = "SELECT UPPER(COLUMN_NAME) 字段名, COLUMN_COMMENT 字段名称, DATA_TYPE 类型, " \"(CASE WHEN DATA_TYPE = 'float' OR DATA_TYPE = 'double' OR DATA_TYPE = 'TINYINT' OR DATA_TYPE = 'SMALLINT' OR DATA_TYPE = 'MEDIUMINT' " \"OR DATA_TYPE = 'INT' OR DATA_TYPE = 'INTEGER' OR DATA_TYPE = 'decimal' OR DATA_TYPE = 'bigint' THEN NUMERIC_PRECISION " \"ELSE CHARACTER_MAXIMUM_LENGTH END ) 长度, " \"CASE WHEN IS_NULLABLE = 'YES' THEN '是' ELSE '否' END 空否, CASE WHEN column_key = 'PRI' THEN '是' ELSE '' END 主键,'' 说明 " \"FROM INFORMATION_SCHEMA.COLUMNS WHERE table_schema ='你的库名' AND table_name = '{}'".format(table_name)print('执行sql:',sql)cursor.execute(sql)result = cursor.fetchall()return result'''
总的大标题部分
'''
# 第二种设置标题的方式,此方式还可以设置文本的字体、颜色、大小等属性
run = document.add_heading("", level=1).add_run("表结构")
# 设置西文字体
run.font.name = u'宋体'
# 设置中文字体
run._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
# 设置字体颜色
run.font.color.rgb = RGBColor(0,0,0) # 黑色
# 设置字体大小
run.font.size = Pt(30)
# 设置下划线
# run.font.underline = True
# 设置删除线
# run.font.strike = True
# 设置加粗
run.bold = True
# 设置斜体
# run.italic = True'''
要查询的表初始化
'''
# 需要查询的表名
table_name_list = ['xxxx', 'xxxx', 'xxxx', '这里放你的表名,我这里很多就不完全写下来了']
# 表名对应的注释 必须一一对应,没有注释也必须用''站位
table_name_disc_list = ['xxx表', 'xxx表', 'xxx表', '这里放你的表的注释,我这里很多就不完全写下来了']
# 校验名称和注释的长度是否一致
if(len(table_name_list) != len(table_name_disc_list)):print('table_name_list长度: ' + len(table_name_list) + ';table_name_disc_list长度: ' + len(table_name_disc_list))raise Exception("长度不一致")'''
写入小标题以及表格内容
'''
# 设置正文全局字体
document.styles['Normal'].font.name = u'宋体'
document.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')for i in range(len(table_name_list)):# 查询sql获得二维元组tuple1 = load_data_from_mysql(table_name_list[i])# 二维元组转化为二维列表 ,且将其他类型转化为字符串 且将None转化为 ''table_data_list = list(list([( '' if it is None else str(it)) for it in items]) for items in list(tuple1))# 写入小标题title = table_name_list[i] + ' ' + table_name_disc_list[i];document.add_heading(title, level=3)# 表格标题table_name = ['字段名', '字段名称', '类型', '长度', '空否', '主键', '说明']# 创建表格行列table = document.add_table(rows=len(table_data_list)+1, cols=len(table_name),style='Table Grid')# 首行设置背景色rows = table.rows[0]for cell in rows.cells:shading_elm = parse_xml(r'<w:shd {} w:fill="D9D9D9"/>'.format(nsdecls('w')))cell._tc.get_or_add_tcPr().append(shading_elm)# 写入表格标题for i in range(len(table_name)):cell = table.cell(0, i)cell.paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 水平居中cell.paragraphs[0].add_run(table_name[i])cell.vertical_alignment = WD_CELL_VERTICAL_ALIGNMENT.CENTER # 垂直居中# 写入表格内容for i in range(len(table_data_list)):for j in range(len(table_name)):table.cell(i+1, j).text = table_data_list[i][j]# 4
document.save("test.docx")【解释】 接下来一个个说明你需要更改的部分
1. load_data_from_mysql -- 执行sql的方法
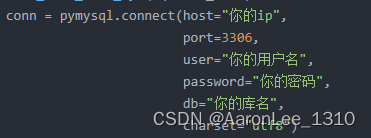
举个例子 db是库名,其他的看起来就懂就不说了
conn = pymysql.connect(host="127.0.0.1",port=3306,user="root",password="123456",db="test",charset="utf8")sql 就是把上面的sql复制下来,然后把最后表名变成参数,如果库名不是固定的需要设计多个,那么自己在加一个参数就行了
2. 你的表名以及注释信息
table_name_list 放你得所有需要用到的表,
table_name_disc_list 和上面表对应的注释,必须和上面意义对应
3. 表头设置

因为我这里是固定的,并且只需要这些字段,如果你的和我有所不通,请更改这部分,注意连同sql一起更改
其他的完全不需要更改,并且在python中把int,data类型的已经更换成字符串了,能够极大的避免导出到word出错
结果展示-部分